

AGI se rapproche vraiment !
Afin de garantir que les humains ne soient pas tués par l'IA, OpenAI n'a jamais cessé de décrypter la boîte noire du réseau neuronal/Transfomer.
En mai de l'année dernière, l'équipe OpenAI a publié une découverte choquante : GPT-4 peut en fait expliquer 300 000 neurones de GPT-2 !
Les internautes se sont exclamés que la sagesse se révèle être ainsi.
 Photos
Photos
Tout à l'heure, le chef de l'équipe de super alignement d'OpenAI a officiellement annoncé qu'il ouvrirait la source du Transformer Debugger, un outil tueur qui a été utilisé en interne.
En bref, les chercheurs peuvent utiliser les outils TDB pour analyser la structure interne de Transformer afin d'étudier le comportement spécifique des petits modèles.
 Pictures
Pictures
En d'autres termes, avec cet outil TDB, il peut nous aider à analyser et analyser AGI à l'avenir !
 Pictures
Pictures
Le débogueur Transformer combine des auto-encodeurs clairsemés avec une "interprétabilité automatique" développée par OpenAI - c'est-à-dire l'utilisation de grands modèles pour expliquer automatiquement les petits modèles et la technologie.
Lien : OpenAI fait exploser un nouveau travail : GPT-4 fissure le cerveau de GPT-2 ! Les 300 000 neurones ont été observés
 Photos
Photos
Adresse papier : https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html#sec-intro
Il convient de mentionner que les chercheurs peuvent explorer rapidement la structure interne du LLM sans écrire de code.
Par exemple, il peut répondre à des questions telles que "Pourquoi le modèle génère-t-il le jeton A au lieu du jeton B", "Pourquoi la tête d'attention H se concentre-t-elle sur le jeton T".
 Photos
Photos
Parce que le TDB peut soutenir les neurones et les têtes d'attention, il permet aux chercheurs d'intervenir dans la transmission directe en procédant à l'ablation de neurones individuels et d'observer les changements spécifiques qui se produisent.
Cependant, selon Jan Leike, cet outil est encore une première version. OpenAI l'a publié dans l'espoir que davantage de chercheurs puissent l'utiliser et l'améliorer davantage sur la base existante.
 Photos
Photos
Adresse du projet : https://github.com/openai/transformer-debugger
Pour comprendre le fonctionnement de ce Transformer Debugger, vous devez revoir OpenAI dans 2023 Une étude relative à l’alignement a été publiée en mai.

L'outil TDB est basé sur deux études déjà publiées et ne publiera pas d'articles
En termes simples, OpenAI espère utiliser un modèle (GPT-4) avec des paramètres plus grands et des capacités plus fortes pour analyser automatiquement les petits Comportement du modèle (GPT-2), expliquant son fonctionnement.
 Photos
Photos
Les résultats préliminaires de la recherche OpenAI à cette époque étaient que les modèles avec relativement peu de paramètres étaient faciles à comprendre, mais à mesure que les paramètres du modèle devenaient plus grands et que le nombre de couches augmentait, l'effet d'explication serait plomb.
 Photos
Photos
À cette époque, OpenAI a déclaré dans ses recherches que GPT-4 lui-même n'était pas conçu pour expliquer le comportement de petits modèles, de sorte que l'interprétation globale de GPT-2 était encore très mauvaise.
 Pictures
Pictures
Des algorithmes et des outils capables de mieux expliquer le comportement du modèle doivent être développés à l'avenir.
Le Transformer Debugger, désormais open source, est la réalisation progressive d'OpenAI au cours de l'année suivante.
Et ce "meilleur outil" - Transformer Debugger, combine "un encodeur automatique clairsemé" dans cette ligne technique consistant à "utiliser de grands modèles pour expliquer de petits modèles".
Ensuite, le précédent processus OpenAI consistant à utiliser GPT-4 pour expliquer les petits modèles dans la recherche sur l'interprétabilité était codé par zéro, abaissant ainsi considérablement le seuil permettant aux chercheurs de se lancer.
Sur la page d'accueil du projet GitHub, les membres de l'équipe OpenAI ont présenté le dernier outil de débogage Transformer à travers une vidéo.
Semblable au débogueur Python, TDB vous permet de parcourir la sortie du modèle de langage, de suivre les activations importantes et d'analyser les activations en amont.
