

Les grands modèles génératifs ont provoqué des changements majeurs dans le domaine de l'intelligence artificielle. Bien que l'espoir des gens de parvenir à une intelligence artificielle générale (AGI) augmente, la puissance de calcul requise pour former et déployer de grands modèles devient également de plus en plus énorme.
Tout à l'heure, Meta a annoncé le lancement de deux clusters GPU 24k (un total de 49 152 H100), marquant l'investissement majeur de Meta dans l'avenir de l'intelligence artificielle.
Cela fait partie du plan d’infrastructure ambitieux de Meta. D’ici fin 2024, Meta prévoit d’étendre son infrastructure pour inclure 350 000 GPU NVIDIA H100, ce qui lui donnera une puissance de calcul équivalente à près de 600 000 H100. Meta s'engage à étendre continuellement son infrastructure pour répondre aux besoins futurs.
Meta a souligné : « Nous soutenons fermement l'informatique ouverte et la technologie open source. Nous avons construit ces clusters informatiques sur la base de Grand Teton, OpenRack et PyTorch, et continuerons à promouvoir l'innovation ouverte dans l'ensemble du secteur. Un cluster de ressources informatiques pour former Llama 3. "
Yann LeCun, lauréat du prix Turing et scientifique en chef du Meta, a également tweeté pour souligner ce point.
Meta a partagé des détails sur le matériel, le réseau, le stockage, la conception, les performances et les logiciels du nouveau cluster, conçu pour fournir un débit élevé et une fiabilité élevée pour une variété de charges de travail d'intelligence artificielle.
La vision à long terme de Meta est de construire une intelligence artificielle générale ouverte et responsable afin que chacun puisse l'utiliser et en bénéficier largement.
En 2022, Meta a partagé pour la première fois les détails d'un super cluster de recherche sur l'IA (RSC) équipé de 16 000 GPU NVIDIA A100. RSC a joué un rôle important dans le développement de Llama et Llama 2, ainsi que dans le développement de modèles avancés d'intelligence artificielle en vision par ordinateur, PNL, reconnaissance vocale, génération d'images, encodage, etc.
Le dernier cluster d'IA de Meta s'appuie sur les succès et les leçons tirées de la phase précédente. Meta souligne son engagement à construire un système complet d'intelligence artificielle et se concentre sur l'amélioration de l'expérience et de l'efficacité du travail des chercheurs et des développeurs.
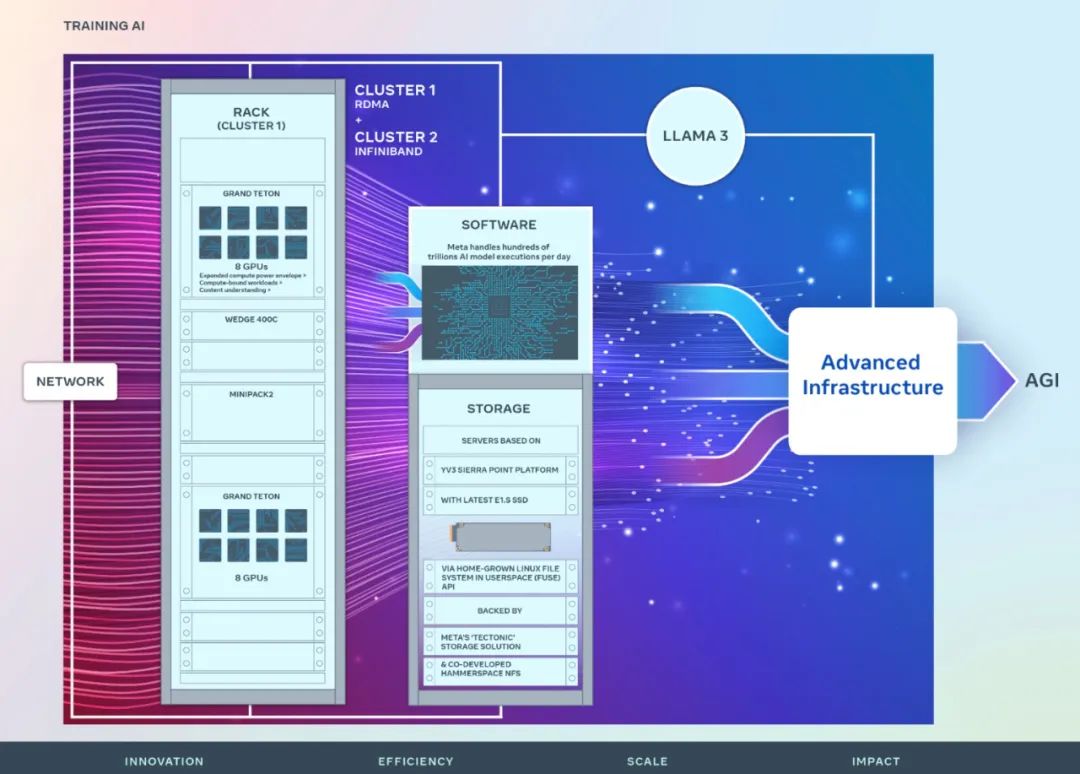
La structure réseau hautes performances utilisée dans les deux nouveaux clusters, combinée à des décisions de stockage clés et à 24 576 GPU NVIDIA Tensor Core H100 dans chaque cluster, permet à ces deux clusters de prendre en charge des modèles de cluster plus grands et plus complexes que le modèle de cluster RSC.
