
 Périphériques technologiques
IA
En utilisant de courtes vidéos IA pour « retourner » la compréhension de vidéos longues, le cadre MovieLLM de Tencent vise la génération d'images continues au niveau du film.
Périphériques technologiques
IA
En utilisant de courtes vidéos IA pour « retourner » la compréhension de vidéos longues, le cadre MovieLLM de Tencent vise la génération d'images continues au niveau du film.
En utilisant de courtes vidéos IA pour « retourner » la compréhension de vidéos longues, le cadre MovieLLM de Tencent vise la génération d'images continues au niveau du film.

Dans le domaine de la compréhension vidéo, bien que les modèles multimodaux aient fait des percées dans l'analyse de vidéos courtes et démontré de fortes capacités de compréhension, ils semblent impuissants face à de longues vidéos de niveau film. Par conséquent, l’analyse et la compréhension de longues vidéos, en particulier la compréhension de contenus cinématographiques d’une heure, sont devenues aujourd’hui un énorme défi.
La difficulté du modèle à comprendre les vidéos longues provient principalement du manque de ressources de données vidéo longues, qui présentent des défauts de qualité et de diversité. De plus, la collecte et l’étiquetage de ces données nécessitent beaucoup de travail.
Face à un tel problème, l'équipe de recherche de Tencent et de l'Université de Fudan a proposé MovieLLM, un framework innovant de génération d'IA. MovieLLM adopte une méthode innovante qui génère non seulement des données vidéo diversifiées et de haute qualité, mais génère également automatiquement un grand nombre d'ensembles de données de questions et réponses associées, enrichissant considérablement la dimension et la profondeur des données, et l'ensemble du processus automatisé est également extrêmement Dadi réduit l'investissement humain.

- Adresse papier : https://arxiv.org/abs/2403.01422
- Adresse de la page d'accueil : https://deaddawn.github.io/MovieLLM/
Ce développement important améliore non seulement la compréhension du modèle des récits vidéo complexes, mais améliore également les capacités analytiques du modèle lors du traitement de contenus cinématographiques d'une durée de plusieurs heures. Dans le même temps, il surmonte les limites de rareté et de biais des ensembles de données existants et offre un moyen nouveau et efficace de comprendre le contenu vidéo ultra-long.
MovieLLM utilise intelligemment les puissantes capacités de génération de GPT-4 et des modèles de diffusion, et adopte une stratégie de génération de description de trame continue « en expansion d'histoire ». La méthode « d'inversion textuelle » est utilisée pour guider le modèle de diffusion afin de générer des images de scène cohérentes avec la description textuelle, créant ainsi des images continues d'un film complet.

Présentation de la méthode
MovieLLM combine GPT-4 et des modèles de diffusion pour améliorer la compréhension des grands modèles de vidéos longues. Cette combinaison intelligente produit des données vidéo longues et diversifiées de haute qualité ainsi que des questions et réponses d'assurance qualité, contribuant ainsi à améliorer les capacités génératives du modèle.
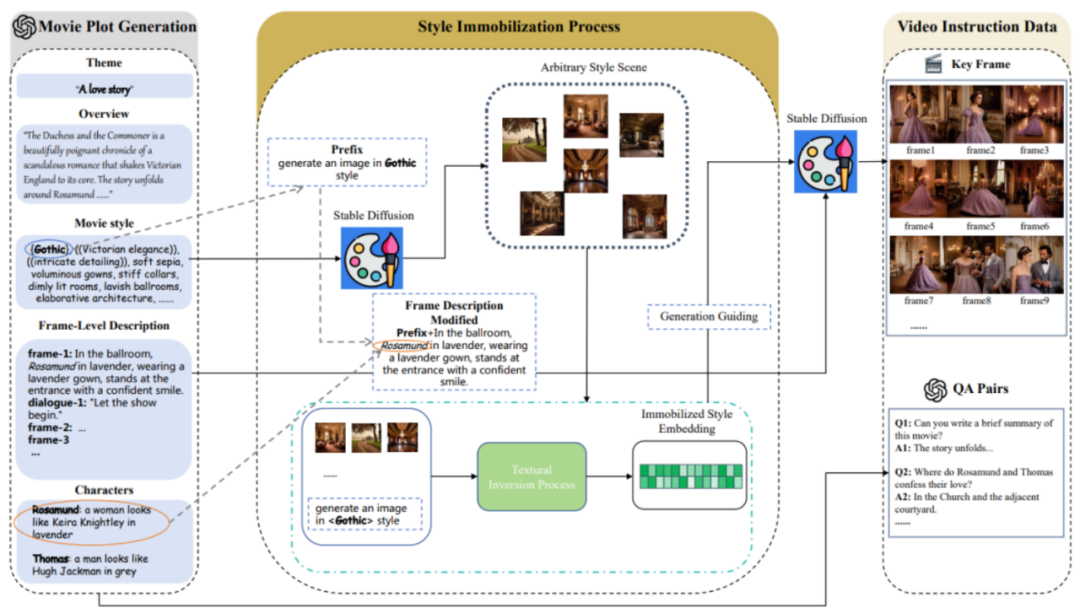
MovieLLM comprend principalement trois étapes :
1.
MovieLLM ne s'appuie pas sur le Web ou sur les ensembles de données existants pour générer des tracés, mais exploite pleinement la puissance de GPT-4 pour produire des données synthétiques. En fournissant des éléments spécifiques tels que le thème, la vue d'ensemble et le style, GPT-4 est guidé pour produire des descriptions d'images clés cinématographiques adaptées au processus de génération ultérieur.
2. Processus de fixation du style.
MovieLLM utilise intelligemment la technologie "d'inversion textuelle" pour fixer la description de style générée dans le script à l'espace latent du modèle de diffusion. Cette méthode guide le modèle pour générer des scènes avec un style fixe et maintenir la diversité tout en conservant une esthétique unifiée.
3. Génération de données de commande vidéo.
Sur la base des deux premières étapes, une intégration de style fixe et une description d'image clé ont été obtenues. Sur cette base, MovieLLM utilise l'intégration de styles pour guider le modèle de diffusion afin de générer des images clés conformes aux descriptions des images clés et génère progressivement diverses paires de questions et réponses pédagogiques en fonction de l'intrigue du film.

