
 Périphériques technologiques
IA
Cartes graphiques grand public disponibles ! Li Kaifu a publié et open source le modèle Yi à 9 milliards de paramètres, qui possède la capacité mathématique de code la plus forte de l'histoire.
Périphériques technologiques
IA
Cartes graphiques grand public disponibles ! Li Kaifu a publié et open source le modèle Yi à 9 milliards de paramètres, qui possède la capacité mathématique de code la plus forte de l'histoire.
Cartes graphiques grand public disponibles ! Li Kaifu a publié et open source le modèle Yi à 9 milliards de paramètres, qui possède la capacité mathématique de code la plus forte de l'histoire.

La société d'IA de Kai-Fu Lee, Zero One, a un autre grand acteur modèle sur la scène :
9 milliards de paramètres Yi-9B.
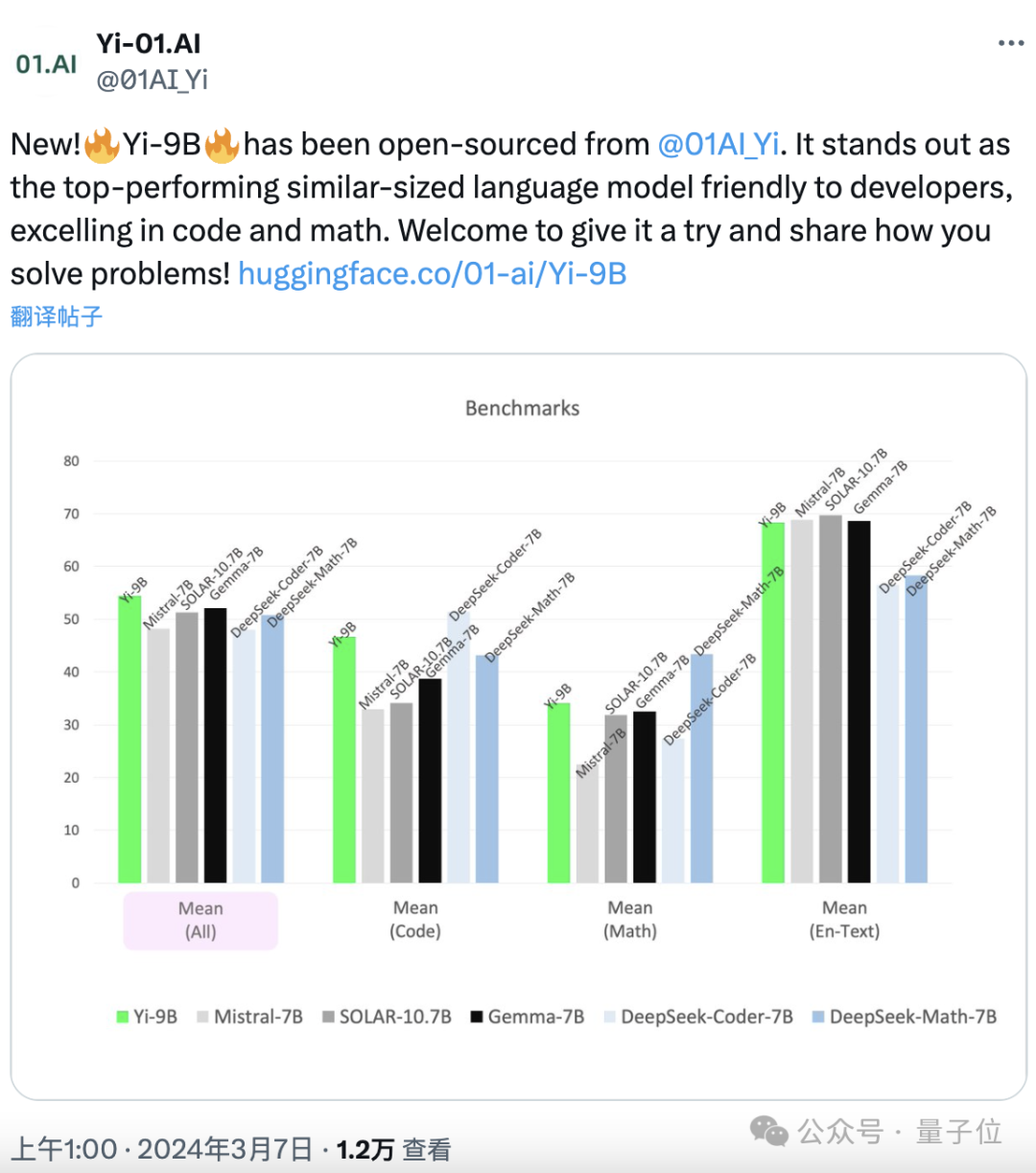
Il est connu comme le "Champion scientifique" dans la série Yi. Il "compense" les mathématiques codées sans prendre de retard en termes de capacité globale.
