
 Périphériques technologiques
IA
La pierre angulaire d'AI4Science : le réseau neuronal à graphes géométriques, la revue la plus complète est ici ! L'Université Renmin de Chine Hillhouse a publié conjointement le laboratoire Tencent AI, l'Université Tsinghua, Stanford, etc.
Périphériques technologiques
IA
La pierre angulaire d'AI4Science : le réseau neuronal à graphes géométriques, la revue la plus complète est ici ! L'Université Renmin de Chine Hillhouse a publié conjointement le laboratoire Tencent AI, l'Université Tsinghua, Stanford, etc.
La pierre angulaire d'AI4Science : le réseau neuronal à graphes géométriques, la revue la plus complète est ici ! L'Université Renmin de Chine Hillhouse a publié conjointement le laboratoire Tencent AI, l'Université Tsinghua, Stanford, etc.


Éditeur | XS
Nature a publié deux résultats de recherche importants en novembre 2023 : la technologie de synthèse des protéines Chroma et la méthode de conception de matériaux cristallins GNoME. Les deux études ont adopté les réseaux de neurones graphiques comme outil de traitement des données scientifiques.
En fait, les réseaux de neurones graphiques, en particulier les réseaux de neurones graphes géométriques, ont toujours été un outil important pour la recherche en intelligence scientifique (AI for Science). En effet, les systèmes physiques tels que les particules, les molécules, les protéines et les cristaux dans le domaine scientifique peuvent être modélisés dans une structure de données spéciale : des graphiques géométriques.
Différents des diagrammes topologiques généraux, afin de mieux décrire le système physique, les diagrammes géométriques ajoutent des informations spatiales indispensables et doivent respecter la symétrie physique de translation, de rotation et de retournement. Compte tenu de la supériorité des réseaux neuronaux à graphes géométriques pour la modélisation des systèmes physiques, diverses méthodes ont vu le jour ces dernières années et le nombre d'articles continue de croître.
Récemment, l'Université Renmin de Chine Hillhouse s'est associée au Tencent AI Lab, à l'Université Tsinghua, à Stanford et à d'autres institutions pour publier un article de synthèse : "Une enquête sur les réseaux neuronaux à graphes géométriques : structures de données, modèles et applications". Basée sur une brève introduction aux connaissances théoriques telles que la théorie des groupes et la symétrie, cette revue passe systématiquement en revue la littérature pertinente sur les réseaux neuronaux à graphes géométriques, depuis les structures de données et les modèles jusqu'à de nombreuses applications scientifiques.

Lien papier :https://arxiv.org/abs/2403.00485
Lien GitHub :https://github.com/RUC-GLAD/GGNN4Science
Dans cette revue, l'auteur After En recherchant plus de 300 références, nous avons résumé 3 modèles de réseaux neuronaux à graphes géométriques différents, introduit des méthodes associées pour un total de 23 tâches différentes sur diverses données scientifiques telles que des particules, des molécules et des protéines, et collecté plus de 50 ensembles de données connexes. Enfin, la revue attend avec impatience les futures orientations de recherche, notamment les modèles de base de graphes géométriques, la combinaison avec de grands modèles de langage, etc.
Ce qui suit est une brève introduction à chaque chapitre.