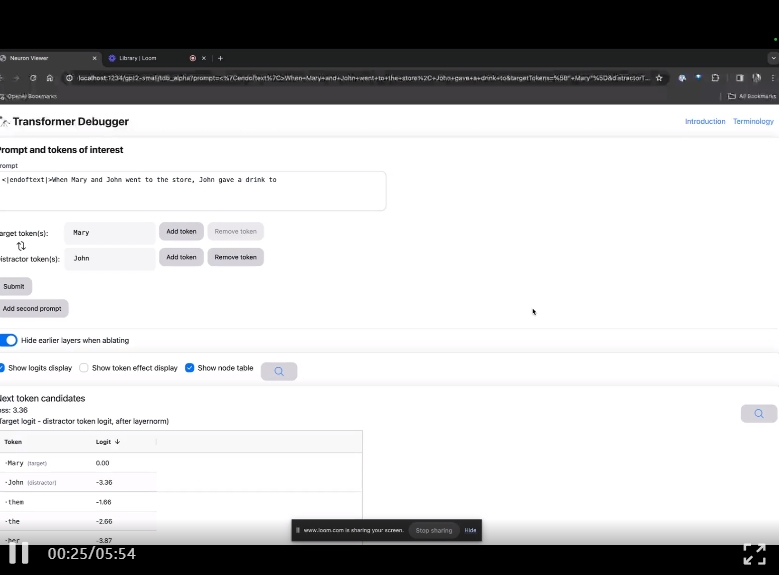
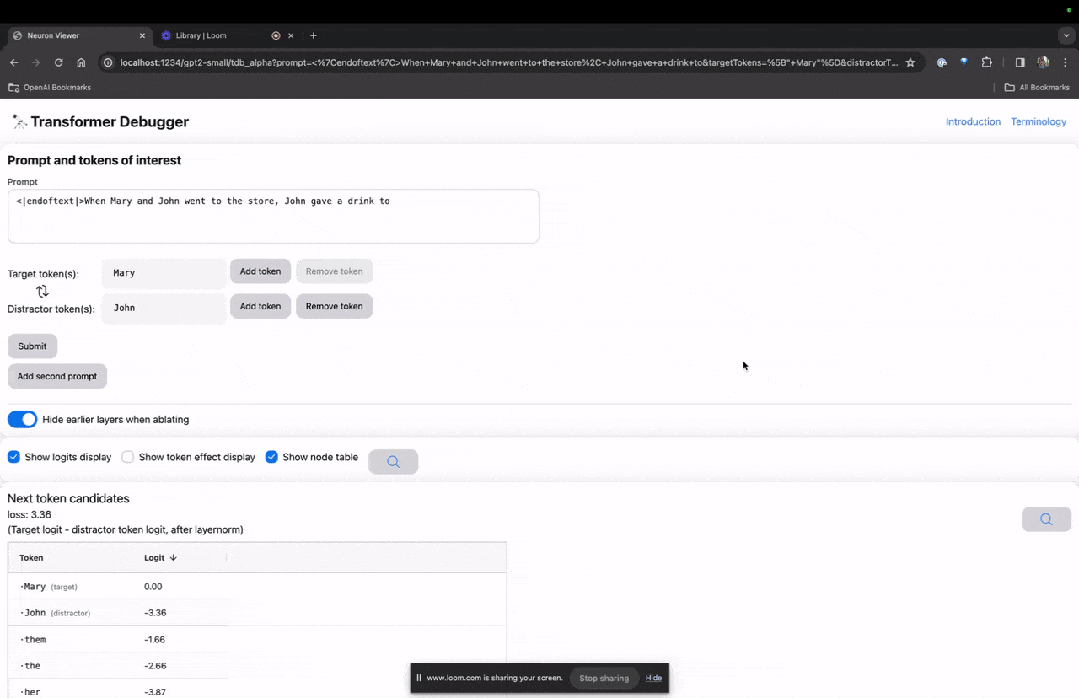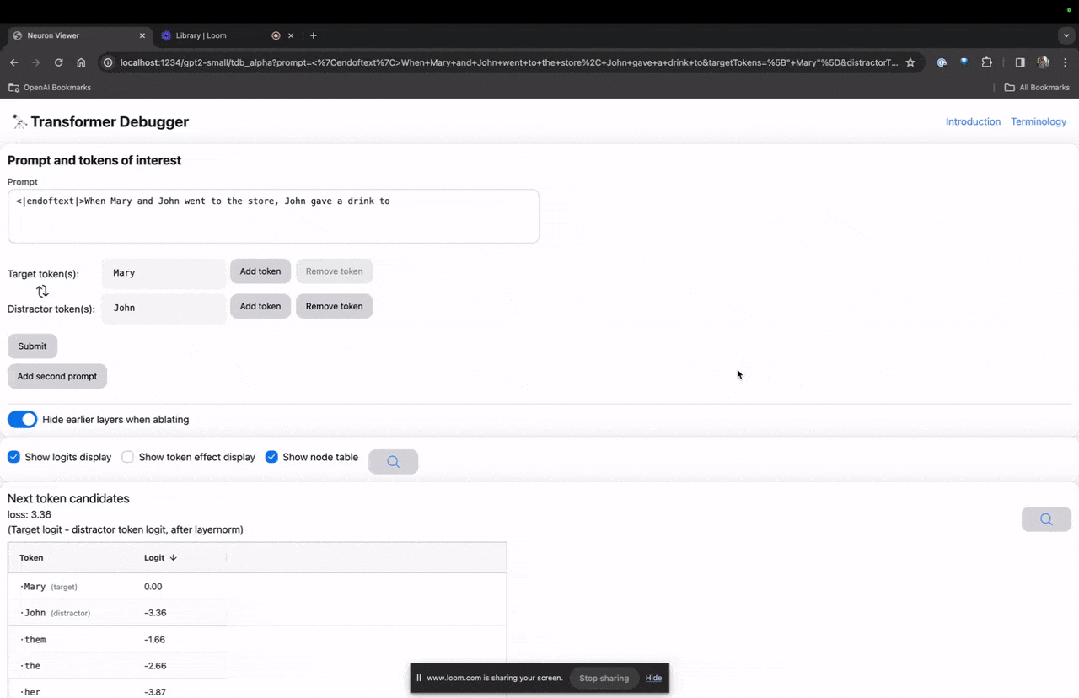