
 Périphériques technologiques
IA
Reconstruction 3D de deux images en 2 secondes ! Cet outil d'IA est populaire sur GitHub, internautes : oubliez Sora
Périphériques technologiques
IA
Reconstruction 3D de deux images en 2 secondes ! Cet outil d'IA est populaire sur GitHub, internautes : oubliez Sora
Reconstruction 3D de deux images en 2 secondes ! Cet outil d'IA est populaire sur GitHub, internautes : oubliez Sora

Seulement 2 photos , pas besoin de mesurer de données supplémentaires -
Dangdang, un ours 3D complet est là :
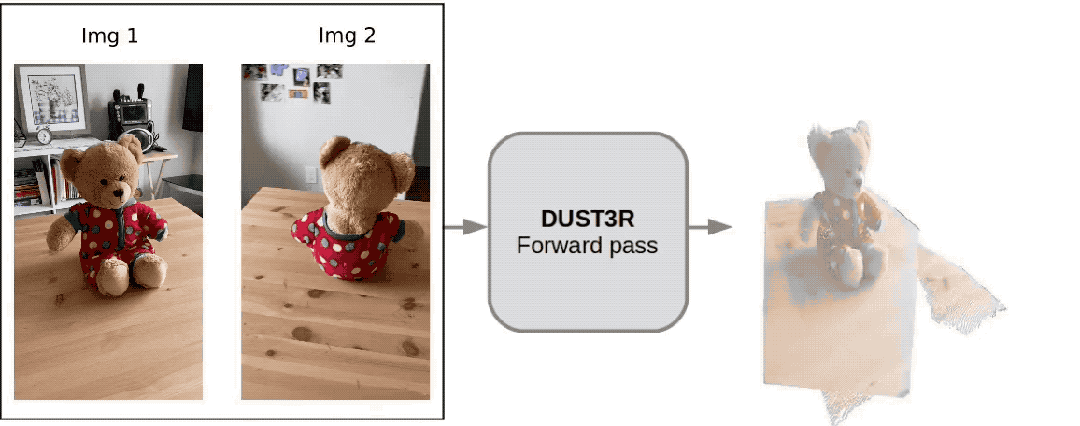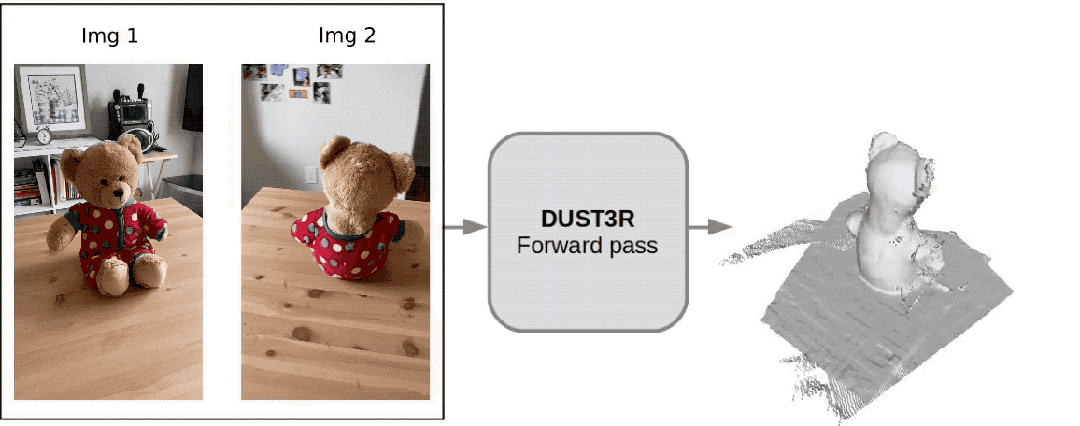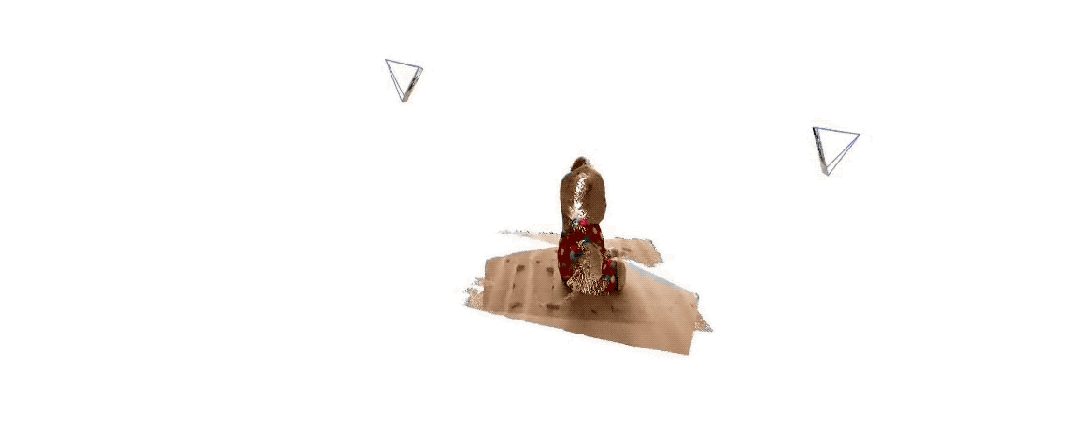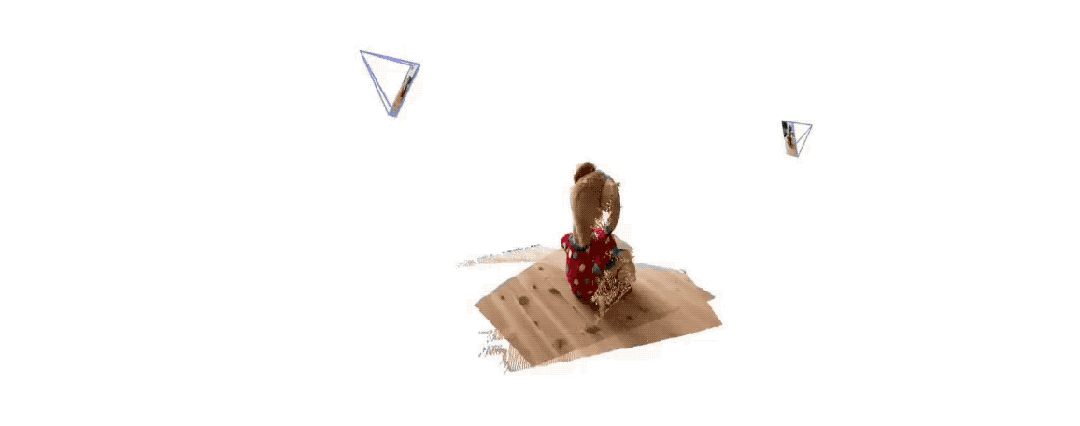
Ce nouvel outil appelé DUSt3R est très populaire, peu de