
 Périphériques technologiques
IA
Le grand modèle MM1 d'Apple arrive sur le marché : 30 milliards de paramètres, multimodal, architecture MoE, plus de la moitié des auteurs sont chinois
Périphériques technologiques
IA
Le grand modèle MM1 d'Apple arrive sur le marché : 30 milliards de paramètres, multimodal, architecture MoE, plus de la moitié des auteurs sont chinois
Le grand modèle MM1 d'Apple arrive sur le marché : 30 milliards de paramètres, multimodal, architecture MoE, plus de la moitié des auteurs sont chinois

Depuis cette année, Apple a évidemment accru l'accent et ses investissements dans l'intelligence artificielle générative (GenAI). Lors de la récente assemblée des actionnaires d'Apple, le PDG d'Apple, Tim Cook, a déclaré que la société prévoyait de réaliser des progrès significatifs dans le domaine de GenAI cette année. En outre, Apple a annoncé qu'elle abandonnait son projet de construction automobile de 10 ans, ce qui a amené certains membres de l'équipe initialement engagés dans la construction automobile à se tourner vers le domaine GenAI.
À travers ces initiatives, Apple a démontré au monde extérieur sa détermination à renforcer GenAI. Actuellement, la technologie GenAI et les produits dans le domaine multimodal ont attiré beaucoup d’attention, en particulier Sora d’OpenAI. Apple espère naturellement faire une percée dans ce domaine.
Dans un article de recherche co-écrit "MM1 : Méthodes, analyses et informations sur la pré-formation multimodale LLM", Apple a divulgué les résultats de ses recherches basées sur la pré-formation multimodale et a lancé une bibliothèque contenant jusqu'à 30 milliards de séries LLM multimodales paramétriques. modèle.

Adresse papier : https://arxiv.org/pdf/2403.09611.pdf
Dans la recherche, l'équipe a mené une discussion approfondie sur la criticité des différents composants architecturaux et la sélection des données. Grâce à une sélection minutieuse d'encodeurs d'images, de connecteurs de langage visuel et de diverses données de pré-formation, ils ont résumé quelques directives de conception importantes. Plus précisément, les principales contributions de cette étude comprennent les aspects suivants.
Tout d'abord, les chercheurs ont mené des expériences d'ablation à petite échelle sur les décisions d'architecture des modèles et la sélection des données de pré-entraînement, et ont découvert plusieurs tendances intéressantes. L'importance des aspects de conception de la modélisation est dans l'ordre suivant : résolution de l'image, perte et capacité de l'encodeur visuel et données de pré-entraînement de l'encodeur visuel.
Deuxièmement, les chercheurs ont utilisé trois types différents de données de pré-entraînement : les légendes d'images, le texte d'image entrelacé et les données en texte brut. Ils ont constaté que lorsqu'il s'agit de performances en quelques plans et en texte uniquement, les données d'entraînement entrelacées et en texte uniquement sont très importantes, tandis que pour les performances en plans zéro, les données de sous-titres sont les plus importantes. Ces tendances persistent après un réglage fin supervisé (SFT), indiquant que les décisions de performance et de modélisation présentées lors de la pré-formation sont préservées après un réglage fin.
Enfin, les chercheurs ont construit MM1, une série de modèles multimodaux avec des paramètres allant jusqu'à 30 milliards (d'autres sont 3 milliards et 7 milliards), qui se compose de modèles denses et de variantes d'experts mixtes (MoE). atteindre SOTA dans les mesures de pré-formation, il maintient également des performances compétitives après un réglage fin supervisé sur une série de références multimodales existantes.
Le modèle pré-entraîné MM1 fonctionne de manière supérieure sur les sous-titres et les tâches de questions et réponses dans des scénarios à quelques plans, surpassant Emu2, Flamingo et IDEFICS. MM1, après réglage fin supervisé, montre également une forte compétitivité sur 12 benchmarks multimodaux.
Grâce à un pré-entraînement multimodal à grande échelle, MM1 a de bonnes performances en prédiction de contexte, en raisonnement multi-images et en chaîne de pensée. De même, MM1 démontre de solides capacités d’apprentissage en quelques coups après le réglage des instructions.


Aperçu de la méthode : Le secret de la construction de MM1
Construire un MLLM (Multimodal Large Language Model) hautes performances est une tâche très pratique. Bien que la conception de l'architecture de haut niveau et le processus de formation soient clairs, les méthodes spécifiques de mise en œuvre ne sont pas toujours évidentes. Dans ces travaux, les chercheurs décrivent en détail les ablations réalisées pour construire des modèles performants. Ils ont exploré trois principales orientations décisionnelles en matière de conception :
- Architecture : les chercheurs ont examiné différents encodeurs d'images pré-entraînés et ont exploré diverses méthodes de connexion des LLM avec ces encodeurs.
- Données : Les chercheurs ont examiné différents types de données et leurs poids de mélange relatifs.
