
 Périphériques technologiques
IA
Que faire s'il n'y a pas de données de bout en bout ? ActiveAD : Apprentissage actif de bout en bout pour la conduite autonome pour la planification !
Périphériques technologiques
IA
Que faire s'il n'y a pas de données de bout en bout ? ActiveAD : Apprentissage actif de bout en bout pour la conduite autonome pour la planification !
Que faire s'il n'y a pas de données de bout en bout ? ActiveAD : Apprentissage actif de bout en bout pour la conduite autonome pour la planification !


L'apprentissage différenciable de bout en bout pour la conduite autonome est récemment devenu un paradigme important. Un goulot d’étranglement majeur réside dans l’énorme demande de données étiquetées de haute qualité, telles que les boîtes 3D et la segmentation sémantique, dont l’annotation manuelle est notoirement coûteuse. Cette difficulté est aggravée par le fait saillant que le comportement au sein de l’échantillon dans l’AD a souvent des distributions à longue traîne. En d’autres termes, la plupart des données collectées peuvent être triviales (par exemple, rouler sur une route droite), seules quelques situations étant critiques pour la sécurité. Dans cet article, nous explorons une question pratiquement importante mais sous-explorée, à savoir comment atteindre l’efficacité des échantillons et des étiquettes dans l’AD de bout en bout.
Plus précisément, l'article conçoit une méthode d'apprentissage actif orientée planification qui annote progressivement des parties des données brutes collectées en fonction de la diversité et des critères d'utilité des itinéraires de planification proposés. Empiriquement, l’approche proposée axée sur le plan peut surpasser dans une large mesure les approches générales d’apprentissage actif. Notamment, notre méthode atteint des performances comparables aux méthodes AD de bout en bout de pointe en utilisant seulement 30 % des données nuScenes. Espérons que notre travail inspirera les travaux futurs dans une perspective centrée sur les données, en plus des efforts méthodologiques.
Lien papier : https://arxiv.org/pdf/2403.02877.pdf
Contribution principale de cet article :
- La première personne à étudier en profondeur les problématiques de données de l'E2E-AD. Fournit également une solution simple mais efficace pour identifier et annoter des données précieuses pour la planification dans le cadre d'un budget limité.
- Sur la base de la philosophie orientée planification de l'approche de bout en bout, de nouvelles mesures de diversité et d'incertitude spécifiques aux tâches sont conçues pour la planification des itinéraires.
- Des expériences approfondies et des études d'ablation ont prouvé l'efficacité de la méthode. ActiveAD surpasse largement les méthodes peer-to-peer génériques et atteint des performances comparables à celles des méthodes SOTA avec des étiquettes complètes en utilisant seulement 30 % des données nuScenes.
Introduction à la méthode
ActiveAD est décrit en détail dans le cadre AD de bout en bout, et les indicateurs de diversité et d'incertitude sont conçus en fonction des caractéristiques des données d'AD.
1) Sélection initiale d'échantillons d'étiquettes
Pour l'apprentissage actif en vision par ordinateur, la sélection initiale d'échantillons est généralement basée uniquement sur l'image originale sans informations supplémentaires ni fonctionnalités apprises, ce qui conduit à la pratique courante de l'initialisation aléatoire. Dans le cas de la MA, des informations préalables supplémentaires sont disponibles. Plus précisément, lors de la collecte de données provenant de capteurs, des informations traditionnelles telles que la vitesse et la trajectoire du véhicule autonome peuvent être enregistrées simultanément. De plus, les conditions météorologiques et d’éclairage sont souvent continues et faciles à annoter au niveau des fragments. Ces informations facilitent la prise de décisions éclairées pour la sélection initiale des ensembles. Par conséquent, nous avons conçu une mesure d’auto-diversité pour la sélection initiale.
