
 Périphériques technologiques
IA
'AI Perspective Eye', triple lauréat du prix Marr, Andrew dirige une équipe pour résoudre le problème de l'occlusion et de l'achèvement de tout objet
Périphériques technologiques
IA
'AI Perspective Eye', triple lauréat du prix Marr, Andrew dirige une équipe pour résoudre le problème de l'occlusion et de l'achèvement de tout objet
'AI Perspective Eye', triple lauréat du prix Marr, Andrew dirige une équipe pour résoudre le problème de l'occlusion et de l'achèvement de tout objet

L'occlusion est l'un des problèmes les plus fondamentaux mais toujours non résolus de la vision par ordinateur, car l'occlusion signifie le manque d'informations visuelles, tandis que les systèmes de vision industrielle s'appuient sur des informations visuelles pour la perception et la compréhension, et dans le monde réel, entre les objets. Occlusion mutuelle est partout. Les derniers travaux de l'équipe d'Andrew Zisserman du laboratoire VGG de l'université d'Oxford ont résolu systématiquement le problème de l'occlusion complète d'objets arbitraires et ont proposé un nouvel ensemble de données d'évaluation plus précise pour ce problème. Ce travail a été salué par le patron du MPI Michael Black, le compte officiel du CVPR, le compte officiel du Département d'informatique de l'Université de Californie du Sud, etc. sur la plateforme X. Ce qui suit est le contenu principal de l'article « Amodal Ground Truth and Completion in the Wild ».

- Lien papier : https://arxiv.org/pdf/2312.17247.pdf
- Page d'accueil du projet : https://www.robots.ox.ac.uk/~vgg /research/amodal/
- Adresse du code : https://github.com/Championchess/Amodal-Completion-in-the-Wild
La segmentation modale est conçue pour compléter l'objet étant la partie occluse, c'est-à-dire c'est-à-dire un masque de forme qui donne les parties visibles et invisibles de l'objet. Cette tâche peut bénéficier à de nombreuses tâches en aval : reconnaissance d'objets, détection de cibles, segmentation d'instances, édition d'images, reconstruction 3D, segmentation d'objets vidéo, support du raisonnement relationnel entre objets, manipulation et navigation du robot, car dans ces tâches, on sait que l'objet occulté est intact La forme aidera.

Cependant, comment évaluer les performances d'un modèle pour la segmentation non modale dans le monde réel est un problème difficile : bien qu'il y ait un grand nombre d'objets occultés dans de nombreuses images, comment obtenir une référence pour les formes complètes de ces objets. Qu'en est-il des masques standards ou non modaux ? Les travaux antérieurs impliquaient l'annotation manuelle de masques non modaux, mais les normes de référence pour une telle annotation sont difficiles à éviter d'introduire des erreurs humaines. Il existe également des travaux consistant à créer des ensembles de données synthétiques, par exemple en attachant directement un autre objet à un objet complet. forme complète de l'objet occulté, mais les images obtenues de cette manière ne sont pas de véritables scènes d'images. Par conséquent, ce travail propose une méthode par projection de modèle 3D pour construire un ensemble de données d'images réelles à grande échelle (MP3D-Amodal) couvrant plusieurs catégories d'objets et fournissant des masques amodaux pour évaluer avec précision les performances de la segmentation amodale. La comparaison des différents ensembles de données est la suivante :
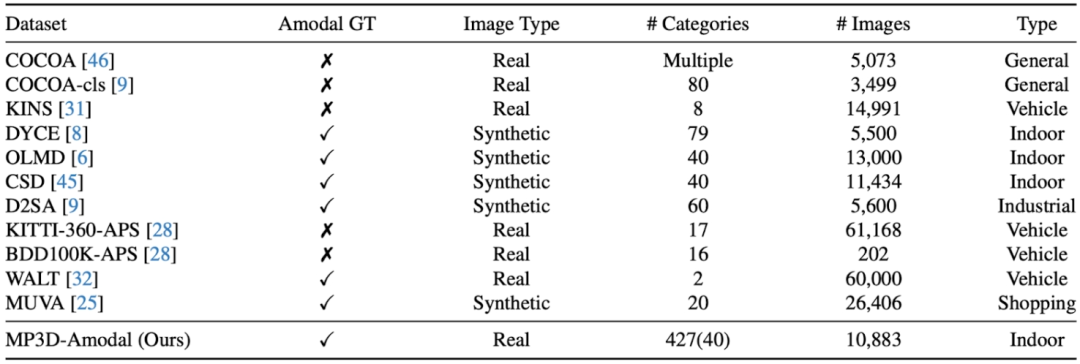
Plus précisément, en prenant l'ensemble de données MatterPort3D comme exemple, pour tout ensemble de données avec de vraies photos et une structure tridimensionnelle de la scène, nous pouvons combiner les données de tous les objets de la scène La forme tridimensionnelle est projetée simultanément sur la caméra pour obtenir le masque modal de chaque objet (la forme visible, car les objets s'occultent les uns les autres), puis la forme tridimensionnelle de chaque objet dans la scène est projetée sur la caméra séparément pour obtenir le masque non modal de l'objet, c'est-à-dire la forme complète. En comparant le masque modal et le masque non modal, les objets masqués peuvent être repérés.

