
 Périphériques technologiques
IA
Pour protéger la confidentialité des clients, exécutez localement des modèles d'IA open source à l'aide de Ruby
Périphériques technologiques
IA
Pour protéger la confidentialité des clients, exécutez localement des modèles d'IA open source à l'aide de Ruby
Pour protéger la confidentialité des clients, exécutez localement des modèles d'IA open source à l'aide de Ruby

Traducteur | Chen Jun
Chonglou
Récemment, nous avons mis en œuvre un projet d'intelligence artificielle (IA) personnalisé. Étant donné que la partie A détient des informations client très sensibles, pour des raisons de sécurité, nous ne pouvons pas les transmettre à OpenAI ou à d'autres modèles propriétaires. Par conséquent, nous avons téléchargé et exécuté un modèle d'IA open source dans une machine virtuelle AWS, en le gardant entièrement sous notre contrôle. Dans le même temps, les applications Rails peuvent effectuer des appels API à l'IA dans un environnement sûr. Bien entendu, si des problèmes de sécurité ne doivent pas être pris en compte, nous préférerions coopérer directement avec OpenAI.

Ci-dessous, je vais partager avec vous comment télécharger le modèle d'IA open source localement, le laisser s'exécuter et comment exécuter le script Ruby dessus.
Pourquoi personnaliser ?
La motivation de ce projet est simple : la sécurité des données. Lors du traitement d’informations client sensibles, l’approche la plus fiable consiste généralement à le faire au sein de l’entreprise. Par conséquent, nous avons besoin de modèles d’IA personnalisés pour jouer un rôle en fournissant un niveau plus élevé de contrôle de sécurité et de protection de la vie privée.
Modèle Open source
Au cours des 6 derniers mois, de nouveaux produits sont apparus sur le marché tels que : Mistral, Mixtral et Lamaetc. Un grand nombre de modèles d'IA open source. Bien qu'ils ne soient pas aussi puissants que GPT-4, les performances de beaucoup d'entre eux ont dépassé GPT-3.5, et ils deviendront de plus en plus puissants au fil du temps. Bien entendu, le modèle que vous choisissez dépend entièrement de vos capacités de traitement et de ce que vous devez réaliser.
Étant donné que nous exécuterons le modèle d'IA localement, nous avons sélectionné le Mistral qui fait environ 4 Go. Il surpasse GPT-3.5 sur la plupart des métriques. Bien que Mixtral soit plus performant que Mistral, il s'agit d'un modèle volumineux qui nécessite au moins 48 Go de mémoire pour fonctionner.
Paramètres
Quand on parle de grands modèles de langage (LLM), nous avons tendance à penser à mentionner la taille de leurs paramètres. Ici, le modèle Mistral que nous exécuterons localement est un modèle de 7 milliards de paramètres (bien sûr, Mixtral a 700 milliards de paramètres, et GPT-3.5 Il y a environ 1750 milliards de paramètres).
En règle générale, les grands modèles de langage utilisent des techniques basées sur les réseaux neuronaux. Les réseaux de neurones sont constitués de neurones et chaque neurone est connecté à tous les autres neurones de la couche suivante.
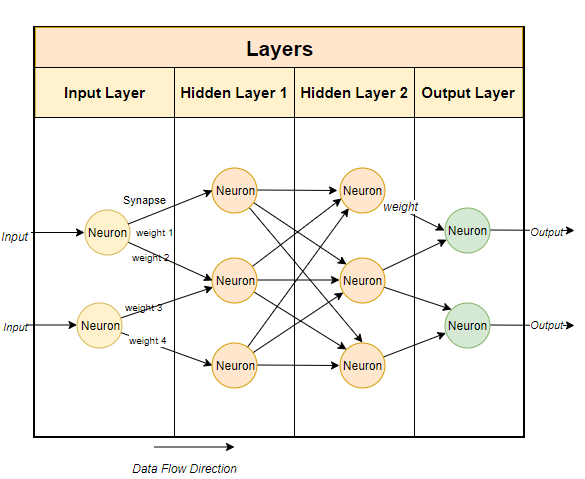
Le but du réseau neuronal est « d'apprendre » un algorithme avancé, un algorithme de correspondance de modèles. En étant formé sur de grandes quantités de texte, il apprendra progressivement la capacité de prédire les modèles de texte et de répondre de manière significative aux signaux que nous lui donnons. En termes simples, les paramètres sont le nombre de poids et de biais dans le modèle. Cela nous donne une idée du nombre de neurones présents dans un réseau neuronal. Par exemple, pour un modèle de
7 milliards de paramètres, il y a environ 100 couches, chacune contenant des milliers de neurones. Exécutez le modèle localement
Pour exécuter le modèle open source localement, vous devez d'abord télécharger l'application appropriée. Bien qu'il existe de nombreuses options sur le marché, celle que je trouve la plus simple et la plus simple à exécuter sur Intel
Macest Ollama. Bien que
