
 Périphériques technologiques
IA
Google lance la dernière IA de « lecture d'écran » ! PaLM 2-S génère automatiquement des données et plusieurs tâches de compréhension actualisent SOTA
Périphériques technologiques
IA
Google lance la dernière IA de « lecture d'écran » ! PaLM 2-S génère automatiquement des données et plusieurs tâches de compréhension actualisent SOTA
Google lance la dernière IA de « lecture d'écran » ! PaLM 2-S génère automatiquement des données et plusieurs tâches de compréhension actualisent SOTA

Le grand modèle que tout le monde veut est celui qui est vraiment intelligent...
Non, l'équipe Google a créé une puissante IA de « lecture d'écran ».
Les chercheurs l'appellent ScreenAI, un nouveau modèle de langage visuel pour comprendre les interfaces utilisateur et les infographies.

Adresse papier : https://arxiv.org/pdf/2402.04615.pdf
Le cœur de ScreenAI est une nouvelle méthode de représentation de texte de capture d'écran qui peut identifier le type et la position des éléments de l'interface utilisateur.
Les chercheurs ont utilisé le modèle de langage Google PaLM 2-S pour générer des données d'entraînement synthétiques, qui ont été utilisées pour entraîner le modèle à répondre à des questions liées aux informations sur l'écran, à la navigation sur l'écran et au résumé du contenu de l'écran. Il convient de mentionner que cette méthode fournit de nouvelles idées pour améliorer les performances du modèle lors de la gestion des tâches liées à l'écran.

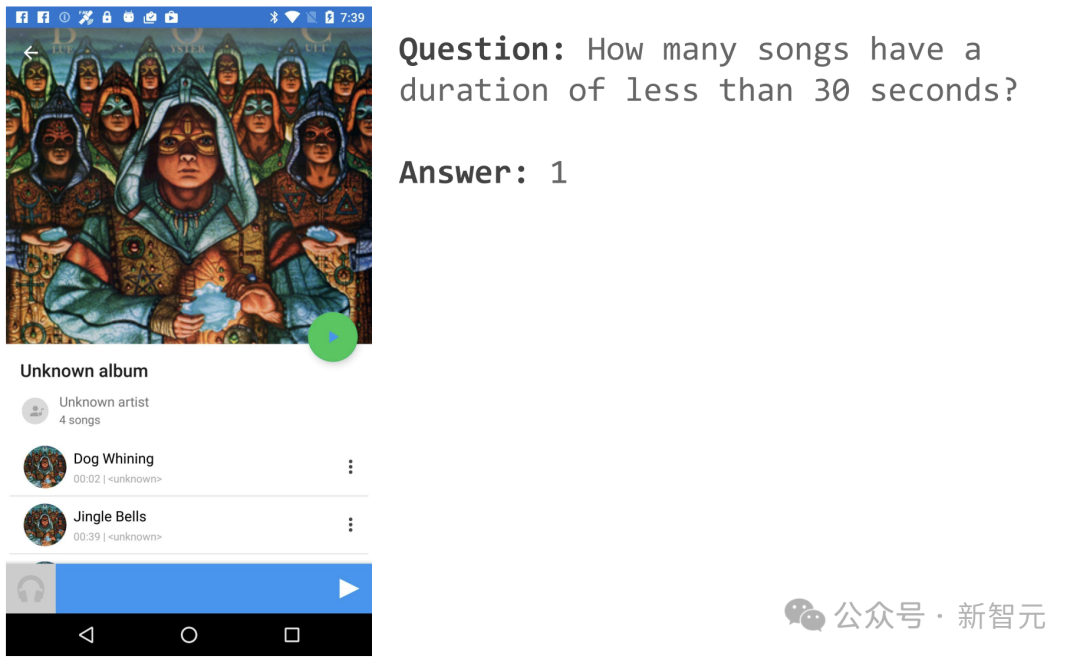
Par exemple, si vous ouvrez une page d'application musicale, vous pouvez demander « Combien de chansons durent moins de 30 secondes » ?
ScreenAI donne une réponse simple : 1.
