
 Périphériques technologiques
IA
ADMap : une nouvelle idée pour des cartes en ligne de haute précision anti-interférences
Périphériques technologiques
IA
ADMap : une nouvelle idée pour des cartes en ligne de haute précision anti-interférences
ADMap : une nouvelle idée pour des cartes en ligne de haute précision anti-interférences

Écrit devant & compréhension personnelle de l'auteur
Je suis très heureux d'être invité à participer à l'événement Heart of Autonomous Driving Nous partagerons la méthode anti-perturbation ADMap pour la reconstruction en ligne de cartes vectorisées de haute précision. Vous pouvez trouver notre code sur https://github.com/hht1996ok/ADMap. Merci à tous pour votre attention et votre soutien.
Dans le domaine de la conduite autonome, la reconstruction de cartes haute définition en ligne revêt une grande importance pour les tâches de planification et de prévision. Des travaux récents ont permis de créer de nombreux modèles de reconstruction de cartes haute définition hautes performances pour répondre à ce besoin. Cependant, l'ordre des points au sein de l'instance vectorisée peut être instable ou irrégulier en raison d'écarts de prédiction, affectant ainsi les tâches ultérieures. Par conséquent, nous proposons le cadre de reconstruction de carte anti-perturbation (ADMap). Cet article espère prendre en compte la vitesse du modèle et la précision globale, et ne pas déranger les ingénieurs lors du déploiement. Par conséquent, trois modules efficients et efficaces sont proposés : Multi-Scale Perception Neck (MPN), Instance Interactive Attention (IIA) et Vector Direction Difference Loss (VDDL). En explorant en cascade les relations entre les ordres de points et au sein des instances, notre modèle supervise mieux le processus de prédiction de l'ordre des points.
Nous avons vérifié l'efficacité d'ADMap dans les ensembles de données nuScenes et Argoverse2. Les résultats expérimentaux montrent qu'ADMap présente les meilleures performances dans divers tests de référence. Dans le benchmark nuScenes, ADMap améliore mAP de 4,2 % et 5,5 % par rapport à la référence en utilisant uniquement les données de la caméra et les données multimodales, respectivement. ADMapv2 réduit non seulement la latence d'inférence, mais améliore également considérablement les performances de base, le mAP le plus élevé atteignant 82,8 %. Dans l'ensemble de données Argoverse, le mAP d'ADMapv2 a augmenté à 62,9 % tandis que la fréquence d'images est restée à 14,8 FPS.
En résumé, l'ADMap que nous avons proposé a les principales contributions suivantes :
- Proposition d'un ADMap de bout en bout et reconstruction d'une carte vectorisée de haute précision plus stable.
- MPN capture mieux les informations multi-échelles sans augmenter les ressources de raisonnement. IIA réalise une interaction efficace entre les instances et au sein des instances, ce qui rend les caractéristiques au niveau des points plus précises et contraint le processus de reconstruction des séquences de points de manière plus détaillée. .
- ADMap permet la reconstruction en temps réel de cartes vectorisées de haute précision et atteint la plus haute précision dans le benchmark nuScenes et Argoverse2. La méthode
est proposée
Comme le montre la figure 1, les points de prédiction dans l'instance tremblent ou se décalent souvent inévitablement. Cette gigue rendra le vecteur d'instance reconstruit inégal ou irrégulier, affectant sérieusement la qualité et l'aspect pratique de. cartes en ligne de haute précision. Nous pensons que la raison est que les modèles existants ne prennent pas pleinement en compte l'interaction entre les instances et au sein des instances. Une interaction incomplète entre les points d'instance et les informations topologiques de la carte entraînera des positions prédites inexactes. De plus, seule une supervision telle que la perte L1 et la perte d'intégration du cosinus ne peut pas utiliser efficacement les relations géométriques pour contraindre le processus de prédiction des points d'instance. Le réseau doit utiliser des segments de lignes vectorielles entre les points pour capturer avec plus de précision les informations de direction de la séquence de points. contraindre chaque point du processus de prédiction.