temps après. a été lancé, il s'est classé deuxième sur la GitHub hot list.
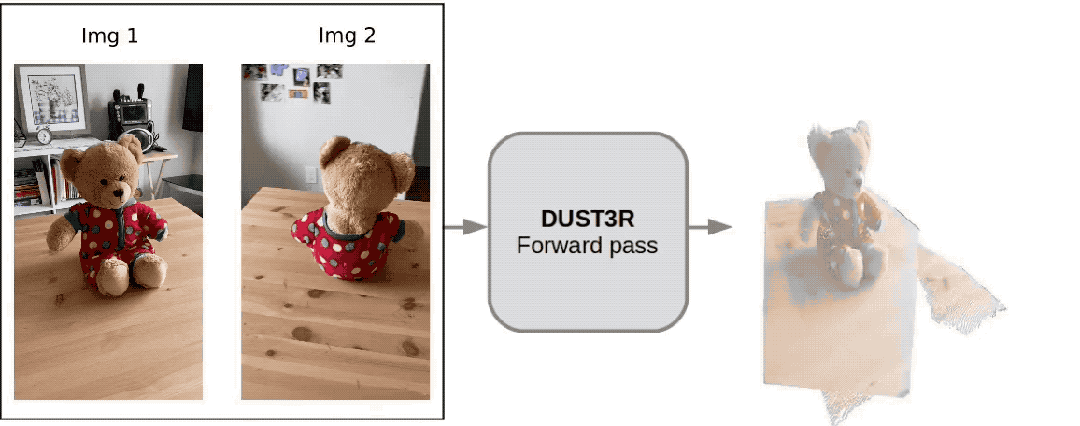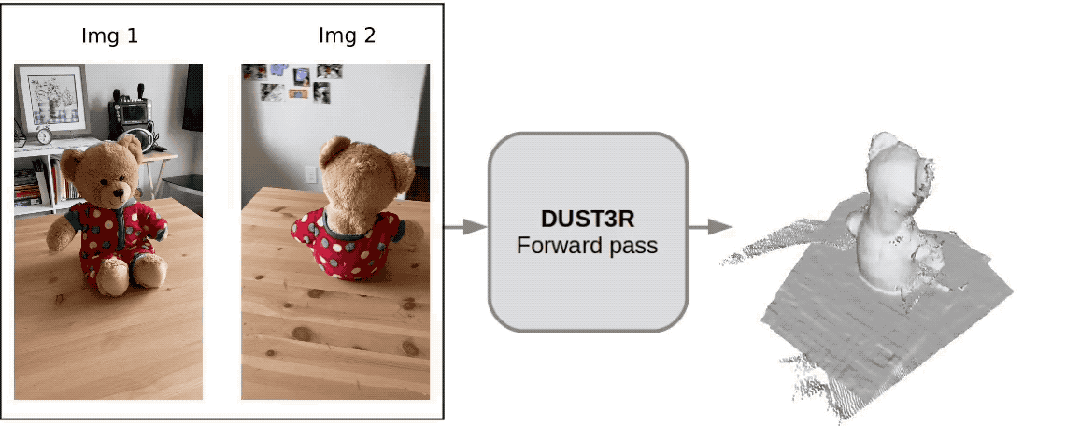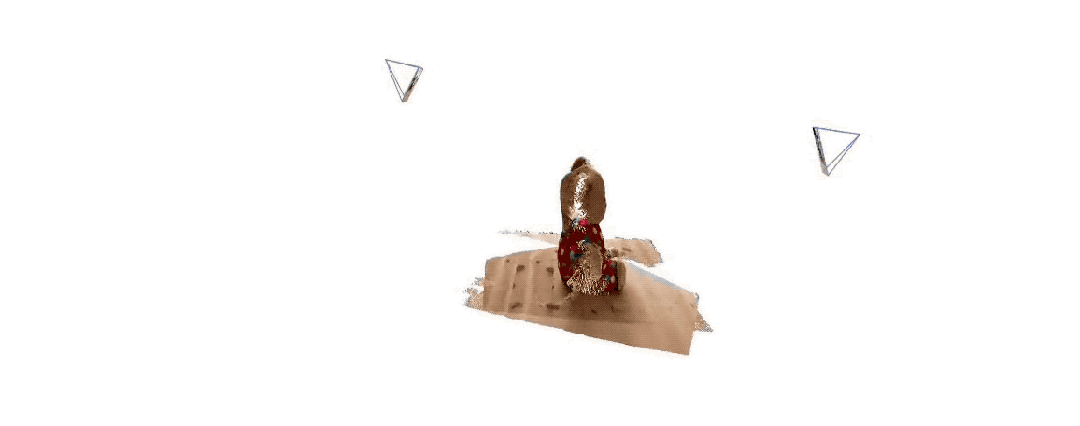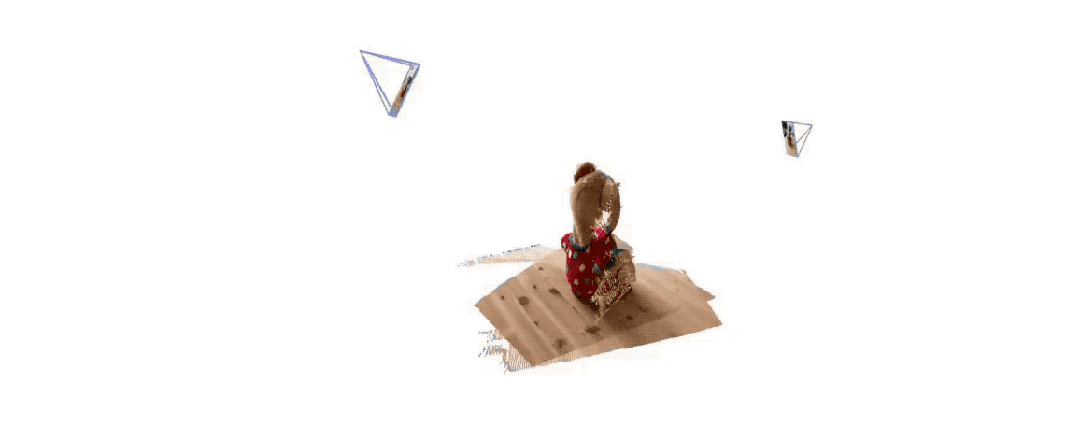
Un internaute a testé et a pris deux photos pour vraiment reconstituer sa cuisine. L'ensemble du processus a pris moins de 2 secondes !