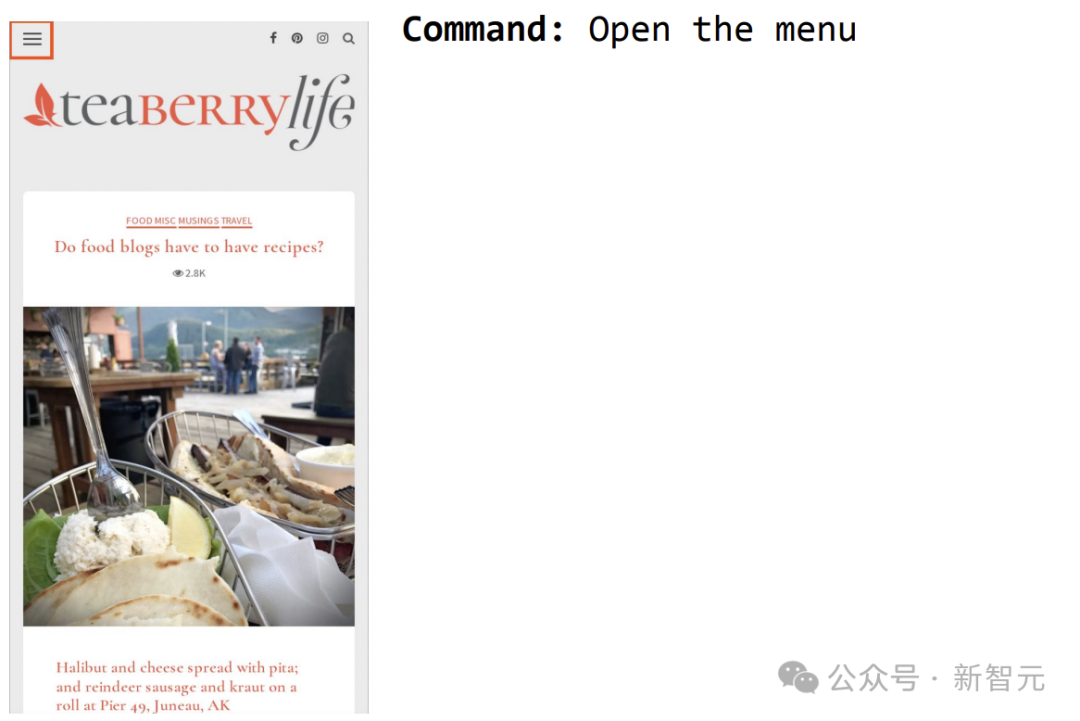
Un autre exemple consiste à commander à ScreenAI d'ouvrir le menu et vous pouvez le sélectionner.
Source d'inspiration architecturale - PaLI
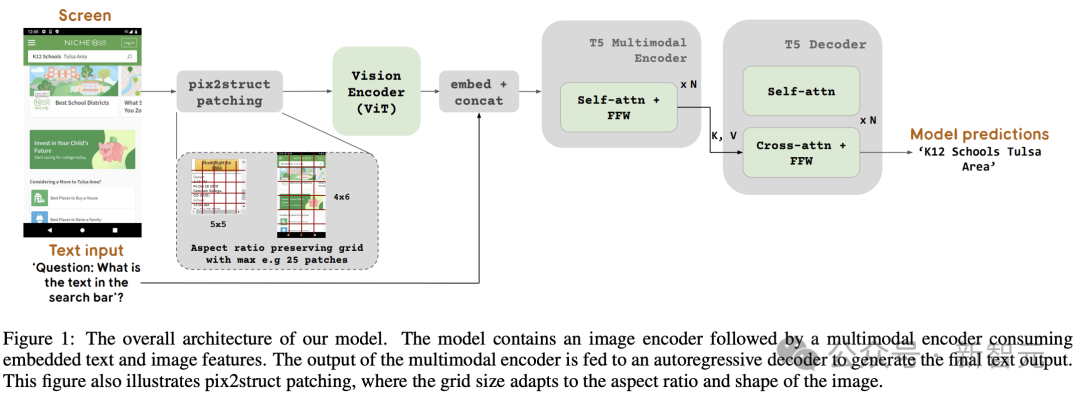
La figure 1 montre l'architecture du modèle ScreenAI. Les chercheurs se sont inspirés de l’architecture de la famille de modèles PaLI, constituée d’un bloc codeur multimodal.