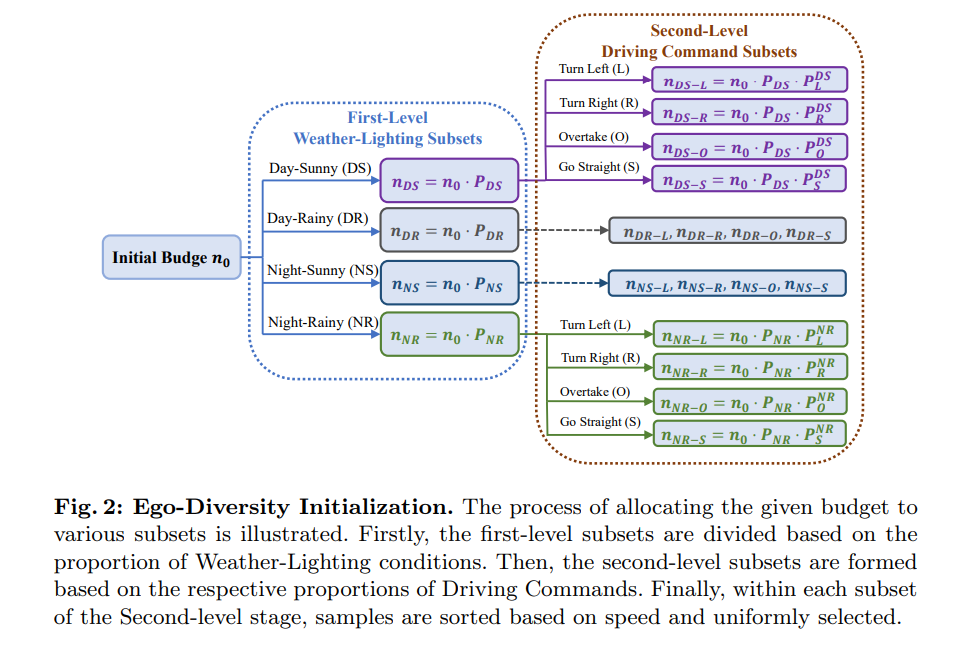
Ego Diversity : Se compose de trois parties : 1) Éclairage météo 2) Instructions de conduite 3) Vitesse moyenne. Tout d'abord, utilisez la description dans nuScenes pour diviser l'ensemble de données complet en quatre sous-ensembles mutuellement exclusifs : Day Sunny (DS), Day Rainy (DR), Night Sunny (NS), NightRainy (NR). Deuxièmement, chaque sous-ensemble est divisé en quatre catégories en fonction du nombre de commandes de conduite à gauche, à droite et en ligne droite dans un segment complet : virage à gauche (L), virage à droite (R), dépassement (O) et aller tout droit (S). L'article conçoit un seuil τc, où si le nombre de commandes gauche et droite dans un clip est supérieur ou égal au seuil τc, nous le considérons comme un comportement transcendant dans le clip. Si seul le nombre de commandes à gauche est supérieur au seuil τc, cela indique un virage à gauche. Si seul le nombre de commandes vers la droite est supérieur au seuil τc, cela indique un virage à droite. Tous les autres cas sont considérés comme directs. Troisièmement, calculez la vitesse moyenne dans chaque scène et triez-la par ordre croissant au sein du sous-ensemble concerné.
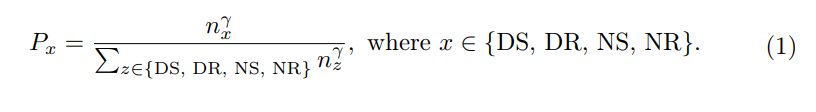
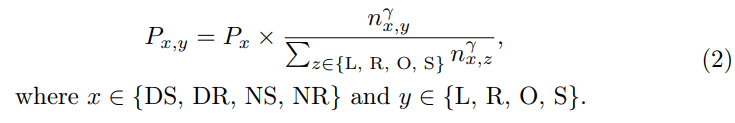
La figure 2 donne le processus intuitif détaillé du processus de sélection initial basé sur des arbres multi-voies.
2) Conception de critères pour la sélection incrémentielle
Dans cette section, nous présenterons comment annoter de manière incrémentale de nouvelles parties d'un fragment sur la base d'un modèle entraîné à l'aide de fragments déjà annotés. Nous utiliserons le modèle intermédiaire pour effectuer une inférence sur des segments non étiquetés, et les sélections ultérieures seront basées sur ces sorties. Néanmoins, une perspective orientée vers la planification est adoptée et trois critères pour la sélection ultérieure des données sont introduits : les erreurs de déplacement, les collisions douces et les incertitudes proxy.
