
 Périphériques technologiques
IA
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Périphériques technologiques
IA
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?
Le papier Stable Diffusion 3 est enfin publié, et les détails architecturaux sont révélés. Cela aidera-t-il à reproduire Sora ?

Le papier pour Stable Diffusion 3 est enfin là !
Ce modèle est sorti il y a deux semaines, utilisant la même architecture DiT (Diffusion Transformer) que Sora, et a fait beaucoup de bruit dès sa sortie.
Par rapport à la version précédente, la qualité des images générées par Stable Diffusion 3 a été considérablement améliorée. Il prend désormais en charge les invites multithèmes, et l'effet d'écriture de texte a également été amélioré, plus de caractères tronqués.
Stability AI a souligné que Stable Diffusion 3 est une série de modèles avec des tailles de paramètres allant de 800M à 8B. Cette plage de paramètres signifie que le modèle peut être exécuté directement sur de nombreux appareils portables, abaissant considérablement le seuil d'utilisation de grands modèles d'IA.
Dans un article récemment publié, Stability AI affirme que dans les évaluations basées sur les préférences humaines, Stable Diffusion 3 surpasse les systèmes de génération de texte en image de pointe actuels tels que DALL・E 3, Midjourney v6, et Idéogramme v1. Bientôt, ils rendront publics les données expérimentales, le code et les poids du modèle de l’étude.
Dans le journal, Stability AI a révélé plus de détails sur Stable Diffusion 3.

- Titre de l'article : Mise à l'échelle des transformateurs de flux rectifiés pour la synthèse d'images à haute résolution
- Lien de l'article : https://stabilityai-public-packages.s3.us-west-2.amazonaws .com/Stable+Diffusion+3+Paper.pdf
Détails architecturaux
Pour la génération de texte en image, le modèle Stable Diffusion 3 doit prendre en compte à la fois les modes texte et image. C’est pourquoi les auteurs de l’article appellent cette nouvelle architecture MMDiT, en référence à sa capacité à gérer plusieurs modalités. Comme pour les versions précédentes de Stable Diffusion, les auteurs utilisent des modèles pré-entraînés pour dériver des représentations de texte et d'images appropriées. Plus précisément, ils ont utilisé trois modèles d'intégration de texte différents (deux modèles CLIP et T5) pour coder les représentations textuelles, ainsi qu'un modèle d'encodage automatique amélioré pour coder les jetons d'image.
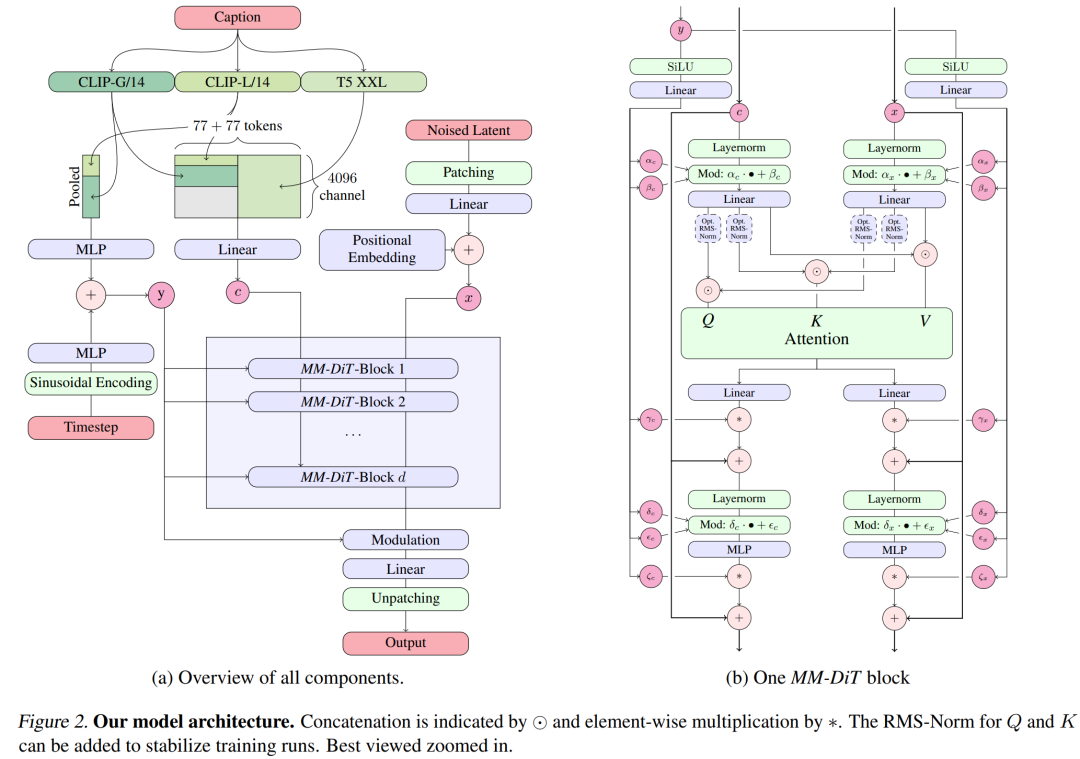
Architecture du modèle Stable Diffusion 3.