Le bloc d'encodeur contient un encodeur visuel de type ViT et un encodeur de langage mT5 consommant une entrée d'image et de texte, suivis d'un décodeur autorégressif.
L'image d'entrée est transformée par l'encodeur visuel en une série d'intégrations, qui sont combinées avec l'intégration de texte d'entrée et introduites dans l'encodeur de langage mT5.
La sortie de l'encodeur est transmise au décodeur, qui génère une sortie texte.
Cette formulation généralisée peut utiliser la même architecture de modèle pour résoudre diverses tâches visuelles et multimodales. Ces tâches peuvent être reformulées sous forme de problèmes texte + image (entrée) en texte (sortie).
Par rapport à la saisie de texte, les intégrations d'images constituent une partie importante de la longueur de saisie des encodeurs multimodaux.
En bref, ce modèle utilise un encodeur d'image et un encodeur de langage pour extraire les caractéristiques de l'image et du texte, fusionner les deux, puis les saisir dans le décodeur pour générer du texte.
Cette méthode de construction peut être largement appliquée à des tâches multimodales telles que la compréhension d'images.
De plus, les chercheurs ont étendu l'architecture encodeur-décodeur de PaLI pour accepter divers modes de blocage d'images.
L'architecture PaLI d'origine n'accepte que les correctifs d'image dans un motif de grille fixe pour traiter les images d'entrée. Cependant, les chercheurs dans le domaine des écrans rencontrent des données qui couvrent une grande variété de résolutions et de formats d’image.
Pour qu'un seul modèle s'adapte à toutes les formes d'écran, il est nécessaire d'utiliser une stratégie de carrelage qui fonctionne pour des images de formes variées.
À cette fin, l'équipe de Google a emprunté une technologie introduite dans Pix2Struct, qui permet la génération de blocs d'images arbitraires en forme de grille en fonction de la forme de l'image d'entrée et d'un nombre maximum prédéfini de blocs, comme le montre la figure 1.
Ceci est capable de s'adapter aux images d'entrée de différents formats et rapports d'aspect sans avoir à rembourrer ou à étirer l'image pour fixer sa forme, ce qui rend le modèle plus polyvalent et capable de gérer à la fois un mobile (c'est-à-dire un portrait) et un ordinateur de bureau (c'est-à-dire un portrait). paysage).
Configuration du modèle
Les chercheurs ont formé 3 modèles de tailles différentes, contenant les paramètres 670M, 2B et 5B.
Pour les modèles de paramètres 670M et 2B, les chercheurs ont commencé avec des points de contrôle unimodaux pré-entraînés d'un encodeur visuel et d'un modèle de langage encodeur-décodeur.
Pour le modèle de paramètres 5B, commencez par le point de contrôle multimodal de pré-entraînement de PaLI-3, où ViT est formé avec un modèle de langage d'encodeur-décodeur basé sur UL2.
La répartition des paramètres entre les modèles de vision et de langage est visible dans le tableau 1.

Génération automatique de données
Les chercheurs affirment que la phase de pré-formation du développement du modèle dépend en grande partie de l'accès à des ensembles de données vastes et diversifiés.
Cependant, l'étiquetage manuel de nombreux ensembles de données n'est pas pratique, c'est pourquoi la stratégie de l'équipe Google est la suivante : la génération automatique de données.
Cette approche exploite de petits modèles spécialisés, chacun étant capable de générer et d'étiqueter des données de manière efficace et avec une grande précision.
Par rapport à l'annotation manuelle, cette approche automatisée est non seulement efficace et évolutive, mais garantit également un certain niveau de diversité et de complexité des données.
La première étape consiste à donner au modèle une compréhension globale des éléments de texte, des divers composants de l'écran, ainsi que de leur structure et hiérarchie globales. Cette compréhension fondamentale est essentielle à la capacité du modèle à interpréter avec précision et à interagir avec diverses interfaces utilisateur.