- Procédure de formation : les chercheurs ont exploré comment entraîner le MLLM, y compris les hyperparamètres et quelles parties du modèle ont été entraînées à quel moment.
Paramètres d'ablation
Étant donné que la formation d'un grand MLLM consomme beaucoup de ressources, les chercheurs ont adopté des paramètres d'ablation simplifiés. La configuration de base de l'ablation est la suivante :
- Encodeur d'image : modèle ViT-L/14 entraîné avec perte CLIP sur DFN-5B et VeCap-300M ; la taille de l'image est de 336 × 336.
- Connecteur de langage visuel : C-Abstractor, contenant 144 jetons d'image.
- Données de pré-formation : images de sous-titres mixtes (45%), documents de texte image entrelacés (45%) et données en texte brut (10%).
- Modèle de langage : modèle de langage de décodeur de transformateur 1.2B.
Pour évaluer différentes décisions de conception, les chercheurs ont utilisé les performances de zéro plan et de quelques plans (4 et 8 échantillons) sur diverses tâches VQA et de description d'image : COCO Captioning, NoCaps, TextCaps, VQAv2, TextVQA, VizWiz, GQA. et OK-VQA.
Expérience d'ablation d'architecture de modèle
Les chercheurs ont analysé les composants qui permettent à LLM de traiter les données visuelles. Plus précisément, ils ont étudié (1) comment pré-entraîner de manière optimale les encodeurs visuels et (2) comment connecter les caractéristiques visuelles à l'espace des LLM (voir Figure 3 à gauche).
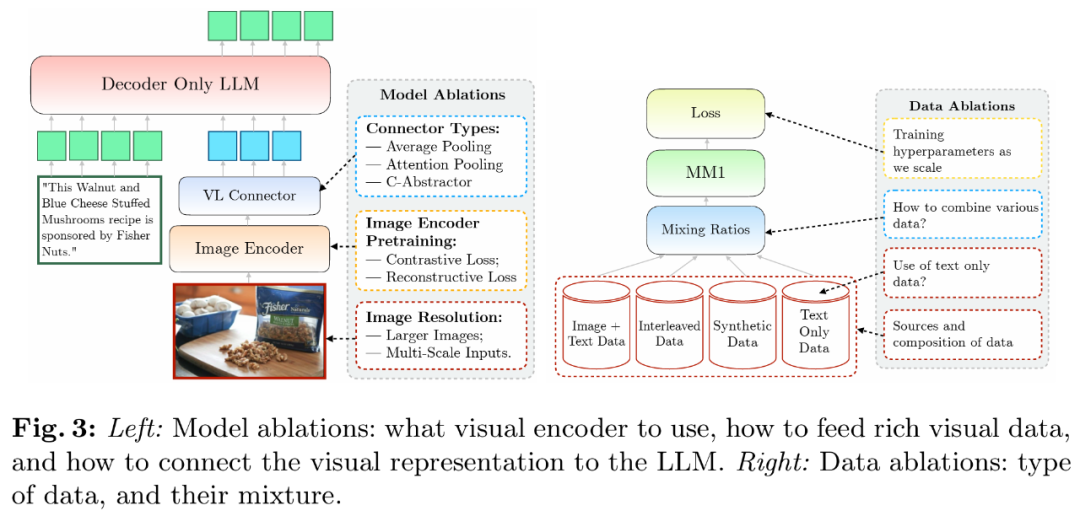
- Pré-formation encodeur d'image. Dans ce processus, les chercheurs ont principalement éliminé l’importance de la résolution d’image et des objectifs de pré-formation de l’encodeur d’image. Il convient de noter que contrairement à d’autres expériences d’ablation, les chercheurs ont utilisé 2,9 milliards de LLM (au lieu de 1,2 milliards) pour garantir une capacité suffisante pour utiliser certains encodeurs d’images plus grands.
