
 Périphériques technologiques
IA
Détection d'images générées par l'IA à l'aide de la détection de contraste de texture
Périphériques technologiques
IA
Détection d'images générées par l'IA à l'aide de la détection de contraste de texture
Détection d'images générées par l'IA à l'aide de la détection de contraste de texture

Dans cet article, nous présenterons comment développer un modèle d'apprentissage profond pour détecter les images générées par l'intelligence artificielle.

De nombreuses méthodes d'apprentissage profond pour détecter les images générées par l'IA sont basées sur la façon dont l'image est générée ou sur les caractéristiques/sémantique de l'image. Généralement, ces modèles ne peuvent reconnaître que des objets spécifiques générés par l'IA, tels que des personnes. , Visage, voiture, etc.
Cependant, la méthode proposée dans cette étude intitulée « Contraste de texture riche et pauvre : une approche simple mais efficace pour la détection d'images générées par l'IA » surmonte ces défis et a une applicabilité plus large. Nous allons plonger dans ce document de recherche pour illustrer comment il résout efficacement les problèmes rencontrés par d’autres méthodes de détection d’images générées par l’IA.
Problème de généralisation
Lorsque nous utilisons un modèle (tel que ResNet-50) pour reconnaître des images générées par l'intelligence artificielle, le modèle apprend en fonction de la sémantique de l'image. Si nous entraînons un modèle à reconnaître les images de voitures générées par l'IA, en utilisant des images réelles et différentes images de voitures générées par l'IA pour l'entraînement, le modèle ne pourra obtenir des informations sur les voitures qu'à partir de ces données, mais pas sur d'autres objets avec précision. identification.
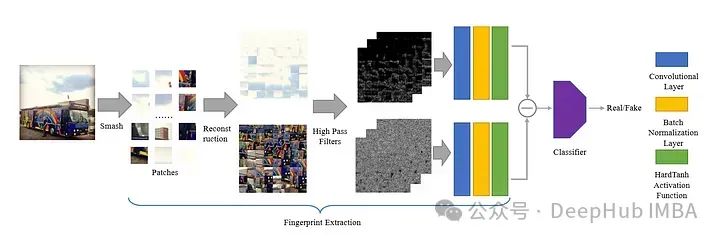
Bien que la formation puisse être effectuée sur les données de divers objets, cette méthode prend beaucoup de temps et ne peut atteindre qu'une précision d'environ 72 % sur des données inconnues. Bien que la précision puisse être améliorée en augmentant le nombre de temps d’entraînement et la quantité de données, nous ne pouvons pas obtenir des données d’entraînement illimitées. Cet article présente une méthode unique, utilisée pour empêcher le modèle d'apprendre les caractéristiques générées par l'IA à partir de la forme de l'image pendant l'entraînement. L'auteur propose une méthode appelée Smash&Reconstruction pour atteindre cet objectif.
Dans cette méthode, l'image est divisée en petits blocs de taille prédéterminée puis réorganisée pour générer une nouvelle image. Il ne s'agit que d'un bref aperçu, car des étapes supplémentaires sont nécessaires avant de former l'image d'entrée finale pour le modèle génératif.
Après avoir divisé l'image en petits patchs, nous divisons les patchs en deux groupes, l'un est les patchs à texture riche et l'autre est les patchs à texture pauvre.
Une zone détaillée d'une image, telle qu'un objet ou la limite entre deux zones de couleur contrastée, devient un riche patch de texture. Les zones richement texturées présentent une grande variation en pixels par rapport aux zones texturées qui constituent principalement l'arrière-plan, comme le ciel ou l'eau calme.
Calcul des mesures de richesse de texture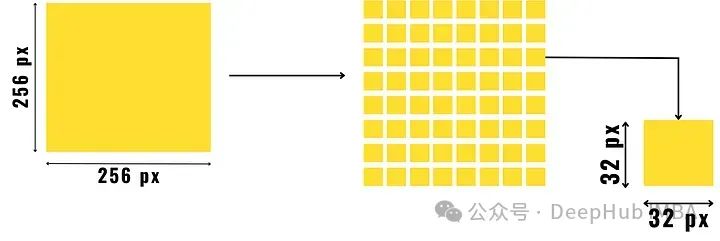
Commencez par diviser l'image en petits morceaux de taille prédéterminée, comme indiqué dans l'image ci-dessus. Recherchez ensuite les dégradés de pixels de ces patchs d'image (c'est-à-dire trouvez la différence entre les valeurs de pixels dans les directions horizontale, diagonale et anti-diagonale et additionnez-les) et séparez-les en patchs de texture riche et en patchs mal texturés.
Par rapport aux blocs avec une texture médiocre, les blocs riches en texture ont des valeurs de dégradé de pixels plus élevées. La formule pour calculer la valeur du dégradé de l'image est la suivante :
Séparez l'image en fonction du contraste des pixels, Deux images composites sont obtenues. Ce processus est un processus complet que cet article appelle « Smash&Reconstruction ».