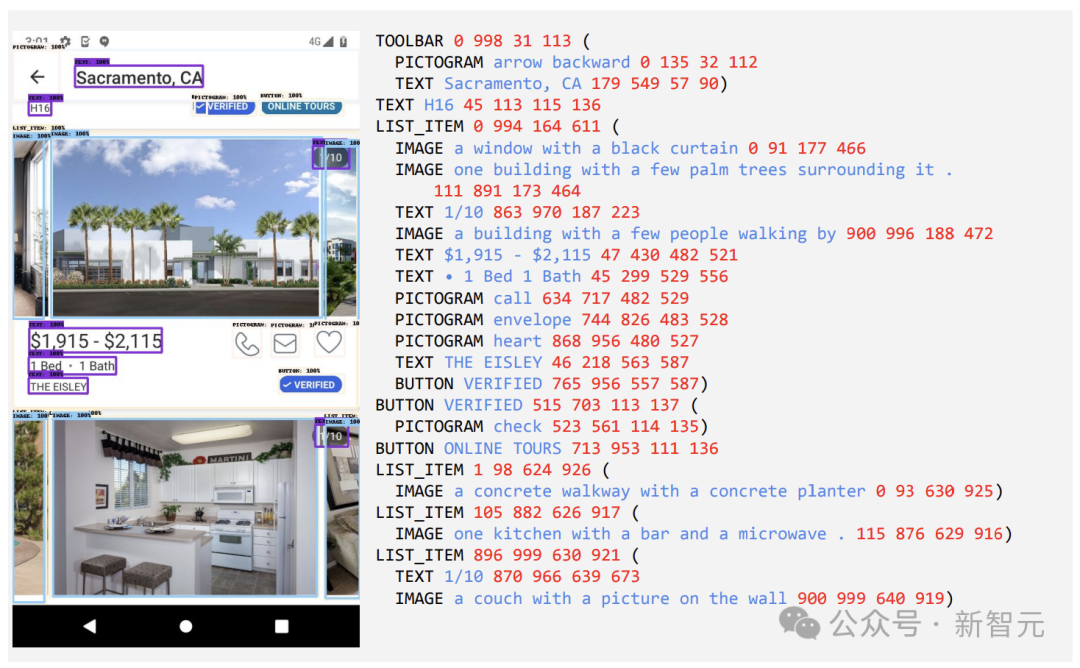
Ici, les chercheurs ont collecté un grand nombre de captures d'écran de divers appareils, notamment des ordinateurs de bureau, des appareils mobiles et des tablettes, via des applications d'exploration et des pages Web.
Ces captures d'écran sont ensuite annotées avec des balises détaillées qui décrivent les éléments de l'interface utilisateur, leurs relations spatiales et d'autres informations descriptives.
De plus, pour injecter une plus grande diversité dans les données de pré-formation, les chercheurs ont également exploité la puissance des modèles de langage, en particulier PaLM 2-S, pour générer des paires QA en deux étapes.
Commencez par générer le motif d'écran décrit précédemment. Les auteurs conçoivent ensuite une invite contenant des modèles d'écran pour guider le modèle de langage afin de générer des données synthétiques.
Après quelques itérations, une astuce peut être identifiée qui génère efficacement les tâches requises, comme le montre l'annexe C.
Pour évaluer la qualité de ces réponses générées, les chercheurs ont effectué une vérification manuelle sur un sous-ensemble de données afin de garantir que les exigences de qualité prédéterminées étaient respectées.
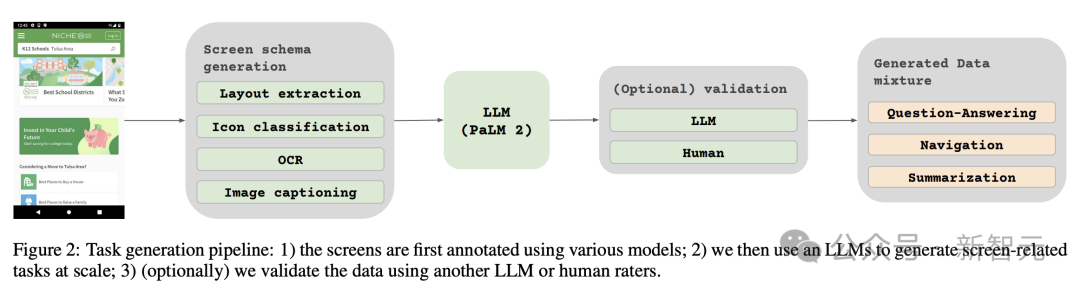
Cette méthode est décrite dans la figure 2, ce qui améliore considérablement la profondeur et l'étendue de l'ensemble de données de pré-entraînement.
