
 Périphériques technologiques
IA
La première solution de reproduction open source de type Sora au monde est là ! Divulgation complète de tous les détails de la formation et des poids des modèles
Périphériques technologiques
IA
La première solution de reproduction open source de type Sora au monde est là ! Divulgation complète de tous les détails de la formation et des poids des modèles
La première solution de reproduction open source de type Sora au monde est là ! Divulgation complète de tous les détails de la formation et des poids des modèles

Le premier modèle de génération vidéo d'architecture open source de type Sora au monde est là !
L'ensemble du processus de formation, y compris le traitement des données, tous les détails de la formation et les poids des modèles, est ouvert.
Il s'agit de l'Open-Sora 1.0 qui vient de sortir.
L'effet réel qu'il apporte est le suivant : il peut générer un trafic animé dans la scène nocturne de la ville animée.

Vous pouvez également utiliser une perspective de photographie aérienne pour montrer la scène de la côte de la falaise et l'eau de mer clapotant contre les rochers.

Ou le vaste ciel étoilé sous photographie time-lapse.

Depuis sa sortie, révéler et reproduire Sora est devenu l'un des sujets les plus abordés dans la communauté des développeurs en raison de ses effets époustouflants et de la rareté des détails techniques. Par exemple, l'équipe Colossal-AI a lancé un processus de formation et de réplication d'inférence Sora qui peut réduire les coûts de 46 %.
Après seulement deux semaines, l'équipe a de nouveau publié les dernières avancées, reproduisant une solution de type Sora, et a rendu la solution technique et les didacticiels pratiques détaillés gratuits et open source sur GitHub.
Alors la question est, comment reproduire Sora ?
Adresse open source Open-Sora : https://github.com/hpcaitech/Open-Sora
Interprétation complète de la solution de réplication Sora
La solution de réplication Sora comprend quatre aspects :
- Conception d'architecture de modèle
- Formation réplication La solution actuelle
- Prétraitement des données
- Stratégie d'optimisation de la formation efficace
Conception de l'architecture du modèle
Le modèle adopte l'architecture homologue Sora Diffusion Transformer (DiT).
Il est basé sur PixArt-α, un modèle graphique open source de haute qualité utilisant l'architecture DiT. Sur cette base, il introduit une couche d'attention temporelle et l'étend aux données vidéo.
Plus précisément, l'architecture entière comprend un VAE pré-entraîné, un encodeur de texte et un modèle STDiT (Spatial Temporal Diffusion Transformer) qui utilise le mécanisme d'attention spatio-temporelle.
Parmi eux, la structure de chaque couche de STDiT est présentée dans la figure ci-dessous.
Il utilise une méthode sérielle pour superposer un module d'attention temporelle unidimensionnelle sur un module d'attention spatiale bidimensionnelle pour modéliser les relations temporelles. Après le module d'attention temporelle, le module d'attention croisée permet d'aligner la sémantique du texte.
Par rapport au mécanisme d'attention complète, une telle structure réduit considérablement les frais généraux de formation et d'inférence.
Par rapport au modèle Latte, qui utilise également le mécanisme d'attention spatio-temporelle, STDiT peut mieux utiliser les poids de l'image pré-entraînée DiT pour continuer l'entraînement sur les données vidéo.
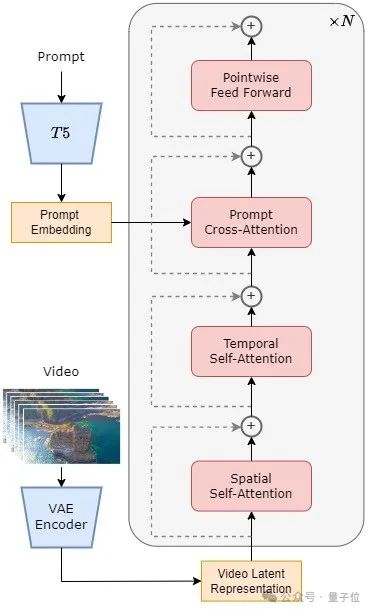
△Schéma structurel STDiT
Le processus de formation et d'inférence de l'ensemble du modèle est le suivant.
Il est entendu que dans la phase de formation, l'encodeur Variational Autoencoder (VAE) pré-entraîné est d'abord utilisé pour compresser les données vidéo, puis le modèle de diffusion STDiT est entraîné avec l'intégration de texte dans l'espace latent compressé.
Dans l'étape d'inférence, un bruit gaussien est échantillonné de manière aléatoire dans l'espace latent du VAE et entré dans STDiT avec l'intégration de l'invite pour obtenir les caractéristiques débruitées. Enfin, il est entré dans le décodeur VAE et décodé pour obtenir la vidéo.