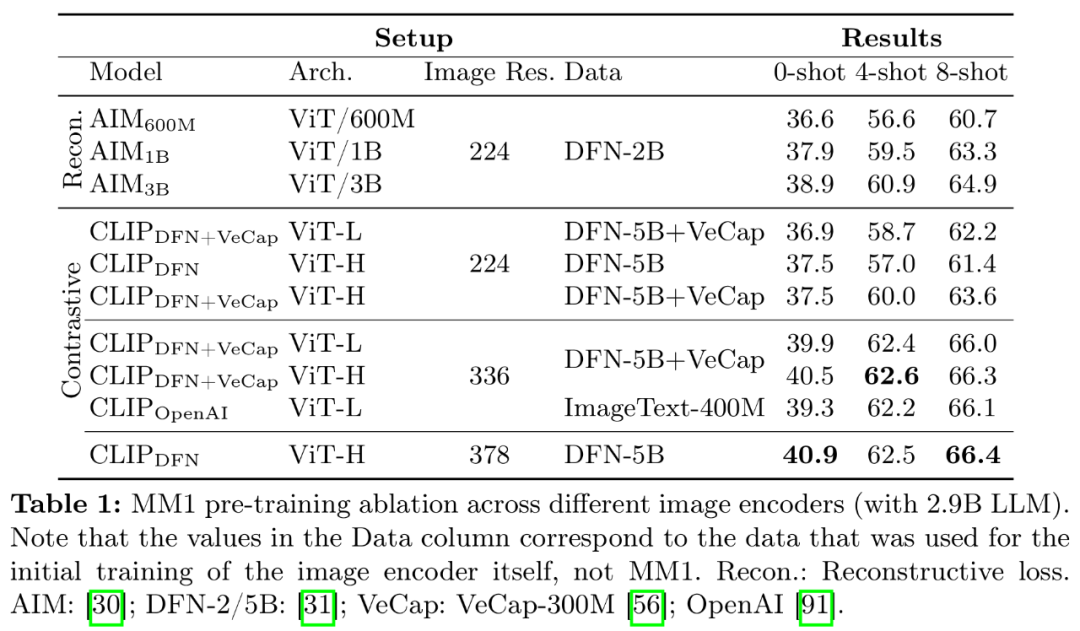
- Expérience de l'encodeur : la résolution de l'image a le plus grand impact, suivie par la taille du modèle et la composition des données d'entraînement. Comme le montre le tableau 1, l'augmentation de la résolution de l'image de 224 à 336 améliore toutes les mesures pour toutes les architectures d'environ 3 %. L'augmentation de la taille du modèle de ViT-L à ViT-H double les paramètres, mais le gain de performances est modeste, généralement inférieur à 1 %. Enfin, l'ajout de VeCap-300M, un ensemble de données de sous-titres synthétiques, améliore les performances de plus de 1 % dans des scénarios comportant quelques prises de vue.
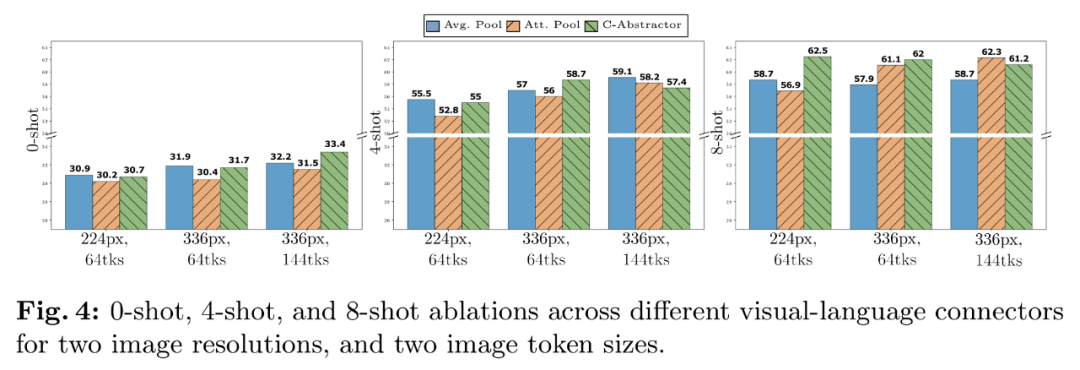
- Connecteurs de langage visuel et résolution d'image. Le but de ce composant est de transformer les représentations visuelles en espace LLM. Étant donné que l'encodeur d'image est ViT, sa sortie est soit une intégration unique, soit un ensemble d'intégrations disposées en grille correspondant aux segments d'image d'entrée. Par conséquent, la disposition spatiale des jetons d’image doit être convertie en disposition séquentielle du LLM. Dans le même temps, la représentation réelle du jeton d’image doit également être mappée à l’espace d’incorporation de mots.
- Expérience du connecteur VL : le nombre de jetons visuels et la résolution de l'image sont les plus importants, tandis que le type de connecteur VL a peu d'impact. Comme le montre la figure 4, à mesure que le nombre de jetons visuels ou/et la résolution de l'image augmente, les taux de reconnaissance de zéro échantillon et de quelques échantillons augmenteront.
Expérience d'ablation de données de pré-entraînement
Généralement, la formation du modèle est divisée en deux étapes : la pré-entraînement et le réglage des instructions. La première étape utilise des données à l'échelle du réseau, tandis que la seconde étape utilise des données organisées spécifiques à la mission. Ce qui suit se concentre sur la phase de pré-formation de cet article et détaille la sélection des données par le chercheur (Figure 3 à droite).