En tirant parti des capacités de traitement du langage naturel de ces modèles, combinées à des modèles d'écran structurés, diverses interactions et scénarios utilisateur peuvent être simulés.
Deux ensembles de tâches différentes
Ensuite, les chercheurs ont défini deux ensembles de tâches différents pour le modèle : un ensemble initial de tâches de pré-formation et un ensemble de tâches de réglage ultérieur.
Les deux groupes diffèrent principalement sur deux aspects :
- Source de données réelles : Pour les tâches de mise au point, les labels sont fournis ou vérifiés par des évaluateurs humains. Pour les tâches de pré-formation, les étiquettes sont déduites à l'aide de méthodes d'apprentissage auto-supervisées ou générées à l'aide d'autres modèles.
- Taille de l'ensemble de données : les tâches de pré-entraînement contiennent généralement un grand nombre d'échantillons. Par conséquent, ces tâches sont utilisées pour entraîner le modèle à travers une série d'étapes plus étendues.
Le tableau 2 présente un résumé de toutes les tâches de pré-formation.
Dans les données mixtes, l'ensemble de données est pondéré proportionnellement à sa taille, avec le poids maximum autorisé pour chaque tâche.

L'intégration de sources multimodales dans la formation multitâche, du traitement du langage à la compréhension visuelle et à l'analyse du contenu Web, permet au modèle de gérer efficacement différents scénarios et améliore sa polyvalence et ses performances globales.

Les chercheurs utilisent diverses tâches et repères pour estimer la qualité du modèle lors de la mise au point. Le tableau 3 résume ces références, y compris les références existantes en matière d'écran principal, d'infographie et de compréhension de documents.

Résultats expérimentaux
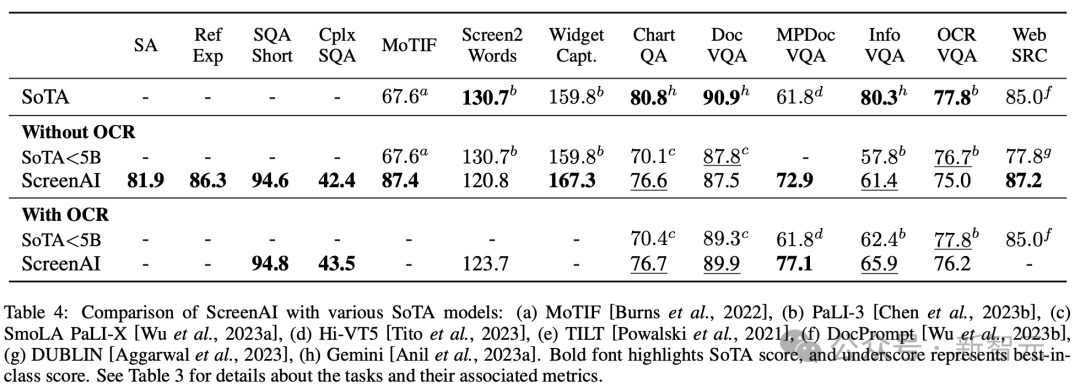
La figure 4 montre les performances du modèle ScreenAI et les compare avec les derniers résultats SOT sur diverses tâches liées aux écrans et aux graphiques d'informations.
Vous pouvez voir les performances de pointe de ScreenAI sur différentes tâches.
Dans le tableau 4, les chercheurs présentent les résultats du réglage fin d'une seule tâche à l'aide des données OCR.
Pour les tâches d'assurance qualité, l'ajout d'OCR peut améliorer les performances (par exemple jusqu'à 4,5 % sur Complex ScreenQA, MPDocVQA et InfoVQA).