Ollama ne fonctionne actuellement que sur Mac et Linux, il fonctionnera également sur Windows à l'avenir. Bien sûr, vous pouvez utiliser WSL (sous-système Windows pour Linux) pour exécuter Linux shell sur Windows. Ollama vous permet non seulement de télécharger et d'exécuter divers modèles open source, mais ouvre également le modèle sur un port local, vous permettant de passer des appels API via le code Ruby. Cela permet aux développeurs Ruby d'écrire des applications Ruby qui peuvent être intégrées aux modèles locaux. puisque Olllama est principalement basé sur la ligne de commande, il est très simple d'installer Olllama sur les systèmes Mac et Linux. Il vous suffit de télécharger Ollama via le lien https://www.php.cn/link/04c7f37f2420f0532d7f0e062ff2d5b5, de consacrer environ 5 minutes pour installer le progiciel, puis d'exécuter le modèle. Après avoir configuré et exécuté Ollama, vous verrez l'icône Ollama dans la barre des tâches de votre navigateur. Cela signifie qu'il s'exécute en arrière-plan et peut exécuter votre modèle. Pour télécharger le modèle, vous pouvez ouvrir un terminal et exécuter la commande suivante : Puisque Mistral a une taille d'environ 4 Go, cela vous prendra un certain temps pour terminer le téléchargement. Une fois le téléchargement terminé, il ouvrira automatiquement l'invite Ollama pour que vous puissiez interagir et communiquer avec Mistral. La prochaine fois que vous exécuterez mistral via Ollama, vous pourrez exécuter directement le modèle correspondant. Similaire à la façon dont nous créons un GPT personnalisé dans OpenAI, via Ollama, vous pouvez personnaliser le modèle de base. Ici, nous pouvons simplement créer un modèle personnalisé. Pour des cas plus détaillés, veuillez vous référer à la documentation en ligne d'Ollama. Tout d'abord, vous pouvez créer un Modelfile (fichier modèle) et y ajouter le texte suivant : Le message système qui apparaît ci-dessus est la base de la réponse spécifique de l'IA. modèle. Ensuite, vous pouvez exécuter la commande suivante sur le terminal pour créer un nouveau modèle : Dans notre cas de projet, j'ai nommé le modèle Ruby . En même temps, vous pouvez utiliser la commande suivante pour lister et afficher vos modèles existants : Bien qu'Ollama ne dispose pas encore de gem dédiée, les développeurs Ruby peuvent utiliser des méthodes de requête HTTP de base pour interagir avec les modèles. Ollama fonctionnant en arrière-plan peut ouvrir le modèle via le port 11434, vous pouvez donc y accéder via "https://www.php.cn/link/dcd3f83c96576c0fd437286a1ff6f1f0". De plus, la documentation de l'API OllamaAPI fournit également différents points de terminaison pour les commandes de base telles que les conversations de chat et la création d'intégrations. Dans ce cas de projet, nous souhaitons utiliser le point de terminaison /api/chat pour envoyer des invites au modèle d'IA. L'image ci-dessous montre un Rubycode de base pour interagir avec le modèle : Fonctionnalité de ce qui précède Rubyl'extrait de code comprend : Comme mentionné ci-dessus, la véritable valeur de l'exécution de modèles d'IA locaux est d'aider les entreprises qui détiennent des données sensibles, traitent des données non structurées telles que des e-mails ou des documents et extraient des informations structurées précieuses. . Dans le cas du projet auquel nous avons participé, nous avons effectué une formation modèle sur toutes les informations client dans le système de gestion de la relation client (CRM). À partir de là, les utilisateurs peuvent poser toutes les questions qu’ils ont sur leurs clients sans avoir à parcourir des centaines d’enregistrements. Introduction du traducteur Julian Chen, rédacteur de communauté 51CTO, a plus de dix ans d'expérience dans la mise en œuvre de projets informatiques, est doué pour contrôler les ressources et les risques internes et externes et se concentre sur la communication Connaissance et expérience en matière de sécurité des réseaux et de l’information. Titre original : Comment exécuter des modèles d'IA open source localement avec Ruby, auteur : Kane Hooper
Obtenez ollama
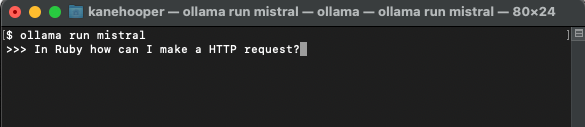
Installation de votre premier modèle
ollama run mistral
Modèle personnalisé
FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked questions about the Ruby Programminglanguage. You will provide an explanation along with code examples.”””