(En plus des cartes 3D, il peut également fournir des cartes de profondeur, des cartes de confiance et des cartes de nuages de points)
Cet ami a été tellement choqué qu'il a dit :
Tout le mondeOubliez Sora d'abord Eh bien, c'est ce que nous pouvons vraiment voir et toucher.
Les expériences montrent que DUSt3R atteint SOTA dans les trois tâches d'estimation de la profondeur monoculaire/multi-vues et d'estimation de la pose relative.
L'équipe des auteurs (de l'Université Aalto, Finlande + branche européenne de l'Institut de recherche sur l'intelligence artificielle de NAVER LABS)Le « manifeste » de
est également plein d'élan :Nous voulons rendre le monde plus difficile à résoudre en vision 3D Tâches.Alors, comment ça se passe ? « tout-en-un »
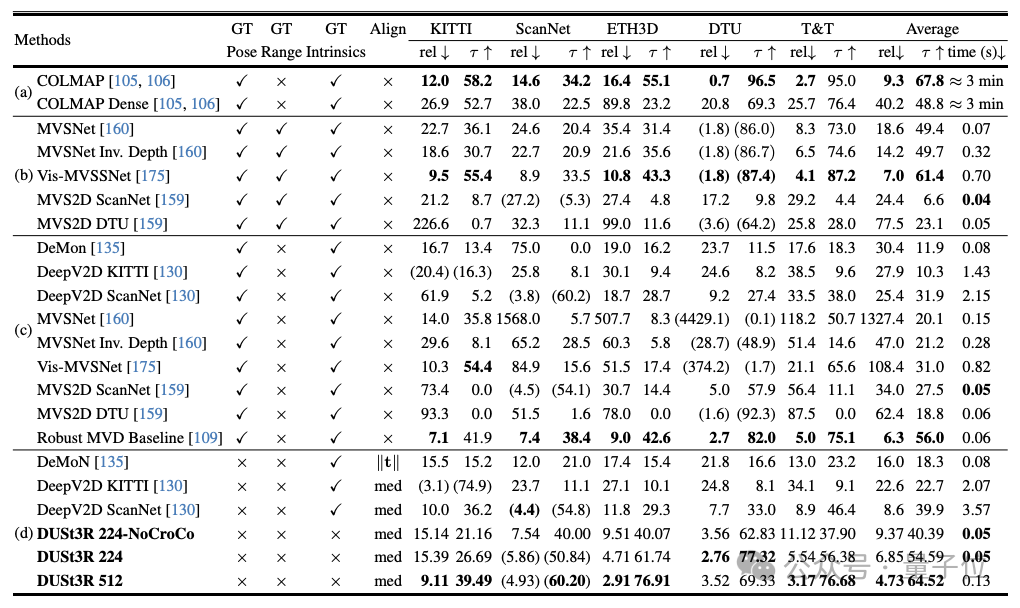
Pour la tâche de reconstruction stéréo multi-vues (MVS)
, la première étape consiste à estimer les paramètres de la caméra, y compris les paramètres internes et externes. Cette opération est ennuyeuse et fastidieuse, mais elle est indispensable pour la triangulation ultérieure des pixels dans l'espace tridimensionnel, et c'est une partie indissociable de presque tous les algorithmes MVS avec de meilleures performances. Dans l’étude de cet article, DUSt3R présenté par l’équipe de l’auteur a adopté une approche complètement différente.Ilne nécessite aucune information préalable sur l'étalonnage de la caméra ou la pose du point de vue
, et peut effectuer une reconstruction 3D dense ou sans contrainte d'images arbitraires. Ici, l'équipe formule le problème de reconstruction par paires sous forme de régression par points, unifiant les situations de reconstruction monoculaire et binoculaire. Lorsque plus de deux images d'entrée sont fournies, toutes les paires d'images de points sont représentées dans un cadre de référence commun grâce à une stratégie d'alignement globale simple et efficace. Comme le montre la figure ci-dessous, étant donné un ensemble de photos avec des poses de caméra et des caractéristiques intrinsèques inconnues, DUSt3R génère un ensemble correspondant de cartes de points, à partir desquelles nous pouvons directement récupérer diverses quantités géométriques qui sont généralement difficiles à estimer simultanément, telles que paramètres de la caméra, correspondance des pixels, carte de profondeur et effet de reconstruction 3D totalement cohérent.