

Dans le processus de développement rapide dans le domaine de la génération visuelle, le modèle de diffusion a complètement changé la tendance de développement de ce domaine, et son introduction de la fonction de génération guidée par texte marque un profond changement dans les capacités.
Cependant, s'appuyer uniquement sur le texte pour réguler ces modèles ne peut pas répondre pleinement aux besoins divers et complexes des différentes applications et scénarios.
Compte tenu de cette lacune, de nombreuses études visent à contrôler des modèles texte-image (T2I) pré-entraînés pour prendre en charge de nouvelles conditions.
Des chercheurs de l'Université des postes et télécommunications de Pékin ont mené un examen approfondi de la génération contrôlable de modèles de diffusion T2I, décrivant les fondements théoriques et les progrès pratiques dans ce domaine. Cette revue couvre les derniers résultats de recherche et constitue une référence importante pour le développement et l’application de ce domaine.

Papier : https://arxiv.org/abs/2403.04279 Code : https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
Notre examen commence par un bref Commence par présenter les bases des modèles probabilistes de diffusion débruitée (DDPM) et du modèle de diffusion T2I largement utilisé.
Nous avons exploré plus en détail le mécanisme de contrôle du modèle de diffusion et déterminé l'efficacité de l'introduction de nouvelles conditions dans le processus de débruitage grâce à une analyse théorique.
De plus, nous avons résumé en détail la recherche dans ce domaine et l'avons divisée en différentes catégories du point de vue des conditions, telles que la génération de conditions spécifiques, la génération multi-conditions et la génération de contrôlabilité générale.
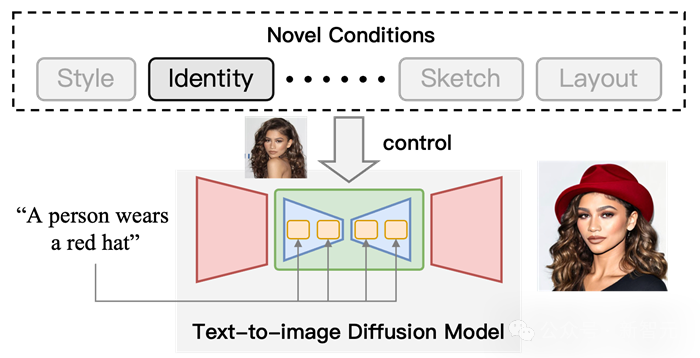
Figure 1 Diagramme schématique de la génération contrôlable à l'aide du modèle de diffusion T2I. Sur la base des conditions de texte, ajoutez des conditions « d'identité » pour contrôler les résultats de sortie.
La tâche de génération conditionnelle à l'aide de modèles de diffusion de texte représente un domaine complexe et à multiples facettes. D'un point de vue conditionnel, nous divisons cette tâche en trois sous-tâches (voir Figure 2).
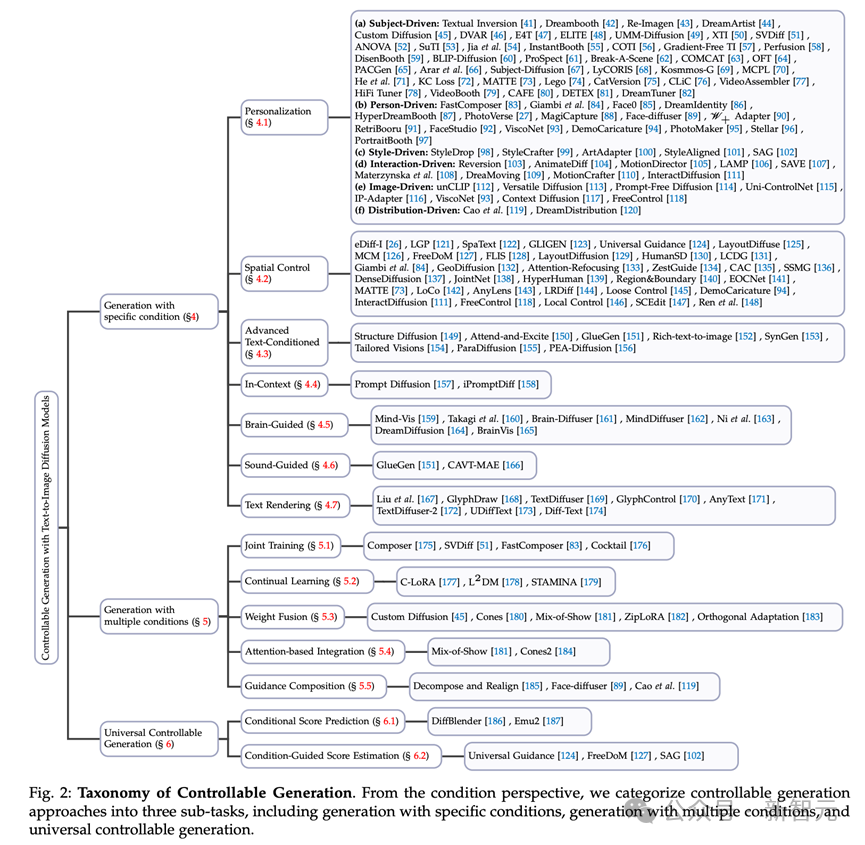
Figure 2 Classification de la génération contrôlable. Du point de vue des conditions, nous divisons la méthode de génération contrôlable en trois sous-tâches, dont la génération avec des conditions spécifiques, la génération avec plusieurs conditions et la génération générale contrôlable.