Il existe deux types de données couramment utilisées pour entraîner le MLLM : les données de légende constituées de descriptions de paires d'images et de textes et de documents entrelacés image-texte provenant du Web. Le tableau 2 est la liste complète des ensembles de données :

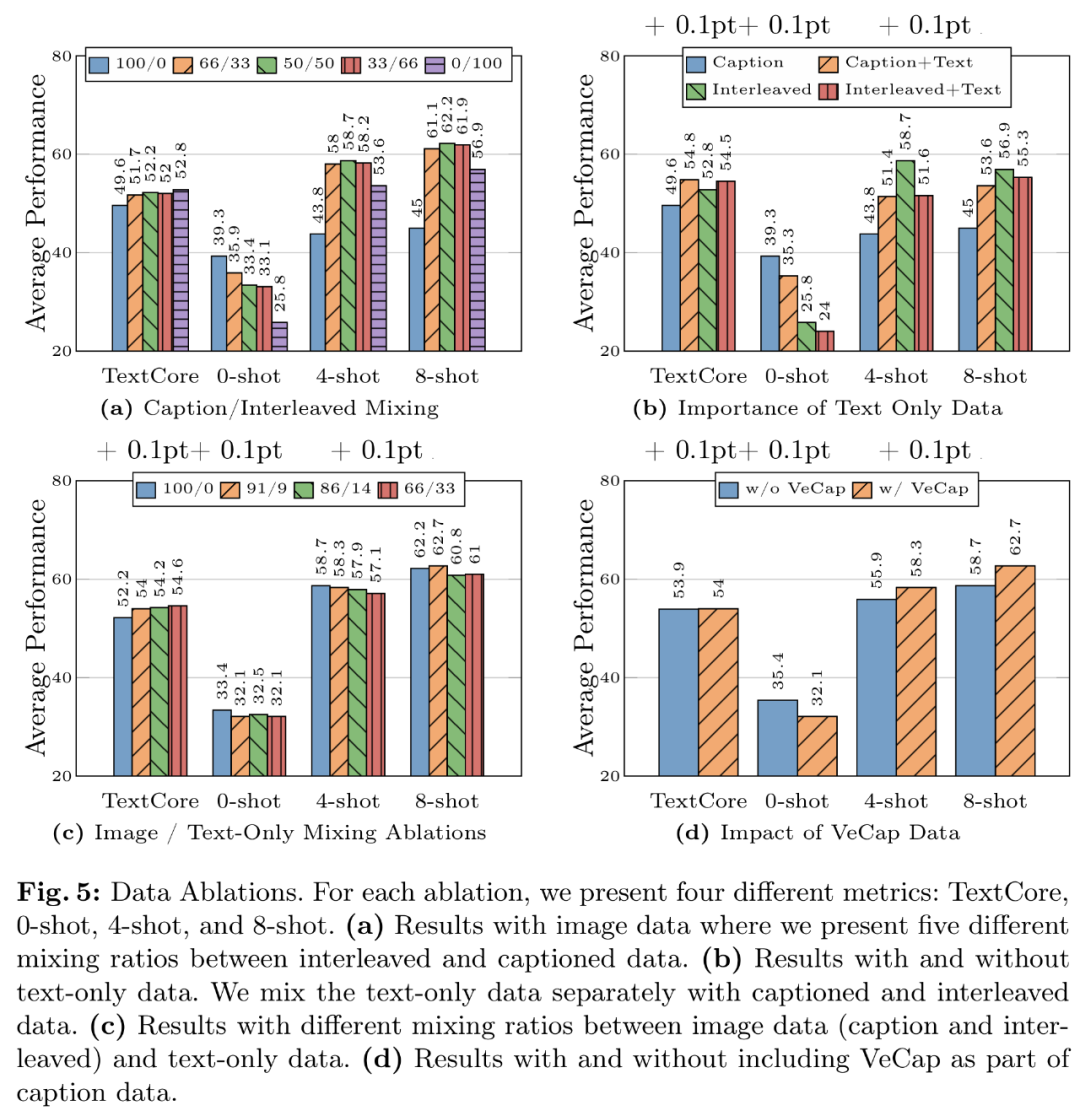
- Expérience des données 1 : les données entrelacées contribuent à améliorer les performances avec quelques échantillons et le texte brut, tandis que les données de sous-titres améliorent les performances sans échantillon. La figure 5a montre les résultats pour différentes combinaisons de données entrelacées et sous-titrées.
- Expérience de données 2 : les données en texte brut contribuent à améliorer les performances sur quelques échantillons et en texte brut. Comme le montre la figure 5b, la combinaison de données en texte brut et de données de sous-titres améliore les performances en quelques prises de vue.
- Leçon de données 3 : Mélangez soigneusement les données d'image et de texte pour obtenir les meilleures performances multimodales et préserver de solides performances de texte. La figure 5c tente plusieurs rapports de mélange entre les données d'image (titre et entrelacé) et de texte brut.
- Expérience de données 4 : Les données synthétiques facilitent l'apprentissage en quelques étapes. Comme le montre la figure 5d, les données synthétiques améliorent considérablement les performances de l'apprentissage en quelques coups, avec des valeurs absolues de 2,4 % et 4 % respectivement.