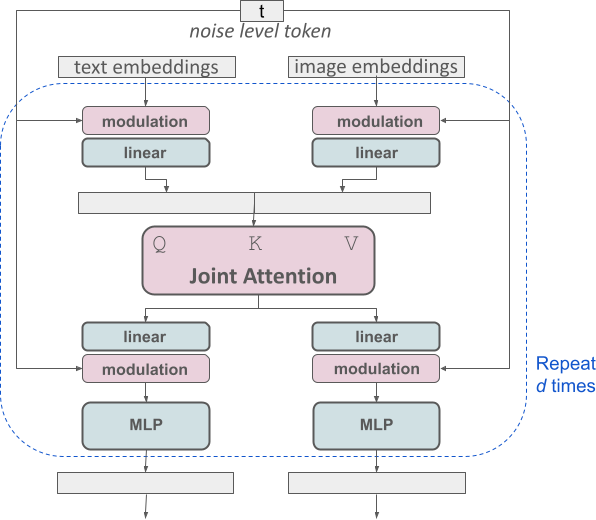
Transformateur de diffusion multimodal amélioré : bloc MMDiT.
L'architecture SD3 est basée sur DiT proposé par William Peebles, membre R&D principal de Sora, et Xie Saining, professeur adjoint d'informatique à l'Université de New York. Étant donné que l'intégration de texte et l'intégration d'images sont conceptuellement très différentes, les auteurs de SD3 utilisent deux ensembles de poids différents pour les deux modalités. Comme le montre la figure ci-dessus, cela équivaut à mettre en place deux transformateurs indépendants pour chaque modalité, mais en combinant les séquences des deux modalités pour les opérations d'attention, afin que les deux représentations puissent travailler dans leur propre espace. Une autre représentation est également prise en compte. .
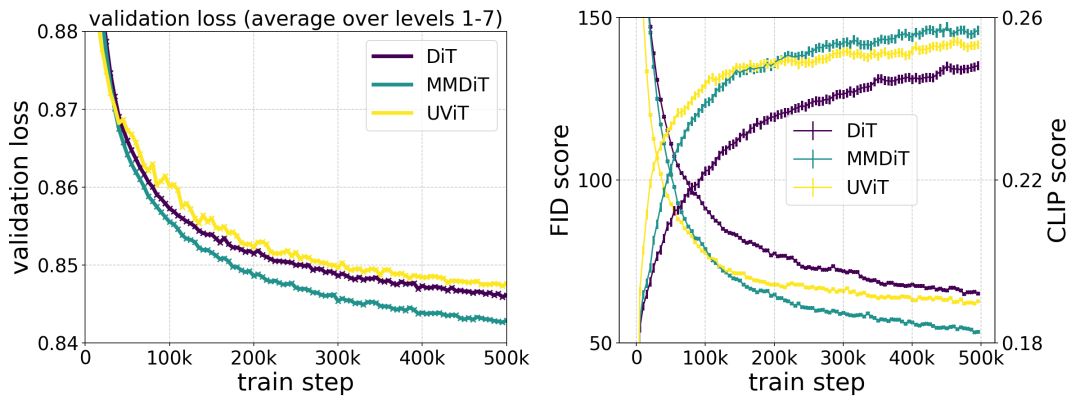
L'architecture MMDiT proposée par les auteurs surpasse les bases de texte-image établies telles que UViT et DiT lors de la mesure de la fidélité visuelle et de l'alignement du texte pendant la formation.