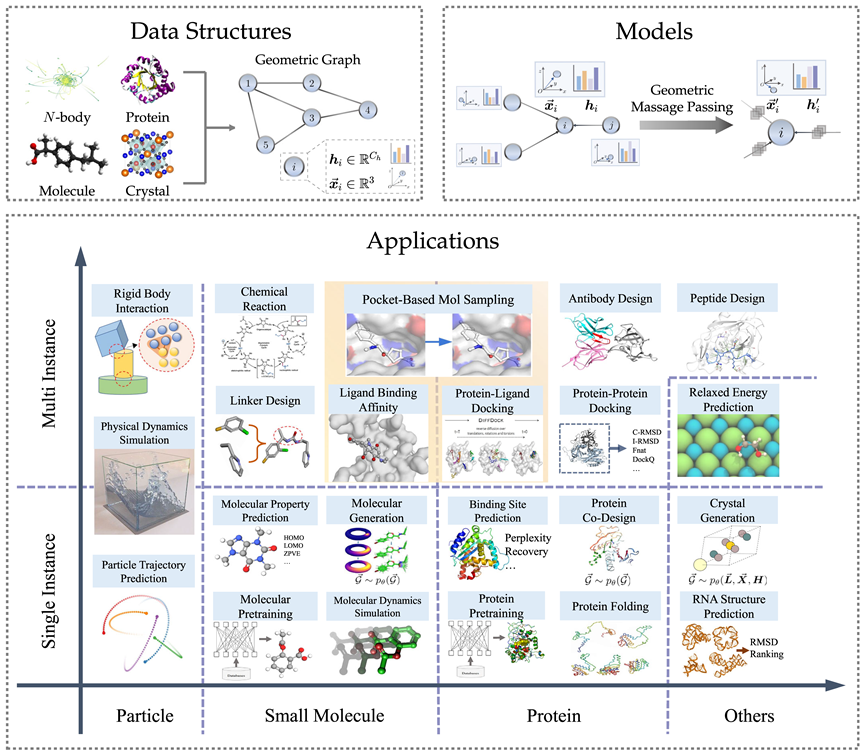
Structure de données du graphique géométrique
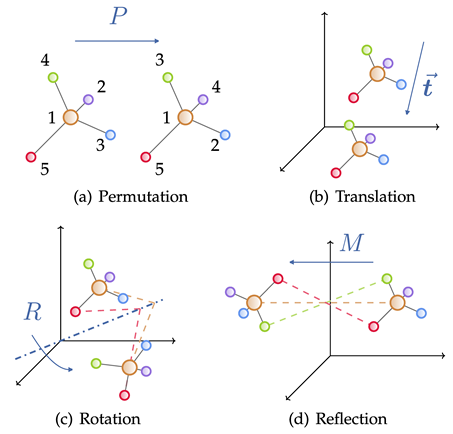
Le graphique géométrique se compose d'une matrice de contiguïté, des caractéristiques des nœuds et des informations géométriques des nœuds (telles que les coordonnées). Dans l'espace euclidien, les figures géométriques montrent généralement des symétries physiques de translation, de rotation et de réflexion. Des groupes sont généralement utilisés pour décrire ces transformations, notamment le groupe euclidien, le groupe de translation, le groupe orthogonal, le groupe de permutation, etc. Intuitivement, cela peut être compris comme une combinaison de quatre opérations : déplacement, translation, rotation et retournement dans un certain ordre.
Pour de nombreux domaines de l'IA pour la science, les graphiques géométriques constituent une méthode de représentation puissante et polyvalente, qui peut être utilisée pour représenter de nombreux systèmes physiques, notamment de petites molécules, des protéines, des cristaux, des nuages de points physiques, etc.
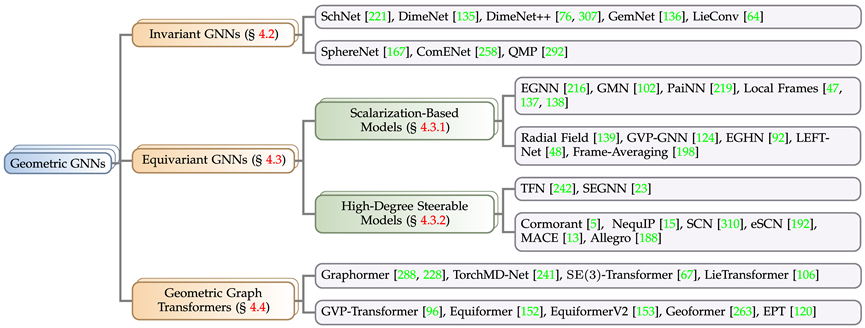
Modèle de réseau neuronal à graphe géométrique
Selon les exigences de symétrie des objectifs de solution dans des problèmes réels, cet article divise les réseaux de neurones à graphe géométrique en trois catégories : le modèle invariant et le modèle de modèle équivariant, et le transformateur de graphe géométrique inspiré de l'architecture Transformer. Le modèle équivariant est subdivisé en un modèle basé sur la scalarisation et un modèle orientable à haut degré basé sur l'harmonisation sphérique. Selon les règles ci-dessus, l'article rassemble et catégorise les modèles de réseaux neuronaux à graphes géométriques bien connus de ces dernières années.