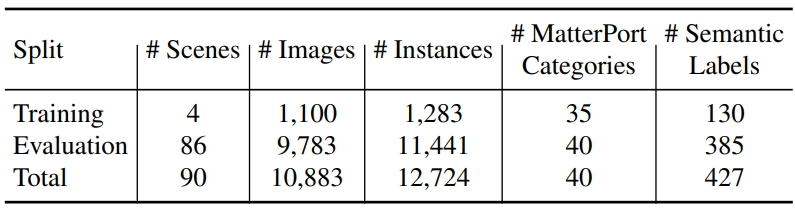
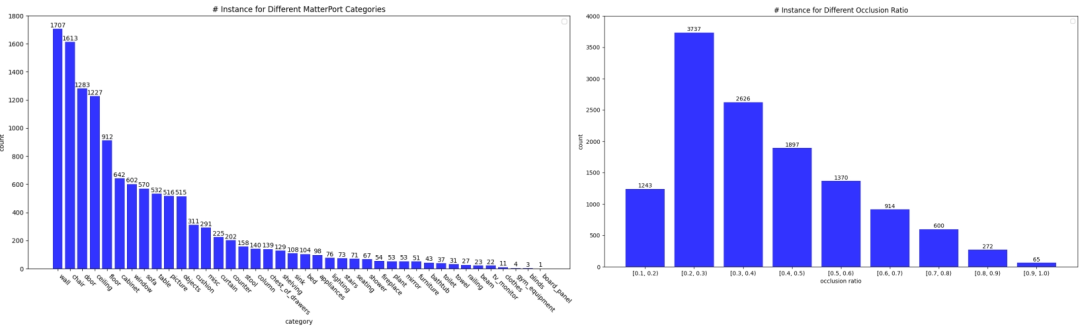
Les statistiques de l'ensemble de données sont les suivantes :
Un échantillon de l'ensemble de données est le suivant :