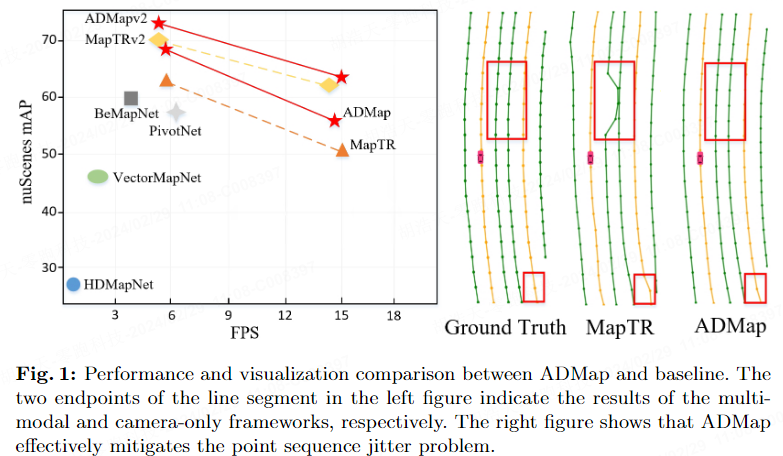
Afin d'atténuer les problèmes ci-dessus, nous avons proposé de manière innovante le cadre de reconstruction de carte anti-perturbation (ADMap) pour réaliser une reconstruction stable et en temps réel de cartes vectorisées de haute précision.
Conception de la méthode
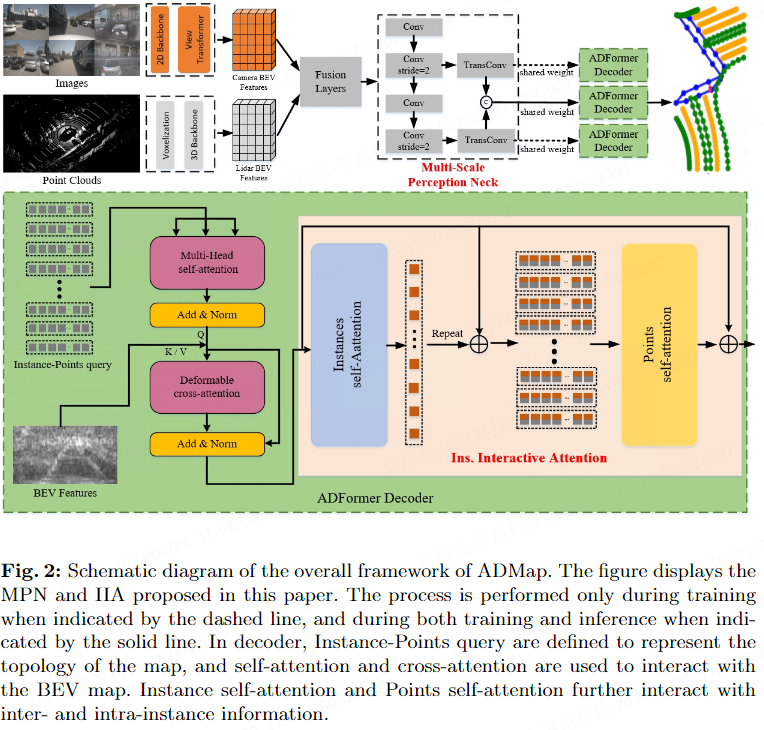
Comme le montre la figure 2, ADMap utilise le cou de perception à plusieurs échelles (MPN), l'attention interactive d'instance (IIA) et la perte de différence de direction vectorielle (perte de différence de direction vectorielle, VDDL) pour prédire l'ordre des points. topologie plus précisément. MPN, IIA et VDDL seront présentés respectivement ci-dessous.
Multi-Scale Perception Neck
Pour obtenir des fonctionnalités BEV plus détaillées, nous introduisons le Multi-Scale Perception Neck (MPN). MPN reçoit les fonctionnalités BEV fusionnées en entrée. Grâce au sous-échantillonnage, les caractéristiques BEV de chaque niveau sont connectées à une couche de suréchantillonnage pour restaurer la carte des caractéristiques de taille d'origine. Enfin, les cartes de fonctionnalités à chaque niveau seront fusionnées en fonctionnalités BEV multi-échelles.