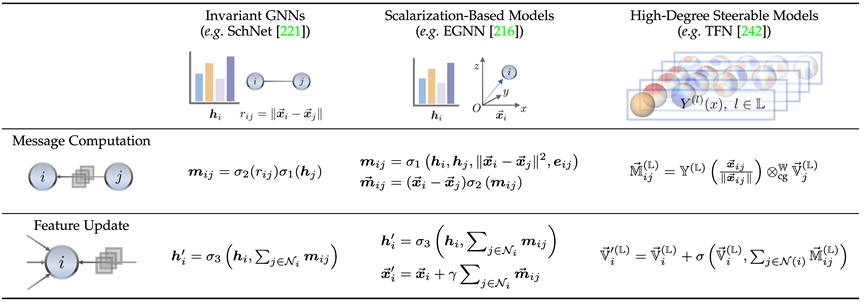
Ici, nous introduisons brièvement la relation entre le modèle invariant (SchNet[1]), le modèle de méthode de scalarisation (EGNN[2]) et le modèle contrôlable d'ordre élevé (TFN[3]) à travers le travail représentatif de chaque branche et différence. On peut constater que tous les trois utilisent des mécanismes de transmission de messages, mais que les deux derniers, qui sont des modèles équivariants, introduisent une transmission de message géométrique supplémentaire.
Le modèle invariant utilise principalement les caractéristiques du nœud lui-même (telles que le type d'atome, la masse, la charge, etc.) et les caractéristiques invariantes entre les atomes (telles que la distance, l'angle [4], l'angle dièdre [5]), etc. .pour calculer les messages.
En plus de cela, la méthode de scalarisation introduit en outre des informations géométriques via la différence de coordonnées entre les nœuds et combine linéairement les informations invariantes en tant que poids des informations géométriques pour obtenir l'introduction de l'équivariance.
Les modèles contrôlables d'ordre élevé utilisent des harmoniques sphériques d'ordre élevé et des matrices de Wigner-D pour représenter les informations géométriques du système. Cette méthode contrôle l'ordre de représentation irréductible via le coefficient Clebsch-Gordan en mécanique quantique, réalisant ainsi le passage du message géométrique. processus.
La précision du réseau neuronal du graphe géométrique est grandement améliorée grâce à la symétrie garantie par ce type de conception, et elle brille également dans la tâche de génération.
La figure ci-dessous montre les résultats des trois tâches de prédiction des propriétés moléculaires, d'amarrage protéine-ligand et de conception (génération) d'anticorps à l'aide du réseau neuronal à graphe géométrique et du modèle traditionnel sur les trois ensembles de données de QM9, PDBBind et SabDab It. On voit clairement que Avantages des réseaux de neurones à graphes géométriques.
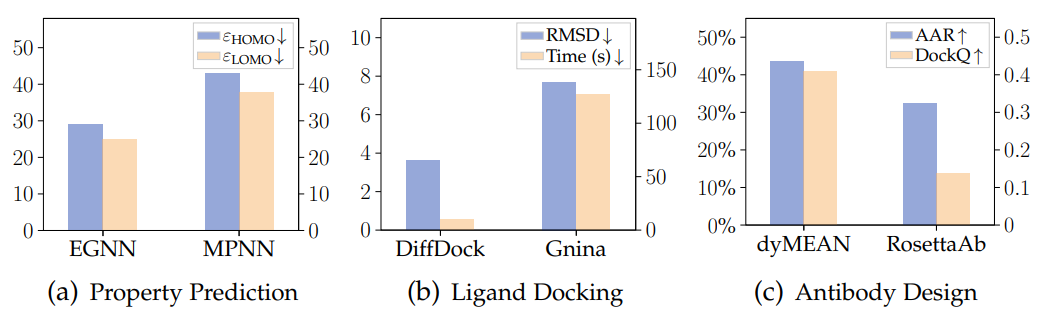
Applications scientifiques
En termes d'applications scientifiques, la revue couvre la physique (particules), la biochimie (petites molécules, protéines) et d'autres scénarios d'application tels que les cristaux, les définitions de tâches et les garanties de symétrie requises. À partir des catégories , les ensembles de données couramment utilisés dans chaque tâche et les idées classiques de conception de modèles dans ce type de tâches sont introduits.
