
 Périphériques technologiques
IA
Terminez la tâche « Génération de code » ! Fudan et al. publient le framework StepCoder : apprentissage par renforcement à partir des signaux de rétroaction du compilateur
Périphériques technologiques
IA
Terminez la tâche « Génération de code » ! Fudan et al. publient le framework StepCoder : apprentissage par renforcement à partir des signaux de rétroaction du compilateur
Terminez la tâche « Génération de code » ! Fudan et al. publient le framework StepCoder : apprentissage par renforcement à partir des signaux de rétroaction du compilateur

L'avancement des grands modèles de langage (LLM) a largement stimulé le développement du domaine de la génération de code. Dans des recherches antérieures, l’apprentissage par renforcement (RL) et les signaux de rétroaction du compilateur ont été combinés pour explorer l’espace de sortie des LLM afin d’optimiser la qualité de la génération de code.
Mais il reste encore deux problèmes :
1. L'exploration par apprentissage par renforcement est difficile à adapter directement aux « besoins humains complexes », ce qui nécessite que les LLM génèrent des « codes de séquence longue »
2. les tests unitaires peuvent ne pas couvrir du code complexe, l'optimisation des LLM à l'aide d'extraits de code non exécutés est inefficace.
Pour relever ces défis, les chercheurs ont proposé un nouveau cadre d'apprentissage par renforcement appelé StepCoder, qui a été développé conjointement par des experts de l'Université de Fudan, de l'Université des sciences et technologies de Huazhong et du Royal Institute of Technology. StepCoder contient deux composants clés conçus pour améliorer l'efficacité et la qualité de la génération de code.
1. CCCSrésout les défis d'exploration en divisant les tâches de génération de code à longue séquence en cours de sous-tâches d'achèvement de code ;
2. -optimisation granulaire.
 Lien papier : https://arxiv.org/pdf/2402.01391.pdf
Lien papier : https://arxiv.org/pdf/2402.01391.pdf
Lien du projet : https://github.com/Ablustrund/APPS_Plus
Les chercheurs ont également construit APPS+ ensemble de données utilisé pour la formation par apprentissage par renforcement, vérifié manuellement pour garantir l'exactitude des tests unitaires.
Les résultats expérimentaux montrent que la méthode améliore la capacité d'explorer l'espace de sortie et surpasse les méthodes de pointe sur les benchmarks correspondants.
StepCoder
Dans le processus de génération de code, l'exploration (exploration) d'apprentissage par renforcement ordinaire est difficile à gérer « des environnements avec des récompenses et des retards rares » et « des exigences complexes impliquant de longues séquences ».
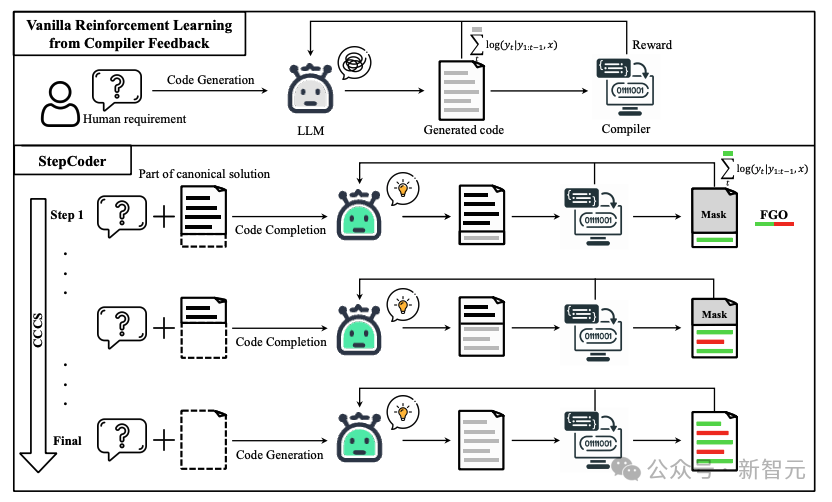 Au stade CCCS (Curriculum of Code Completion Subtasks), les chercheurs décomposent des problèmes d'exploration complexes en une série de sous-tâches. En utilisant une partie de la solution canonique comme invite, LLM peut commencer à explorer à partir de séquences simples.