Comme le montre la figure 2, la ligne pointillée représente que cette étape n'est mise en œuvre que pendant la formation, et la ligne continue représente que cette étape est mise en œuvre pendant les processus de formation et d'inférence. Au cours du processus de formation, des cartes de fonctionnalités BEV multi-échelles et des cartes de fonctionnalités BEV à chaque niveau sont envoyées au Transformer Decoder, ce qui permet au réseau de prédire les informations d'instance de la scène à différentes échelles pour capturer des fonctionnalités multi-échelles plus raffinées. Pendant le processus d'inférence, MPN conserve uniquement les caractéristiques BEV multi-échelles et ne génère pas de cartes de caractéristiques à chaque niveau. Cela garantit que l'utilisation des ressources du cou pendant l'inférence reste inchangée.
Transformer Decoder
Transformer Decoder définit un ensemble de requêtes au niveau de l'instance et un ensemble de requêtes au niveau du point. Les requêtes au niveau du point sont ensuite partagées avec toutes les instances. Ces requêtes hiérarchiques sont définies comme :
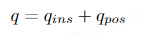
Le décodeur se compose de plusieurs couches de décodage en cascade qui mettent à jour de manière itérative la requête hiérarchique. Dans chaque couche de décodage, des requêtes hiérarchiques sont entrées dans le mécanisme d'auto-attention, ce qui permet d'échanger des informations entre les requêtes hiérarchiques. L'attention déformable est utilisée pour interagir avec les requêtes hiérarchiques et les fonctionnalités BEV multi-échelles.
Instance Interactive Attention
Afin de mieux obtenir les caractéristiques de chaque instance dans l'étape de décodage, nous avons proposé l'Instance Interactive Attention (IIA), qui comprend l'auto-attention des instances et l'auto-attention des points. Contrairement à MapTRv2 qui extrait en parallèle les intégrations au niveau de l'instance et au niveau du point, IIA extrait les intégrations de requêtes en cascade. Les interactions de fonctionnalités entre les intégrations d'instances aident en outre le réseau à apprendre les relations entre les intégrations au niveau du point.
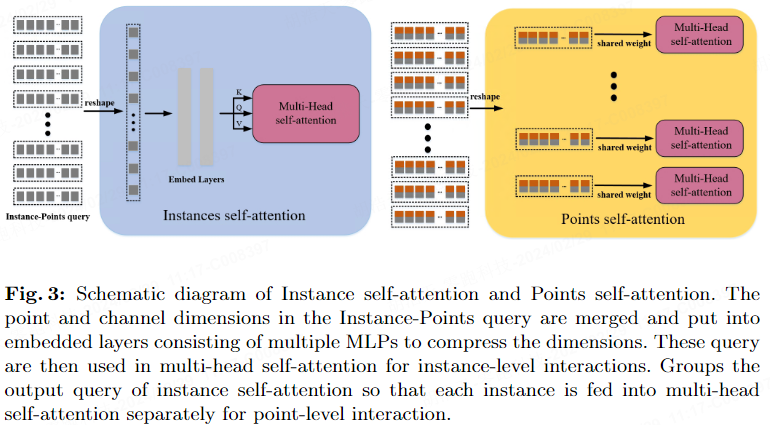
Comme le montre la figure 3, les intégrations hiérarchiques produites par l'attention croisée déformable sont entrées dans l'auto-attention des instances. Après avoir fusionné la dimension de point et la dimension de canal, la transformation de dimension est effectuée. Par la suite, l'intégration hiérarchique est connectée à la couche d'intégration composée de plusieurs MLP pour obtenir la requête d'instance. La requête est placée dans l'auto-attention multi-têtes pour capturer la relation topologique entre les instances et obtenir l'intégration d'instance. Pour incorporer des informations au niveau de l'instance dans des intégrations au niveau du point, nous additionnons les intégrations d'instance et les intégrations hiérarchiques. Les fonctionnalités ajoutées sont entrées dans Point self-attention, qui interagit avec les fonctionnalités ponctuelles de chaque instance pour corréler plus finement les relations topologiques entre les séquences de points.
