
 tutoriels informatiques
connaissances en informatique
Utilisez ddrescue pour récupérer des données sous Linux
tutoriels informatiques
connaissances en informatique
Utilisez ddrescue pour récupérer des données sous Linux
Utilisez ddrescue pour récupérer des données sous Linux

DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes :
- Il n'écrasera pas les données récupérées mais comblera les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement.
- Récupérez les données de plusieurs fichiers ou blocs dans un seul fichier.
- Prend en charge plusieurs types d'interfaces de périphériques, telles que les lecteurs SATA, ATA, SCSI, MFM, les disquettes et les cartes SD.
Dans ce guide, j'examinerai en profondeur ce puissant outil de récupération de données, en discutant de ses étapes d'installation et de la façon de l'utiliser pour récupérer des périphériques ou des partitions bloqués.
- Installer ddrescue
- Apprenez les bases
- Considérations importantes
- Utilisez DDREASE
- Réparer les blocs cassés
- Récupérer des fichiers image vers de nouveaux blocs
- Restaurer le bloc de données vers un autre bloc de données
- Récupérer des données spécifiques à partir de fichiers image enregistrés
- Fonctionnalités avancées
- Comment fonctionne le sauvetage
- Conclusion
Veuillez noter : dans ce guide, j'utilise une distribution Linux (Ubuntu 22.04). Les étapes d'installation de l'utilitaire Ddreasure peuvent varier en fonction de la distribution, mais les directives sont universelles pour toutes les distributions Linux.
Installer ddrescue
Pour installer ddrescue sur Linux, notamment Ubuntu et ses versions ou distributions basées sur Debian, utilisez : Objectif :
sudo apt installer gddrescue
Pour l'installer sur REHL, Fedora et CentOS, activez d'abord ETEL (Extra Packages for Enterprise Linux).
sudo yum install epel—release
Les commandes ci-dessus sont applicables aux versions plus récentes des distributions respectives.
Ensuite, exécutez la commande suivante pour installer ddreasue :
sudo miam installez ddrescue
Pour les distributions basées sur Arch-Linux comme Arch-Linux et Manjaro, installez l'utilitaire de récupération ddrescue à l'aide de la commande ci-dessous.
sudo pacman—S ddrescue
Puisque j'utilise Ubuntu 22.04, j'utiliserai le gestionnaire de packages APT pour l'installer.
Apprenez les bases
Avant d'utiliser l'outil ddreasue pour récupérer des données, je recommande aux utilisateurs qui ne sont pas familiers avec le processus de récupération de comprendre certaines conventions de dénomination de Linux.
Linux reconnaît les blocs (périphériques) en tant que fichiers et les place dans le répertoire /dev. Pour répertorier les fichiers du répertoire /dev, utilisez la commande ls/dev.
Les disques durs (blocs de stockage) sont représentés par sd et l'alphabet ; dans le cas de plusieurs périphériques de stockage, les fichiers seront représentés par /dev/sda, /dev/sdb, etc.
Si le périphérique de stockage comporte des partitions, elles seront représentées par des numéros avec les noms de fichiers de lecteur correspondants, tels que /dev/sda1, /dev/sda2, etc.