Modèle final et méthode d'entraînement
Les chercheurs ont collecté les résultats d'ablation précédents et déterminé la recette finale du pré-entraînement multimodal MM1 :
- Encodeur d'image : prise en compte de la résolution de l'image En raison de l'importance du taux, les chercheurs ont utilisé le modèle ViT-H avec une résolution de 378x378px et ont utilisé la cible CLIP pour la pré-formation sur DFN-5B
- Connecteur de langage visuel : puisque le nombre de jetons visuels est le nombre de jetons visuels ; Le plus important, l'étude L'auteur a utilisé un connecteur VL avec 144 jetons. L'architecture réelle semble être moins importante, et le chercheur a choisi C-Abstract
- Données : afin de maintenir les performances de l'échantillon zéro et de l'échantillon réduit, le chercheur a utilisé les données soigneusement combinées suivantes : 45 % d'image ; -document texte entrelacé, 45 % de documents image-texte et 10 % de documents texte brut.
Afin d'améliorer les performances du modèle, les chercheurs ont étendu la taille du LLM aux paramètres 3B, 7B et 30B. Tous les modèles ont été entièrement dégelés et pré-entraînés avec une taille de lot de 512 séquences avec une longueur de séquence de 4 096, un maximum de 16 images par séquence et une résolution de 378 × 378. Tous les modèles ont été formés à l'aide du framework AXLearn.
Ils ont effectué une recherche sur grille sur les taux d'apprentissage à petite échelle, 9M, 85M, 302M et 1,2B, en utilisant la régression linéaire dans l'espace logarithmique pour déduire les changements des modèles plus petits aux plus grands (voir Figure 6), le résultat est la prédiction du taux d'apprentissage maximal optimal η étant donné le nombre de paramètres (non intégrés) N :