△Processus de formation du modèle
Plan de reproduction de la formation
Dans la partie reproduction de la formation, Open-Sora fait référence à la diffusion vidéo stable (SVD).
Elle est divisée en 3 étapes :
- Pré-formation en image à grande échelle.
- Pré-formation vidéo à grande échelle.
- Réglage précis des données vidéo de haute qualité.
Chaque étape poursuivra l'entraînement en fonction des poids de l'étape précédente.
Par rapport à une formation en une seule étape à partir de zéro, la formation en plusieurs étapes atteint l'objectif de génération vidéo de haute qualité plus efficacement en développant progressivement les données.

△Trois étapes du plan d'entraînement
La première étape est une pré-formation aux images à grande échelle.
L'équipe a utilisé les riches données d'images et la technologie des graphiques vincentiens sur Internet pour d'abord former un modèle de graphique vincentien de haute qualité, et a utilisé ce modèle comme poids d'initialisation pour la prochaine étape de pré-formation vidéo.
Dans le même temps, comme il n'existe actuellement pas de VAE spatio-temporelle de haute qualité, ils utilisent la VAE d'images pré-entraînées à diffusion stable.
Cela garantit non seulement les performances supérieures du modèle initial, mais réduit également considérablement le coût global de la pré-formation vidéo.
La deuxième étape est une pré-formation vidéo à grande échelle.
Cette étape augmente principalement la capacité de généralisation du modèle et saisit efficacement la corrélation des séries chronologiques de la vidéo.
Il doit utiliser une grande quantité de données vidéo pour la formation et garantir la diversité des supports vidéo.
Dans le même temps, le modèle de deuxième étape ajoute un module d'attention temporelle basé sur le modèle de graphique vincentien de première étape pour apprendre les relations temporelles dans les vidéos. Les modules restants restent cohérents avec la première étape et chargent les poids de la première étape comme initialisation, tout en initialisant la sortie du module d'attention temporelle à zéro pour obtenir une convergence plus efficace et plus rapide.
L'équipe Colossal-AI a utilisé les poids open source de PixArt-alpha comme initialisation du modèle STDiT de deuxième étape et le modèle T5 comme encodeur de texte. Ils ont utilisé une petite résolution de 256 x 256 pour la pré-formation, ce qui a encore augmenté la vitesse de convergence et réduit les coûts de formation.

△Effet de génération Open-Sora (mot d'invite : images du monde sous-marin, dans lequel une tortue nage tranquillement parmi les récifs coralliens)
La troisième étape consiste à affiner les données vidéo de haute qualité.
Selon les rapports, cette étape peut améliorer considérablement la qualité de la génération du modèle. La taille des données utilisées est inférieure d’un ordre de grandeur à celle de l’étape précédente, mais la durée, la résolution et la qualité des vidéos sont supérieures.
Un réglage fin de cette manière peut permettre une expansion efficace de la génération vidéo du court au long, de la basse résolution à la haute résolution et de la basse fidélité à la haute fidélité.
Il convient de mentionner que Colossal-AI a également divulgué en détail l'utilisation des ressources de chaque étape.
Dans le processus de reproduction d'Open-Sora, ils ont utilisé 64 H800 pour la formation. Le volume total de formation de la deuxième étape est de 2 808 heures GPU, soit environ 7 000 USD, et le volume de formation de la troisième étape est de 1 920 heures GPU, soit environ 4 500 USD. Après une estimation préliminaire, l'ensemble du plan de formation a réussi à contrôler le processus de reproduction d'Open-Sora à environ 10 000 $ US.
Prétraitement des données
Afin de réduire davantage le seuil et la complexité de la récurrence Sora, l'équipe Colossal-AI fournit également un script de prétraitement des données vidéo pratique dans l'entrepôt de code, afin que tout le monde puisse facilement démarrer la pré-formation sur la récurrence Sora.
Y compris le téléchargement d'ensembles de données vidéo publiques, la segmentation de longues vidéos en courts clips vidéo en fonction de la continuité des prises de vue et l'utilisation du grand modèle de langage open source LLaVA pour générer des mots d'invite précis.
Le code de génération de titre vidéo par lots qu'ils fournissent peut annoter une vidéo avec deux cartes et 3 secondes, et la qualité est proche de GPT-4V.
Le couple vidéo/texte final peut être utilisé directement pour la formation. Avec le code open source qu'ils fournissent sur GitHub, vous pouvez générer facilement et rapidement les paires vidéo/texte nécessaires à la formation sur votre propre ensemble de données, réduisant ainsi considérablement le seuil technique et la préparation préliminaire au démarrage d'un projet de réplication Sora.