Au stade CCCS (Curriculum of Code Completion Subtasks), les chercheurs décomposent des problèmes d'exploration complexes en une série de sous-tâches. En utilisant une partie de la solution canonique comme invite, LLM peut commencer à explorer à partir de séquences simples.
Le calcul des récompenses n'est lié qu'à des fragments de code exécutables, il est donc inexact d'utiliser l'intégralité du code (partie rouge sur l'image) pour optimiser LLM (partie grise sur l'image).
Dans l'étape FGO (Fine-Grained Optimization), les chercheurs masquent les jetons non exécutés (partie rouge) dans le test unitaire et utilisent uniquement les jetons exécutés (partie verte) pour calculer la fonction de perte, ce qui peut fournir des informations granulaires détaillées. optimisation.
Connaissances préliminaires
Supposons que
est un ensemble de données de formation pour la génération de code, où x, y, u représentent respectivement les besoins humains (c'est-à-dire la description de la tâche), les solutions standard et les échantillons de tests unitaires. 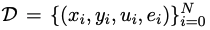
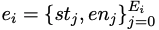 Pour l'exigence humaine x, sa solution standard y peut être exprimée comme
Pour l'exigence humaine x, sa solution standard y peut être exprimée comme
; dans l'étape de génération de code, étant donné l'exigence humaine x, l'état final est l'ensemble de codes qui réussit le test unitaire u. 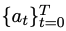
StepCoder intègre deux composants clés : CCCS et FGO, où le but de CCCS est de décomposer la tâche de génération de code en un cours de sous-tâches de complétion de code, ce qui peut atténuer les défis d'exploration dans RL FGO est conçu spécifiquement pour les tâches de génération de code et fournit une optimisation fine en calculant la perte uniquement pour les fragments de code exécutés.
CCCS
Pendant le processus de génération de code, la résolution de besoins humains complexes nécessite souvent un modèle politique pour entreprendre une longue séquence d'actions. Dans le même temps, les retours du compilateur sont retardés et rares, c'est-à-dire que le modèle politique ne reçoit des récompenses qu'une fois que l'intégralité du code a été générée. Dans ce cas, l'exploration est très difficile.
Le cœur de cette méthode est de décomposer une si longue liste de problèmes d'exploration en une série de sous-tâches courtes et faciles à explorer. Les chercheurs simplifient la génération de code en sous-tâches de complétion de code, où les sous-tâches sont représentées par des sous-tâches typiques. exemples dans l’ensemble de données de formation. La solution est construite automatiquement.
Pour les besoins humains x, au début de la phase de formation du CCCS, le point de départ s* de l'exploration est un état proche de l'état final.
Plus précisément, les chercheurs fournissent la demande humaine x et la première moitié de la solution standard 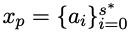 , et entraînent un modèle de politique pour compléter le code selon x'=(x, xp).
, et entraînent un modèle de politique pour compléter le code selon x'=(x, xp).
En supposant que y^ est la séquence combinée de xp et de la trajectoire de sortie τ, c'est-à-dire yˆ=(xp,τ), le modèle de récompense fournit une récompense r basée sur l'exactitude du fragment de code τ avec y^ comme entrée.

Les chercheurs ont utilisé l'algorithme d'optimisation de politique proximale (PPO) pour optimiser le modèle de politique πθ en tirant parti de la récompense r et de la trajectoire τ.
Pendant la phase d'optimisation, le segment de code de solution canonique xp utilisé pour fournir des indices sera masqué afin qu'il n'ait pas d'impact sur le gradient de mise à jour du modèle de politique.
CCCS optimise le modèle politique πθ en maximisant la fonction d'opposition, où π^ref est le modèle de référence en PPO, initialisé par le modèle SFT.