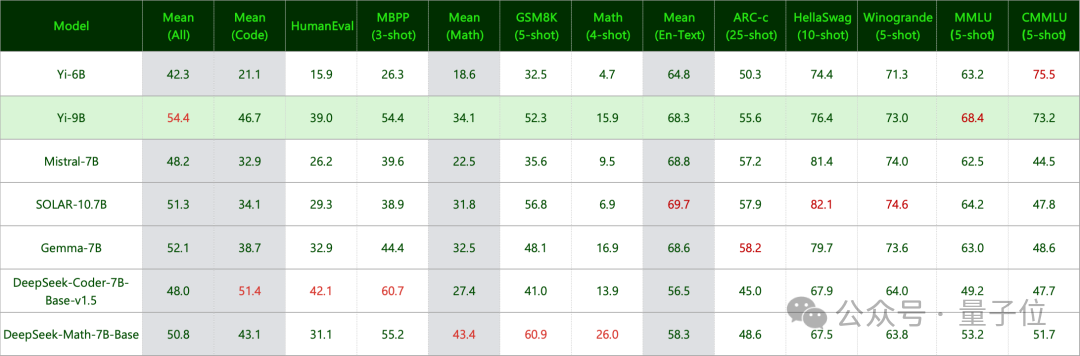
Fonctionne le mieux parmi une série de modèles open source d'échelle similaire (notamment Mistral-7B, SOLAR-10.7B, Gemma-7B, DeepSeek-Coder-7B-Base-v1.5, etc.) .
Ancienne règle, la version est open source, particulièrement conviviale pour les développeurs :
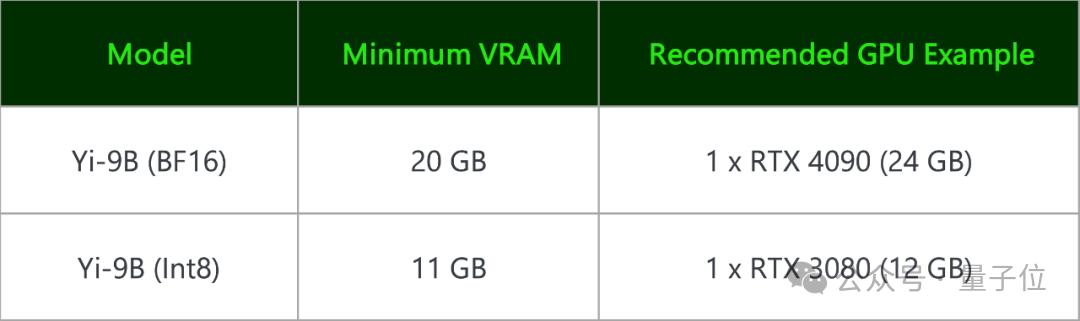
Yi-9B (BF 16) et sa version quantifiée Yi-9B (Int8) peuvent être déployées sur des cartes graphiques grand public.
