
 Java
javaDidacticiel
Traitement XML efficace en Java : conseils pour améliorer les performances
Java
javaDidacticiel
Traitement XML efficace en Java : conseils pour améliorer les performances
Traitement XML efficace en Java : conseils pour améliorer les performances


Le traitement XML efficace en Java a toujours été au centre des préoccupations des développeurs. En réponse à ce problème, l'éditeur PHP Banana a compilé quelques conseils pour améliorer les performances. Grâce à une sélection raisonnable d'analyseurs, à l'optimisation de la logique du code et au traitement raisonnable de gros volumes de données, l'efficacité du traitement XML peut être efficacement améliorée, rendant le travail de développement plus efficace et plus fluide. Nous détaillerons ensuite ces techniques pour aider les développeurs à mieux relever les défis du traitement XML.
Utilisez l'analyseur SAX : SAX (Simple api for XML) est un analyseur événementiel très efficace lors du traitement de documents XML volumineux. L'analyseur SAX analyse les éléments XML un par un, stockant uniquement le minimum d'informations requis pour l'analyse, minimisant ainsi la consommation de mémoire et le temps de traitement.
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
DefaultHandler handler = new DefaultHandler() {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) {
// 处理元素开始事件
}
@Override
public void characters(char[] ch, int start, int length) {
// 处理元素内容事件
}
};
parser.parse(new InputSource(new File("file.xml")), handler);Utilisez l'analyseur DOM4J : DOM4J est un analyseur résidant en mémoire qui charge l'intégralité du document XML en mémoire. Bien que cela puisse être pratique pour les applications qui nécessitent un traitement complexe de XML ou une navigation fréquente, cela peut consommer de grandes quantités de mémoire, en particulier lors du traitement de documents XML volumineux.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(new File("file.xml"));
Element root = doc.getRootElement();
List<Element> elements = root.elements();
for (Element element : elements) {
// 处理元素
}Utilisez l'analyseur StAX : StAX (Streaming API for XML) est un analyseur basé sur les événements, similaire à SAX, mais axé sur un traitement plus rapide et une empreinte mémoire plus petite. L'analyseur StAX permet aux développeurs de diffuser des documents XML, évitant ainsi de charger l'intégralité du document en mémoire.
XMLStreamReader reader = XMLInputFactory.newFactory().createXMLStreamReader(new File("file.xml"));
while (reader.hasNext()) {
int eventType = reader.next();
switch (eventType) {
case XMLStreamConstants.START_ELEMENT:
// 处理元素开始事件
break;
case XMLStreamConstants.CHARACTERS:
// 处理元素内容事件
break;
default:
// 忽略其他事件
break;
}
}Optimiser l'utilisation de la mémoire : L'optimisation de la mémoire est cruciale lorsque vous travaillez avec des documents XML volumineux. L'utilisation d'un analyseur SAX ou StAX peut réduire considérablement la consommation de mémoire car ils ne chargent pas l'intégralité du document en mémoire. De plus, les pools de mémoire peuvent être utilisés pour réutiliser des objets, optimisant ainsi davantage l'utilisation de la mémoire.
Exploiter la simultanéité : Sur les systèmes multicœurs, tirer parti de la concurrency peut améliorer les performances de traitement XML. Vous pouvez utiliser l'API de concurrence Java (telle que ThreadPoolExecutor) pour créer un pool de threads et utiliser plusieurs threads pour traiter différentes parties du document XML en parallèle.