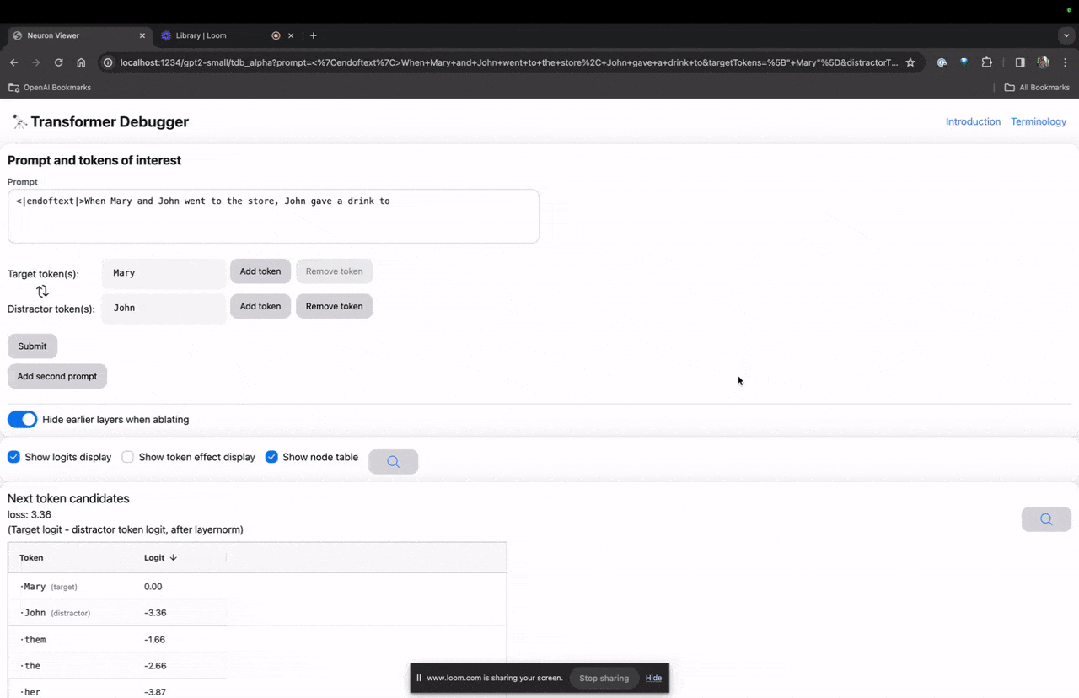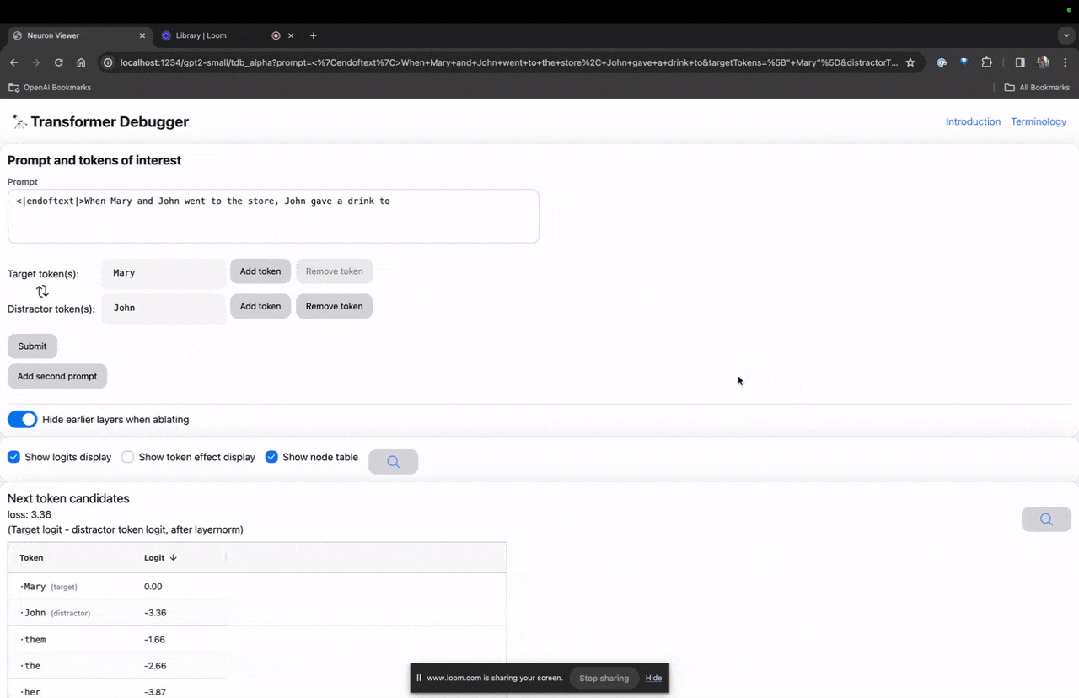
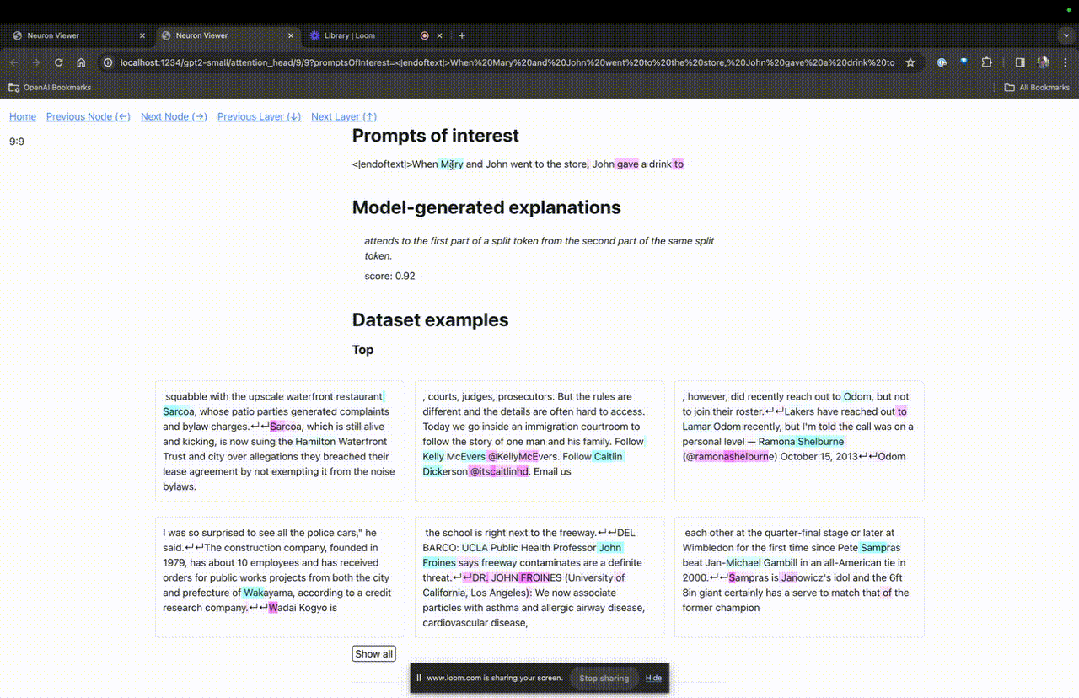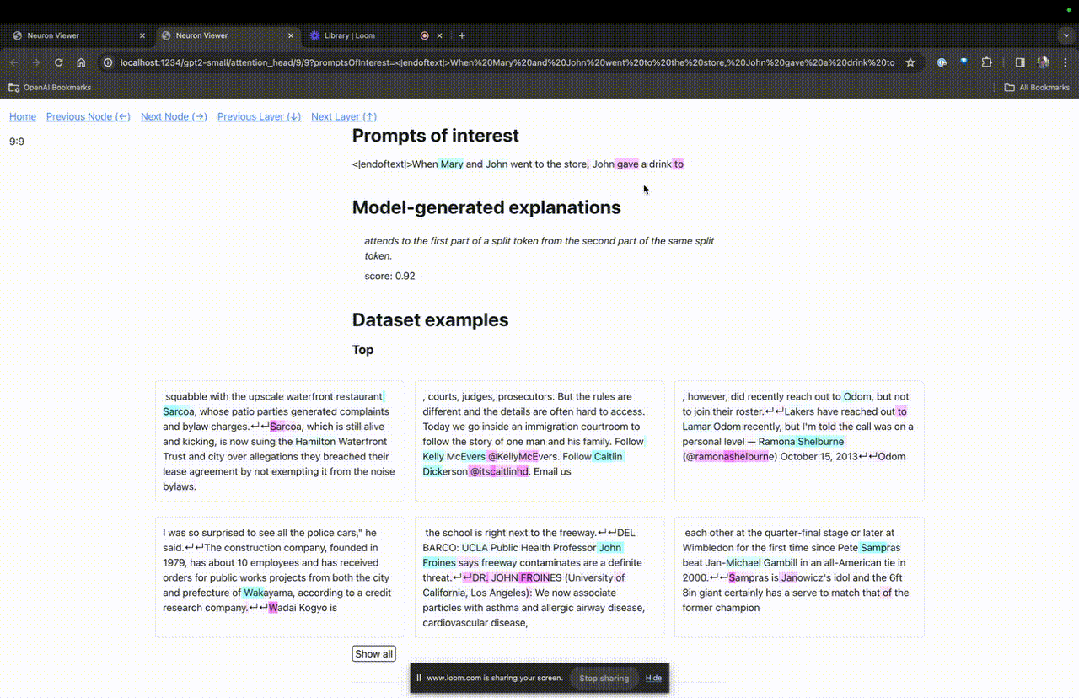