Une RTX 4090 ou une RTX 3090 suffisent.
Amplification profonde + entraînement incrémentiel en plusieurs étapes
La famille Yi de Zero One Thousand Things a déjà publié les séries Yi-6B et Yi-34B.
Tous deux ont été pré-entraînés sur les données chinoises et anglaises du jeton 3,1T, et Yi-9B a été formé sur cette base en ajoutant le jeton 0,8T.
La date limite pour les données est le juin 2023.
Il a été mentionné au début que la plus grande amélioration du Yi-9B réside dans les mathématiques et le codage, alors comment améliorer ces deux capacités ?
Introduction à Zéro Mille Choses :
Le simple fait d'augmenter la quantité de données ne peut pas répondre aux attentes.
repose sur d'abord en augmentant la taille du modèle à 9B sur la base de Yi-6B, puis en effectuant un entraînement incrémentiel de données en plusieurs étapes .
Tout d'abord, comment augmenter la taille du modèle ?
Une prémisse est que l'équipe a découvert grâce à l'analyse :
Yi-6B a été entièrement entraîné, et l'effet d'entraînement peut ne pas être amélioré, quel que soit le nombre de jetons ajoutés, il est donc envisagé d'augmenter sa taille. (L'unité sur la photo ci-dessous n'est pas TB mais B)

Comment l'augmenter ? La réponse est amplification profonde.
Introduction à Zero One Thousand Things :
L'expansion de la largeur du modèle d'origine entraînera davantage de pertes de performances. Après l'amplification en profondeur du modèle en sélectionnant une couche appropriée, le cosinus d'entrée/sortie de la nouvelle couche sera plus proche de 1,0. , c'est-à-dire que plus les performances du modèle amplifié peuvent maintenir les performances du modèle d'origine, plus la perte de performances du modèle sera faible.
Selon cette idée, Zero Yiwu a choisi de copier les 16 couches relativement arrière (couches 12-28) du Yi-6B pour former le Yi-9B à 48 couches.
Les expériences montrent que cette méthode a de meilleures performances que l'utilisation du modèle Solar-10.7B pour copier les 16 couches centrales (8-24 couches) .
Deuxièmement, quelle est la méthode de formation en plusieurs étapes ?
La réponse est d'ajouter d'abord des données 0,4T contenant du texte et du code, mais le rapport de données est le même que celui de Yi-6B.
Ajoutez ensuite 0,4 T supplémentaire de données, qui incluent également du texte et du code, mais se concentrent sur l'augmentation de la proportion de code et de données mathématiques.
(Entendu, c'est la même chose que notre astuce « penser étape par étape » pour poser des questions sur les grands modèles)
Une fois ces deux étapes terminées, l'équipe se réfère toujours à deux articles (An Empirical Model of Large- Formation par lots et ne diminuez pas le taux d'apprentissage, augmentez la taille du lot) et optimisation de la méthode d'ajustement des paramètres.
C'est-à-dire qu'à partir d'un taux d'apprentissage fixe, chaque fois que la perte du modèle cesse de diminuer, la taille du lot augmente afin que le déclin soit ininterrompu et que le modèle apprenne plus complètement.
Au final, Yi-9B contenait en réalité un total de 8,8 milliards de paramètres, atteignant une longueur de contexte de 4k.
La série Yi possède les capacités de codage et mathématiques les plus puissantes
Dans les tests réels, Zero Yiwu a utilisé la méthode de génération de décodage gourmande (c'est-à-dire en sélectionnant le mot avec la valeur de probabilité la plus élevée à chaque fois) pour les tests.
Les modèles participants sont DeepSeek-Coder, DeepSeek-Math, Mistral-7B, SOLAR-10.7B et Gemma-7B :
(1)DeepSeek-Coder, d'une société nationale de recherche approfondie, ses instructions 33B L'évaluation humaine de la version optimisée dépasse GPT-3.5-turbo, et les performances de la version 7B peuvent atteindre les performances de CodeLlama-34B.