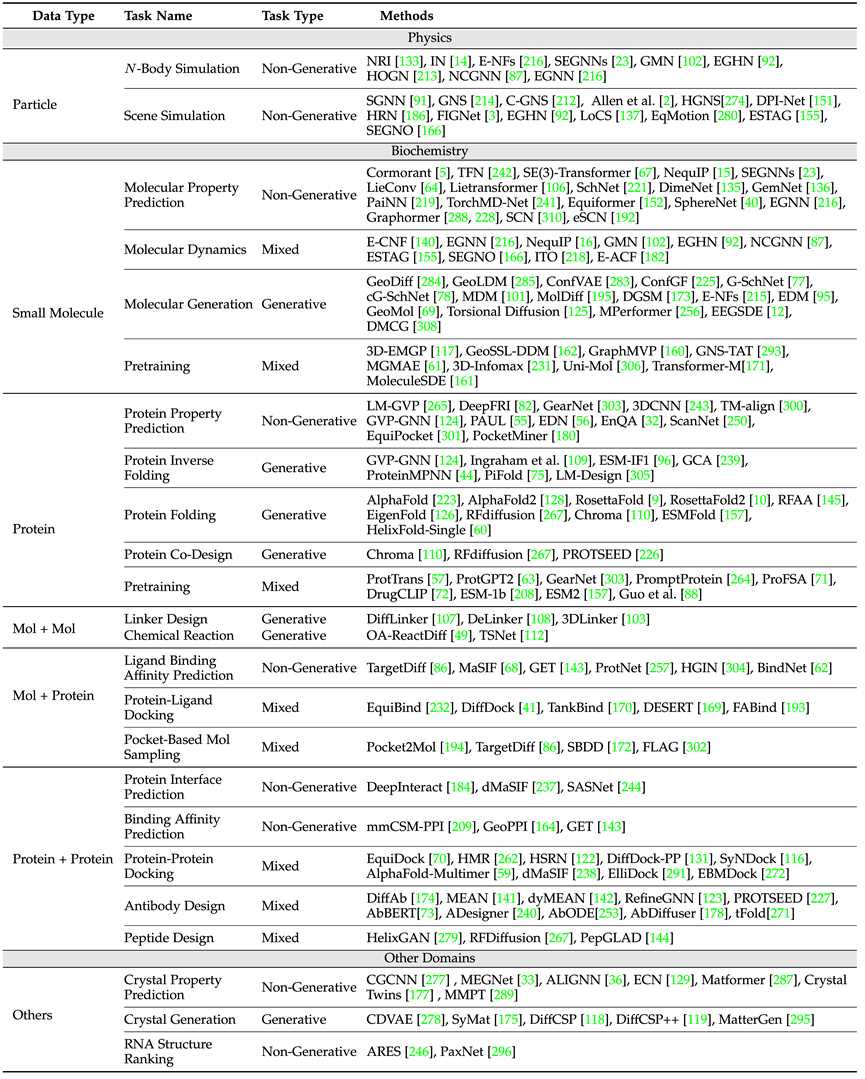
Le tableau ci-dessus présente les tâches courantes et les modèles classiques dans divers domaines. Parmi eux, selon une instance unique et des instances multiples (telles que les réactions chimiques, qui nécessitent la participation de plusieurs molécules), l'article distingue séparément les petites molécules - petites molécules, petites molécules -Protéine, protéine - trois domaines de protéines.
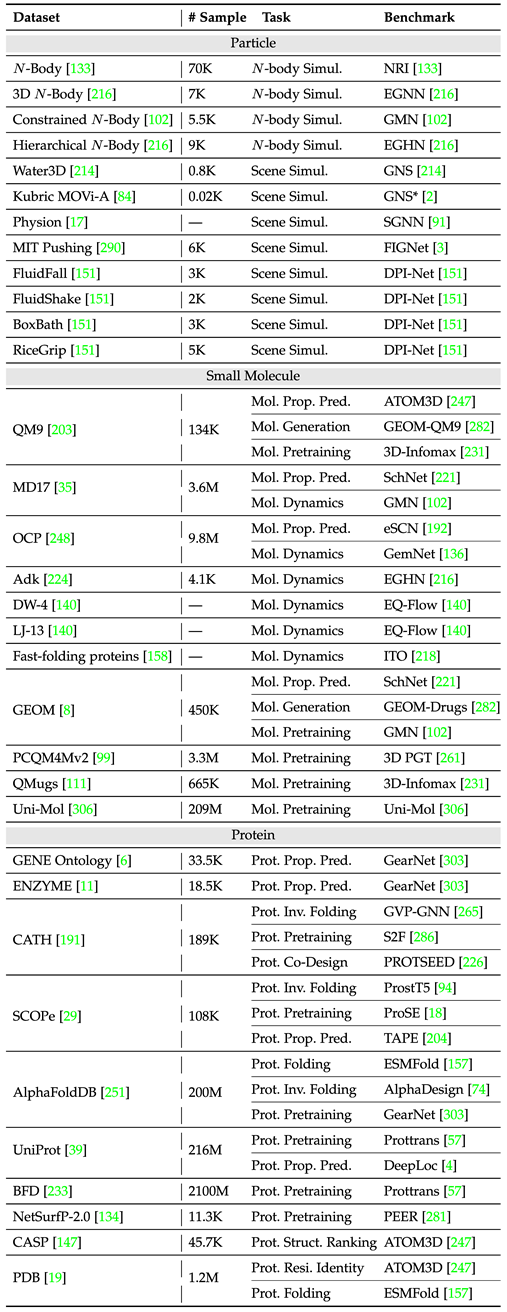
Afin de mieux faciliter la conception de modèles et le développement d'expériences sur le terrain, l'article compte les ensembles de données et les références communs pour deux types de tâches basées sur une instance unique et des instances multiples, et enregistre les tailles d'échantillon et les types de tâches de différents ensembles de données. .