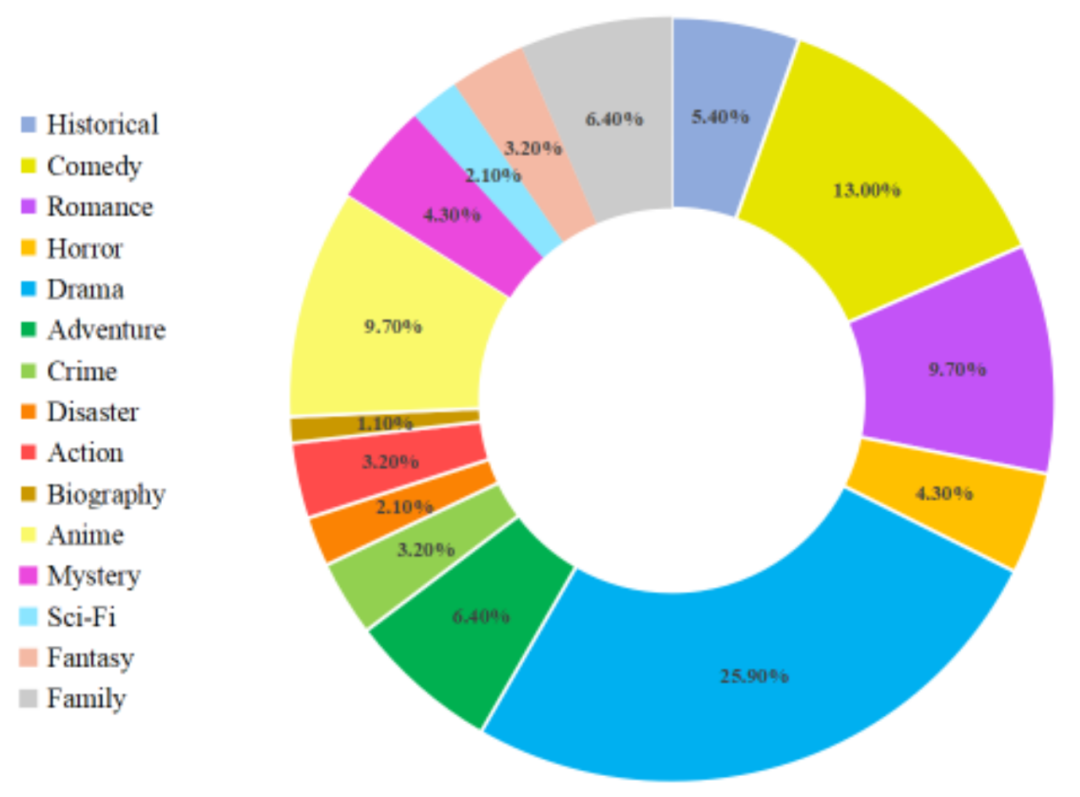
Après les étapes ci-dessus, MovieLLM a créé des styles variés et de haute qualité, des images de film cohérentes et des données de paires de questions et réponses correspondantes. La répartition détaillée des types de données de films est la suivante :
Résultats expérimentaux
En appliquant des données construites sur la base de MovieLLM pour un réglage fin sur LLaMA-VID, un grand modèle axé sur la compréhension de vidéos longues, cet article améliore considérablement la capacité du modèle à comprendre du contenu vidéo de différentes longueurs. Pour la compréhension des vidéos longues, il n'existe actuellement aucun travail proposant un benchmark de test, donc cet article propose également un benchmark pour tester les capacités de compréhension des vidéos longues.
Bien que MovieLLM n'ait pas construit spécifiquement de données vidéo courtes pour la formation, grâce à la formation, des améliorations de performances sur divers benchmarks vidéo courts ont quand même été observées :
Dans MSVD-QA et MSRVTT - Par rapport au. Dans le modèle de base, l'assurance qualité s'est considérablement améliorée sur ces deux ensembles de données de test.

