
 Périphériques technologiques
IA
Né pour la conduite autonome, Lightning NeRF : 10 fois plus rapide
Périphériques technologiques
IA
Né pour la conduite autonome, Lightning NeRF : 10 fois plus rapide
Né pour la conduite autonome, Lightning NeRF : 10 fois plus rapide

Écrit ci-dessus et compréhension personnelle de l'auteur
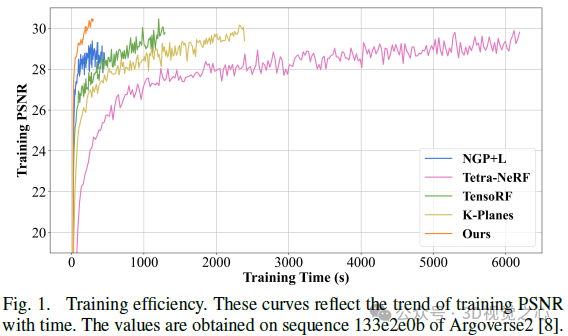
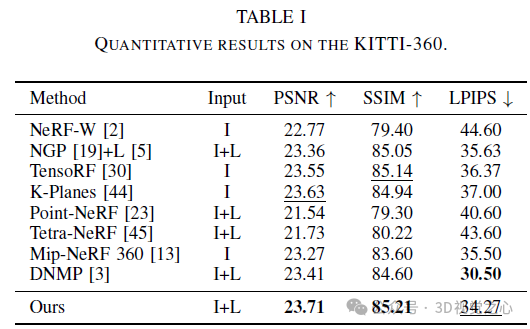
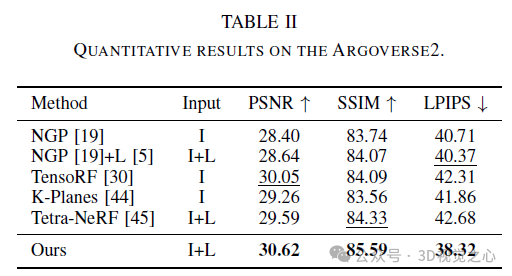
Des recherches récentes ont souligné les perspectives d'application du NeRF dans les environnements de conduite autonome. Cependant, la complexité des environnements extérieurs, associée aux points de vue restreints dans les scènes de conduite, complique la tâche de reconstruction précise de la géométrie de la scène. Ces défis se traduisent souvent par une qualité de reconstruction réduite et des durées de formation et de rendu plus longues. Pour relever ces défis, nous avons lancé Lightning NeRF. Il utilise une représentation de scène hybride efficace qui exploite efficacement les a priori géométriques du lidar dans des scénarios de conduite autonome. Lightning NeRF améliore considérablement les nouvelles performances de synthèse de vues de NeRF et réduit la surcharge de calcul. Grâce à une évaluation sur des ensembles de données du monde réel tels que KITTI-360, Argoverse2 et notre ensemble de données privé, nous démontrons que notre méthode dépasse non seulement l'état de l'art actuel en termes de qualité de synthèse de nouvelles vues, mais améliore également la vitesse d'entraînement. Cinq fois plus rapide et un rendu dix fois plus rapide. Lien H Code : https://gision-sjtu/lightning-insf
 Explication détaillée de l'approche de scénario de fonction Lightning Nerf
Explication détaillée de l'approche de scénario de fonction Lightning Nerf
preliminaries
nerf Function, ces fonctions implicites sont généralement paramétrées par MLP. Il est capable de renvoyer la valeur de couleur c et la prédiction de densité volumique σ d'un point 3D x dans la scène en fonction de la direction de visualisation d. 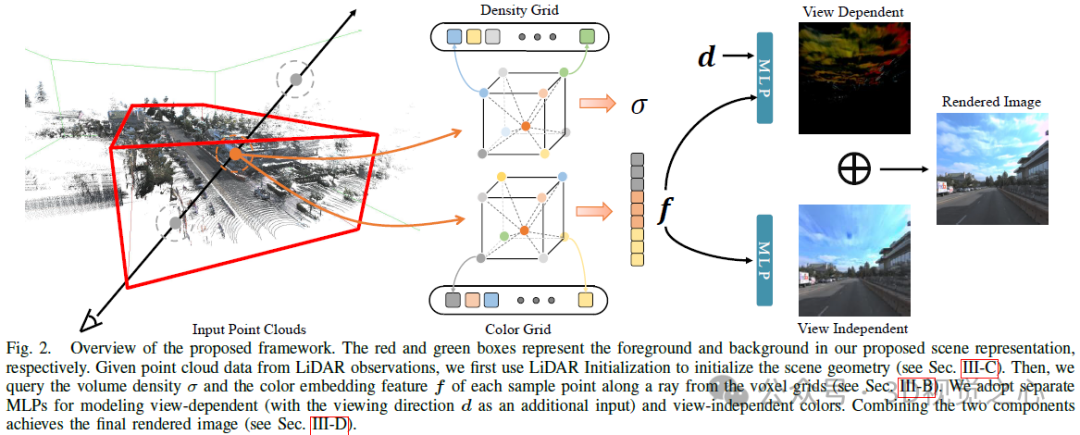
Pour restituer les pixels, NeRF utilise un échantillonnage de volume hiérarchique pour générer une série de points le long d'un rayon r, puis combine les caractéristiques de densité et de couleur prédites à ces emplacements par accumulation. 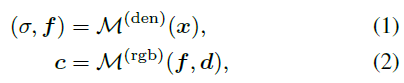
Bien que NeRF fonctionne bien dans la synthèse de nouvelles perspectives, son long temps de formation et sa vitesse de rendu lente sont principalement causés par l'inefficacité de la stratégie d'échantillonnage. Pour améliorer l'efficacité du modèle, nous maintenons une occupation de grille grossière pendant la formation et échantillonnons uniquement les emplacements dans le volume occupé. Cette stratégie d'échantillonnage est similaire aux travaux existants et permet d'améliorer les performances du modèle et d'accélérer la formation. 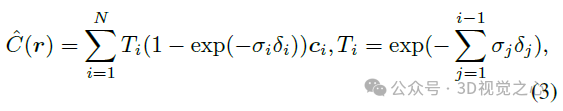