DeepSeek-Math s'appuie sur des paramètres 7B pour renverser GPT-4, choquant toute la communauté open source.
(2)SOLAR-10.7BUpstage AI de Corée du Sud, née en décembre 2023, surpasse Mixtral-8x7B-Instruct en performances.
(3)Mistral-7B est le premier grand modèle open source MoE, atteignant voire dépassant le niveau de Llama 2 70B et GPT-3.5.
(4)Gemma-7BDe Google, Zero One Wanwu a souligné :
La quantité de paramètres efficaces est en fait au même niveau que Yi-9B.
(Les normes de dénomination des deux sont différentes. Le premier utilise uniquement des paramètres de non-intégration, tandis que le second utilise tous les paramètres et les arrondit)
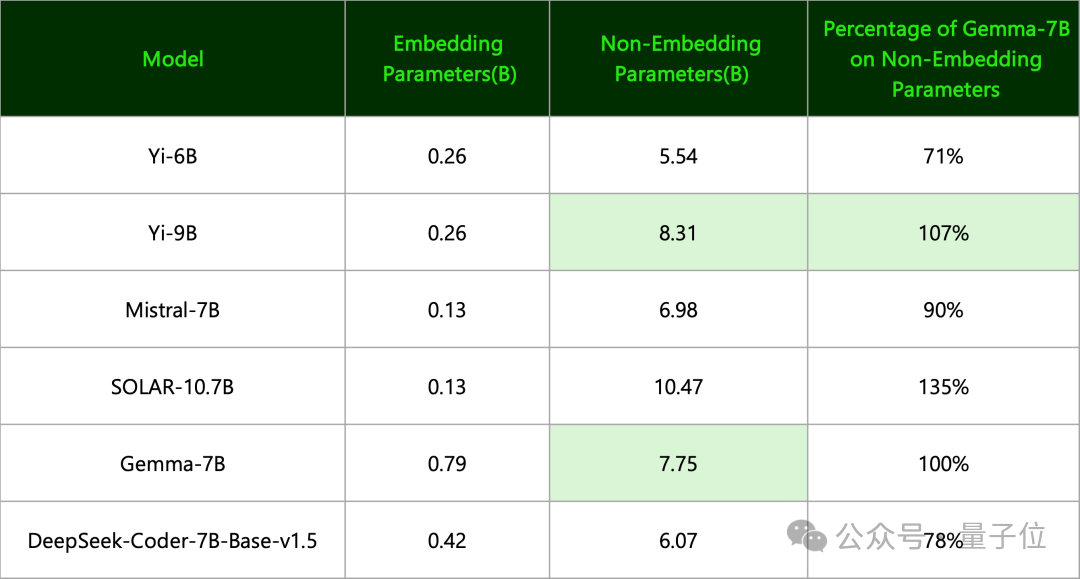
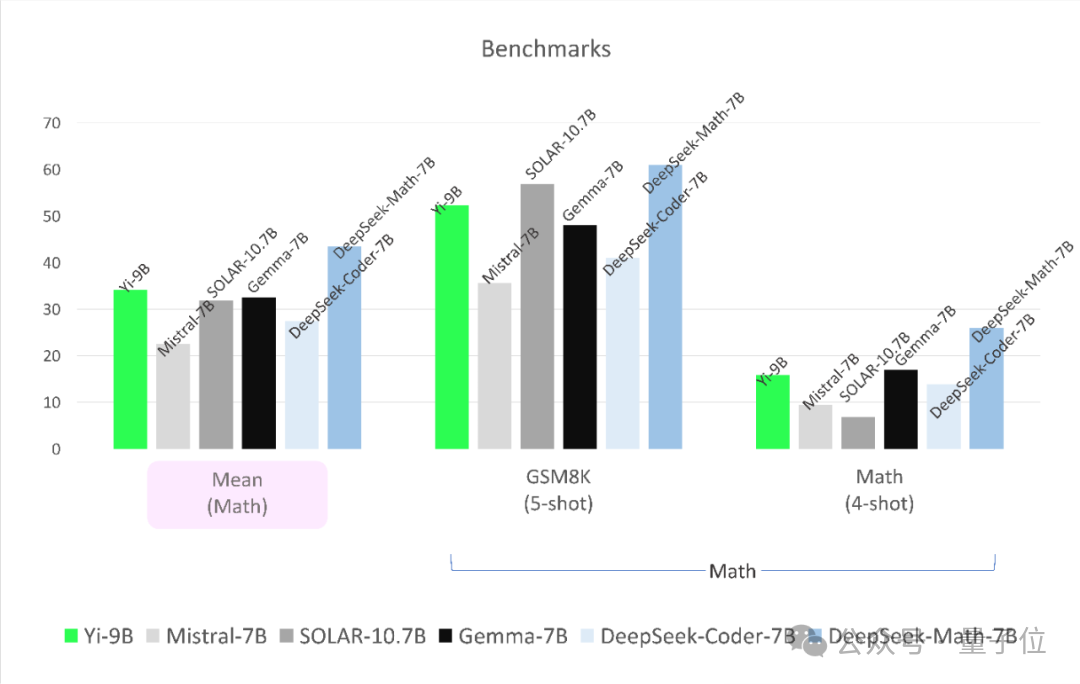
Les résultats sont les suivants.
Tout d'abord, en termes de tâches de codage, les performances de Yi-9B sont juste derrière DeepSeek-Coder-7B, et les quatre autres sont tous KO.
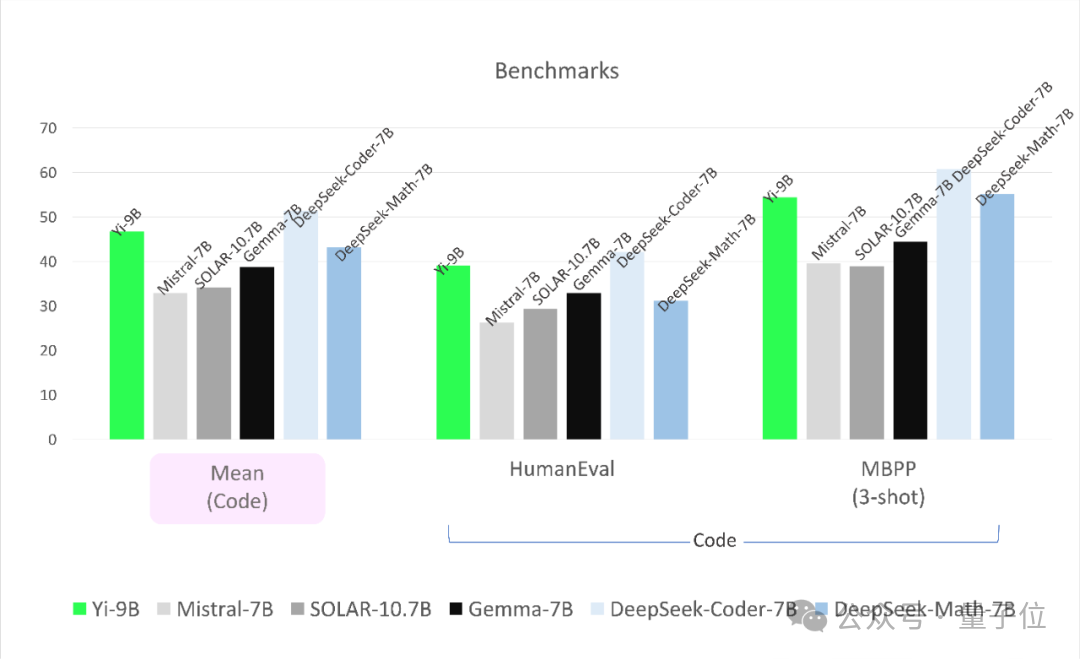
En termes de capacité mathématique, les performances de Yi-9B sont juste derrière DeepSeek-Math-7B, surpassant les quatre autres.