Perte de différence de direction vectorielle
La carte de haute précision contient des éléments de carte statiques vectorisés, notamment des lignes de voies, des bordures et des passages pour piétons. ADMap propose une perte de différence de direction vectorielle pour ces formes ouvertes (lignes de voie, bordures) et fermées (passages pour piétons). Nous modélisons la direction du vecteur de séquence de points à l'intérieur de l'instance, et la direction du point peut être surveillée plus en détail par la différence entre la direction du vecteur prédite et la direction du vecteur réel. De plus, les points présentant de grandes différences dans les directions vectorielles réelles sont considérés comme représentant des changements drastiques dans la topologie de certaines scènes (plus difficiles à prédire) et nécessitent plus d'attention de la part du modèle. Par conséquent, les points présentant des différences de direction vectorielles réelles plus importantes reçoivent un poids plus important afin de garantir que le réseau puisse prédire avec précision ce point de changement radical.

La figure 4 montre la modélisation initiale de la ligne vectorielle prédite { et de la vraie ligne vectorielle { dans la séquence de points prédite { et la séquence de points vraie { ). Afin de garantir que les angles opposés n'obtiennent pas la même perte, nous calculons le cosinus de la différence d'angle de la ligne vectorielle θ' :
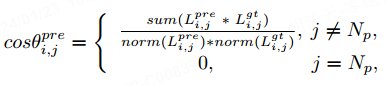
où la fonction accumule la position des coordonnées de la ligne vectorielle, représentant l'opération de normalisation. . Nous utilisons la différence d'angle vectorielle de chaque point dans l'instance réelle pour leur attribuer des poids de différentes tailles. Le poids est défini comme suit :
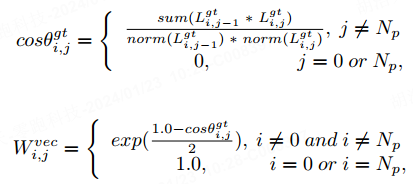
, qui représente le nombre de points dans l'instance, et la fonction représente la fonction exponentielle de base e. Étant donné que la différence d'angle vectoriel ne peut pas être calculée entre le premier et le dernier point, nous définissons le poids du premier et du dernier point sur 1. Lorsque la différence d'angle vectoriel dans la vérité terrain devient plus grande, nous accordons à ce point un poids plus important, ce qui incite le réseau à accorder plus d'attention aux changements significatifs de la topologie de la carte. La perte de différence d'angle de chaque point de la séquence de points est définie comme :
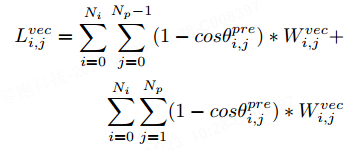
Nous utilisons θ pour ajuster l'intervalle de la valeur de perte à [0,0, 2,0]. En ajoutant les cosinus des différences d'angle entre les lignes vectorielles adjacentes en chaque point, cette perte couvre de manière plus complète les informations de topologie géométrique de chaque point. Étant donné que les deux premier et dernier points n’ont qu’une seule ligne vectorielle adjacente, la perte du premier et des deux derniers points est le cosinus de la différence d’angle vectorielle unique.
Expérience
Pour une évaluation équitable, nous divisons les éléments de la carte en trois types : les lignes de voie, les limites de route et les passages pour piétons. La précision moyenne (AP) est utilisée pour évaluer la qualité de la construction de la carte, et la somme des distances de chanfrein entre l'ordre des points prédit et l'ordre réel des points est utilisée pour déterminer si les deux correspondent. Le seuil de distance du chanfrein est fixé à [0,5, 1,0, 1,5], nous calculons AP sous ces trois seuils respectivement et utilisons la moyenne comme indicateur final.