Sur le benchmark de performances basé sur la génération vidéo, des améliorations de performances ont été obtenues dans les cinq domaines d'évaluation.
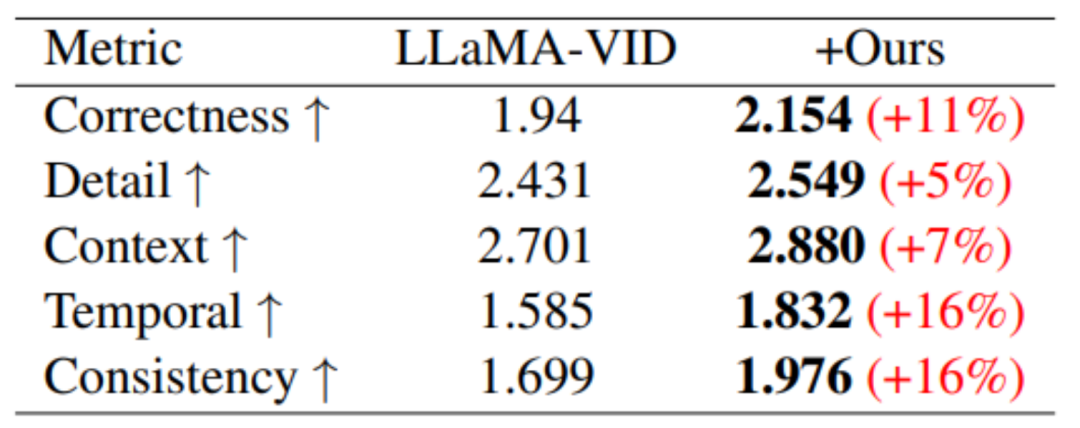
En termes de compréhension de vidéos longues, grâce à la formation de MovieLLM, la compréhension du modèle du résumé, de l'intrigue et du timing a été considérablement améliorée.

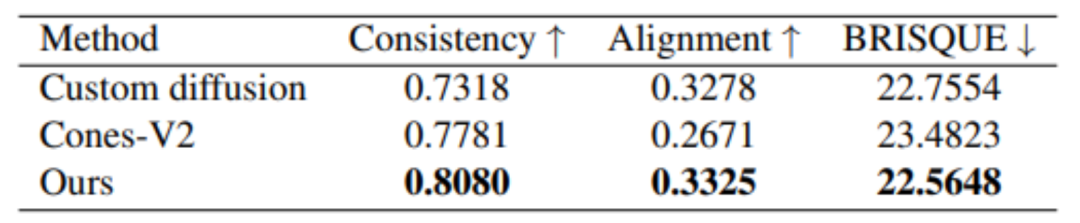
De plus, MovieLLM a également de meilleurs résultats en termes de qualité de génération par rapport à d'autres méthodes similaires de génération d'images de style fixe.
En bref, le workflow de génération de données proposé par MovieLLM réduit considérablement le défi de la production de données vidéo au niveau du film pour les modèles et améliore le contrôle et la diversité du contenu généré. Dans le même temps, MovieLLM améliore considérablement la capacité du modèle multimodal à comprendre les longues vidéos au niveau du film, fournissant ainsi une référence précieuse pour que d'autres domaines adoptent des méthodes de génération de données similaires.
Les lecteurs intéressés par cette recherche peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Comment apprendre Debian Syslog
Apr 13, 2025 am 11:51 AM
Ce guide vous guidera pour apprendre à utiliser Syslog dans Debian Systems. Syslog est un service clé dans les systèmes Linux pour les messages du système de journalisation et du journal d'application. Il aide les administrateurs à surveiller et à analyser l'activité du système pour identifier et résoudre rapidement les problèmes. 1. Connaissance de base de Syslog Les fonctions principales de Syslog comprennent: la collecte et la gestion des messages journaux de manière centralisée; Prise en charge de plusieurs formats de sortie de journal et des emplacements cibles (tels que les fichiers ou les réseaux); Fournir des fonctions de visualisation et de filtrage des journaux en temps réel. 2. Installer et configurer syslog (en utilisant RSYSLOG) Le système Debian utilise RSYSLOG par défaut. Vous pouvez l'installer avec la commande suivante: SudoaptupDatesud