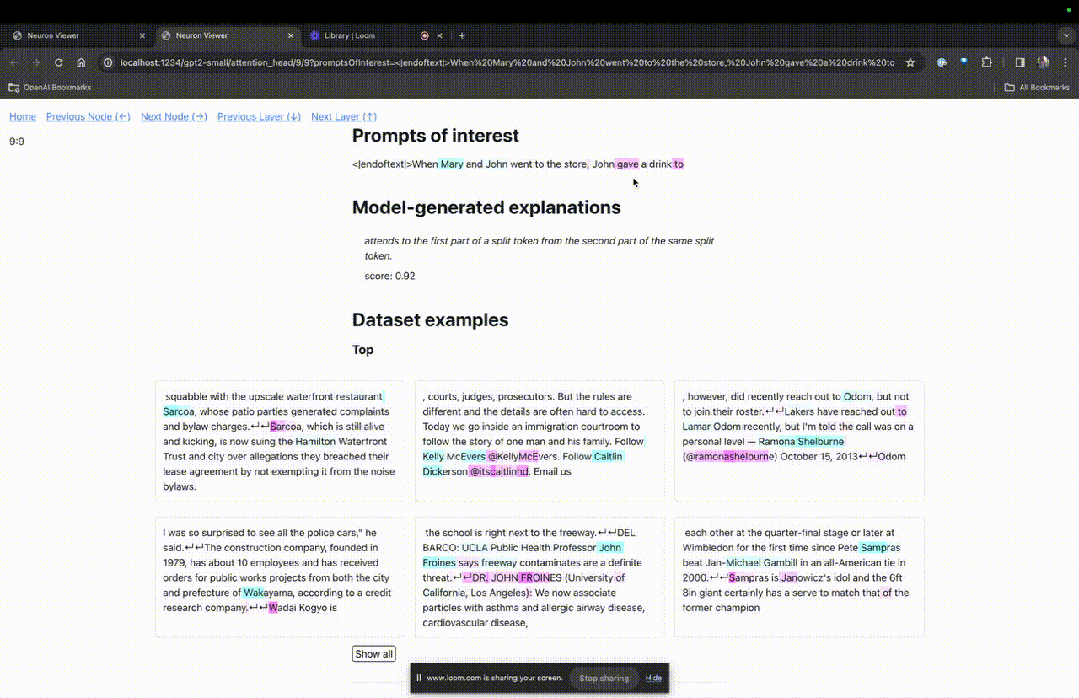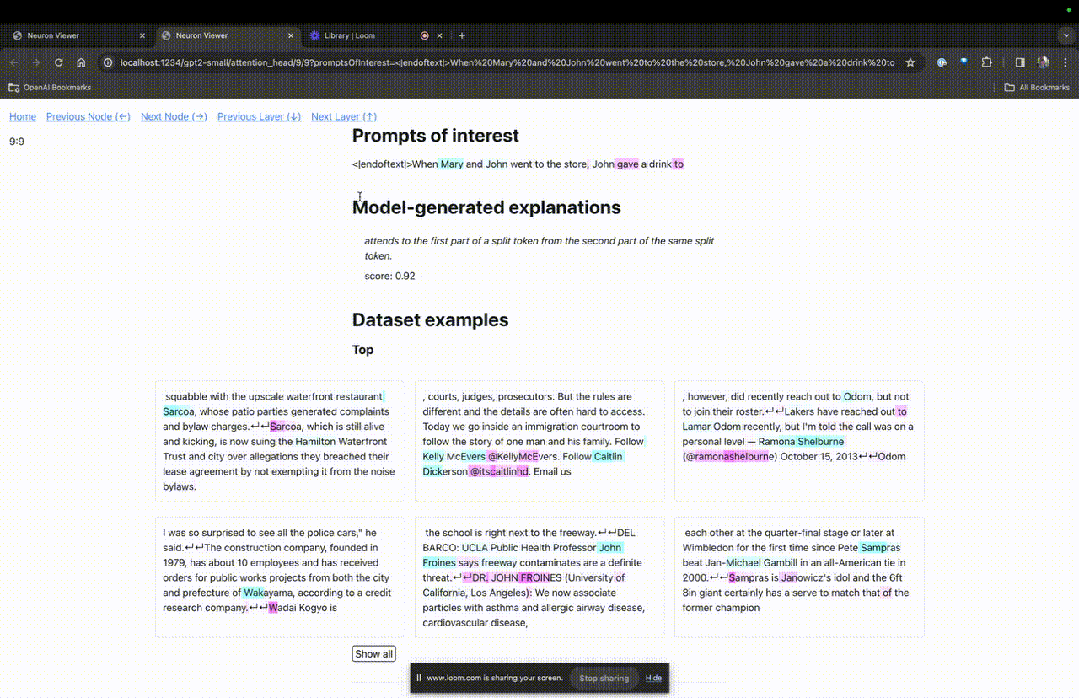
Entrez sur la page d'accueil de TDB, entrez d'abord dans la colonne "Invite" - invite et signe d'intérêt :
Mary et Johon sont allés au magasin, Johon a donné à boire à....