Le tableau suivant résume les ensembles de données de tâches à instance unique courants.
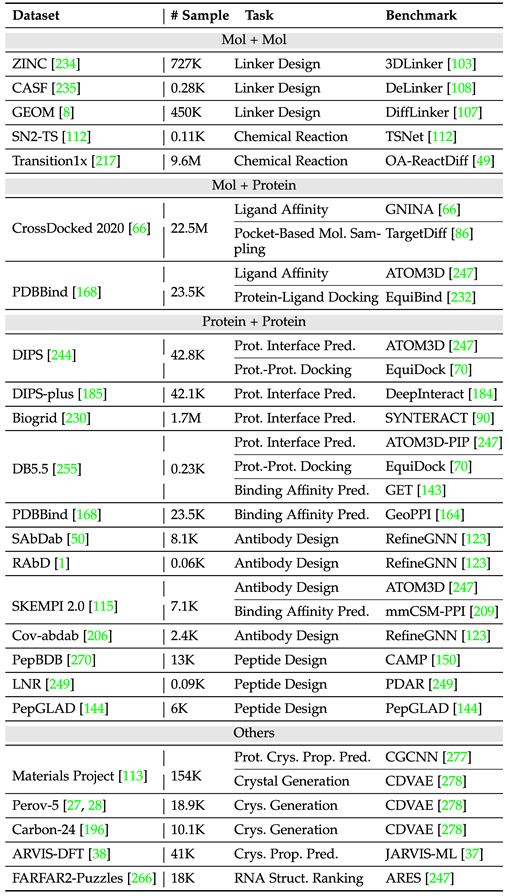
Le tableau suivant organise les ensembles de données de tâches multi-instances courantes.
Perspectives futures
L'article donne un aperçu préliminaire de plusieurs aspects, dans l'espoir de servir de point de départ :
1. Le modèle de graphe géométrique de base
est unifié dans diverses tâches et domaines. La supériorité du modèle de base s'est pleinement reflétée dans les progrès significatifs des modèles de la série GPT. Comment réaliser une conception raisonnable dans l'espace des tâches, l'espace des données et l'espace des modèles, afin d'introduire cette idée dans la conception du réseau neuronal à graphes géométriques, reste un problème ouvert intéressant.
2. Cycle efficace de formation de modèles et de vérification expérimentale dans le monde réel
L'acquisition de données scientifiques est coûteuse et prend du temps, et les modèles qui ne sont évalués que sur des ensembles de données indépendants ne peuvent pas refléter directement les commentaires du monde réel. L'importance de parvenir à des paradigmes expérimentaux itératifs modèles-réalité efficaces similaires à GNoME (qui intègre un pipeline de bout en bout comprenant une formation sur les réseaux de graphes, des calculs de théorie fonctionnelle de la densité et des laboratoires automatisés pour la découverte et la synthèse des matériaux) augmentera de jour en jour. jour.
3. Intégration avec les grands modèles de langage (LLM)
Il a été largement prouvé que les grands modèles de langage (LLM) possèdent des connaissances riches, couvrant divers domaines. Bien que certains travaux utilisent les LLM pour certaines tâches telles que la prédiction des propriétés moléculaires et la conception de médicaments, ils ne fonctionnent que sur des primitives ou des graphes moléculaires. Comment les combiner de manière organique avec des réseaux neuronaux de graphes géométriques afin qu'ils puissent traiter des informations structurelles 3D et effectuer des prédictions ou des générations sur des structures 3D reste encore un défi.