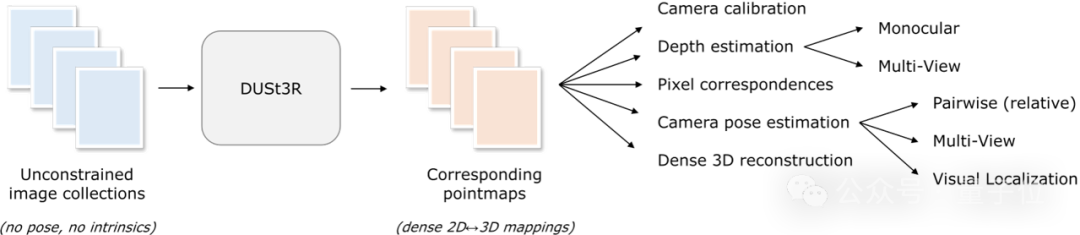
(L'auteur rappelle que DUSt3R convient également pour une image à entrée unique)
En termes d'architecture réseau spécifique, DUSt3R est basé sur le encodeur et décodeur standard Transformer, qui a été influencé par CroCo (via cross Une étude sur la pré-entraînement auto-supervisée aux tâches de vision 3D s'est inspirée de
et a été entraînée à l'aide d'une simple perte de régression.Comme indiqué ci-dessous, les deux vues (I1, I2) de la scène sont d'abord encodées à la manière siamoise à l'aide de l'encodeur ViT partagé.
La représentation symbolique résultante (F1 et F2) est ensuite transmise à deux décodeurs Transformer, qui échangent continuellement des informations par attention croisée.
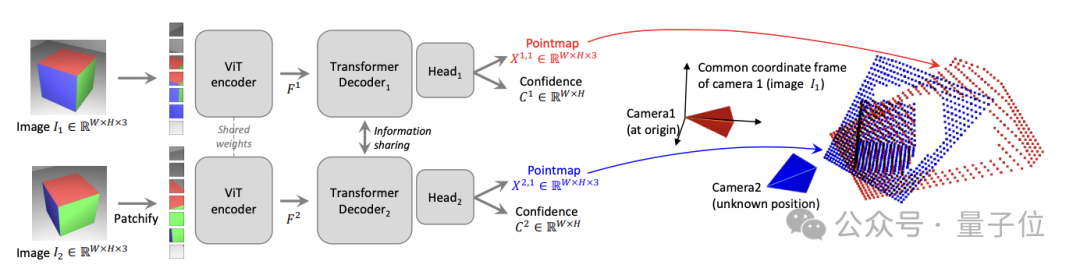
Enfin, les deux têtes de régression génèrent deux cartes de points correspondantes et des cartes de confiance associées.
Le point clé est que les deux tracés de points doivent être représentés dans le même système de coordonnées de la première image.
Plusieurs tâches ont été récompensées par SOTA
L'expérience a d'abord évalué les performances de DUSt3R sur la tâche d'estimation de pose absolue sur les ensembles de données 7Scenes (7 scènes d'intérieur) et Cambridge Landmarks (8 scènes d'extérieur) . Les indicateurs sont les erreurs de traduction et. rotation. Erreur (plus la valeur est petite, mieux c'est) .
L'auteur a déclaré que par rapport à d'autres méthodes existantes de correspondance de fonctionnalités et de bout en bout, les performances de DUSt3R sont remarquables.
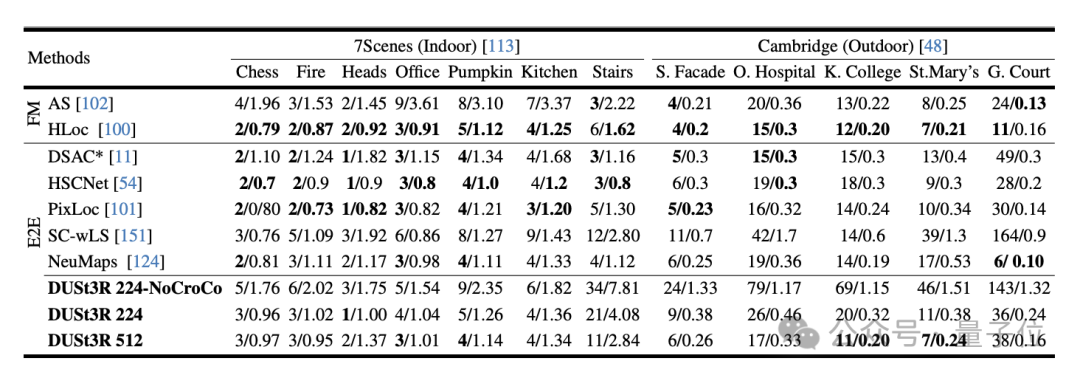
Parce que d'une part, il n'a jamais reçu de formation en positionnement visuel, et d'autre part, il n'a pas rencontré d'images de requête ni d'images de base de données pendant le processus de formation.