ollama create <model-name> -f './Modelfile</model-name>
ollama create ruby -f './Modelfile'
ollama list
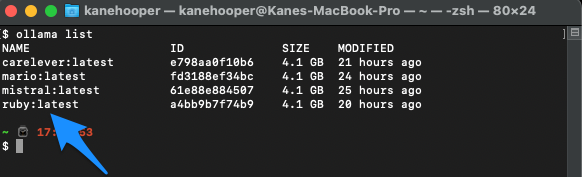
Ollama run ruby
Intégré à Ruby
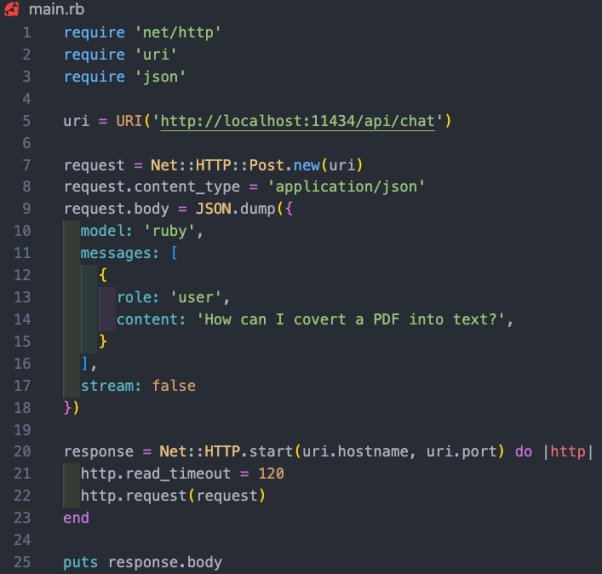
Résumé du cas
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
 Iyo One : en partie casque, en partie ordinateur audio
Aug 08, 2024 am 01:03 AM
Iyo One : en partie casque, en partie ordinateur audio
Aug 08, 2024 am 01:03 AM
A tout moment, la concentration est une vertu. Auteur | Editeur Tang Yitao | Jing Yu La résurgence de l'intelligence artificielle a donné naissance à une nouvelle vague d'innovation matérielle. L’AIPin le plus populaire a rencontré des critiques négatives sans précédent. Marques Brownlee (MKBHD) l'a qualifié de pire produit qu'il ait jamais examiné ; David Pierce, rédacteur en chef de The Verge, a déclaré qu'il ne recommanderait à personne d'acheter cet appareil. Son concurrent, le RabbitR1, n'est guère mieux. Le plus grand doute à propos de cet appareil d'IA est qu'il ne s'agit évidemment que d'une application, mais Rabbit a construit un matériel de 200 $. De nombreuses personnes voient l’innovation matérielle en matière d’IA comme une opportunité de renverser l’ère des smartphones et de s’y consacrer.
 Premier système d'IA de découverte scientifique entièrement automatisé, la startup auteur de Transformer, Sakana AI, lance AI Scientist
Aug 13, 2024 pm 04:43 PM
Premier système d'IA de découverte scientifique entièrement automatisé, la startup auteur de Transformer, Sakana AI, lance AI Scientist
Aug 13, 2024 pm 04:43 PM
Editeur | ScienceAI Il y a un an, Llion Jones, le dernier auteur de l'article Transformer de Google, a quitté son entreprise pour créer une entreprise et a cofondé la société d'intelligence artificielle SakanaAI avec l'ancien chercheur de Google, David Ha. SakanaAI prétend créer un nouveau modèle de base basé sur une intelligence inspirée de la nature ! Désormais, SakanaAI a remis sa feuille de réponses. SakanaAI annonce le lancement d'AIScientist, le premier système d'IA au monde pour la recherche scientifique automatisée et la découverte ouverte ! De la conception, l'écriture de code, la réalisation d'expériences et la synthèse des résultats, à la rédaction d'articles entiers et à la réalisation d'examens par les pairs, AIScientist ouvre la voie à la recherche et à l'accélération scientifiques basées sur l'IA.
 Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Il est impossible de terminer la conversion XML à PDF directement sur votre téléphone avec une seule application. Il est nécessaire d'utiliser les services cloud, qui peuvent être réalisés via deux étapes: 1. Convertir XML en PDF dans le cloud, 2. Accédez ou téléchargez le fichier PDF converti sur le téléphone mobile.