Autres conseils :
- CacheFragments XML fréquemment consultés
- Trouver des informations spécifiques dans un document XML à l'aide de XPath ou XQuery
- Envisagez d'utiliser une bibliothèque XML tierce telle qu'Apache Xerces ou oracle XML Parser
- Benchmarkingtestset profilage du code de traitement XML
Conclusion : En utilisant un analyseur SAX, DOM4J ou StAX, en optimisant l'utilisation de la mémoire, en tirant parti de la concurrence et en employant d'autres techniques, les développeurs Java peuvent améliorer considérablement les performances du traitement XML. Ces techniques permettent de garantir des applications fluides et efficaces, même lorsque vous travaillez avec des documents XML volumineux ou complexes. Il est essentiel de surveilleret d'ajuster en permanence votre pipeline de traitement XML pour répondre aux besoins changeants des applications.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment affiner la profondeur localement
Feb 19, 2025 pm 05:21 PM
Comment affiner la profondeur localement
Feb 19, 2025 pm 05:21 PM
Le réglage fin local des modèles de classe Deepseek est confronté au défi des ressources informatiques insuffisantes et de l'expertise. Pour relever ces défis, les stratégies suivantes peuvent être adoptées: quantification du modèle: convertir les paramètres du modèle en entiers à faible précision, réduisant l'empreinte de la mémoire. Utilisez des modèles plus petits: sélectionnez un modèle pré-entraîné avec des paramètres plus petits pour un réglage fin local plus facile. Sélection des données et prétraitement: sélectionnez des données de haute qualité et effectuez un prétraitement approprié pour éviter une mauvaise qualité des données affectant l'efficacité du modèle. Formation par lots: pour les grands ensembles de données, chargez les données en lots de formation pour éviter le débordement de la mémoire. Accélération avec GPU: Utilisez des cartes graphiques indépendantes pour accélérer le processus de formation et raccourcir le temps de formation.
 Comment analysez-vous et traitez-vous HTML / XML dans PHP?
Feb 07, 2025 am 11:57 AM
Comment analysez-vous et traitez-vous HTML / XML dans PHP?
Feb 07, 2025 am 11:57 AM
Ce tutoriel montre comment traiter efficacement les documents XML à l'aide de PHP. XML (Language de balisage extensible) est un langage de balisage basé sur le texte polyvalent conçu à la fois pour la lisibilité humaine et l'analyse de la machine. Il est couramment utilisé pour le stockage de données et
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
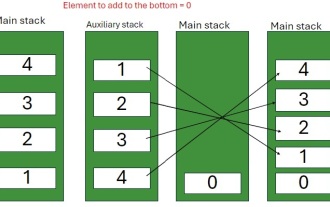 Programme Java pour insérer un élément au bas d'une pile
Feb 07, 2025 am 11:59 AM
Programme Java pour insérer un élément au bas d'une pile
Feb 07, 2025 am 11:59 AM
Une pile est une structure de données qui suit le principe LIFO (dernier dans, premier sorti). En d'autres termes, le dernier élément que nous ajoutons à une pile est le premier à être supprimé. Lorsque nous ajoutons (ou poussons) des éléments à une pile, ils sont placés sur le dessus; c'est-à-dire surtout
 CS-semaine 3
Apr 04, 2025 am 06:06 AM
CS-semaine 3
Apr 04, 2025 am 06:06 AM
Les algorithmes sont l'ensemble des instructions pour résoudre les problèmes, et leur vitesse d'exécution et leur utilisation de la mémoire varient. En programmation, de nombreux algorithmes sont basés sur la recherche et le tri de données. Cet article présentera plusieurs algorithmes de récupération et de tri de données. La recherche linéaire suppose qu'il existe un tableau [20,500,10,5,100,1,50] et doit trouver le numéro 50. L'algorithme de recherche linéaire vérifie chaque élément du tableau un par un jusqu'à ce que la valeur cible soit trouvée ou que le tableau complet soit traversé. L'organigramme de l'algorithme est le suivant: Le pseudo-code pour la recherche linéaire est le suivant: Vérifiez chaque élément: Si la valeur cible est trouvée: return True return false C Implementation: # include # includeIntMain (void) {i
 Comment exécuter votre première application de démarrage de printemps dans Intellij?
Feb 07, 2025 am 11:40 AM
Comment exécuter votre première application de démarrage de printemps dans Intellij?
Feb 07, 2025 am 11:40 AM
Intellij Idea simplifie le développement de Boot Spring, ce qui en fait un favori parmi les développeurs Java. Son approche de configuration de la convention minimise le code passe-partout, permettant aux développeurs de se concentrer sur la logique métier. Ce tutoriel montre deux métho
