
 développement back-end
Tutoriel Python
Laboratoire d'analyse de données Python : expérimentation et exploration
développement back-end
Tutoriel Python
Laboratoire d'analyse de données Python : expérimentation et exploration
Laboratoire d'analyse de données Python : expérimentation et exploration


python est un langage de programmation puissant qui est largement utilisé pour l'analyse des données. Cet atelier est conçu pour vous permettre d'explorer divers aspects de l'analyse des données dans Python à travers une série d'expériences. Grâce à ces exercices pratiques, vous acquerrez une compréhension approfondie des concepts de base du traitement des données, de la visualisation et de la modélisation.
Expérience 1 : Chargement et exploration de données
- Importer et manipuler des fichiers CSV
- Explorez les structures de données à l'aide de NumPy et pandas
- Calculer des statistiques de base comme la moyenne et l'écart type
- Filtrer et trierles données pour identifier les modèles
Expérience 2 : Visualisation des données
- Créez des graphiques linéaires, des histogrammes et des nuages de points avec Matplotlib
- Personnalisez l'apparence de la visualisation, y compris la couleur, la largeur des lignes et les étiquettes
- Utilisez Seaborn pour créer des visualisations plus avancées telles que des cartes thermiques et des diagrammes de cluster
Expérience 3 : Prétraitement des données
- Traitement des valeurs manquantes, y compris suppression, remplissage et interpolation
- Détection et exclusion des valeurs aberrantes
- Normalisation et mise à l'échelle des données pour améliorer les performances de modélisation
Expérience 4 : Modélisation de l'apprentissage automatique
- Comprendre les principes de base de l'apprentissage supervisé et de l'apprentissage non supervisé
- Formez et évaluez des modèles de régression linéaire, de régression logistique et d'arbre de décision avec Scikit-learn
- Optimiserles paramètres du modèle pour améliorer la précision des prédictions
Expérience 5 : Analyse des séries chronologiques
- Charger et traiter les données de séries chronologiques
- Dessiner des graphiques de séries chronologiques à l'aide de Pandas et de Statsmodels
- Identifier les tendances, la saisonnalité et la périodicité dans les séries chronologiques
Expérience 6 : Analyse de texte
- Utilisez Natural Language Toolkit (NLTK) pour traiter les données textuelles
- Effectuez une analyse de la fréquence des mots, des racines de mots et une analyse des sentiments
- Explorez la classification de texte et la modélisation de sujets
Conclusion
Ces expériences offrent une expérience pratique et vous permettent d'explorer la puissance de l'analyse des données Python. En effectuant ces exercices, vous maîtriserez les concepts de base du chargement, de l'exploration, de la visualisation, du prétraitement, de la modélisation et de l'analyse de texte des données. Ces compétences vous donneront une base solide pour réussir dans une variété de projets d'analyse de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



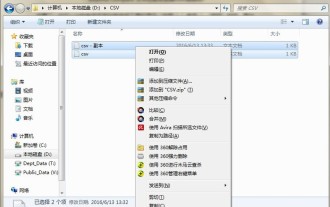 Méthode de fonctionnement détaillée pour comparer les fichiers CSV avec Beyond Compare
Apr 22, 2024 am 11:52 AM
Méthode de fonctionnement détaillée pour comparer les fichiers CSV avec Beyond Compare
Apr 22, 2024 am 11:52 AM
Après avoir installé le logiciel BeyondCompare, sélectionnez le fichier CSV à comparer, cliquez avec le bouton droit sur le fichier et sélectionnez l'option [Comparer] dans le menu développé. La session de comparaison de texte sera ouverte par défaut. Vous pouvez cliquer sur la barre d'outils de la session de comparaison de texte pour afficher respectivement les boutons [Toutes [,] Différences [ et [Identique]] afin d'afficher les différences de fichiers de manière plus intuitive et plus précise. Méthode 2 : ouvrez BeyondCompare en mode de comparaison de tables, sélectionnez la session de comparaison de tables et ouvrez l'interface d'opération de session. Cliquez sur le bouton [Ouvrir le fichier] et sélectionnez le fichier CSV à comparer. Cliquez sur le bouton du signe d'inégalité [≠] dans la barre d'outils de l'interface d'opération de la session de comparaison de tableaux pour afficher les différences entre les fichiers.
 Que signifie l'instantané de la monnaie numérique ? Apprenez-en davantage sur l'instantané de la monnaie numérique dans un article
Mar 26, 2024 am 09:51 AM
Que signifie l'instantané de la monnaie numérique ? Apprenez-en davantage sur l'instantané de la monnaie numérique dans un article
Mar 26, 2024 am 09:51 AM
Pour certains investisseurs novices qui viennent d'entrer dans le cercle des devises, ils rencontreront toujours un vocabulaire professionnel au cours du processus d'investissement. Ce vocabulaire professionnel est créé pour faciliter l'investissement des investisseurs, mais en même temps, ce vocabulaire peut aussi être relativement difficile à comprendre. . L’instantané de monnaie numérique que nous vous présentons aujourd’hui est un concept relativement professionnel dans le cercle monétaire. Comme nous le savons tous, le marché du Bitcoin évolue très rapidement, il est donc souvent nécessaire de prendre des instantanés pour comprendre les changements sur le marché et nos processus opérationnels. De nombreux investisseurs ne savent peut-être toujours pas ce que signifient les instantanés de monnaie numérique. Laissez maintenant l'éditeur vous présenter un article pour comprendre l'instantané de la monnaie numérique. Que signifie l’instantané de la monnaie numérique ? Un instantané de monnaie numérique est un moment sur une blockchain spécifiée (c'est-à-dire
 Comment lire un fichier CSV en Python
Mar 28, 2024 am 10:34 AM
Comment lire un fichier CSV en Python
Mar 28, 2024 am 10:34 AM
Méthode de lecture : 1. Créez un exemple de fichier python ; 2. Importez le module csv, puis utilisez la fonction open pour ouvrir le fichier CSV ; 3. Passez l'objet fichier à la fonction csv.reader, puis utilisez une boucle for pour parcourir et lire chaque ligne de données ; 4. , imprimez simplement chaque ligne de données.