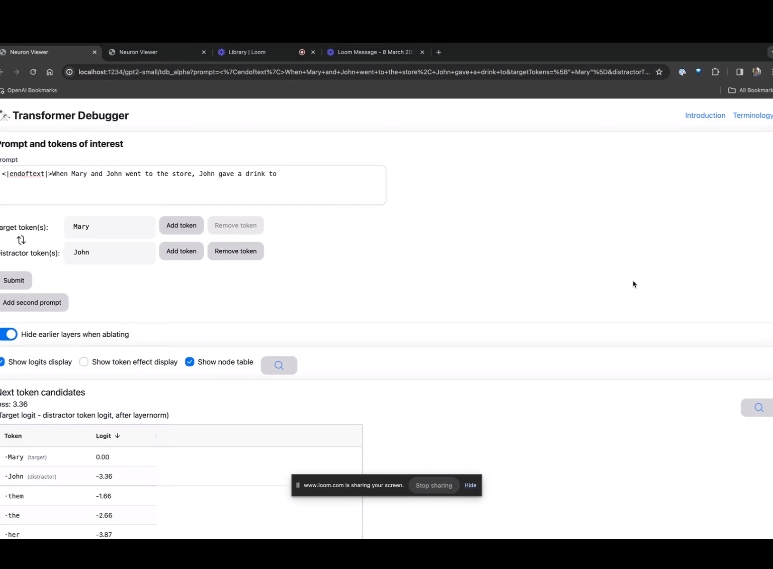
L'étape suivante consiste à effectuer une prédiction du « mot suivant », ce qui nécessite la saisie du jeton cible et des jetons interférents.
Après la soumission finale, vous pouvez voir le logarithme des candidats au mot suivant prédits donnés par le système.
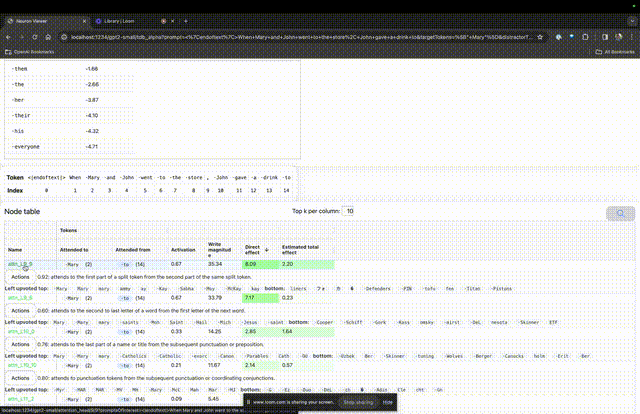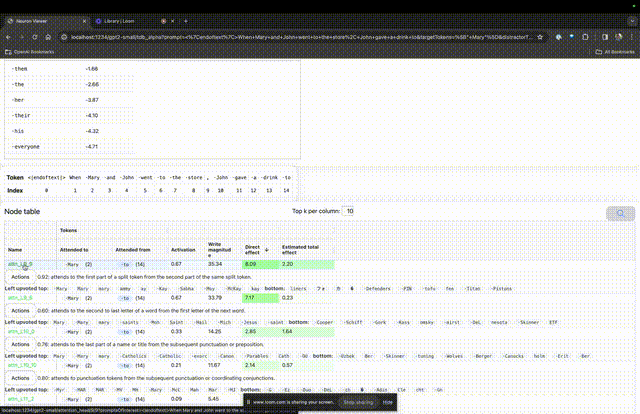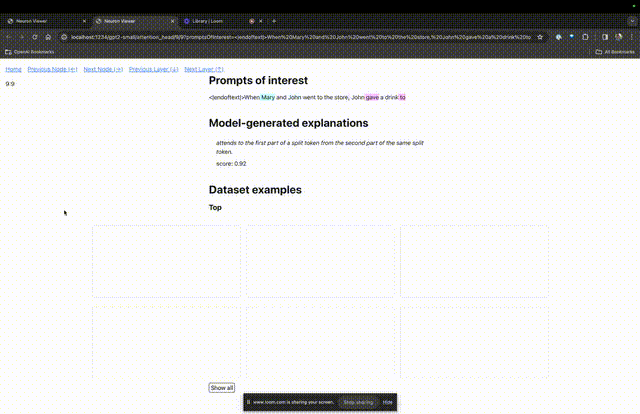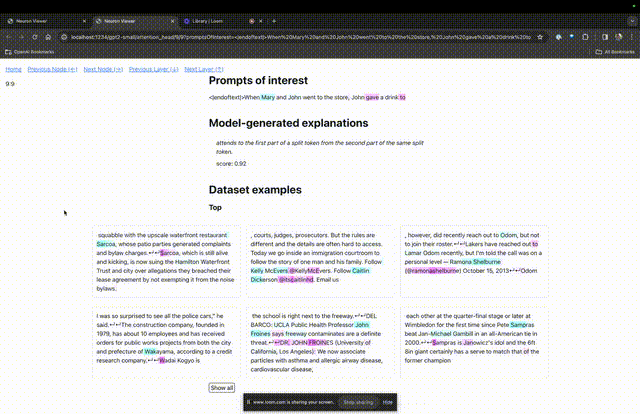
La "table des nœuds" ci-dessous est la partie essentielle de TDB. Chaque ligne correspond ici à un nœud qui active un composant de modèle.
 Images
Images
Si vous souhaitez connaître la fonction de la tête d'attention qui est très importante pour une invite spécifique, cliquez simplement sur le nom du composant.
Ensuite, TDB ouvrira la page "Neuron Browser" et les mots d'invite précédents seront affichés en haut.
 Photo
Photo
Vous pouvez voir les jetons bleu clair et roses ici. Sous chaque jeton de la couleur correspondante, l'attention des balises suivantes sur ce jeton entraînera l'écriture d'un grand vecteur de norme sur le jeton suivant.
 Pictures
Pictures
Dans deux autres vidéos, les chercheurs présentent le concept de TDB et son application dans la compréhension des boucles. Dans le même temps, il a également démontré comment TDB peut reproduire qualitativement l’une des conclusions de l’article.