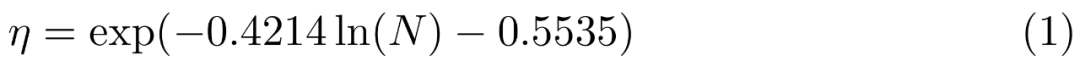
étendu par Mix of Experts (MoE). Lors d'expériences, les chercheurs ont exploré davantage les moyens d'étendre le modèle dense en ajoutant davantage d'experts à la couche FFN du modèle de langage.
Pour convertir un modèle dense en MoE, remplacez simplement le décodeur de langage dense par un décodeur de langage MoE. Pour former MoE, les chercheurs ont utilisé les mêmes hyperparamètres de formation et les mêmes paramètres de formation que Dense Backbone 4, y compris les données de formation et les jetons de formation.
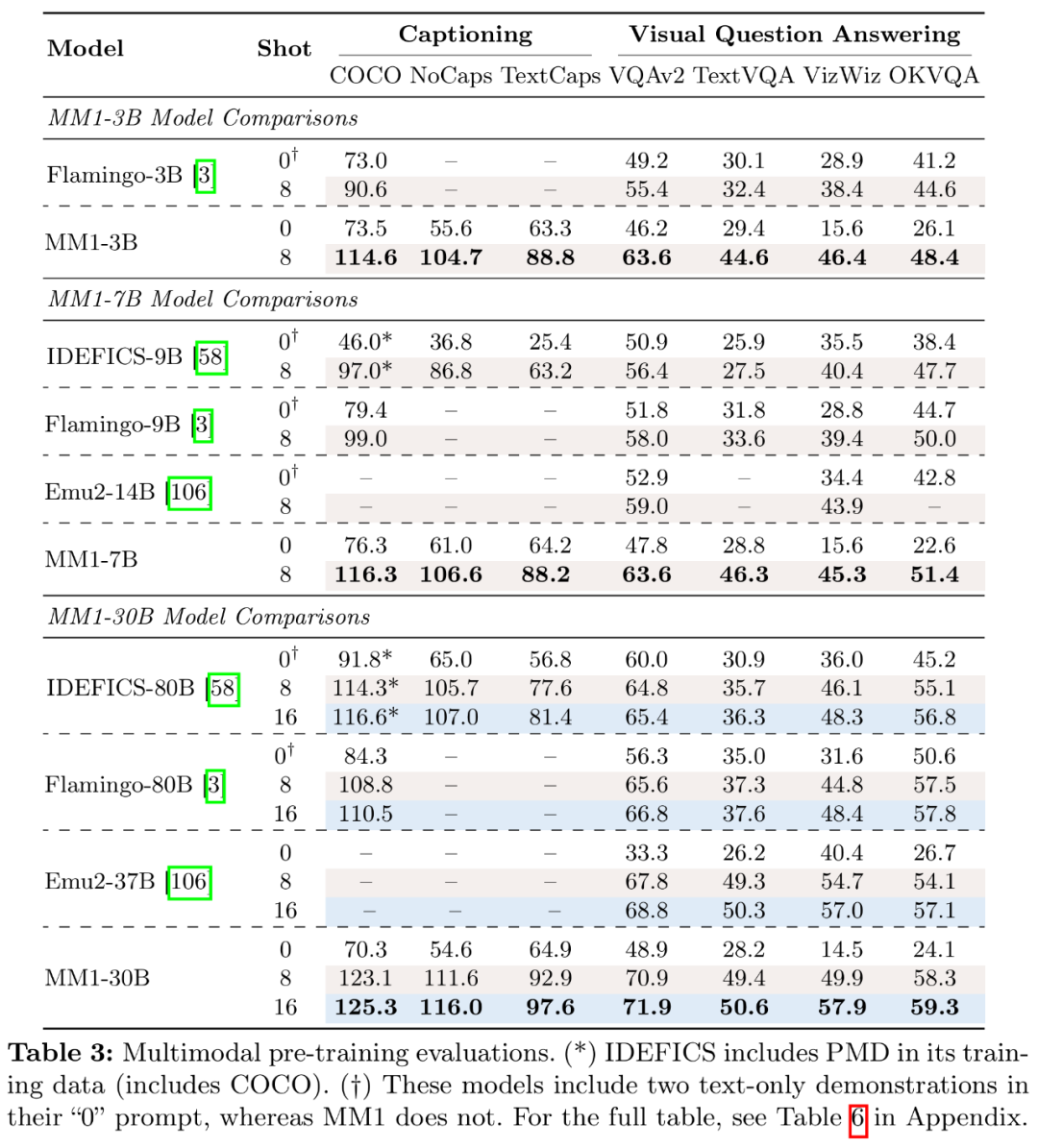
Concernant les résultats de pré-entraînement multimodaux, les chercheurs ont évalué les modèles pré-entraînés sur les tâches de limite supérieure et VQA avec des invites appropriées. Le tableau 3 évalue les résultats avec un échantillon nul et avec quelques échantillons :
Résultats de réglage fin supervisé
Enfin, les chercheurs ont introduit l'expérience de réglage fin supervisé (SFT) formée au-dessus des pré-entraînés. modèle.
Ils ont suivi LLaVA-1.5 et LLaVA-NeXT et ont collecté environ 1 million d'échantillons SFT à partir de différents ensembles de données. Étant donné qu’une résolution d’image intuitivement plus élevée conduit à de meilleures performances, les chercheurs ont également adopté la méthode SFT étendue à la haute résolution.
Les résultats du réglage fin supervisé sont les suivants :
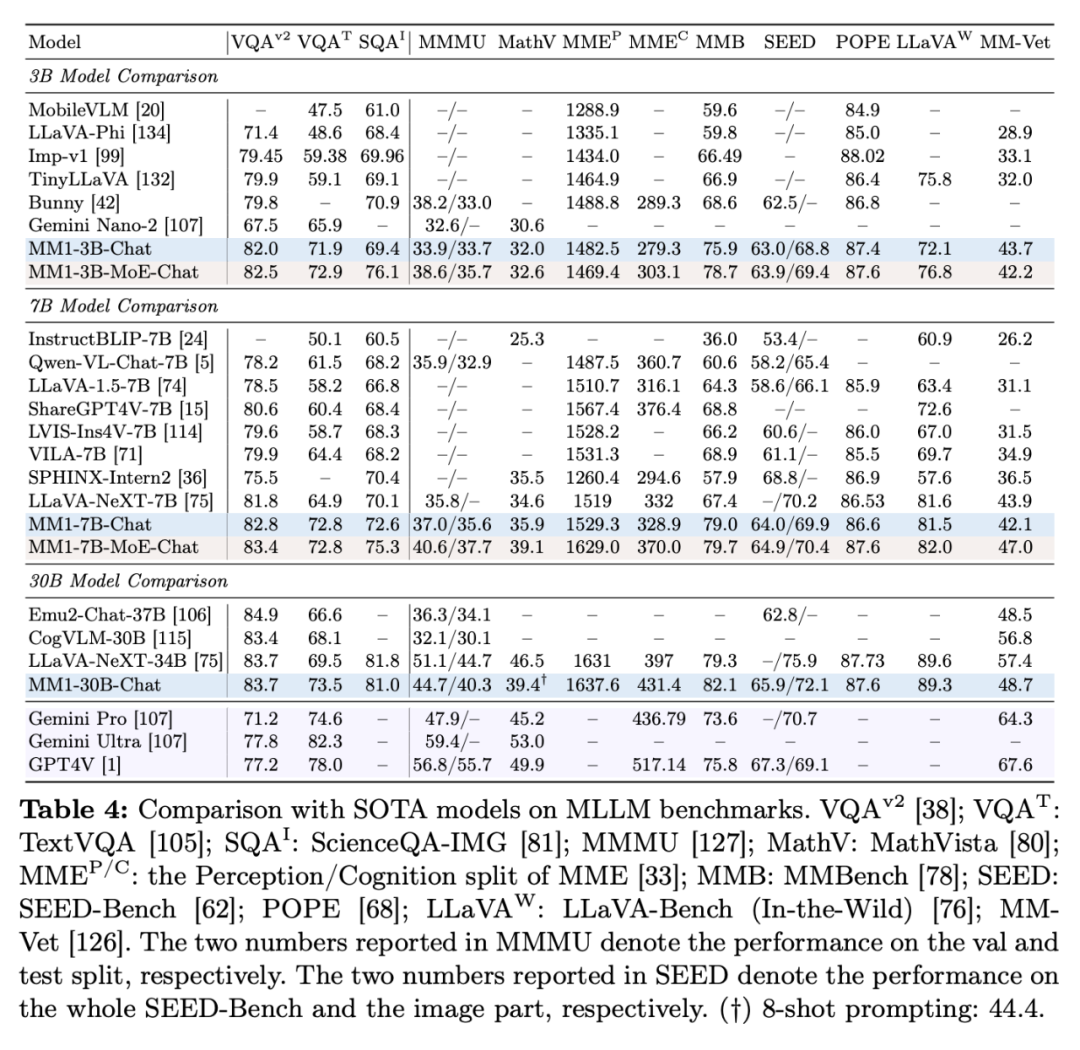
Le tableau 4 montre la comparaison avec SOTA, "-Chat" représente le modèle MM1 après réglage fin supervisé.