Deuxièmement, la tâche de régression de pose multi-vues est effectuée sur 10 images aléatoires. Résultats DUST3R a obtenu les meilleurs résultats sur les deux ensembles de données.
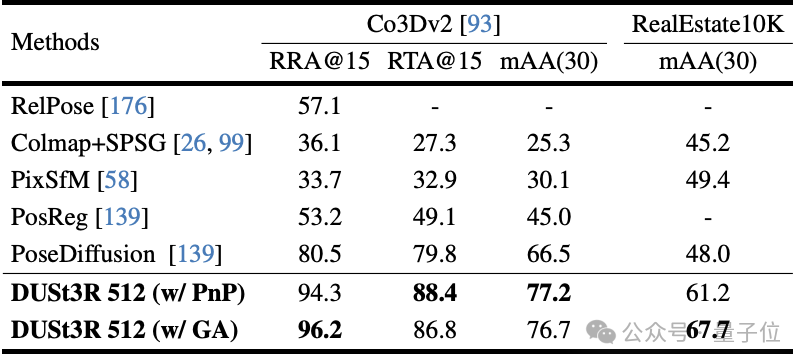
Sur la tâche d'estimation de profondeur monoculaire, DUSt3R peut également bien gérer les scènes intérieures et extérieures, avec des performances meilleures que les lignes de base auto-supervisées et à égalité avec les lignes de base supervisées les plus avancées.
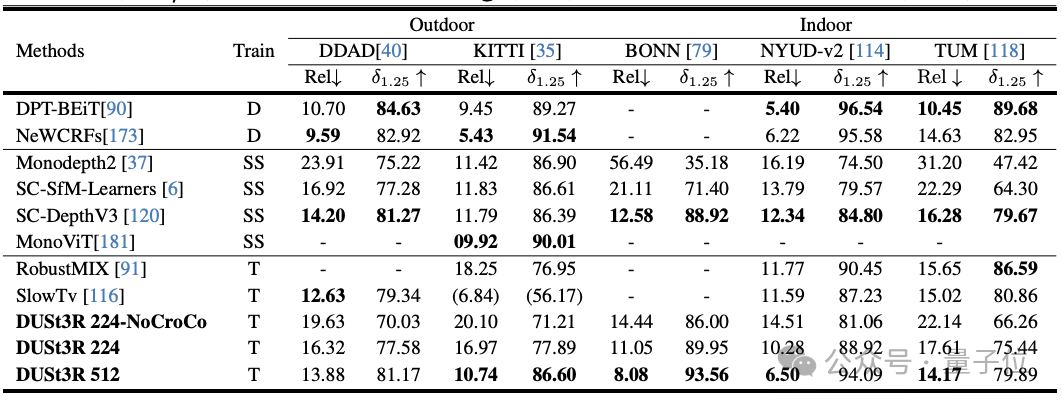
DUST3R fonctionne également bien dans l'estimation de la profondeur multi-vues.
Voici les effets de reconstruction 3D donnés par les deux groupes Pour vous donner une idée, ils n'ont saisi que deux images :
(1)

(2)

Netizen Actual. mesure : Ce n'est pas grave si les deux images ne se chevauchent pas. Un internaute a donné à DUSt3R deux images sans aucun contenu qui se chevauche. En conséquence, il a également produit une vue 3D précise en quelques secondes :

 En réponse, certains internautes ont dit que cela signifie que cette méthode n'y fait pas de "mesures objectives", mais se comporte plutôt comme une IA.
En réponse, certains internautes ont dit que cela signifie que cette méthode n'y fait pas de "mesures objectives", mais se comporte plutôt comme une IA.
 De plus, certaines personnes sont curieuses
De plus, certaines personnes sont curieuses
? Certains internautes l'ont essayé, et la réponse est
oui!
[1] Article https://arxiv.org/abs/2312.14132
[2] Code https://github.com/naver/dust3r
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1662
1662
 14
1419
52
1313
25
1262
29
1235
24
14
1419
52
1313
25
1262
29
1235
24

 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