De plus, résoudre la forme complète tâche de reconstruction de n'importe quel objet, l'auteur extrait les connaissances préalables sur la forme complète de l'objet à partir des caractéristiques du modèle de diffusion stable pour effectuer une segmentation non modale de tout objet occlus. L'architecture spécifique est la suivante (SDAmodal) :
.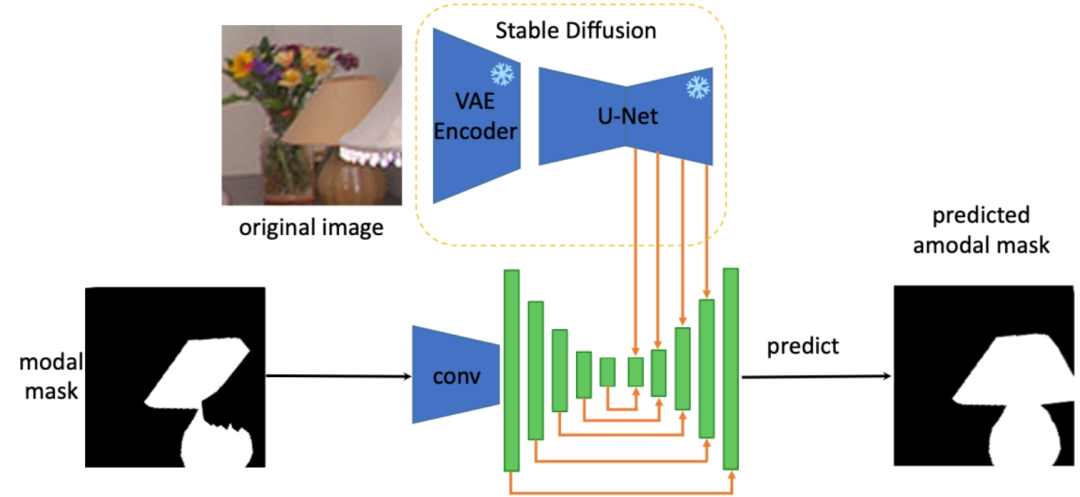
La motivation pour proposer d'utiliser la fonction de diffusion stable est que Stable Diffusion a la capacité de compléter des images, elle peut donc contenir toutes les informations sur l'objet dans une certaine mesure et parce que Stable Diffusion a été entraînée avec un grand nombre d'images. nombre d'images, on peut s'attendre à ce qu'il ait la capacité de traiter n'importe quel objet dans n'importe quel environnement. Contrairement aux cadres en deux étapes précédents, SDAmodal ne nécessite pas de masques d'occlusion annotés en entrée ; SDAmodal a une structure simple, mais montre une forte capacité de généralisation à échantillon nul (comparez les paramètres F et H dans le tableau suivant, seule la formation sur COCOA peut améliorer sur un autre ensemble de données dans un domaine différent et des catégories différentes) ; même s'il n'y a pas d'annotation des objets occlus, SDAmodal peut améliorer l'ensemble de données existant COCOA couvrant plusieurs types d'objets occlus et le nouveau jeu de données proposé sur MP3D-Amodal, Les performances SOTA (réglage H) ont été atteintes.
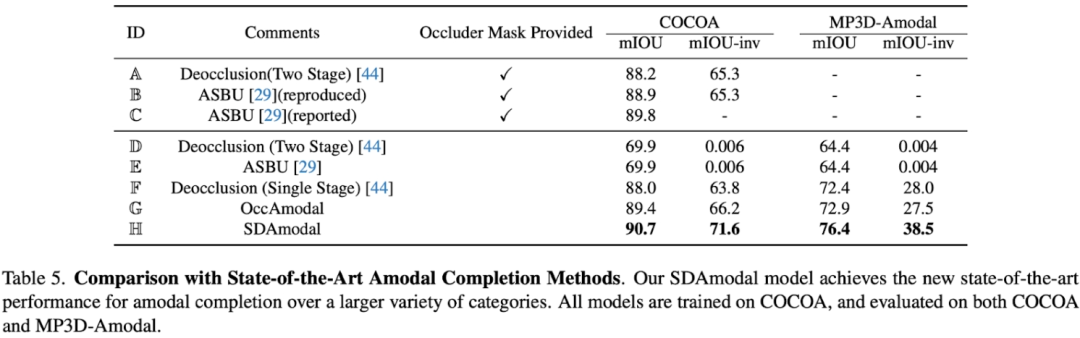
En plus des expériences quantitatives, les comparaisons qualitatives reflètent également les avantages du modèle SDAmodal : On peut l'observer sur la figure ci-dessous (tous les modèles sont uniquement entraînés sur COCOA), pour différents types d'objets occlus, que ce soit Qu'il provienne de COCOA ou d'un autre MP3D-Amodal, SDAmodal peut grandement améliorer l'effet de segmentation non modale, et le masque non modal prédit est plus proche du réel.

Pour plus de détails, veuillez lire l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, architecte en chef de SonyInterActiveTeretment (SIE, Sony Interactive Entertainment), a publié plus de détails matériels de l'hôte de nouvelle génération PlayStation5Pro (PS5PRO), y compris un GPU AMDRDNA2.x architecture amélioré sur les performances, et un programme d'apprentissage de l'intelligence machine / artificielle "AmethylSt" avec AMD. L'amélioration des performances de PS5PRO est toujours sur trois piliers, y compris un GPU plus puissant, un traçage avancé des rayons et une fonction de super-résolution PSSR alimentée par AI. GPU adopte une architecture AMDRDNA2 personnalisée, que Sony a nommé RDNA2.x, et il a une architecture RDNA3.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Les améliorations de Microsoft aux fonctions de recherche Windows ont été testées sur certains canaux d'initiés Windows dans l'UE. Auparavant, la fonction de recherche Windows intégrée a été critiquée par les utilisateurs et avait une mauvaise expérience. Cette mise à jour divise la fonction de recherche en deux parties: recherche locale et recherche Web basée sur Bing pour améliorer l'expérience utilisateur. La nouvelle version de l'interface de recherche effectue la recherche de fichiers locale par défaut. Si vous devez rechercher en ligne, vous devez cliquer sur l'onglet "Microsoft Bingwebsearch" pour changer. Après le changement, la barre de recherche affichera "Microsoft BingWebsearch:", où les utilisateurs peuvent entrer des mots clés. Ce mouvement évite efficacement le mélange des résultats de recherche locaux avec les résultats de recherche Bing