Tout d'abord, en moyenne, les MM1-3B-Chat et MM1-7B-Chat surpassent tous les modèles répertoriés de même taille. MM1-3B-Chat et MM1-7B-Chat fonctionnent particulièrement bien sur VQAv2, TextVQA, ScienceQA, MMBench et les benchmarks récents (MMMU et MathVista).
Deuxièmement, les chercheurs ont exploré deux modèles MoE : 3B-MoE (64 experts) et 6B-MoE (32 experts). Le modèle MoE d'Apple a obtenu de meilleures performances que le modèle dense dans presque tous les benchmarks. Cela montre l’énorme potentiel d’expansion du ministère de l’Environnement.
Troisièmement, pour le modèle de taille 30B, MM1-30B-Chat fonctionne mieux que Emu2-Chat37B et CogVLM-30B sur TextVQA, SEED et MMMU. MM1 atteint également des performances globales compétitives par rapport à LLaVA-NeXT.
Cependant, LLaVA-NeXT ne prend pas en charge l'inférence multi-images, ni les indices de quelques prises de vue, car chaque image est représentée par 2880 jetons envoyés à LLM, alors que le nombre total de jetons dans MM1 n'est que de 720. Cela limite certaines applications impliquant plusieurs images.
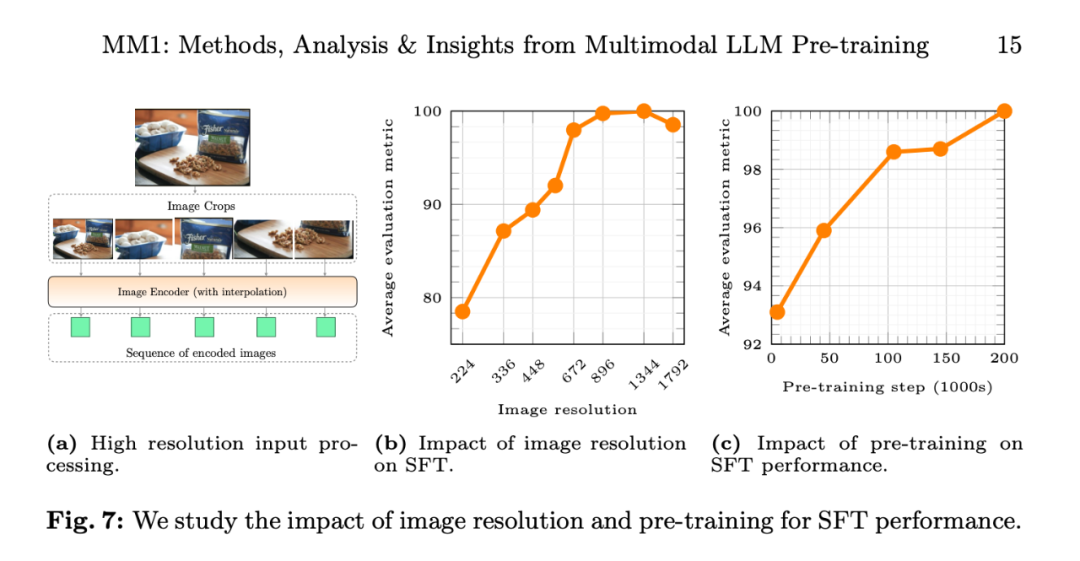
La figure 7b montre l'impact de la résolution de l'image d'entrée sur les performances moyennes de la métrique d'évaluation SFT, et la figure 7c montre que les performances du modèle continuent de s'améliorer à mesure que les données de pré-entraînement augmentent.
L'impact de la résolution de l'image. La figure 7b montre l'impact de la résolution de l'image d'entrée sur les performances moyennes de la métrique d'évaluation SFT.