Support de formation efficace
De plus, l'équipe Colossal-AI propose également une solution d'accélération de la formation.
Grâce à des stratégies de formation efficaces telles que l'optimisation des opérateurs et le parallélisme hybride, un effet d'accélération de 1,55x a été obtenu lors de la formation au traitement de vidéos de 64 images, d'une résolution de 512 x 512.
Dans le même temps, grâce au système de gestion de mémoire hétérogène de Colossal-AI, une tâche de formation vidéo haute définition 1080p d'une minute peut être effectuée sans entrave sur un seul serveur (8H800).

Et l'équipe a également constaté que l'architecture du modèle STDiT montrait également une excellente efficacité lors de la formation.
Par rapport à DiT utilisant le mécanisme d'attention totale, STDiT atteint une accélération jusqu'à 5 fois supérieure à mesure que le nombre d'images augmente, ce qui est particulièrement critique dans les tâches réelles telles que le traitement de longues séquences vidéo.

Enfin, l'équipe a également publié davantage d'effets de génération Open-Sora.
, durée 00:25
L'équipe et Qubits ont révélé qu'ils mettront à jour et optimiseront les solutions et développements liés à Open-Sora à long terme. À l’avenir, davantage de données de formation vidéo seront utilisées pour générer un contenu vidéo plus long et de meilleure qualité et prendre en charge les fonctionnalités multi-résolutions.
En termes d'applications pratiques, l'équipe a révélé qu'elle favoriserait la mise en œuvre dans les films, les jeux, la publicité et d'autres domaines.
Les développeurs intéressés peuvent visiter le projet GitHub pour en savoir plus~
Open-Sora Adresse open source : https://github.com/hpcaitech/Open-Sora
Lien de référence :
[1]https : //arxiv .org/abs/2212.09748 Modèles de diffusion évolutifs avec transformateurs.
[2]https://arxiv.org/abs/2310.00426 PixArt-α : formation rapide du transformateur de diffusion pour la synthèse photoréaliste de texte en image.
[3]https://arxiv.org/abs/2311.15127 Diffusion vidéo stable : mise à l'échelle des modèles de diffusion vidéo latente vers de grands ensembles de données.
[4]https://arxiv.org/abs/2401.03048 Latte : Transformateur de diffusion latente pour la génération vidéo.
[5]https://huggingface.co/stabilityai/sd-vae-ft-mse-original.
[6]https://github.com/google-research/text-to-text-transfer-transformer.
[7]https://github.com/haotian-liu/LLaVA.
[8]https://hpc-ai.com/blog/open-sora-v1.0.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Échanges qui prennent en charge les transactions transversales: 1. Binance, 2. UniSwap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, ces plateformes prennent en charge les transactions d'actifs multi-chaînes via diverses technologies.
 Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) se démarque sur le marché des crypto-monnaies avec ses mécanismes uniques de vérification biométrique et de protection de la vie privée, attirant l'attention de nombreux investisseurs. WLD a permis de se produire avec remarquablement parmi les Altcoins avec ses technologies innovantes, en particulier en combinaison avec la technologie d'Intelligence artificielle OpenAI. Mais comment les actifs numériques se comporteront-ils au cours des prochaines années? Prédons ensemble le prix futur de WLD. Les prévisions de prix de 2025 WLD devraient atteindre une croissance significative de la WLD en 2025. L'analyse du marché montre que le prix moyen du WLD peut atteindre 1,31 $, avec un maximum de 1,36 $. Cependant, sur un marché baissier, le prix peut tomber à environ 0,55 $. Cette attente de croissance est principalement due à WorldCoin2.
 'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' est une journée difficile pour l'industrie de la crypto-monnaie
Apr 21, 2025 pm 02:48 PM
Le plongeon sur le marché des crypto-monnaies a provoqué la panique parmi les investisseurs, et Dogecoin (Doge) est devenu l'une des zones les plus difficiles. Son prix a fortement chuté et le verrouillage de la valeur totale de la finance décentralisée (DEFI) (TVL) a également connu une baisse significative. La vague de vente de "Black Monday" a balayé le marché des crypto-monnaies, et Dogecoin a été le premier à être touché. Son Defitvl a chuté aux niveaux de 2023 et le prix de la devise a chuté de 23,78% au cours du dernier mois. Le Defitvl de Dogecoin est tombé à un minimum de 2,72 millions de dollars, principalement en raison d'une baisse de 26,37% de l'indice de valeur SOSO. D'autres plates-formes de Defi majeures, telles que le Dao et Thorchain ennuyeux, TVL ont également chuté de 24,04% et 20, respectivement.