Avec cette approche, les informations peuvent circuler entre les images et les jetons de texte, améliorant ainsi la compréhension globale du modèle et la typographie de la sortie générée. Comme indiqué dans l'article, cette architecture est également facilement extensible à plusieurs modalités telles que la vidéo.

Grâce aux capacités améliorées de suivi d'invite de Stable Diffusion 3, le nouveau modèle a la capacité de produire des images qui se concentrent sur une variété de thèmes et de qualités différents, tout en étant très flexible dans le style de l'image elle-même.

Flux rectifié amélioré grâce à la repondération
Stable Diffusion 3 adopte la formule Rectified Flow (RF) Pendant le processus d'entraînement, les données et le bruit sont connectés dans une trajectoire linéaire. Cela rend le chemin d'inférence plus droit, réduisant ainsi les étapes d'échantillonnage. De plus, les auteurs introduisent également un nouveau schéma d’échantillonnage de trajectoire au cours du processus de formation. Ils ont émis l’hypothèse que la partie médiane de la trajectoire poserait une tâche de prédiction plus difficile, de sorte que le système a accordé plus de poids à la partie médiane de la trajectoire. Ils ont comparé en utilisant plusieurs ensembles de données, métriques et paramètres d'échantillonneur et ont testé la méthode proposée par rapport à 60 autres trajectoires de diffusion telles que LDM, EDM et ADM. Les résultats montrent que même si les performances des formulations RF précédentes s'améliorent avec peu d'étapes d'échantillonnage, leurs performances relatives diminuent à mesure que le nombre d'étapes augmente. En revanche, la variante RF repondérée proposée par les auteurs améliore systématiquement les performances.
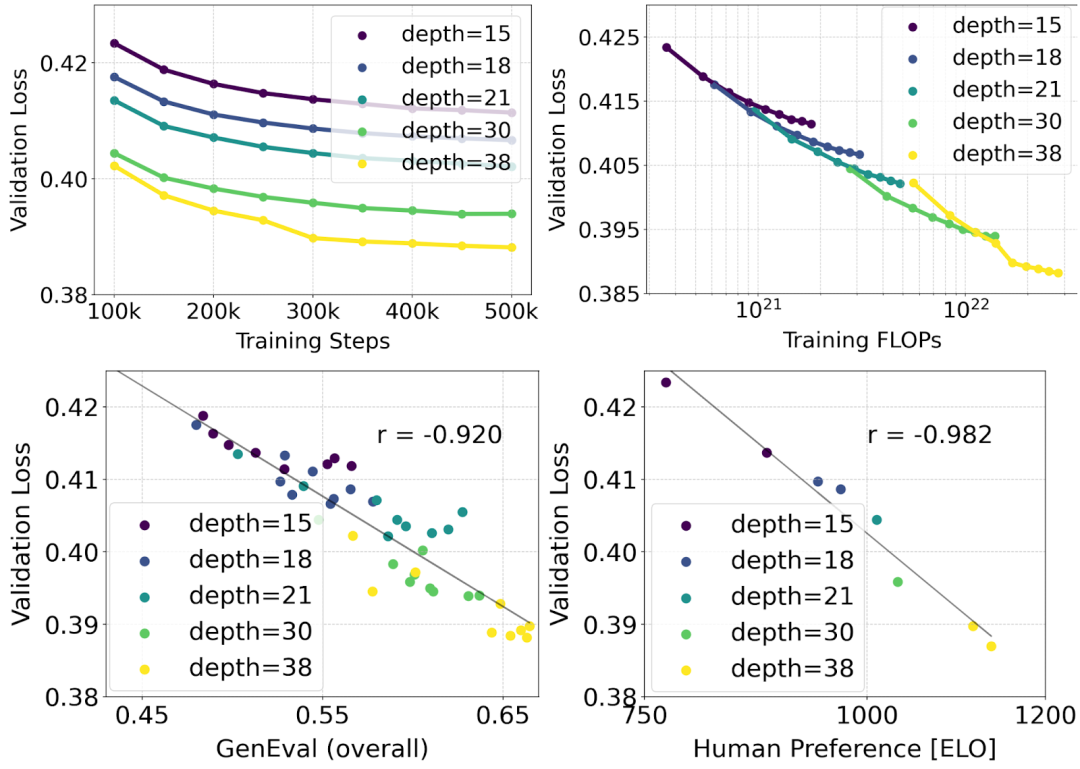
Mise à l'échelle du modèle de transformateur de flux rectifié
L'auteur a mené des recherches de mise à l'échelle sur la synthèse texte-image à l'aide de la formule de flux rectifié repondérée et du squelette MMDiT. Ils ont formé des modèles allant de 15 blocs avec des paramètres 450M à 38 blocs avec des paramètres 8B et ont observé que la perte de validation diminuait progressivement avec l'augmentation de la taille du modèle et des étapes de formation (première partie de la figure ci-dessus OK). Pour examiner si cela se traduisait par des améliorations significatives des résultats du modèle, les auteurs ont également évalué la métrique d'alignement automatique des images (GenEval) et