4. Assouplissement des contraintes d'équivariance
Il ne fait aucun doute que l'équivariance est cruciale pour améliorer l'efficacité des données et la capacité de généralisation du modèle, mais il convient de noter que des contraintes d'équivariance trop fortes peuvent parfois trop restreindre le modèle. performance. Par conséquent, comment équilibrer l’équivariance et l’adaptabilité du modèle conçu est une question très intéressante. L'exploration dans ce domaine peut non seulement enrichir notre compréhension du comportement des modèles, mais également ouvrir la voie au développement de solutions plus robustes et générales avec une applicabilité plus large.
Références
[1] Schütt K, Kindermans PJ, Sauceda Felix H E, et al. Schnet : Un réseau neuronal convolutionnel à filtre continu pour la modélisation des interactions quantiques [J]. .
[2] Satorras V G, Hoogeboom E, Welling M. E (n) réseaux de neurones à graphes équivariants[C]//Conférence internationale sur l'apprentissage automatique. PMLR, 2021 : 9323-9332.
[3] Thomas N, Smidt T, Kearnes S, et al. Réseaux de champs tensoriels : réseaux de neurones équivariants en rotation et en translation pour les nuages de points 3D [J]. Préimpression arXiv arXiv:1802.08219, 2018.
[4] Gasteiger J, Groß J, Günnemann S. Transmission de messages directionnels pour les graphiques moléculaires[C]//Conférence internationale sur les représentations d'apprentissage. 2019.
[5] Gasteiger J, Becker F, Günnemann S. Gemnet : Réseaux neuronaux à graphes directionnels universels pour molécules[J]. Advances in Neural Information Processing Systems, 2021, 34 : 6790-6802.
[6] Merchant A, Batzner S, Schoenholz SS, et al. Mise à l'échelle de l'apprentissage profond pour la découverte des matériaux[J]. Nature, 2023, 624(7990) : 80-85.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Trois secrets pour déployer de grands modèles dans le cloud
Apr 24, 2024 pm 03:00 PM
Trois secrets pour déployer de grands modèles dans le cloud
Apr 24, 2024 pm 03:00 PM
Compilation|Produit par Xingxuan|51CTO Technology Stack (ID WeChat : blog51cto) Au cours des deux dernières années, j'ai été davantage impliqué dans des projets d'IA générative utilisant de grands modèles de langage (LLM) plutôt que des systèmes traditionnels. Le cloud computing sans serveur commence à me manquer. Leurs applications vont de l’amélioration de l’IA conversationnelle à la fourniture de solutions d’analyse complexes pour diverses industries, ainsi que de nombreuses autres fonctionnalités. De nombreuses entreprises déploient ces modèles sur des plates-formes cloud, car les fournisseurs de cloud public fournissent déjà un écosystème prêt à l'emploi et constituent la voie de moindre résistance. Cependant, cela n’est pas bon marché. Le cloud offre également d'autres avantages tels que l'évolutivité, l'efficacité et des capacités informatiques avancées (GPU disponibles sur demande). Il existe certains aspects peu connus du déploiement de LLM sur les plateformes de cloud public
 Identifiez automatiquement les meilleures molécules et réduisez les coûts de synthèse. Le MIT développe un cadre d'algorithme de prise de décision en matière de conception moléculaire.
Jun 22, 2024 am 06:43 AM
Identifiez automatiquement les meilleures molécules et réduisez les coûts de synthèse. Le MIT développe un cadre d'algorithme de prise de décision en matière de conception moléculaire.
Jun 22, 2024 am 06:43 AM
Éditeur | L’utilisation de Ziluo AI pour rationaliser la découverte de médicaments explose. Ciblez des milliards de molécules candidates pour détecter celles qui pourraient posséder les propriétés nécessaires au développement de nouveaux médicaments. Il y a tellement de variables à prendre en compte, depuis le prix des matériaux jusqu’au risque d’erreur, qu’évaluer les coûts de synthèse des meilleures molécules candidates n’est pas une tâche facile, même si les scientifiques utilisent l’IA. Ici, les chercheurs du MIT ont développé SPARROW, un cadre d'algorithme de prise de décision quantitative, pour identifier automatiquement les meilleurs candidats moléculaires, minimisant ainsi les coûts de synthèse tout en maximisant la probabilité que les candidats possèdent les propriétés souhaitées. L’algorithme a également identifié les matériaux et les étapes expérimentales nécessaires à la synthèse de ces molécules. SPARROW prend en compte le coût de synthèse d'un lot de molécules à la fois, puisque plusieurs molécules candidates sont souvent disponibles