La plupart des recherches sont consacrées à la manière de générer des images dans des conditions spécifiques, telles que la génération guidée par l'image et la génération d'esquisse en image.
Pour révéler la théorie et les caractéristiques de ces méthodes, nous les classons davantage en fonction de leurs types de conditions.
1. Générer à l'aide de conditions spécifiques : fait référence à des méthodes qui introduisent des types spécifiques de conditions, y compris des conditions personnalisées (personnalisation, par exemple DreamBooth, inversion textuelle) et des conditions plus directes, telles que la série ControlNet, physiologique. signal-to-Image
2. Génération multi-conditions : En utilisant plusieurs conditions pour générer, nous subdivisons cette tâche d'un point de vue technique.
3. Génération contrôlable unifiée : Cette tâche est conçue pour pouvoir générer en utilisant n'importe quelles conditions (même n'importe quel nombre).
Comment introduire de nouvelles conditions dans le modèle de diffusion T2I
Veuillez vous référer à l'article original pour plus de détails. Les mécanismes de ces méthodes sont brièvement présentés ci-dessous.
Prédiction du score conditionnel
Dans le modèle de diffusion T2I, l'utilisation d'un modèle entraînable (tel qu'UNet) pour prédire le score de probabilité (c'est-à-dire le bruit) dans le processus de débruitage est une méthode basique et efficace .
Dans la méthode de prédiction des scores basée sur les conditions, de nouvelles conditions sont utilisées comme entrées dans le modèle de prédiction pour prédire directement les nouveaux scores.
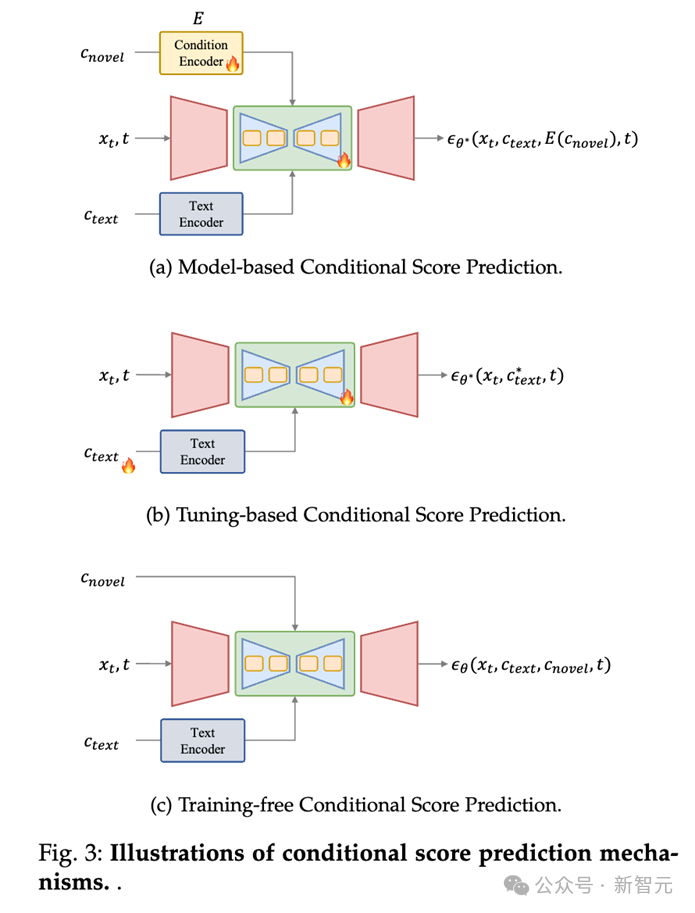
Il peut être divisé en trois méthodes pour introduire de nouvelles conditions :
1. Prédiction du score de condition basée sur un modèle : Ce type de méthode introduira un modèle pour coder de nouvelles conditions et utilisera les fonctionnalités de codage comme entrée d'UNet (telles que l'action sur la couche d'attention croisée) pour prédire les résultats du score de nouveauté sous certaines conditions ;
2. Prédiction du score conditionnel basée sur un réglage fin : Ce type de méthode n'utilise pas de condition explicite, mais affine les paramètres du réseau d'intégration et de débruitage de texte. pour lui faire apprendre des informations sur de nouvelles conditions, en utilisant ainsi des poids affinés pour obtenir une génération contrôlable. Par exemple, DreamBooth et Textual Inversion sont de telles pratiques.