Pour lister tous les blocs et autres appareils connectés dans le système, utilisez la commande list block lsblk :
lsblk
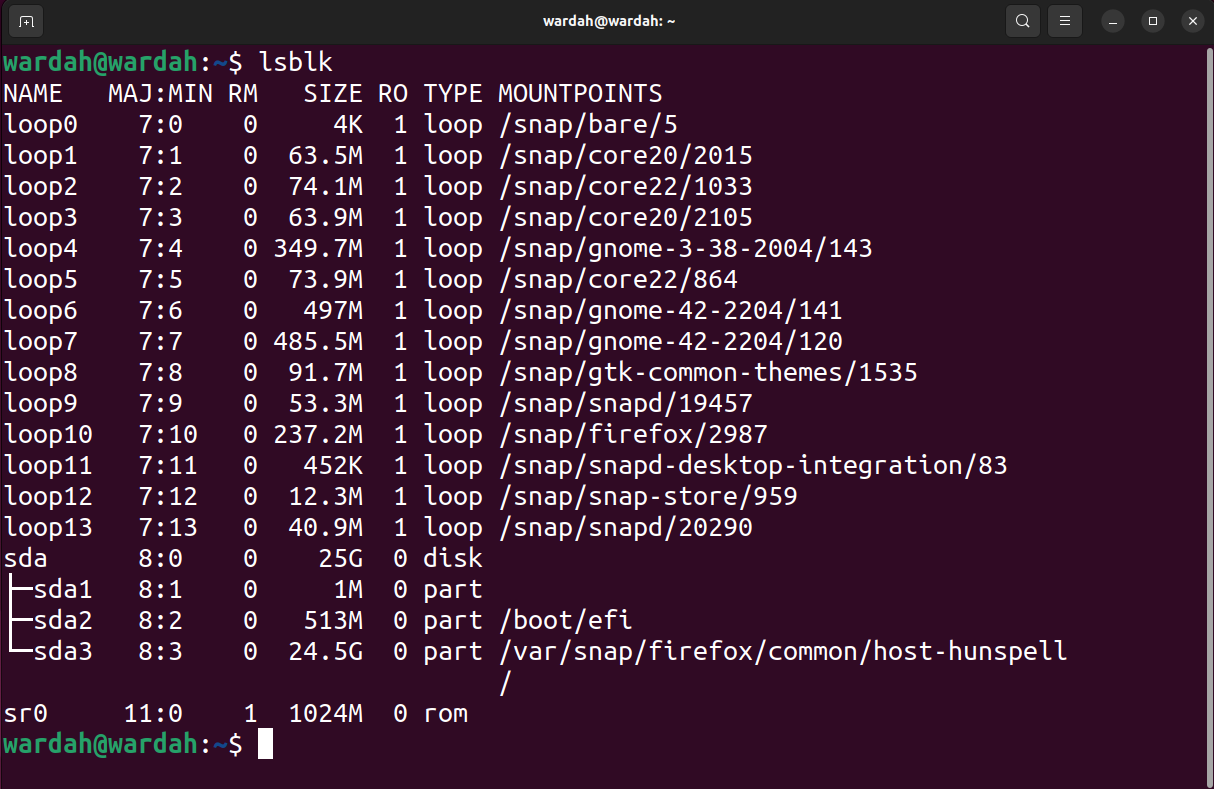
ddrescue peut récupérer des blocs entiers (y compris le MBR et les partitions) ou des partitions. D'un autre côté, si vous avez uniquement besoin de récupérer des fichiers spécifiques à partir d'une partition spécifique, il est préférable de récupérer la partition plutôt que le bloc entier.
Considérations importantes
Certains problèmes très critiques doivent être pris en compte avant d'utiliser l'utilitaire ddue :
- N'essayez pas de récupérer un bloc monté, il ne devrait même pas être en mode lecture seule.
- N'essayez pas de réparer des blocs de données contenant des erreurs d'E/S.
- Le système peut modifier les noms des périphériques d'entrée et de sortie au redémarrage. Avant de démarrer le processus de copie, assurez-vous que le nom de l'appareil est correct.
- Si vous utilisez un bloc séparé comme périphérique de sortie, toutes les données de l'appareil seront écrasées.
Utilisez ddrescue
Après avoir installé l'utilitaire ddrescue et compris la convention de dénomination, l'étape suivante consiste à identifier le disque défaillant et à le récupérer à l'aide de l'outil ddrescue.