Expérience comparative
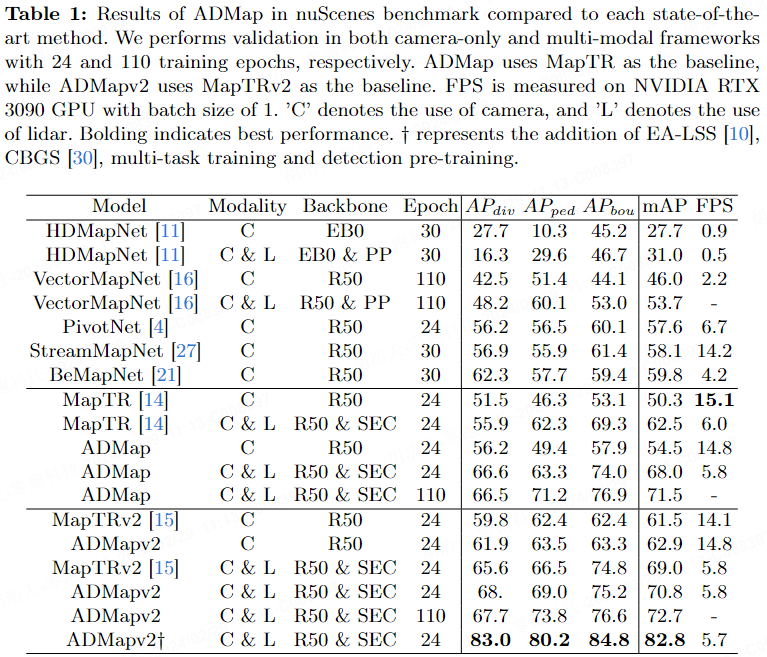
Le Tableau 1 présente les métriques d'ADMap et les méthodes de pointe sur l'ensemble de données nuScenes. Dans le cadre de la caméra uniquement, le mAP d'ADMap a augmenté de 5,5 % par rapport à la référence (MapTR) et ADMapv2 a augmenté de 1,4 % par rapport à la référence (MapTRv2). ADMapv2 a un mAP maximum de 82,8 %, atteignant les meilleures performances parmi les benchmarks actuels. Certains détails seront annoncés dans les versions ultérieures d'arxiv. En termes de vitesse, ADMap améliore considérablement les performances du modèle par rapport à sa référence avec un FPS légèrement inférieur. Il convient de mentionner qu'ADMapv2 améliore non seulement les performances, mais améliore également la vitesse d'inférence du modèle.
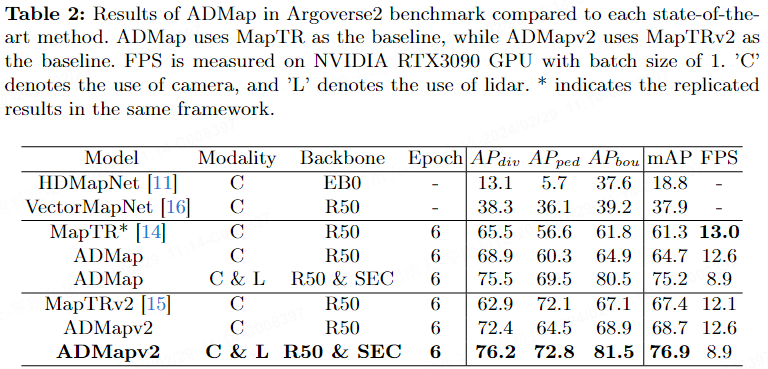
Le tableau 2 rapporte les métriques d'ADMap et les méthodes de pointe dans Argoverse2. Dans le cadre de la caméra uniquement, ADMap et ADMapv2 se sont améliorés respectivement de 3,4 % et 1,3 % par rapport à la référence. Dans le cadre multimodal, ADMap et ADMapv2 ont obtenu les meilleures performances, avec mAP de 75,2 % et 76,9 % respectivement. En termes de vitesse. ADMapv2 amélioré de 11,4 ms par rapport à MapTRv2.
Expériences d'ablation
Dans le tableau 3, nous fournissons des expériences d'ablation pour chaque module d'ADMap sur le benchmark nuScenes.
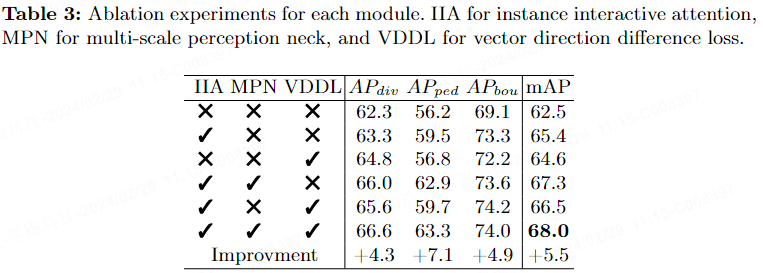
Le tableau 4 montre l'impact de l'insertion de différents mécanismes d'attention sur la performance finale. DSA signifie attention personnelle découplée, et IIA signifie attention interactive. Les résultats montrent que l'IIA améliore le mAP de 1,3 % par rapport au DSA.