le score de préférence humaine (ELO) (deuxième ligne ci-dessus). Les résultats montrent une forte corrélation entre ces métriques et la perte de validation, ce qui suggère que cette dernière est un bon prédicteur des performances globales du modèle. De plus, la tendance à la mise à l’échelle ne montre aucun signe de saturation, ce qui rend les auteurs optimistes quant à la poursuite de l’amélioration des performances du modèle à l’avenir.
Encodeur de texte flexible
En supprimant l'encodeur de texte T5, paramètre 4,7B, gourmand en mémoire, utilisé pour l'inférence, les besoins en mémoire du SD3 peuvent être considérablement réduits avec une perte de performances minimale. Comme indiqué, la suppression de cet encodeur de texte n'a aucun impact sur l'esthétique visuelle (taux de victoire de 50 % sans T5) et ne réduit que légèrement la cohérence du texte (taux de victoire de 46 %). Cependant, l'auteur recommande d'ajouter T5 lors de la génération de texte écrit pour utiliser pleinement les performances de SD3, car ils ont observé que sans l'ajout de T5, les performances de génération de composition diminuaient encore plus (taux de victoire de 38 %), comme le montre la figure ci-dessous :

La suppression de T5 pour l'inférence n'entraînera qu'une baisse significative des performances lors de la présentation d'invites très complexes impliquant de nombreux détails ou de grandes quantités de texte écrit. L'image ci-dessus montre trois échantillons aléatoires de chaque exemple.
Performances du modèle
L'auteur compare les images de sortie de Stable Diffusion 3 avec divers autres modèles open source (y compris SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 et Pixart-α) ainsi qu'avec des sources fermées. des modèles tels que DALL -E 3, Midjourney v6 et Ideogram v1) ont été comparés pour évaluer les performances sur la base des commentaires humains. Dans ces tests, les évaluateurs humains reçoivent des exemples de résultats de chaque modèle et sont jugés en fonction de la façon dont le résultat du modèle suit le contexte de l'invite donnée (suivi de l'invite), de la qualité du rendu du texte conformément à l'invite (typographie) et quelle image Les images avec une esthétique visuelle plus élevée sont sélectionnées pour obtenir les meilleurs résultats.
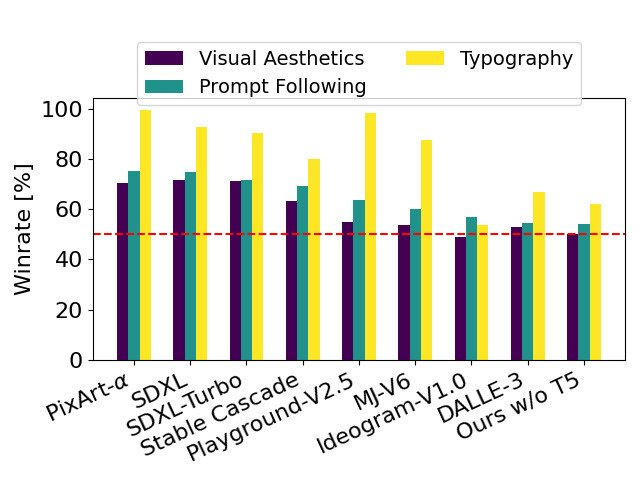
Comparé à SD3, ce tableau décrit son taux de victoire basé sur l'évaluation humaine de l'esthétique visuelle, du suivi rapide et de la mise en page du texte.