Impact du pré-entraînement : la figure 7c montre qu'à mesure que les données de pré-entraînement augmentent, les performances du modèle continuent de s'améliorer.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1657
1657
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 Combien vaut le bitcoin
Apr 28, 2025 pm 07:42 PM
Combien vaut le bitcoin
Apr 28, 2025 pm 07:42 PM
Le prix de Bitcoin varie de 20 000 $ à 30 000 $. 1. Le prix de Bitcoin a radicalement fluctué depuis 2009, atteignant près de 20 000 $ en 2017 et près de 60 000 $ en 2021. 2. Les prix sont affectés par des facteurs tels que la demande du marché, l'offre et l'environnement macroéconomique. 3. Obtenez des prix en temps réel via les échanges, les applications mobiles et les sites Web. 4. Le prix du bitcoin est très volatil, tiré par le sentiment du marché et les facteurs externes. 5. Il a une certaine relation avec les marchés financiers traditionnels et est affecté par les marchés boursiers mondiaux, la force du dollar américain, etc. 6. La tendance à long terme est optimiste, mais les risques doivent être évalués avec prudence.
 Laquelle des dix principales plateformes de trading de devises au monde figurent parmi les dix principales plateformes de trading de devises en 2025
Apr 28, 2025 pm 08:12 PM
Laquelle des dix principales plateformes de trading de devises au monde figurent parmi les dix principales plateformes de trading de devises en 2025
Apr 28, 2025 pm 08:12 PM
Les dix premiers échanges de crypto-monnaie au monde en 2025 incluent Binance, Okx, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, Kucoin, Bittrex et Poloniex, qui sont tous connus pour leur volume et leur sécurité commerciaux élevés.
 Laquelle des dix principales plateformes de trading de devises au monde est la dernière version des dix principales plateformes de trading de devises
Apr 28, 2025 pm 08:09 PM
Laquelle des dix principales plateformes de trading de devises au monde est la dernière version des dix principales plateformes de trading de devises
Apr 28, 2025 pm 08:09 PM
Les dix principales plates-formes de trading de crypto-monnaie au monde comprennent Binance, Okx, Gate.io, Coinbase, Kraken, Huobi Global, BitFinex, Bittrex, Kucoin et Poloniex, qui fournissent toutes une variété de méthodes de trading et de puissantes mesures de sécurité.
 Quelles sont les dix principales applications de trading de devises virtuelles? Le dernier classement de change de monnaie numérique
Apr 28, 2025 pm 08:03 PM
Quelles sont les dix principales applications de trading de devises virtuelles? Le dernier classement de change de monnaie numérique
Apr 28, 2025 pm 08:03 PM
Les dix premiers échanges de devises numériques tels que Binance, OKX, Gate.io ont amélioré leurs systèmes, des transactions diversifiées efficaces et des mesures de sécurité strictes.
 Decryption Gate.io Strategy Medgrade: Comment redéfinir la gestion des actifs cryptographiques dans Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Medgrade: Comment redéfinir la gestion des actifs cryptographiques dans Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 redéfinit la gestion des actifs cryptographiques grâce à une architecture innovante et à des percées de performance. 1) Il résout trois principaux points de douleur: les silos d'actifs, la désintégration du revenu et le paradoxe de la sécurité et de la commodité. 2) Grâce à des pôles d'actifs intelligents, à la gestion des risques dynamiques et aux moteurs d'amélioration du rendement, la vitesse de transfert croisée, le taux de rendement moyen et la vitesse de réponse aux incidents de sécurité sont améliorés. 3) Fournir aux utilisateurs la visualisation des actifs, l'automatisation des politiques et l'intégration de la gouvernance, réalisant la reconstruction de la valeur utilisateur. 4) Grâce à la collaboration écologique et à l'innovation de la conformité, l'efficacité globale de la plate-forme a été améliorée. 5) À l'avenir, les pools d'assurance-contrat intelligents, l'intégration du marché des prévisions et l'allocation d'actifs axés sur l'IA seront lancés pour continuer à diriger le développement de l'industrie.
 Quelles sont les principales plateformes de trading de devises? Les 10 meilleurs échanges de devises virtuels virtuels
Apr 28, 2025 pm 08:06 PM
Quelles sont les principales plateformes de trading de devises? Les 10 meilleurs échanges de devises virtuels virtuels
Apr 28, 2025 pm 08:06 PM
Actuellement classé parmi les dix premiers échanges de devises virtuels: 1. Binance, 2. Okx, 3. Gate.io, 4. Coin Library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. Bit Stamp.
 Recommandés plates-formes fiables de trading de devises numériques. Top 10 des échanges de devises numériques dans le monde. 2025
Apr 28, 2025 pm 04:30 PM
Recommandés plates-formes fiables de trading de devises numériques. Top 10 des échanges de devises numériques dans le monde. 2025
Apr 28, 2025 pm 04:30 PM
Plate-forme de trading de devises numériques fiables recommandées: 1. Okx, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. Kucoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, ces plates-formes sont connu
 Comment comprendre la compatibilité ABI en C?
Apr 28, 2025 pm 10:12 PM
Comment comprendre la compatibilité ABI en C?
Apr 28, 2025 pm 10:12 PM
La compatibilité ABI en C se réfère si le code binaire généré par différents compilateurs ou versions peut être compatible sans recompilation. 1. Fonction Calling Conventions, 2. Modification du nom, 3. Disposition de la table de fonction virtuelle, 4. Structure et mise en page de classe sont les principaux aspects impliqués.