Cela permet au modèle d'apprendre les détails de la texture au lieu de la représentation du contenu de l'objet
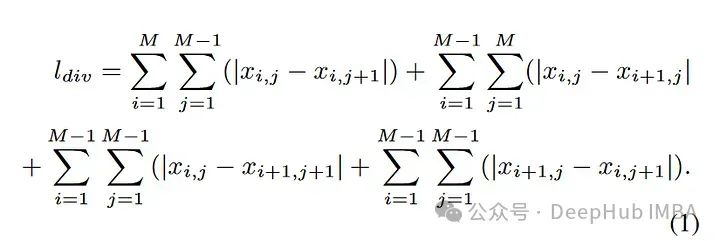
empreinte digitale
La plupart des méthodes basées sur les empreintes digitales sont limitées par la technologie de génération d'images, ces modèles/ Les algorithmes ne peuvent détecter que les images générées par des méthodes spécifiques/similaires telles que la diffusion, le GAN ou d'autres méthodes de génération d'images basées sur CNN. 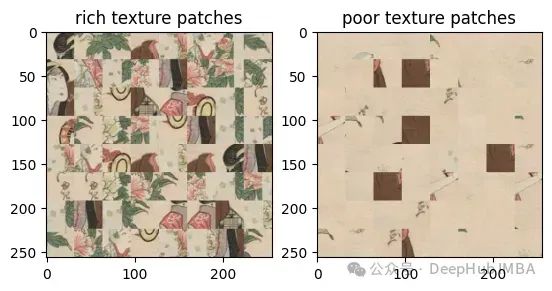
Pour résoudre précisément ce problème, le journal a divisé ces patchs d'images en textures riches ou pauvres. L’auteur a ensuite proposé une nouvelle méthode d’identification des empreintes digitales dans les images générées par l’intelligence artificielle, c’est le titre de l’article. Ils ont proposé de trouver le contraste entre les zones riches et pauvres en texture de l'image après avoir appliqué 30 filtres passe-haut.
En quoi le contraste entre les blocs de texture riches et pauvres aide-t-il ?
Pour une meilleure compréhension, nous comparons les images côte à côte, les images réelles et les images générées par l'IA.

Ces deux images sont également très difficiles à voir à l'œil nu, non ? filtre passe-haut, le contraste entre elles :

À partir de ces résultats, nous pouvons voir que les images générées par l'IA ont des taches de texture riches et un faible contraste par rapport aux images réelles. Le contraste est beaucoup plus élevé. 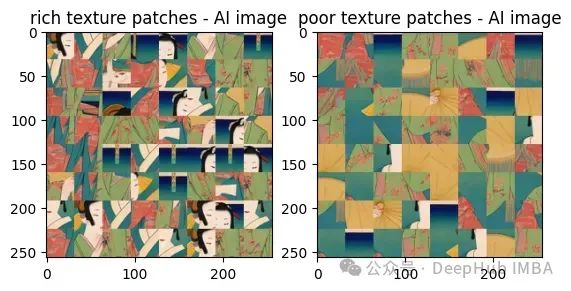
De cette façon, nous pouvons voir la différence à l'œil nu, nous pouvons donc mettre les résultats de contraste dans le modèle entraînable et saisir les données de résultat dans le classificateur. C'est l'architecture du modèle de notre article :
. 
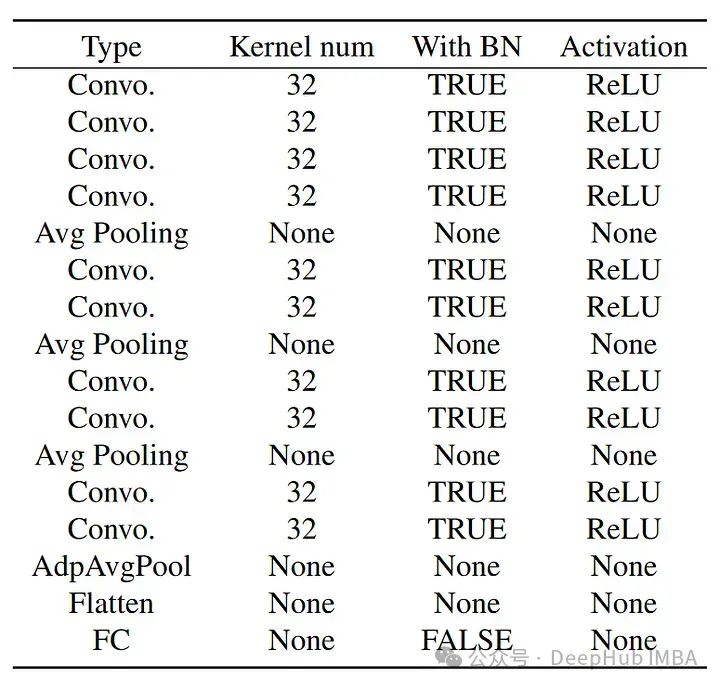
 La structure du classificateur est la suivante :
La structure du classificateur est la suivante :
L'article mentionne 30 filtres passe-haut, qui ont été initialement introduits pour la stéganalyse.