Network
Meta traite des centaines de milliards d'exécutions de modèles d'IA chaque jour. La diffusion de modèles d'IA à grande échelle nécessite une infrastructure très avancée et flexible.
Afin d'optimiser l'expérience de bout en bout pour les chercheurs en intelligence artificielle tout en garantissant le fonctionnement efficace du centre de données de Meta, Meta a construit un protocole de communication réseau en cluster basé sur les commutateurs rack Arista 7800 et Wedge400 et Minipack2 OCP, un réseau. cluster de structure qui implémente l'accès direct à la mémoire à distance (RDMA) sur Ethernet. L'autre cluster utilise une structure NVIDIA Quantum2 InfiniBand. Les deux solutions interconnectent des points de terminaison à 400 Gbit/s.
Ces deux nouveaux clusters peuvent être utilisés pour évaluer l'adéquation et l'évolutivité de différents types d'interconnexions pour une formation à grande échelle, aidant Meta à comprendre comment concevoir et construire des clusters à plus grande échelle à l'avenir. Grâce à une co-conception minutieuse de l'architecture du réseau, des logiciels et du modèle, Meta a réussi à exploiter les clusters RoCE et InfiniBand pour de grandes charges de travail GenAI sans aucun goulot d'étranglement réseau.
Compute
Les deux clusters sont construits à l'aide de Grand Teton, une plate-forme matérielle GPU ouverte conçue en interne chez Meta.
Grand Teton est construit sur plusieurs générations de systèmes d'IA, intégrant des interfaces d'alimentation, de contrôle, de calcul et de structure dans un seul châssis pour de meilleures performances globales, une meilleure intégrité du signal et des performances thermiques. Il offre une évolutivité et une flexibilité rapides dans une conception simplifiée, lui permettant d'être rapidement déployé dans les flottes de centres de données et facilement entretenu et étendu.
Stockage
Le stockage joue un rôle important dans la formation en IA, mais c'est l'un des aspects dont on parle le moins.
Au fil du temps, les efforts de formation GenAI sont devenus plus multimodaux, consommant de grandes quantités de données d'images, de vidéos et de texte, et la demande de stockage de données a augmenté rapidement.
Metas Speicherbereitstellung für den neuen Cluster erfüllt die Daten- und Checkpointing-Anforderungen des KI-Clusters über die Native Linux File System (FUSE) API im Benutzerbereich, die auf der verteilten Speicherlösung „Tectonic“ von Meta basiert. Diese Lösung ermöglicht es Tausenden von GPUs, Prüfpunkte synchron zu speichern und zu laden und bietet gleichzeitig den flexiblen und durchsatzstarken Speicher im Exabyte-Bereich, der zum Laden von Daten erforderlich ist.
Meta arbeitet auch mit Hammerspace zusammen, um gemeinsam die parallele Bereitstellung von Network File System (NFS) zu entwickeln und zu implementieren. Mit Hammerspace können Ingenieure interaktives Debuggen von Jobs mit Tausenden von GPUs durchführen.
Leistung
Meta Eines der Prinzipien für den Aufbau großer Cluster für künstliche Intelligenz besteht darin, gleichzeitig Leistung und Benutzerfreundlichkeit zu maximieren. Dies ist ein wichtiges Prinzip für die Erstellung erstklassiger KI-Modelle.
Meta Wenn man die Grenzen von Systemen mit künstlicher Intelligenz ausreizt, kann man die Fähigkeiten eines skalierbaren Designs am besten testen, indem man einfach ein System baut, es dann optimiert und tatsächlich testet (Simulatoren sind zwar hilfreich, können aber nur bedingt gehen). ).
In diesem Design verglich Meta die Leistung kleiner und großer Cluster, um zu verstehen, wo die Engpässe liegen. Im Folgenden wird die kollektive AllGather-Leistung (ausgedrückt als normalisierte Bandbreite auf einer Skala von 0–100) gezeigt, wenn eine große Anzahl von GPUs mit der Kommunikationsgröße mit der höchsten erwarteten Leistung miteinander kommuniziert.
Die Out-of-the-Box-Leistung großer Cluster ist im Vergleich zur optimierten Leistung kleiner Cluster zunächst schlecht und inkonsistent. Um dieses Problem zu beheben, hat Meta einige Änderungen an der Art und Weise vorgenommen, wie der interne Job-Scheduler auf die Kenntnis der Netzwerktopologie abgestimmt ist, was Latenzvorteile mit sich bringt und den Datenverkehr zu den oberen Schichten des Netzwerks minimiert.