En termes simples, l'idée de la recherche sur l'interprétabilité automatique OpenAI est de laisser GPT-4 interpréter le comportement des neurones en langage naturel, puis d'appliquer ce processus dans GPT -2.
Comment est-ce possible ? Tout d’abord, nous devons « décortiquer » le LLM.
Comme les cerveaux, ils sont constitués de « neurones » qui observent certains modèles dans le texte, ce qui détermine ce que le modèle entier dira ensuite.
Par exemple, si vous recevez une invite du type « Quels super-héros Marvel ont les super-pouvoirs les plus utiles ? » « Neurones de super-héros Marvel » peut augmenter la probabilité que le modèle nomme des super-héros spécifiques dans les films Marvel.
L'outil d'OpenAI utilise ce paramètre pour décomposer le modèle en parties distinctes.
Étape 1 : Utilisez GPT-4 pour générer des explications
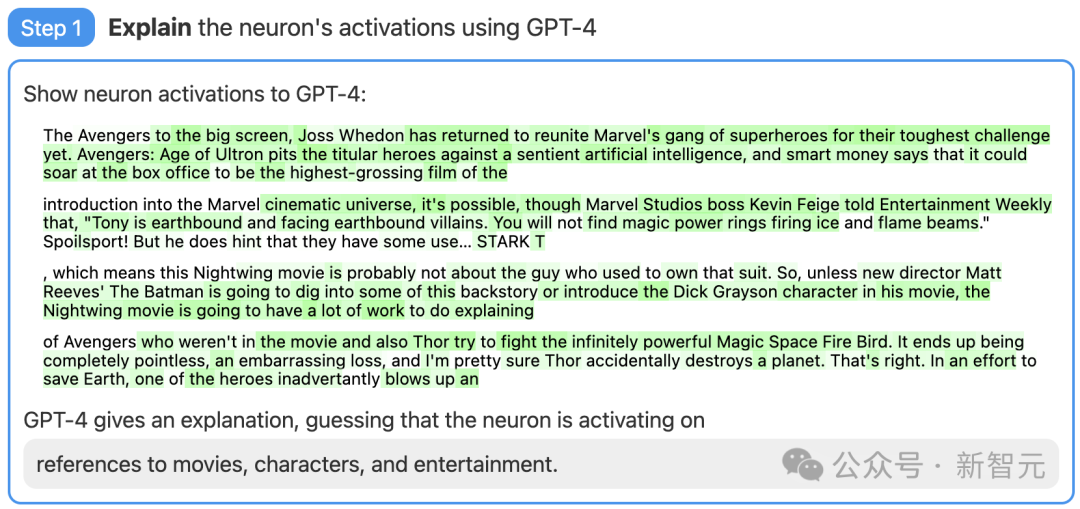
Tout d'abord, trouvez un neurone de GPT-2 et affichez la séquence de texte et l'activation pertinentes à GPT-4.
Ensuite, laissez GPT-4 générer une explication possible basée sur ces comportements.
Par exemple, dans l'exemple ci-dessous, GPT-4 estime que ce neurone est lié aux films, aux personnages et aux divertissements.
 Images
Images
Étape 2 : Utilisez GPT-4 pour simuler
Ensuite, laissez GPT-4 simuler ce que les neurones activés par cela feront en fonction de l'explication qu'il génère.
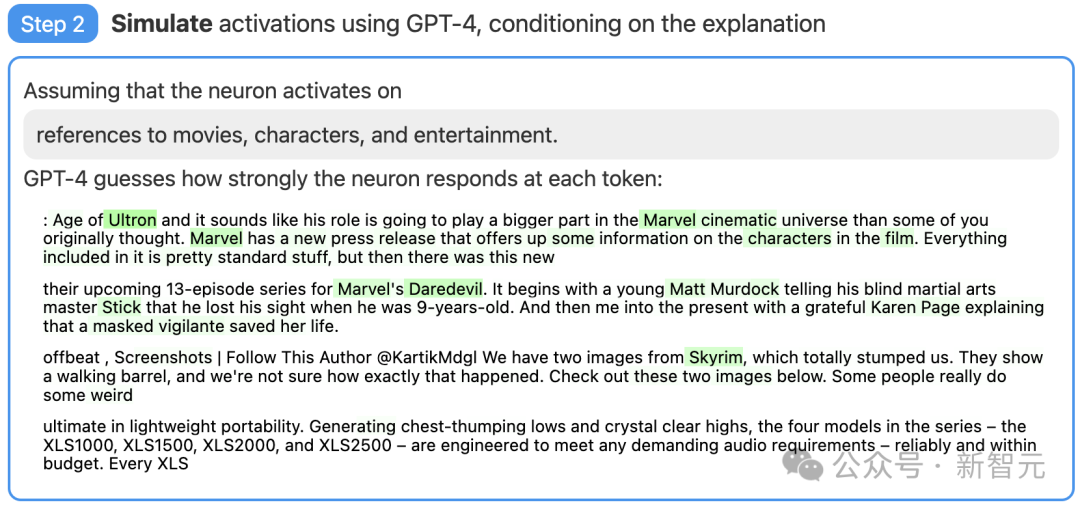 Photos
Photos
Troisième étape : Score comparatif
Enfin, comparez le comportement du neurone simulé (GPT-4) avec le comportement du neurone réel (GPT-2), voir Voyons voyez à quel point la supposition de GPT-4 est précise.