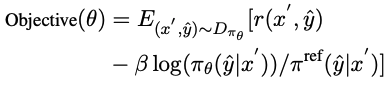
Au fur et à mesure que la formation progresse, le point de départ s* de l'exploration se déplacera progressivement vers le point de départ de la solution standard. Plus précisément, un seuil ρ est fixé pour chaque échantillon de formation, et l'accumulation de segments de code est générée à chaque fois. temps πθ Lorsque le taux de précision est supérieur à ρ, le point de départ est déplacé au début.
Dans les étapes ultérieures de la formation, le processus d'exploration de cette méthode est équivalent à celui de l'apprentissage par renforcement original, c'est-à-dire s*=0, et le modèle politique génère uniquement du code avec les besoins humains en entrée.
Échantillonnez le point de reconnaissance initial s* à la position de départ de l'instruction conditionnelle pour compléter le segment de code non écrit restant.
Plus précisément, plus il y a d'instructions conditionnelles, plus le programme dispose de chemins indépendants et plus la complexité logique est élevée. fréquemment.
Cette méthode d'échantillonnage peut extraire uniformément des structures de code représentatives tout en prenant en compte les structures sémantiques complexes et simples dans l'ensemble de données de formation.
Pour accélérer la phase de formation, les chercheurs ont fixé le nombre de cours pour le i-ème échantillon à 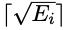 , où Ei est le nombre de ses instructions conditionnelles. La durée du cours de formation du i-ème échantillon est
, où Ei est le nombre de ses instructions conditionnelles. La durée du cours de formation du i-ème échantillon est 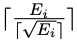 , et non 1.
, et non 1.
Les principaux points du CCCS peuvent être résumés comme suit :
1 Il est facile de démarrer l'exploration à partir d'un état proche de l'objectif (c'est-à-dire l'état final) ; pour commencer l'exploration à partir d'un état éloigné du sexe objectif, mais l'exploration devient plus facile si vous pouvez puiser dans l'état d'avoir appris à atteindre vos objectifs.
FGO
La relation entre les récompenses et les actions dans la génération de code est différente des autres tâches d'apprentissage par renforcement (telles que Atari, un ensemble de récompenses qui ne sont pas pertinentes pour calculer les récompenses dans le). le code généré peut être exclu de l'action.
Plus précisément, pour les tests unitaires, les commentaires du compilateur ne concernent que le fragment de code exécuté. Cependant, dans les objectifs d'optimisation RL ordinaires, toutes les actions sur la trajectoire participeront au calcul du gradient, et le calcul du gradient est imprécis.
Afin d'améliorer la précision de l'optimisation, les chercheurs ont protégé les actions non exécutées (c'est-à-dire les jetons) dans le test unitaire et la perte du modèle de stratégie.

Partie expérimentale
APPS+dataset
L'apprentissage par renforcement nécessite une grande quantité de données d'entraînement de haute qualité. Au cours de l'enquête, les chercheurs ont découvert que parmi les ensembles de données open source actuellement disponibles, seul APPS répond à cette exigence. Une demande.
Mais il existe des instances incorrectes dans APPS, telles que des entrées, des sorties ou des solutions standard manquantes, où la solution standard peut ne pas être compilée ou exécutée, ou il peut y avoir des différences dans les résultats d'exécution.
Pour améliorer l'ensemble de données APPS, les chercheurs ont filtré les instances avec des entrées, des sorties ou des solutions standard manquantes, puis ont standardisé les formats d'entrées et de sorties pour faciliter l'exécution et la comparaison des tests unitaires, pour chaque instance ; Des tests unitaires et des analyses manuelles ont été effectués pour éliminer les cas de code incomplet ou non pertinent, d'erreurs de syntaxe, d'utilisation abusive de l'API ou de dépendances de bibliothèque manquantes.
En cas de différences de résultat, les chercheurs examinent manuellement la description du problème, corrigent le résultat attendu ou éliminent l'instance.
Enfin, l'ensemble de données APPS+ a été construit, contenant 7456 instances. Chaque instance comprend la description du problème de programmation, la solution standard, le nom de la fonction, le test unitaire (c'est-à-dire l'entrée et la sortie) et la partie de début du code de démarrage (c'est-à-dire la solution standard).