3. Prédiction de score conditionnelle sans entraînement : Ce type de méthode ne nécessite pas d'entraînement du modèle, et peut appliquer directement des conditions au lien de prédiction du modèle, comme dans le Layout-to-Image ( génération d'images de mise en page), vous pouvez modifier directement la carte d'attention de la couche d'attention croisée pour définir la disposition de l'objet.
La méthode d'estimation du score de l'évaluation guidée conditionnelle consiste à ajouter un guidage conditionnel dans le processus de débruitage en rétropropagant le gradient à travers le modèle de prédiction conditionnelle (tel que le prédicteur de condition ci-dessus ).
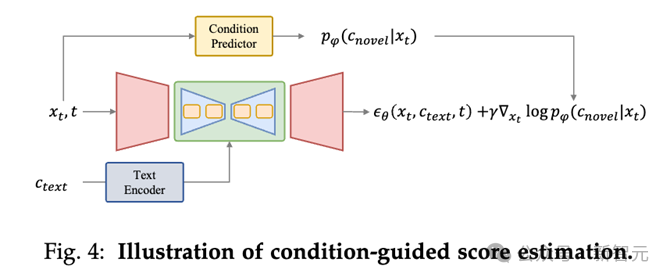
Utiliser des conditions spécifiques pour générer

1. Personnalisation : Les tâches personnalisées sont conçues pour capturer et utiliser des concepts comme conditions de génération pour une génération contrôlable. décrits via du texte et doivent être extraits d’exemples d’images. Tels que DreamBooth, Texutal Inversion et LoRA.
2. Contrôle spatial : Étant donné que le texte est difficile à représenter des informations structurelles, c'est-à-dire l'emplacement et les étiquettes denses, l'utilisation de signaux spatiaux pour contrôler les méthodes de diffusion texte-image est un domaine de recherche important, comme la mise en page. , posture humaine, analyse du corps humain. Des méthodes telles que ControlNet.
3. Génération avancée conditionnelle de texte : Bien que le texte joue le rôle de conditions de base dans les modèles de diffusion texte-image, il reste encore quelques défis dans ce domaine.
Tout d'abord, lorsque vous effectuez une synthèse guidée par texte dans des textes complexes impliquant plusieurs sujets ou des descriptions riches, vous rencontrez souvent le problème du désalignement du texte. De plus, ces modèles sont principalement formés sur des ensembles de données anglais, ce qui entraîne un manque important de capacités de génération multilingue. Pour remédier à cette limitation, de nombreux travaux ont proposé des approches innovantes visant à étendre la portée de ces langages modèles.
4. Génération en contexte : Dans la tâche de génération de contexte, basée sur une paire d'exemples d'images spécifiques à la tâche et de conseils textuels, comprenez et effectuez une tâche spécifique sur une nouvelle image de requête.
5. Génération guidée par le cerveau : Les tâches de génération guidée par le cerveau se concentrent sur le contrôle de la création d'images directement à partir de l'activité cérébrale, telles que les enregistrements d'électroencéphalographie (EEG) et l'imagerie par résonance magnétique fonctionnelle (IRMf).
6. Génération guidée par le son : Générez des images correspondantes basées sur le son.
7. Rendu de texte : Générez du texte dans des images, qui peut être largement utilisé dans des affiches, des couvertures de données, des émoticônes et d'autres scénarios d'application.