Standard 1 : Erreur de déplacement (DE). sera exprimée comme la distance entre l’itinéraire prévu τ du modèle et les trajectoires humaines τ* enregistrées dans l’ensemble de données.
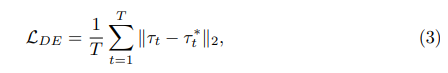
où T représente le cadre dans la scène. Puisque l’erreur de déplacement est elle-même une mesure de performance (aucune annotation requise), elle devient naturellement le premier et le plus critique critère de sélection active.
Standard 2 : Collision douce (SC). Le LSC est défini comme la distance entre la trajectoire prédite du véhicule autonome et la trajectoire prédite de l’agent. Les prédictions des agents de faible confiance seront filtrées par le seuil ε. Dans chaque scénario, la distance la plus courte est choisie comme mesure du coefficient de risque. Dans le même temps, une corrélation positive est maintenue entre terme et distance la plus proche :
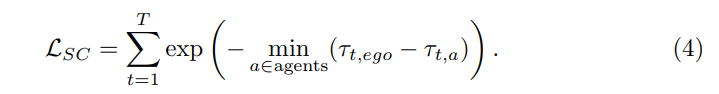
Utiliser la « collision douce » comme critère car : D'une part, contrairement à « l'erreur de déplacement », le calcul du « taux de collision » dépend sur la 3D de la cible Annotations pour les cases qui ne sont pas disponibles dans les données non étiquetées. Par conséquent, il devrait être possible de calculer le critère uniquement sur la base des résultats d’inférence du modèle. D'un autre côté, considérons un critère de collision dure : si la trajectoire prédite du véhicule personnel entre en collision avec les trajectoires d'autres agents prédits, attribuez-lui 1, sinon attribuez-lui 0. Cependant, cela peut entraîner un nombre insuffisant d'échantillons avec l'étiquette 1, car le taux de collision des modèles de pointe en AD est généralement faible (moins de 1 %). Par conséquent, il a été choisi d’utiliser la distance la plus proche des autres paires de cibles au lieu de la métrique du « taux de collision ». Le risque est considéré comme beaucoup plus élevé lorsque la distance par rapport aux autres véhicules ou aux piétons est trop proche. En bref, les « collisions légères » constituent une mesure efficace de la probabilité de collision et peuvent fournir une surveillance intensive.
Critère III : Incertitude de l'agent (AU). Les prédictions des trajectoires futures des agents environnants sont naturellement incertaines, de sorte que les modules de prédiction de mouvement génèrent généralement plusieurs modalités et scores de confiance correspondants. Notre objectif est de sélectionner les données pour lesquelles les agents proches ont une forte incertitude. Plus précisément, les sujets distants sont filtrés par un seuil de distance δ, et l'entropie pondérée des probabilités prédites de plusieurs modes pour les sujets restants est calculée. Supposons que le nombre de modalités est et que le score de confiance de l'agent dans différentes modalités est Pi(a), où i∈{1,…,Nm}. Ensuite, l'incertitude de l'agent peut être définie comme :
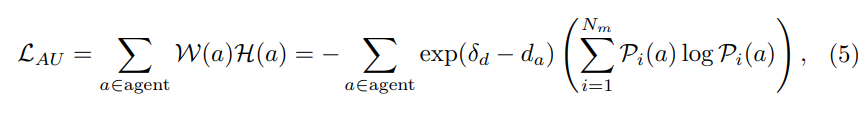
Perte globale :
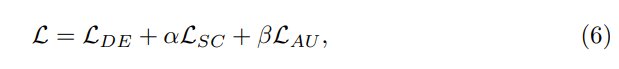
3) Paradigme global d'apprentissage actif
Alg1 présente l'ensemble du flux de travail de la méthode. Étant donné un budget disponible B, une taille de sélection initiale n0, le nombre de sélections d'activités effectuées à chaque étape ni et un total de M étapes de sélection. La sélection est d'abord initialisée à l'aide des méthodes de randomisation ou d'auto-diversité décrites ci-dessus. Ensuite, les données actuellement annotées sont utilisées pour entraîner le réseau. Sur la base du réseau formé, nous faisons des prédictions sur ceux non étiquetés et calculons la perte totale. Enfin, les échantillons sont triés en fonction de la perte globale et les ni meilleurs échantillons à annoter dans l'itération en cours sont sélectionnés. Ce processus est répété jusqu'à ce que l'itération atteigne la limite supérieure M et que le nombre d'échantillons sélectionnés atteigne la limite supérieure B.