Meta optimiert außerdem Netzwerk-Routing-Richtlinien in Verbindung mit Änderungen der NVIDIA Collective Communications Library (NCCL) für eine optimale Netzwerkauslastung. Dies trägt dazu bei, dass große Cluster die gleiche erwartete Leistung erzielen wie kleinere Cluster.
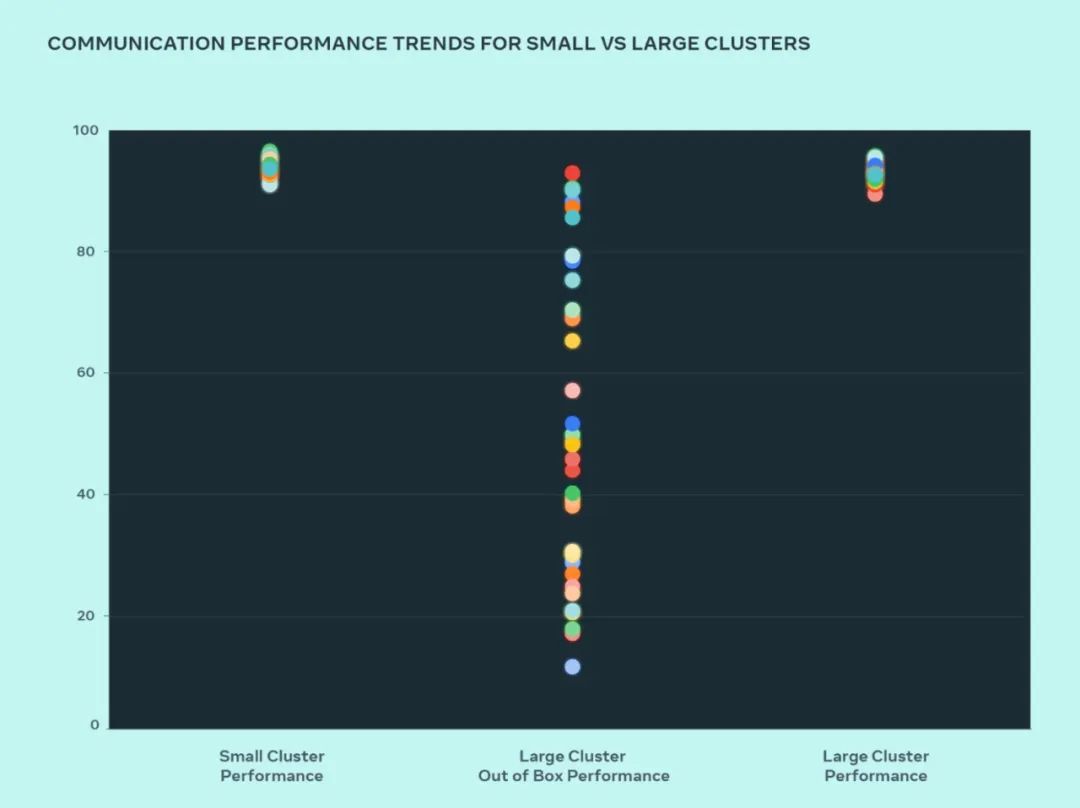
Aus der Abbildung können wir ersehen, dass die Leistung des kleinen Clusters (Gesamtkommunikationsbandbreite und -auslastung) standardmäßig über 90 % erreicht, die Leistungsauslastung des nicht optimierten großen Clusters jedoch sehr niedrig ist und bei 10 % liegt von 90 % auf 90 %. Nach der Optimierung des gesamten Systems (Software, Netzwerk usw.) stellten wir fest, dass die Leistung großer Cluster in den idealen Bereich von über 90 % zurückkehrte.
Neben Softwareänderungen an der internen Infrastruktur arbeitet Meta eng mit den Teams zusammen, die Trainingsrahmen und -modelle schreiben, um sie an die sich entwickelnde Infrastruktur anzupassen. Beispielsweise eröffnet die NVIDIA H100-GPU die Möglichkeit, mit neuen Datentypen wie 8-Bit-Gleitkomma (FP8) zu trainieren. Um die Vorteile größerer Cluster voll auszuschöpfen, sind Investitionen in zusätzliche Parallelisierungstechniken und neue Speicherlösungen erforderlich, die die Möglichkeit bieten, Prüfpunkte auf Tausenden von Ebenen so zu optimieren, dass sie in Hunderten von Millisekunden ausgeführt werden.
Meta erkennt auch, dass die Debugbarkeit eine der größten Herausforderungen beim Training im großen Maßstab ist. Die Identifizierung fehlerhafter GPUs, die das gesamte Training blockieren, ist im großen Maßstab schwierig. Meta entwickelt Tools wie asynchrones Debugging oder verteilte kollektive Flugaufzeichnungen, um die Details verteilter Schulungen offenzulegen und dabei zu helfen, auftretende Probleme schneller und einfacher zu identifizieren.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