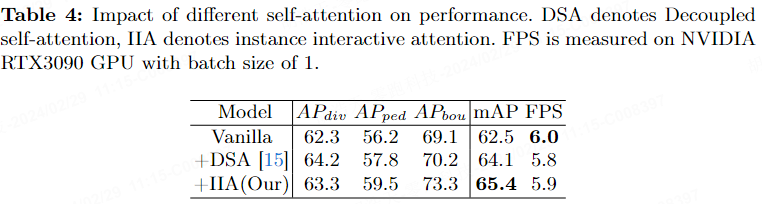
Le tableau 5 rapporte l'impact de l'ajout de couches de colonne vertébrale et de cou sur mAP après la fusion des fonctionnalités. Après avoir ajouté les couches de colonne vertébrale et de cou basées sur SECOND, mAP a augmenté de 1,2 %. Après avoir ajouté MPN, le mAP du modèle a augmenté de 2,0 % sans augmenter le temps d'inférence.
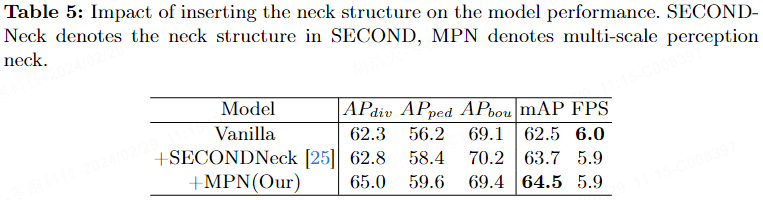
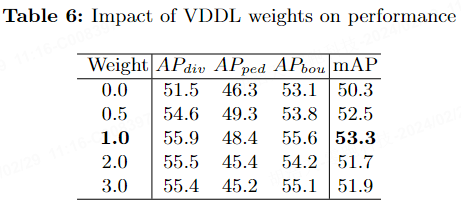
Le tableau 6 indique l'impact sur les performances de l'ajout de VDDL dans le benchmark nuScenes. On peut voir que lorsque le poids est fixé à 1,0, mAP est le plus élevé, atteignant 53,3 %.
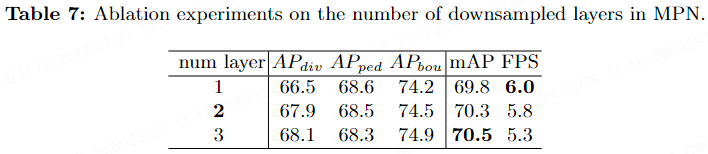
Le tableau 7 rapporte l'impact du nombre de couches de sous-échantillonnage MPN sur les performances finales dans le benchmark nuScenes. Plus il y a de couches de sous-échantillonnage, plus la vitesse d'inférence du modèle est lente. Par conséquent, pour équilibrer vitesse et performances, nous avons fixé le nombre de couches de sous-échantillonnage à 2.
Afin de vérifier qu'ADMap atténue efficacement le problème de perturbation de l'ordre des points, nous avons proposé la distance moyenne de chanfrein (ACE). Nous avons sélectionné les instances prédites dont la somme des distances de chanfrein est inférieure à 1,5 et calculé leur distance de chanfrein moyenne (ACE). Plus l'ACE est petit, plus la prédiction de l'ordre des points d'instance est précise. Le tableau 8 prouve qu'ADMap peut atténuer efficacement le problème de perturbation des nuages de points.

Résultats de visualisation
Les deux images suivantes montrent les résultats de visualisation de l'ensemble de données nuScenes et de l'ensemble de données Argoverse2.