 Remarque : Il existe de nombreuses façons de stéganographie d'image. D'une manière générale, tant que l'information est cachée d'une manière ou d'une autre dans une image et qu'elle est difficile à découvrir par les méthodes ordinaires, on peut parler de stéganographie d'image. Il existe de nombreuses études connexes sur la stéganalyse, et ceux qui sont intéressés peuvent vérifier les informations pertinentes.
Remarque : Il existe de nombreuses façons de stéganographie d'image. D'une manière générale, tant que l'information est cachée d'une manière ou d'une autre dans une image et qu'elle est difficile à découvrir par les méthodes ordinaires, on peut parler de stéganographie d'image. Il existe de nombreuses études connexes sur la stéganalyse, et ceux qui sont intéressés peuvent vérifier les informations pertinentes.
Le filtre ici est une valeur matricielle appliquée à l'image à l'aide d'une méthode de convolution. Le filtre utilisé est un filtre passe-haut, qui ne laisse passer que les caractéristiques haute fréquence de l'image. Les caractéristiques haute fréquence incluent généralement des contours, des détails fins et des changements rapides d'intensité ou de couleur.
À l'exception de (f) et (g), tous les filtres sont pivotés selon un angle avant d'être réappliqués à l'image, formant ainsi un total de 30 filtres. La rotation de ces matrices se fait à l'aide de transformations affines, qui se font à l'aide de SciPy.
Résumé
Les résultats de l'article ont atteint une précision de vérification de 92%, et on dit que si vous vous entraînez davantage, vous obtiendrez de meilleurs résultats. C'est une étude très intéressante, et j'ai également trouvé. le Code de formation, ceux qui sont intéressés peuvent étudier en profondeur :
 Paper : https://arxiv.org/abs/2311.12397
Paper : https://arxiv.org/abs/2311.12397
Code : https://github.com/hridayK/Detection-of-AI-generated -images
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
AlphaFold 3 est lancé, prédisant de manière exhaustive les interactions et les structures des protéines et de toutes les molécules de la vie, avec une précision bien plus grande que jamais
Jul 16, 2024 am 12:08 AM
Editeur | Radis Skin Depuis la sortie du puissant AlphaFold2 en 2021, les scientifiques utilisent des modèles de prédiction de la structure des protéines pour cartographier diverses structures protéiques dans les cellules, découvrir des médicaments et dresser une « carte cosmique » de chaque interaction protéique connue. Tout à l'heure, Google DeepMind a publié le modèle AlphaFold3, capable d'effectuer des prédictions de structure conjointe pour des complexes comprenant des protéines, des acides nucléiques, de petites molécules, des ions et des résidus modifiés. La précision d’AlphaFold3 a été considérablement améliorée par rapport à de nombreux outils dédiés dans le passé (interaction protéine-ligand, interaction protéine-acide nucléique, prédiction anticorps-antigène). Cela montre qu’au sein d’un cadre unique et unifié d’apprentissage profond, il est possible de réaliser
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
 Iyo One : en partie casque, en partie ordinateur audio
Aug 08, 2024 am 01:03 AM
Iyo One : en partie casque, en partie ordinateur audio
Aug 08, 2024 am 01:03 AM
A tout moment, la concentration est une vertu. Auteur | Editeur Tang Yitao | Jing Yu La résurgence de l'intelligence artificielle a donné naissance à une nouvelle vague d'innovation matérielle. L’AIPin le plus populaire a rencontré des critiques négatives sans précédent. Marques Brownlee (MKBHD) l'a qualifié de pire produit qu'il ait jamais examiné ; David Pierce, rédacteur en chef de The Verge, a déclaré qu'il ne recommanderait à personne d'acheter cet appareil. Son concurrent, le RabbitR1, n'est guère mieux. Le plus grand doute à propos de cet appareil d'IA est qu'il ne s'agit évidemment que d'une application, mais Rabbit a construit un matériel de 200 $. De nombreuses personnes voient l’innovation matérielle en matière d’IA comme une opportunité de renverser l’ère des smartphones et de s’y consacrer.
 Quelles sont les dix principales plateformes de trading de devises virtuelles?
Feb 20, 2025 pm 02:15 PM
Quelles sont les dix principales plateformes de trading de devises virtuelles?
Feb 20, 2025 pm 02:15 PM
Avec la popularité des crypto-monnaies, des plateformes de trading de devises virtuelles ont émergé. Les dix principales plateformes de trading de devises virtuelles au monde sont classées comme suit selon le volume des transactions et la part de marché: Binance, Coinbase, FTX, Kucoin, Crypto.com, Kraken, Huobi, Gate.io, Bitfinex, Gemini. Ces plateformes offrent un large éventail de services, allant d'un large éventail de choix de crypto-monnaie à la négociation des dérivés, adapté aux commerçants de niveaux différents.