Représentation de scène hybride
La représentation de volume hybride a été optimisée et rendue rapidement à l'aide de modèles compacts. Compte tenu de cela, nous adoptons une représentation en grille de voxels hybride pour modéliser le champ de rayonnement afin d’améliorer l’efficacité. En bref, nous modélisons explicitement la densité volumétrique en stockant σ aux sommets du maillage, tout en utilisant un MLP peu profond pour décoder implicitement la couleur intégrant f dans la couleur finale c. Pour gérer la nature sans frontières des environnements extérieurs, nous divisons la représentation de la scène en deux parties, premier plan et arrière-plan, comme le montre la figure 2. Plus précisément, nous examinons le tronc de la caméra dans chaque image de la séquence de trajectoires et définissons le cadre de délimitation du premier plan de telle sorte qu'il enveloppe étroitement tous les troncs de cône dans le système de coordonnées aligné. La zone d'arrière-plan est obtenue en agrandissant la zone de premier plan le long de chaque dimension.
Représentation de la grille Voxel
. Une représentation de maillage voxel stocke explicitement les propriétés de la scène (par exemple, la densité, la couleur RVB ou les caractéristiques) dans ses sommets de maillage pour prendre en charge des requêtes de fonctionnalités efficaces. De cette façon, pour une position 3D donnée, nous pouvons décoder l'attribut correspondant via interpolation trilinéaire :
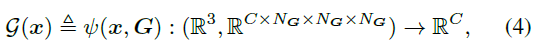 avant-plan
avant-plan
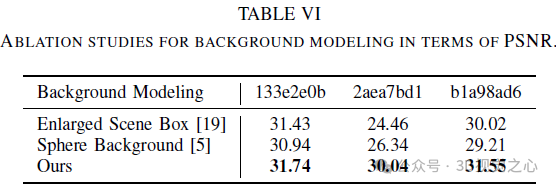
Contexte Bien que la modélisation de premier plan mentionnée précédemment fonctionne pour les champs de rayonnement au niveau des objets, l'étendre à des scènes extérieures illimitées n'est pas triviale. Certaines techniques connexes, telles que NGP, étendent directement leur cadre de délimitation de scène afin que la zone d'arrière-plan puisse être incluse, tandis que GANcraft et URF introduisent un rayonnement de fond sphérique pour résoudre ce problème. Cependant, la première tentative a entraîné un gaspillage de ses fonctionnalités puisque la majeure partie de la zone de sa zone de scène était utilisée pour la scène d'arrière-plan. Pour ce dernier schéma, il peut ne pas être capable de gérer des panoramas complexes dans des scènes urbaines (par exemple des bâtiments vallonnés ou des paysages complexes) car il suppose simplement que le rayonnement de fond dépend uniquement de la direction de la vue.