Résultats expérimentaux
Pour évaluer les performances d'autres LLM et StepCoder en matière de génération de code, les chercheurs ont mené des expériences sur l'ensemble de données APPS+.
Les résultats montrent que le modèle basé sur RL surpasse les autres modèles de langage, notamment le modèle de base et le modèle SFT.
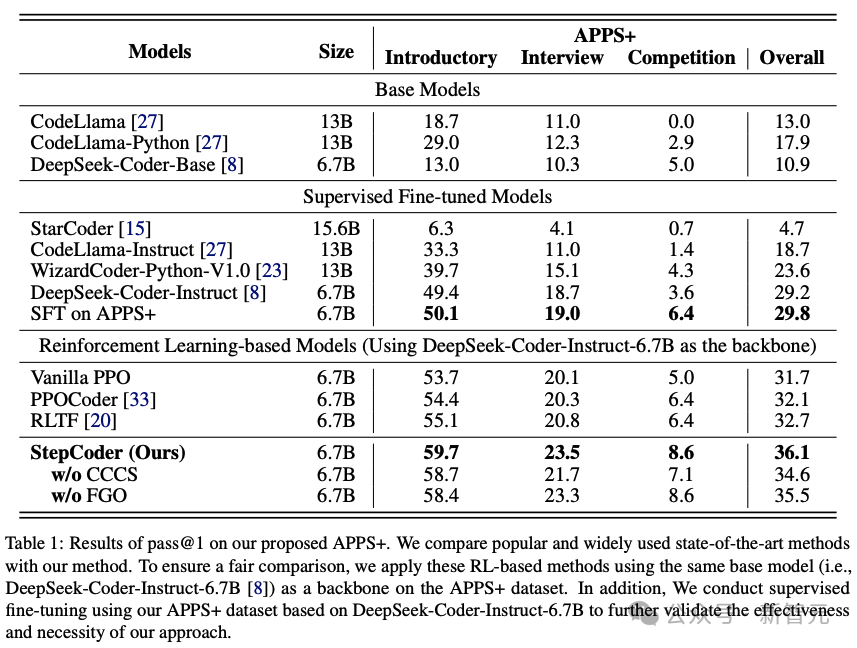
Les chercheurs ont estimé que l'apprentissage par renforcement peut encore améliorer la qualité de la génération de code en explorant plus efficacement l'espace de sortie du modèle, guidé par les commentaires du compilateur.
De plus, StepCoder a surpassé tous les modèles de base, y compris d'autres méthodes basées sur RL, et a obtenu le score le plus élevé.
Plus précisément, cette méthode a obtenu des scores élevés de 59,7%, 23,5% et 8,6% respectivement aux questions des tests de niveau "Introduction", "Entretien" et "Concours".
Par rapport à d'autres méthodes basées sur l'apprentissage par renforcement, cette méthode excelle dans l'exploration de l'espace de sortie en simplifiant les tâches complexes de génération de code en sous-tâches d'achèvement de code, et le processus FGO joue un rôle clé dans l'optimisation précise de l'effet du modèle politique.
On constate également que sur l'ensemble de données APPS+ basé sur la même architecture réseau, StepCoder est plus performant que le LLM supervisé pour le réglage fin par rapport au réseau backbone, ce dernier améliore à peine le taux de réussite du code généré ; Il est également directement démontré que l'utilisation des commentaires du compilateur pour optimiser le modèle peut améliorer la qualité du code généré plus que la prédiction du prochain jeton dans la génération de code.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Cascade déroulante Boîte en V Mode en V
Apr 07, 2025 pm 08:06 PM
Vue et Element-UI Boîtes déroulantes en cascade Points de fosse de liaison V-model: V-model lie un tableau représentant les valeurs sélectionnées à chaque niveau de la boîte de sélection en cascade, pas une chaîne; La valeur initiale de SelectOptions doit être un tableau vide, non nul ou non défini; Le chargement dynamique des données nécessite l'utilisation de compétences de programmation asynchrones pour gérer les mises à jour des données en asynchrone; Pour les énormes ensembles de données, les techniques d'optimisation des performances telles que le défilement virtuel et le chargement paresseux doivent être prises en compte.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