D'après les résultats des tests, l'auteur a constaté que Stable Diffusion 3 est équivalent, voire meilleur, au système de génération de texte en image de pointe actuel dans tous les aspects ci-dessus.
Lors des premiers tests d'inférence non optimisés sur du matériel grand public, le plus grand modèle SD3 à paramètres 8B s'insère dans la VRAM de 24 Go du RTX 4090, prenant 34 secondes pour générer une image à une résolution de 1024 x 1024 en utilisant 50 étapes d'échantillonnage.

De plus, lors de la version initiale, Stable Diffusion 3 sera disponible en plusieurs variantes, allant des modèles paramétriques 800 m aux modèles paramétriques 8B, afin de supprimer davantage les barrières matérielles.


Veuillez vous référer au document original pour plus de détails.
Lien de référence : https://stability.ai/news/stable-diffusion-3-research-paper
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
Binance est le suzerain de l'écosystème mondial de trading d'actifs numériques, et ses caractéristiques comprennent: 1. Le volume de négociation quotidien moyen dépasse 150 milliards de dollars, prend en charge 500 paires de négociation, couvrant 98% des monnaies grand public; 2. La matrice d'innovation couvre le marché des dérivés, la mise en page Web3 et le système éducatif; 3. Les avantages techniques sont des moteurs de correspondance d'une milliseconde, avec des volumes de traitement de pointe de 1,4 million de transactions par seconde; 4. Conformité Progress détient des licences de 15 pays et établit des entités conformes en Europe et aux États-Unis.
 Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Les échanges jouent un rôle essentiel sur le marché des crypto-monnaies d'aujourd'hui. Ce ne sont pas seulement des plateformes pour les investisseurs pour négocier, mais aussi des sources importantes de liquidité du marché et la découverte des prix. Les plus grands échanges de devises virtuels au monde se classent parmi les dix premiers, et ces échanges sont non seulement bien en avance dans le volume des échanges, mais présentent également leurs propres avantages dans l'expérience utilisateur, la sécurité et les services innovants. Les échanges qui dépassent la liste ont généralement une grande base d'utilisateurs et une influence approfondie du marché, et leur volume de trading et leurs types d'actifs sont souvent difficiles à atteindre par d'autres échanges.
 'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
Le plongeon sur le marché des crypto-monnaies a provoqué la panique parmi les investisseurs, et Dogecoin (Doge) est devenu l'une des zones les plus difficiles. Son prix a fortement chuté et le verrouillage de la valeur totale de la finance décentralisée (DEFI) (TVL) a également connu une baisse significative. La vague de vente de "Black Monday" a balayé le marché des crypto-monnaies, et Dogecoin a été le premier à être touché. Son Defitvl a chuté aux niveaux de 2023 et le prix de la devise a chuté de 23,78% au cours du dernier mois. Le Defitvl de Dogecoin est tombé à un minimum de 2,72 millions de dollars, principalement en raison d'une baisse de 26,37% de l'indice de valeur SOSO. D'autres plates-formes de Defi majeures, telles que le Dao et Thorchain ennuyeux, TVL ont également chuté de 24,04% et 20, respectivement.
 Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) se démarque sur le marché des crypto-monnaies avec ses mécanismes uniques de vérification biométrique et de protection de la vie privée, attirant l'attention de nombreux investisseurs. WLD a permis de se produire avec remarquablement parmi les Altcoins avec ses technologies innovantes, en particulier en combinaison avec la technologie d'Intelligence artificielle OpenAI. Mais comment les actifs numériques se comporteront-ils au cours des prochaines années? Prédons ensemble le prix futur de WLD. Les prévisions de prix de 2025 WLD devraient atteindre une croissance significative de la WLD en 2025. L'analyse du marché montre que le prix moyen du WLD peut atteindre 1,31 $, avec un maximum de 1,36 $. Cependant, sur un marché baissier, le prix peut tomber à environ 0,55 $. Cette attente de croissance est principalement due à WorldCoin2.