 Pourquoi la hausse ou la baisse des prix de monnaie virtuelle? Pourquoi la hausse ou la baisse des prix de monnaie virtuelle?
Apr 21, 2025 am 08:57 AM
Pourquoi la hausse ou la baisse des prix de monnaie virtuelle? Pourquoi la hausse ou la baisse des prix de monnaie virtuelle?
Apr 21, 2025 am 08:57 AM
Les facteurs de la hausse des prix des devises virtuels comprennent: 1. Une augmentation de la demande du marché, 2. Daisser l'offre, 3. Stimulé de nouvelles positives, 4. Sentiment du marché optimiste, 5. Environnement macroéconomique; Les facteurs de déclin comprennent: 1. Daissement de la demande du marché, 2. AUGMENT DE L'OFFICATION, 3. Strike of Negative News, 4. Pespimiste Market Sentiment, 5. Environnement macroéconomique.
 Comment gagner des récompenses de plateaux aériens du noyau sur la stratégie de processus complète de la binance
Apr 21, 2025 pm 01:03 PM
Comment gagner des récompenses de plateaux aériens du noyau sur la stratégie de processus complète de la binance
Apr 21, 2025 pm 01:03 PM
Dans le monde animé des crypto-monnaies, de nouvelles opportunités émergent toujours. À l'heure actuelle, l'activité aérienne de Kerneldao (noyau) attire beaucoup l'attention et attire l'attention de nombreux investisseurs. Alors, quelle est l'origine de ce projet? Quels avantages le support BNB peut-il en tirer? Ne vous inquiétez pas, ce qui suit le révélera un par un pour vous.
 Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Les plates-formes qui ont des performances exceptionnelles dans le commerce, la sécurité et l'expérience utilisateur en effet de levier en 2025 sont: 1. OKX, adaptés aux traders à haute fréquence, fournissant jusqu'à 100 fois l'effet de levier; 2. Binance, adaptée aux commerçants multi-monnaies du monde entier, offrant un effet de levier 125 fois élevé; 3. Gate.io, adapté aux joueurs de dérivés professionnels, fournissant 100 fois l'effet de levier; 4. Bitget, adapté aux novices et aux commerçants sociaux, fournissant jusqu'à 100 fois l'effet de levier; 5. Kraken, adapté aux investisseurs stables, fournissant 5 fois l'effet de levier; 6. BUTBIT, adapté aux explorateurs Altcoin, fournissant 20 fois l'effet de levier; 7. Kucoin, adapté aux commerçants à faible coût, fournissant 10 fois l'effet de levier; 8. Bitfinex, adapté au jeu senior
 WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
Binance est le suzerain de l'écosystème mondial de trading d'actifs numériques, et ses caractéristiques comprennent: 1. Le volume de négociation quotidien moyen dépasse 150 milliards de dollars, prend en charge 500 paires de négociation, couvrant 98% des monnaies grand public; 2. La matrice d'innovation couvre le marché des dérivés, la mise en page Web3 et le système éducatif; 3. Les avantages techniques sont des moteurs de correspondance d'une milliseconde, avec des volumes de traitement de pointe de 1,4 million de transactions par seconde; 4. Conformité Progress détient des licences de 15 pays et établit des entités conformes en Europe et aux États-Unis.
 Aavenomics est une recommandation pour modifier le jeton Aave Protocol et introduire le rachat de jetons, qui a atteint le nombre de personnes quorum.
Apr 21, 2025 pm 06:24 PM
Aavenomics est une recommandation pour modifier le jeton Aave Protocol et introduire le rachat de jetons, qui a atteint le nombre de personnes quorum.
Apr 21, 2025 pm 06:24 PM
Aavenomics est une proposition de modification du jeton de protocole Aave et d'introduire des dépens de jetons, qui a mis en œuvre un quorum pour Aavedao. Marc Zeller, fondateur de l'Aave Project Chain (ACI), l'a annoncé sur X, notant qu'il marque une nouvelle ère pour l'accord. Marc Zeller, fondateur de l'Aave Chain Initiative (ACI), a annoncé sur X que la proposition d'Aavenomics comprend la modification du jeton Aave Protocol et l'introduction de dépens de jetons, a obtenu un quorum pour Aavedao. Selon Zeller, cela marque une nouvelle ère pour l'accord. Les membres d'Aavedao ont voté massivement pour soutenir la proposition, qui était de 100 par semaine mercredi