La capacité globale n'est pas mauvaise non plus.
Ses performances sont les meilleures parmi les modèles open source de taille similaire, surpassant les cinq autres joueurs.
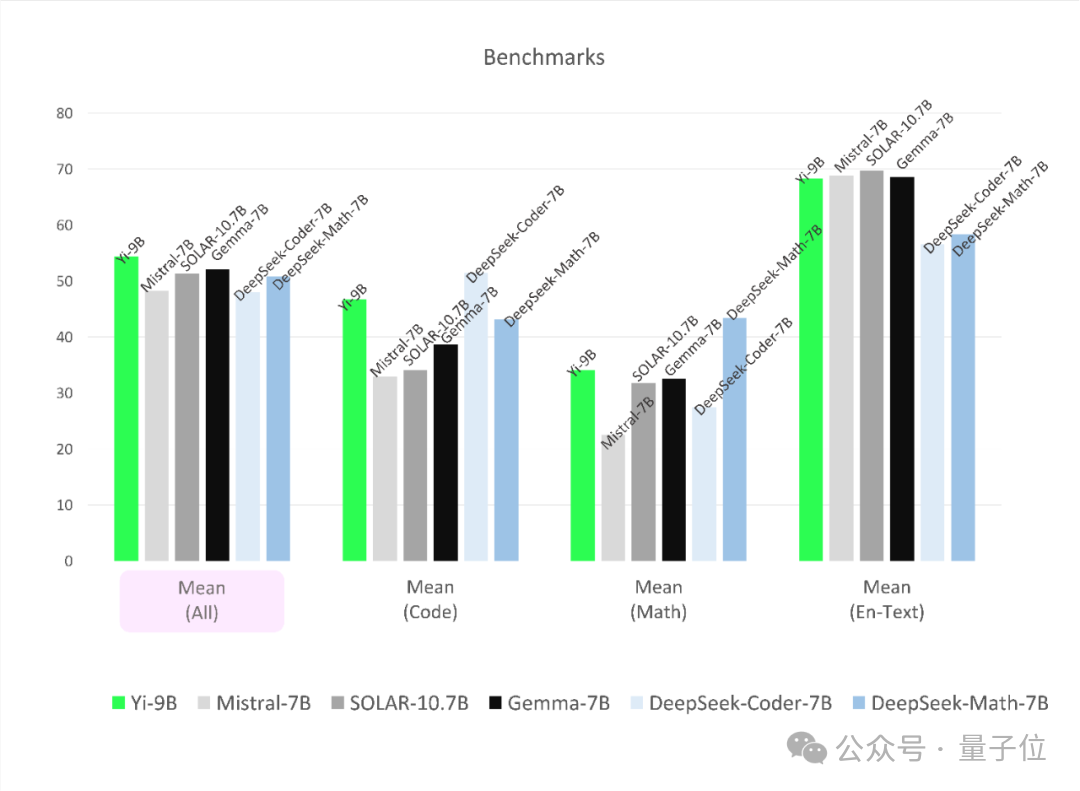
Enfin, le bon sens et la capacité de raisonnement ont été testés :
Le résultat est que Yi-9B est à égalité avec Mistral-7B, SOLAR-10.7B et Gemma-7B.
En plus des compétences linguistiques, non seulement l'anglais est bon, mais le chinois est également largement apprécié :
Enfin, après avoir lu ces lignes, certains internautes ont dit : J'ai hâte de l'essayer.

Certaines personnes s'inquiètent de DeepSeek :
Dépêchez-vous et renforcez votre "jeu". La domination totale a disparu ==

Le portail est ici : https://huggingface.co/01-ai/Yi-9B
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