Pour cela, nous avons mis en place un modèle de maillage d'arrière-plan supplémentaire pour maintenir constante la résolution de la partie de premier plan. Nous adoptons le paramétrage de scène dans [9] comme arrière-plan, qui est soigneusement conçu. Premièrement, contrairement à la modélisation sphérique inverse, nous utilisons une modélisation cubique inverse, de norme ℓ∞, puisque nous utilisons une représentation en grille de voxels. Deuxièmement, nous n'instancions pas de MLP supplémentaire pour interroger la couleur d'arrière-plan afin d'économiser de la mémoire. Plus précisément, nous déformons les points d'arrière-plan 3D en 4D via :
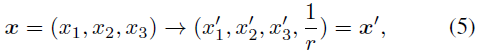
Initialisation LiDAR
en utilisant notre représentation de scène hybride, qui nécessite beaucoup de calculs lorsque nous partons directement d'une représentation de grille de voxels efficace. Ce modèle économise les calculs et la mémoire lors du MLP. interroge les valeurs de densité. Cependant, étant donné la nature à grande échelle et la complexité des scènes urbaines, cette représentation légère peut facilement rester bloquée dans des minima locaux lors de l'optimisation en raison de la résolution limitée de la grille de densité. Heureusement, en conduite autonome, la plupart des véhicules autonomes (SDV) sont équipés de capteurs LiDAR, qui fournissent des a priori géométriques approximatifs pour la reconstruction de la scène. À cette fin, nous proposons d'utiliser des nuages de points lidar pour initialiser notre maillage de densité afin de lever les obstacles d'une optimisation conjointe de la géométrie de la scène et de la radioactivité.
Décomposition des couleurs
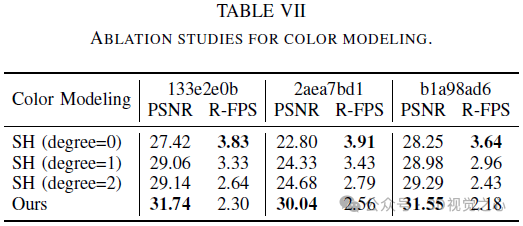
Le NeRF original utilisait un MLP dépendant de la vue pour modéliser la couleur dans le champ de rayonnement, une simplification du monde physique où le rayonnement se compose d'une couleur diffuse (indépendante de la vue) et d'une couleur spéculaire (liée à la vue). composition. De plus, étant donné que la couleur de sortie finale c est complètement liée à la direction de visualisation d, il est difficile de restituer des images haute fidélité dans des vues invisibles. Comme le montre la figure 3, notre méthode entraînée sans décomposition des couleurs (CD) échoue lors de la synthèse d'une nouvelle vue dans le paramètre d'extrapolation (c'est-à-dire en décalant la direction de visualisation de 2 mètres vers la gauche en fonction de la vue d'entraînement), tandis que notre méthode en couleur. le cas donne des résultats de rendu raisonnables.