Génération multi-conditionnelle

La tâche de génération multi-conditionnelle est conçue pour générer des images basées sur plusieurs conditions, telles que générer une personne spécifique dans une pose définie par l'utilisateur ou générer une personne dans trois identités personnalisées.
Dans cette section, nous fournissons un aperçu complet de ces méthodes d'un point de vue technique et les classons dans les catégories suivantes :
1. Entraînement conjoint : Introduire plusieurs conditions pour un entraînement conjoint pendant la phase d'entraînement.
2. Apprentissage continu : Apprenez plusieurs conditions en séquence et n'oubliez pas les anciennes conditions tout en apprenant de nouvelles conditions pour réaliser la génération multi-conditions.
3. Fusion de poids : Utilisez les paramètres obtenus en affinant dans différentes conditions pour la fusion de poids, afin que le modèle puisse être généré dans plusieurs conditions en même temps.
4. Intégration basée sur l'attention : définit la position de plusieurs conditions (généralement des objets) dans l'image via une carte d'attention pour obtenir une génération multi-conditions.
En plus des méthodes adaptées à des types spécifiques de conditions, il existe également des méthodes générales conçues pour s'adapter à des conditions arbitraires dans la génération d'images.
Ces méthodes sont globalement classées en deux groupes en fonction de leurs fondements théoriques : les cadres généraux de prédiction de score conditionnel et l'estimation générale du score bootstrap conditionnel.
1. Cadre universel de prédiction du score de condition : Le cadre universel de prédiction du score de condition fonctionne en créant un cadre capable de coder n'importe quelle condition donnée et de les exploiter pour prédire le bruit à chaque pas de temps lors de la synthèse d'image.
Cette méthode offre une solution universelle qui peut être adaptée de manière flexible à diverses conditions. En intégrant directement les informations conditionnelles dans le modèle génératif, cette approche permet d'ajuster dynamiquement le processus de génération d'images en fonction de diverses conditions, le rendant polyvalent et applicable à divers scénarios de synthèse d'images.
2. Estimation guidée conditionnelle générale du score : D'autres méthodes utilisent l'estimation guidée conditionnelle du score pour incorporer diverses conditions dans les modèles de diffusion texte-image. Le principal défi réside dans l’obtention de conseils spécifiques à une condition à partir de variables latentes lors du débruitage.
L'introduction de nouvelles conditions peut être utile dans plusieurs tâches, notamment l'édition d'images, la complétion d'images, la combinaison d'images, la génération de texte/image 3D.
Par exemple, dans l'édition d'images, vous pouvez utiliser une méthode personnalisée pour modifier le chat sur la photo en un chat avec une identité spécifique. Pour d’autres informations, veuillez vous référer au document.
Cette revue explore le domaine de la génération conditionnelle de modèles de diffusion texte-image, révélant de nouvelles conditions incorporées dans le processus de génération guidée par texte.
Tout d'abord, l'auteur fournit aux lecteurs des connaissances de base, en introduisant le modèle probabiliste de diffusion débruitante, le célèbre modèle de diffusion texte-image et une taxonomie bien structurée. Par la suite, les auteurs ont révélé le mécanisme permettant d’introduire de nouvelles conditions dans le modèle de diffusion T2I.
Ensuite, l'auteur résume les méthodes de génération conditionnelle précédentes et les analyse sous les aspects de base théorique, de progrès technique et de stratégies de solution.
De plus, l'auteur explore les applications pratiques de la génération contrôlable, soulignant son rôle important et son énorme potentiel à l'ère de la génération de contenu IA.
Cette enquête vise à comprendre de manière globale l'état actuel du domaine de la génération T2I contrôlable, favorisant ainsi l'évolution et l'expansion continues de ce domaine de recherche dynamique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 tutoriel d'installation de pycharm
tutoriel d'installation de pycharm
 introduction au fichier hiberfil
introduction au fichier hiberfil
 Que sont les constantes de caractère
Que sont les constantes de caractère
 Carte secondaire de téléphone portable
Carte secondaire de téléphone portable
 Méthode de définition de l'espace HTML
Méthode de définition de l'espace HTML
 La fonction de la balise span
La fonction de la balise span
 Comment mettre à niveau le système Hongmeng sur le téléphone mobile Honor
Comment mettre à niveau le système Hongmeng sur le téléphone mobile Honor
 espace HTML
espace HTML
 Comment restaurer le navigateur IE pour accéder automatiquement à EDGE
Comment restaurer le navigateur IE pour accéder automatiquement à EDGE








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