 Comment exporter les données interrogées dans Navicat
Apr 24, 2024 am 04:15 AM
Comment exporter les données interrogées dans Navicat
Apr 24, 2024 am 04:15 AM
Exporter les résultats de la requête dans Navicat : exécuter la requête. Cliquez avec le bouton droit sur les résultats de la requête et sélectionnez Exporter les données. Sélectionnez le format d'exportation selon vos besoins : CSV : le séparateur de champ est une virgule. Excel : inclut les en-têtes de tableau, au format Excel. Script SQL : contient les instructions SQL utilisées pour recréer les résultats de la requête. Sélectionnez les options d'exportation (telles que l'encodage, les sauts de ligne). Sélectionnez l'emplacement d'exportation et le nom du fichier. Cliquez sur "Exporter" pour lancer l'exportation.
 Comment lire des fichiers CSV avec Pycharm
Apr 03, 2024 pm 08:45 PM
Comment lire des fichiers CSV avec Pycharm
Apr 03, 2024 pm 08:45 PM
Les étapes pour lire les fichiers CSV dans PyCharm sont les suivantes : Importez le module csv. Ouvrez le fichier CSV à l'aide de la fonction open(). Utilisez la fonction csv.reader() pour lire le contenu du fichier CSV. Parcourez chaque ligne et obtenez les données du champ sous forme de liste. Traitez les données dans le fichier CSV, comme l'impression ou un traitement ultérieur.
 Pièges du gouffre du gestionnaire de paquets Python : comment les éviter
Apr 01, 2024 am 09:21 AM
Pièges du gouffre du gestionnaire de paquets Python : comment les éviter
Apr 01, 2024 am 09:21 AM
Le gestionnaire de packages Python est un outil puissant et pratique pour gérer et installer des packages Python. Cependant, si vous ne faites pas attention lors de son utilisation, vous risquez de tomber dans divers pièges. Cet article décrit ces pièges et les stratégies pour aider les développeurs à les éviter. Piège 1 : problème de conflit d'installation : lorsque plusieurs packages fournissent des fonctions ou des classes portant le même nom mais des versions différentes, des conflits d'installation peuvent survenir. Réponse : Vérifiez les dépendances avant l'installation pour vous assurer qu'il n'y a pas de conflits entre les packages. Utilisez l'option --no-deps de pip pour éviter l'installation automatique des dépendances. Piège 2 : problèmes de package avec les anciennes versions : si une version n'est pas spécifiée, le gestionnaire de packages peut installer la dernière version même s'il existe une version plus ancienne, plus stable ou adaptée à vos besoins. Réponse : Spécifiez explicitement la version requise lors de l'installation, par exemple p
 Installez facilement le langage Go à l'aide de la boîte à outils CSV-TK
Mar 26, 2024 pm 01:33 PM
Installez facilement le langage Go à l'aide de la boîte à outils CSV-TK
Mar 26, 2024 pm 01:33 PM
Dans le domaine actuel du développement logiciel, le langage Go, en tant que langage de programmation rapide et efficace, est privilégié par de plus en plus de développeurs. Au cours du processus d'installation du langage Go, la boîte à outils CSV-TK est devenue un outil pratique et pratique pour aider les développeurs à installer et configurer facilement l'environnement du langage Go. Ensuite, nous présenterons en détail comment utiliser la boîte à outils CSV-TK pour installer facilement le langage Go, ainsi que quelques exemples de code spécifiques. Tout d’abord, nous devons comprendre ce qu’est la boîte à outils CSV-TK et ce qu’elle fait. CSV-TK est
 L'avenir des collections simultanées en Java : explorer de nouvelles fonctionnalités et tendances
Apr 03, 2024 am 09:20 AM
L'avenir des collections simultanées en Java : explorer de nouvelles fonctionnalités et tendances
Apr 03, 2024 am 09:20 AM
Avec l'essor des systèmes distribués et des processeurs multicœurs, les collections simultanées sont devenues cruciales dans le développement de logiciels modernes. Les collections simultanées Java fournissent des implémentations de collections efficaces et sécurisées tout en gérant la complexité de l'accès simultané. Cet article explore l'avenir des collections simultanées en Java, en se concentrant sur les nouvelles fonctionnalités et tendances. Nouvelle fonctionnalité JSR354 : collectes simultanées résilientes jsR354 définit une nouvelle interface de collecte simultanée avec un comportement élastique pour garantir performances et fiabilité même dans des conditions de concurrence extrêmes. Ces interfaces fournissent des fonctionnalités supplémentaires d'atomicité, telles que la prise en charge des invariants mutables et des itérations non bloquantes. RxJava3.0 : Collections simultanées réactives RxJava3.0 introduit le concept de programmation réactive, permettant aux collections simultanées d'être facilement intégrées aux flux de données réactifs.