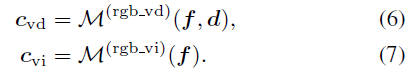
La couleur finale à l'emplacement échantillonné est la somme de ces deux facteurs :

Perte d'entraînement
Nous modifions la perte photométrique à l'aide de poids redimensionnés pour optimiser notre modèle, faites-le concentrez-vous sur des échantillons durs pour obtenir une convergence rapide. Le coefficient de poids est défini comme suit :

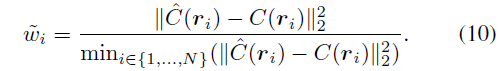
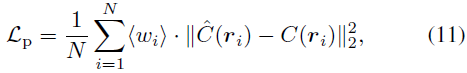 photos
photos
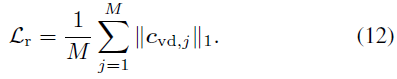

Expérience
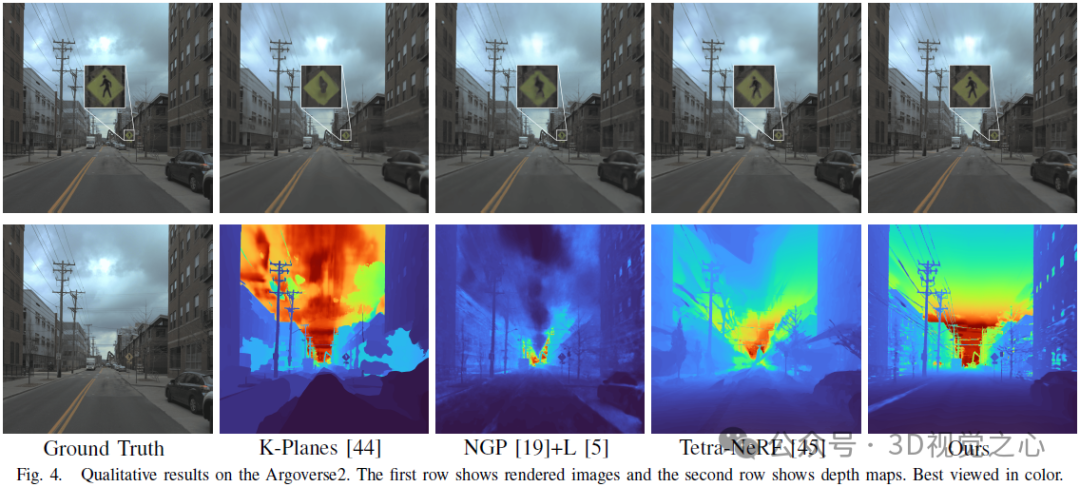
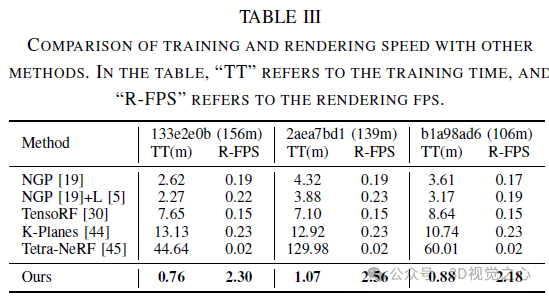
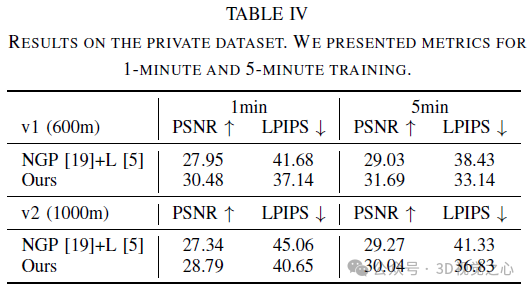

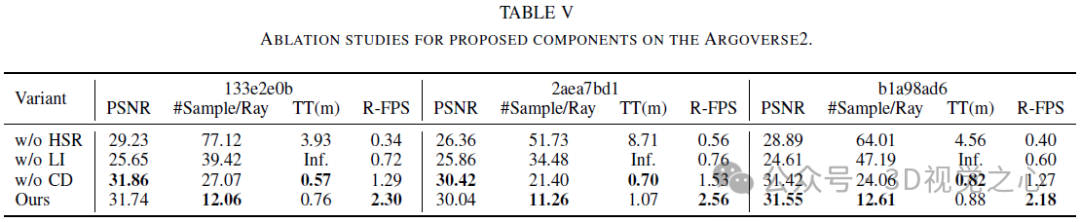
Conclusion
Cet article présente Lightning NeRF, un cadre de synthèse de vues de scènes extérieures efficace qui intègre des nuages de points et des images. La méthode proposée exploite les nuages de points pour initialiser rapidement une représentation clairsemée de la scène, obtenant ainsi des améliorations significatives en termes de performances et de vitesse. En modélisant l'arrière-plan plus efficacement, nous réduisons la pression de représentation au premier plan. Enfin, grâce à la décomposition des couleurs, les couleurs liées à la vue et indépendantes de la vue sont modélisées séparément, ce qui améliore la capacité d'extrapolation du modèle. Des expériences approfondies sur divers ensembles de données de conduite autonome démontrent que notre méthode surpasse les techniques de pointe précédentes en termes de performances et d'efficacité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