 Rexas Finance (RXS) peut dépasser Solana (Sol), Cardano (ADA), XRP et Dogecoin (DOGE) en 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) peut dépasser Solana (Sol), Cardano (ADA), XRP et Dogecoin (DOGE) en 2025
Apr 21, 2025 pm 02:30 PM
Sur le marché volatil des crypto-monnaies, les investisseurs recherchent des alternatives qui vont au-delà des devises populaires. Bien que les crypto-monnaies bien connues telles que Solana (Sol), Cardano (ADA), XRP et Dogecoin (DOGE) sont également confrontées à des défis tels que le sentiment du marché, l'incertitude réglementaire et l'évolutivité. Cependant, un nouveau projet émergent, la rexasfinance (RXS), est en émergence. Il ne s'appuie pas sur les effets de célébrités ou le battage médiatique, mais se concentre sur la combinaison des actifs du monde réel (RWA) avec la technologie de la blockchain pour offrir aux investisseurs une façon innovante d'investir. Cette stratégie le fait espérer être l'un des projets les plus réussis de 2025. Rexasfi
 Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Les principaux échanges comprennent: 1. Binance, le plus grand volume de trading au monde, prend en charge 600 devises et les frais de gestion des points sont de 0,1%; 2. Okx, une plate-forme équilibrée, prend en charge 708 paires de trading, et les frais de traitement des contrats perpétuels sont de 0,05%; 3. Gate.io, couvre 2700 petites monnaies, et les frais de traitement des points sont de 0,1% à 0,3%; 4. Coinbase, la référence de conformité américaine, les frais de traitement des points sont de 0,5%; 5. Kraken, la haute sécurité et l'audit de réserve régulière.
 La plate-forme de médias sociaux Web3 Tox collabore avec Omni Labs pour intégrer l'infrastructure d'IA
Apr 21, 2025 pm 07:06 PM
La plate-forme de médias sociaux Web3 Tox collabore avec Omni Labs pour intégrer l'infrastructure d'IA
Apr 21, 2025 pm 07:06 PM
La plate-forme décentralisée de médias sociaux Tox a atteint un partenariat stratégique avec Omnilabs, un leader des solutions d'intelligence artificielle, pour intégrer les capacités d'intelligence artificielle dans l'écosystème web3. Ce partenariat est publié par le compte officiel de Tox Officiel de Tox et vise à créer un environnement en ligne plus juste et plus intelligent. Omnilabs est connu pour ses systèmes autonomes intelligents, avec sa capacité AI-AS-A-Service (AIAAS) soutenant de nombreux protocoles Defi et NFT. Son infrastructure utilise des agents d'IA pour la prise de décision en temps réel, les processus automatisés et l'analyse approfondie des données, visant à s'intégrer de manière transparente dans l'écosystème décentralisé pour autonomiser la plate-forme blockchain. La collaboration avec Tox rendra les outils d'IA d'Omnilabs plus étendus, en les intégrant dans les réseaux sociaux décentralisés,
 Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Les plates-formes qui ont des performances exceptionnelles dans le commerce, la sécurité et l'expérience utilisateur en effet de levier en 2025 sont: 1. OKX, adaptés aux traders à haute fréquence, fournissant jusqu'à 100 fois l'effet de levier; 2. Binance, adaptée aux commerçants multi-monnaies du monde entier, offrant un effet de levier 125 fois élevé; 3. Gate.io, adapté aux joueurs de dérivés professionnels, fournissant 100 fois l'effet de levier; 4. Bitget, adapté aux novices et aux commerçants sociaux, fournissant jusqu'à 100 fois l'effet de levier; 5. Kraken, adapté aux investisseurs stables, fournissant 5 fois l'effet de levier; 6. BUTBIT, adapté aux explorateurs Altcoin, fournissant 20 fois l'effet de levier; 7. Kucoin, adapté aux commerçants à faible coût, fournissant 10 fois l'effet de levier; 8. Bitfinex, adapté au jeu senior