Résultats expérimentaux
Des expériences ont été menées sur l'ensemble de données nuScenes largement utilisé. Toutes les expériences sont mises en œuvre à l'aide de PyTorch et exécutées sur les GPU RTX 3090 et A100.
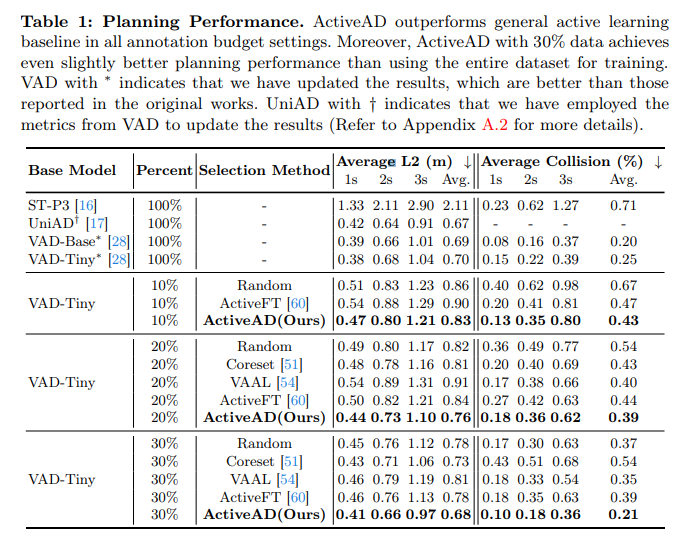
Tableau 1 : Performance de la planification. ActiveAD surpasse les références générales d'apprentissage actif dans tous les paramètres de budget d'annotation. De plus, ActiveAD avec 30 % des données a obtenu des performances de planification légèrement meilleures par rapport à la formation utilisant l'intégralité de l'ensemble de données. Les VAD avec * indiquent des résultats mis à jour qui sont meilleurs que ceux rapportés dans le travail original. UniAD avec † indique que les indicateurs de VAD ont été utilisés pour mettre à jour les résultats.
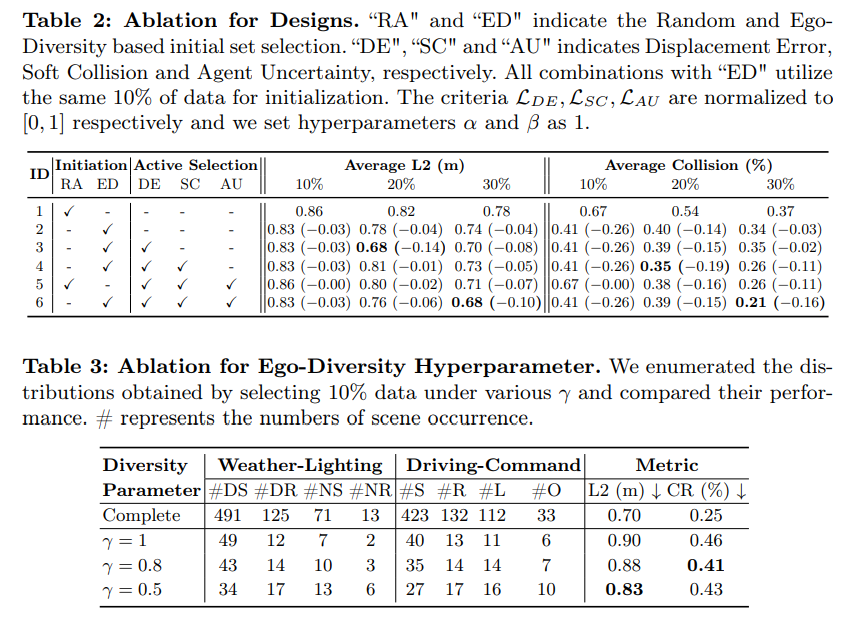
Tableau 2 : Expérience d'ablation conçue. « RA » et « ED » représentent la sélection initiale de l'ensemble basée sur le caractère aléatoire et l'auto-diversité. «DE», «SC» et «AU» représentent respectivement les erreurs de déplacement, qui sont respectivement une collision douce et une incertitude d'agent. Toutes les combinaisons avec « ED » sont initialisées avec les mêmes données à 10 %. LDE, LSC et LAU sont respectivement normalisés à [0, 1] et les hyperparamètres α et β sont définis sur 1.