 Photos
Photos
En notant, les chercheurs d'OpenAI ont mesuré l'efficacité de cette technologie dans différentes parties du réseau neuronal. Cette technique n'explique pas aussi bien les modèles plus grands, probablement parce que les couches ultérieures sont plus difficiles à expliquer.
 Photos
Photos
Actuellement, la grande majorité des scores d'explication sont très faibles, mais les chercheurs ont également découvert qu'ils peuvent être améliorés en itérant les explications, en utilisant des modèles plus grands et en modifiant l'architecture des modèles expliqués. .
Maintenant, OpenAI ouvre l'ensemble de données et les outils de visualisation pour les résultats de "Utiliser GPT-4 pour expliquer les 307 200 neurones dans GPT-2", et réalise également l'interprétation et la notation des modèles existants sur le marché. public via le code de l’API OpenAI et appelle la communauté universitaire à développer de meilleures techniques qui produisent des explications plus performantes.
De plus, l'équipe a également constaté que plus le modèle est grand, plus le taux de cohérence de l'explication est élevé. Parmi eux, GPT-4 est le plus proche des humains, mais il existe encore un grand écart.
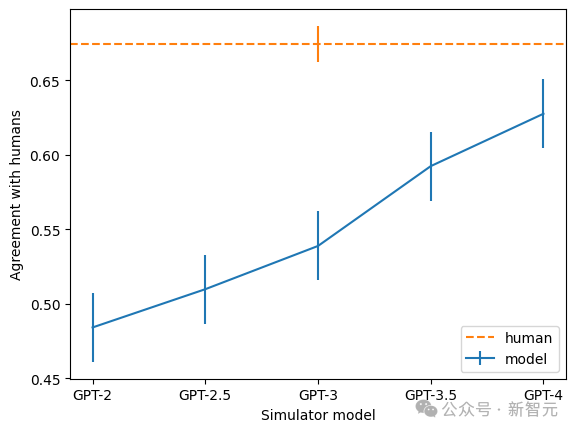 Photos
Photos
Ce qui suit sont des exemples de neurones dans différentes couches activées. Vous pouvez voir que plus la couche est haute, plus elle est abstraite.
 images
images
 images
images
 images
images
 images
images
L'encodeur automatique clairsemé utilisé par OpenAI est un modèle avec un biais sur l'entrée et comprend également une couche linéaire avec biais et ReLU pour l'encodeur, et une autre couche linéaire et biais pour le décodeur.
Les chercheurs ont découvert que le terme de biais est très important pour les performances de l'auto-encodeur. Ils relient le biais appliqué à l'entrée et à la sortie, et le résultat équivaut à soustraire le biais fixe de toutes les activations.
Les chercheurs ont utilisé l'optimiseur Adam pour entraîner un auto-encodeur afin de reconstruire l'activation MLP du Transformer à l'aide de MSE. L'utilisation de la perte MSE peut éviter le défi de la polysémantique et utiliser la perte plus une pénalité L1 pour encourager la parcimonie.
Plusieurs principes sont très importants lors de la formation des auto-encodeurs.
La première chose est l'échelle. Entraîner un auto-encodeur sur davantage de données rend les fonctionnalités subjectivement « plus nettes » et plus interprétables. OpenAI utilise donc 8 milliards de points de formation pour l'auto-encodeur.
Deuxièmement, pendant l'entraînement, certains neurones cesseront de fonctionner, même sur un grand nombre de points de données.
Les chercheurs ont ensuite "rééchantillonné" ces neurones morts pendant l'entraînement, permettant au modèle de représenter plus de fonctionnalités pour une dimension de couche cachée d'auto-encodeur donnée, produisant ainsi de meilleurs résultats.
Comment juger si votre méthode est efficace ? En apprentissage automatique, vous pouvez simplement utiliser la perte comme norme, mais il n'est pas facile de trouver une référence similaire ici.
Par exemple, rechercher une métrique basée sur les informations afin que, dans un sens, la meilleure décomposition soit celle qui minimise les informations totales de l'auto-encodeur et des données.
- Mais en fait, l'information totale n'a souvent rien à voir avec l'interprétabilité subjective des fonctionnalités ou la rareté de l'activation.
En fin de compte, les chercheurs ont utilisé une combinaison de plusieurs mesures supplémentaires :
- Inspection manuelle : les caractéristiques semblent-elles explicables ?
- Densité des fonctionnalités : le nombre de fonctionnalités en temps réel et le pourcentage de jetons qui les déclenchent est un guide très utile.
- Perte de reconstruction : mesure dans quelle mesure l'auto-encodeur reconstruit les activations MLP. Le but ultime est de prendre en compte la fonctionnalité de la couche MLP, la perte MSE doit donc être faible.
- Modèle de jouet : l'utilisation d'un modèle déjà bien compris permet une évaluation claire des performances de l'auto-encodeur.
Cependant, les chercheurs ont également exprimé leur espoir de déterminer de meilleurs indicateurs pour les solutions d'apprentissage de dictionnaires à partir des auto-encodeurs clairsemés formés sur Transformer.
Référence :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