Cependant, l'utilisation de l'OCR augmente légèrement la durée de saisie, ce qui entraîne globalement un entraînement plus lent. Cela nécessite également d'obtenir les résultats OCR au moment de l'inférence.
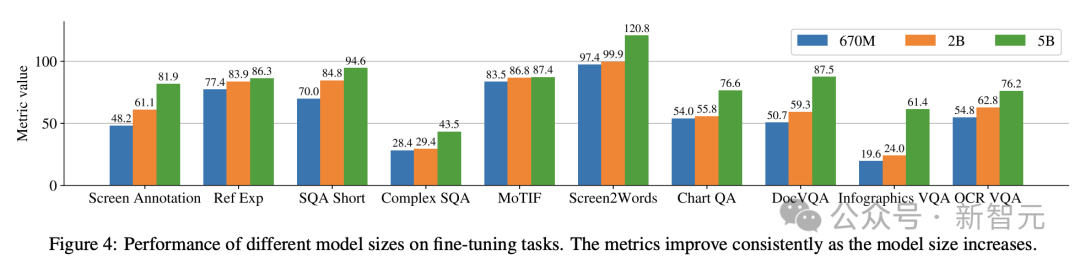
De plus, les chercheurs ont mené des expériences à tâche unique en utilisant les tailles de modèles suivantes : 670 millions de paramètres, 2 milliards de paramètres et 5 milliards de paramètres.
Comme on peut l'observer sur la figure 4, pour toutes les tâches, l'augmentation de la taille du modèle améliore les performances, et l'amélioration à la plus grande échelle n'est pas encore saturée.
Pour les tâches qui nécessitent un texte visuel et un raisonnement arithmétique plus complexes (telles que InfoVQA, ChartQA et Complex ScreenQA), l'amélioration entre le modèle à 2 milliards de paramètres et le modèle à 5 milliards de paramètres est nettement supérieure au modèle à 670 millions de paramètres. et le modèle à 2 milliards de paramètres.
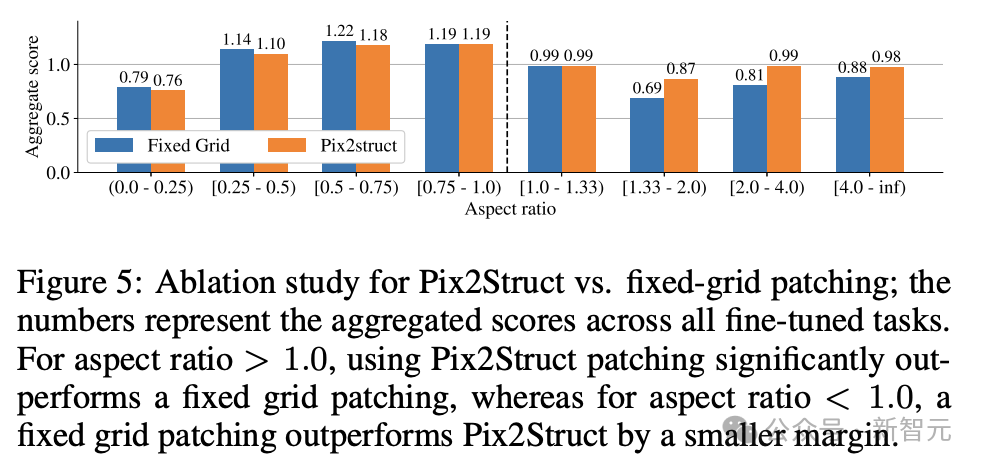
Enfin, la figure 5 montre que pour les images avec un rapport hauteur/largeur > 1,0 (images en mode paysage), la stratégie de segmentation pix2struct est nettement meilleure que la segmentation en grille fixe.
Pour les images en mode portrait, la tendance est inverse, mais la segmentation en grille fixe n'est que légèrement meilleure.
Étant donné que les chercheurs souhaitaient que le modèle ScreenAI fonctionne sur des images avec différents formats d'image, ils ont choisi d'utiliser la stratégie de segmentation pix2struct.
Les chercheurs de Google ont déclaré que le modèle ScreenAI nécessite également davantage de recherches sur certaines tâches pour combler l'écart avec des modèles plus grands tels que GPT-4 et Gemini.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