Figure 3 : Visualisation des scènes sélectionnées. Critères d'erreur de déplacement (col 1), de collision douce (col 2), d'incertitude de l'agent (col 3) et hybride (col 4) basés sur des images de caméra frontale sélectionnées sur la base d'un modèle entraîné sur 10 % des données. Mixed représente notre stratégie de choix final, ActiveAD, et prend en considération les trois premiers scénarios !

Tableau 4, performances dans divers scénarios. Plus le taux de collision moyen L2(m)/moyen (%) du modèle actif utilisant 30 % des données est faible, meilleures sont les performances dans diverses conditions météorologiques/d'éclairage et de commande de conduite.
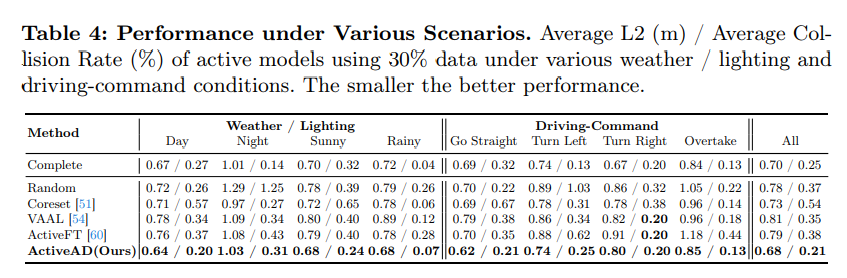
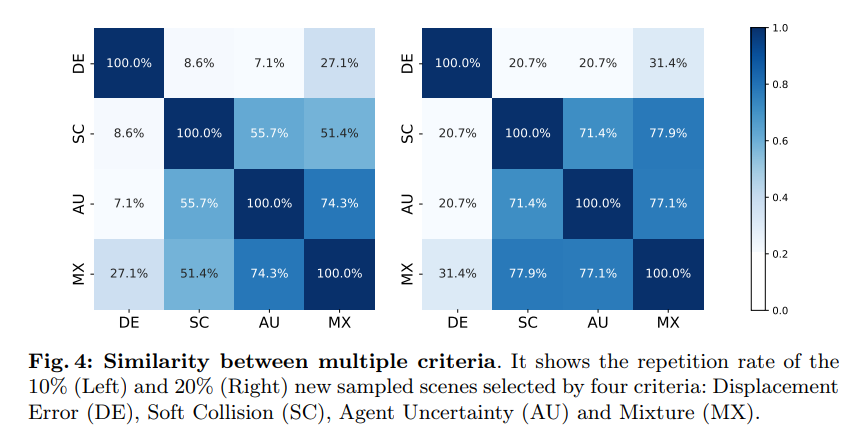
Figure 4 : Similitude entre plusieurs critères. Il montre le nouveau scénario d'échantillonnage avec 10 % (à gauche) et 20 % (à droite) sélectionnés selon quatre critères : erreur de déplacement (DE), collision douce (SC), incertitude de l'agent (AU) et mélange (MX)
Quelques conclusions de ce travail
Afin de résoudre les problèmes de coût élevé et de longue traîne de l'annotation de bout en bout des données de conduite autonome, nous avons pris l'initiative de développer une solution d'apprentissage actif sur mesure, ActiveAD. ActiveAD introduit de nouvelles mesures de diversité et d'incertitude spécifiques aux tâches, basées sur une philosophie orientée planification. Un grand nombre d'expériences prouvent l'efficacité de la méthode, utilisant seulement 30 % des données, elle dépasse largement les méthodes générales précédentes et atteint des performances comparables aux modèles de l'état de l'art. Cela représente une exploration significative de la conduite autonome de bout en bout dans une perspective centrée sur les données, et nous espérons que nos travaux pourront inspirer de futures recherches et découvertes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