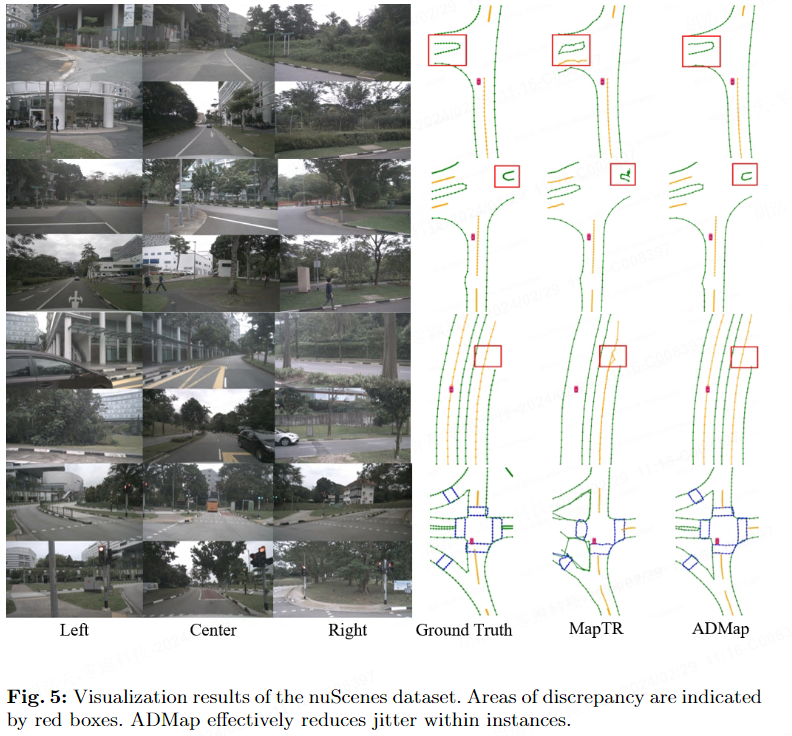
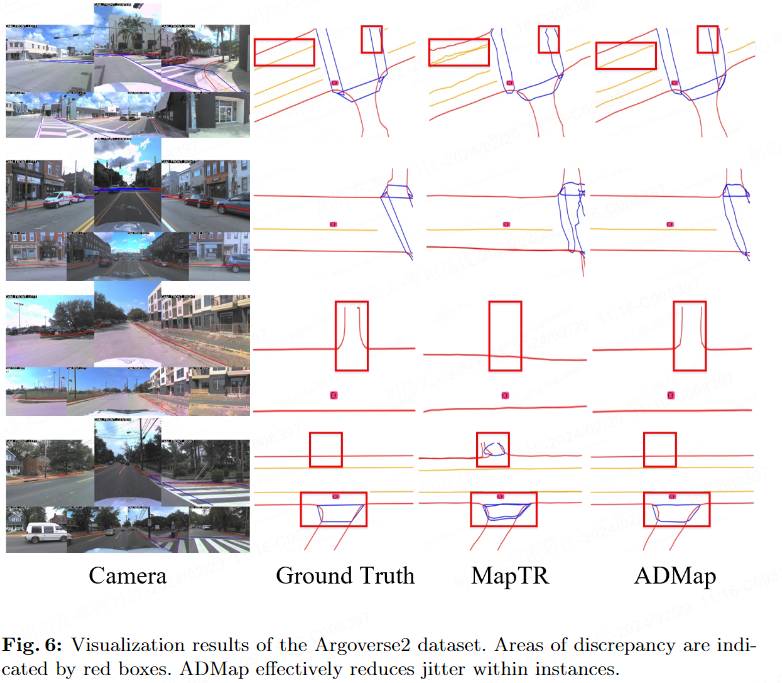
Résumé
ADMap est un cadre de reconstruction de carte vectorisée de haute précision efficace et efficient, qui atténue efficacement le phénomène de gigue ou d'irrégularité qui peut se produire dans l'ordre des vecteurs d'instance en raison d'un biais de prédiction. Des expériences approfondies montrent que la méthode proposée permet d'obtenir les meilleures performances sur les benchmarks nuScenes et Argoverse2. Nous pensons qu'ADMap contribuera à faire progresser la recherche sur les tâches de reconstruction de cartes vectorielles de haute précision, favorisant ainsi mieux le développement de la conduite autonome et d'autres domaines.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