Réparer les blocs endommagés
Le premier exemple contiendra le processus de récupération de l'intégralité du bloc. Tout d'abord, listez les blocs à l'aide de la commande lsblk :
lsblk—o Nom, Taille, FSTYPE
L'indicateur—o est utilisé pour spécifier le type d'informations (champ) que la commande doit générer. J'ai mentionné le nom, la taille et le FSTYPE ou le type de système de fichiers.
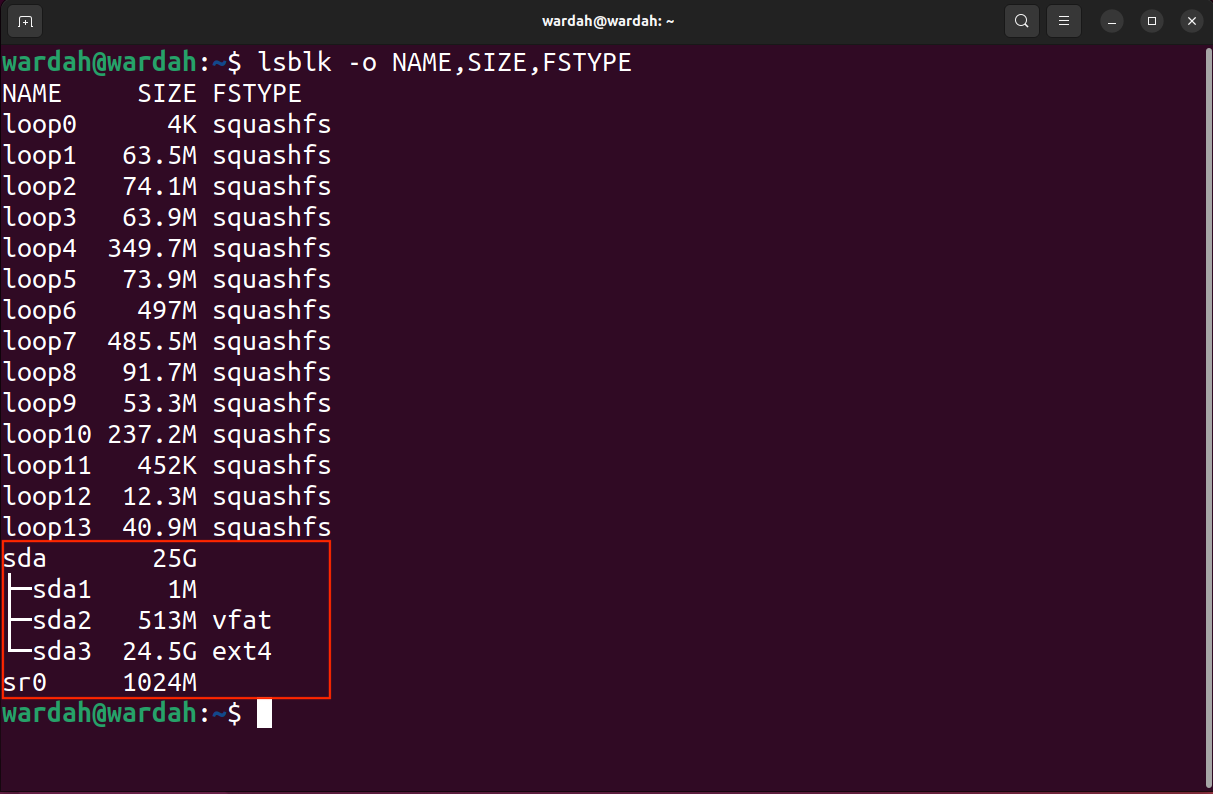
Vous pouvez maintenant déterminer le bloc cible, la partition et l'emplacement pour enregistrer le fichier image récupéré.
Une autre chose importante à noter est que sous Linux, les noms de bloc sont attribués dynamiquement au moment du démarrage et après un redémarrage, le nom du bloc peut changer. Soyez donc prudent lorsque vous écrivez les noms de blocs.
Maintenant, utilisez la syntaxe ci-dessous pour enregistrer le morceau en tant que fichier image et utilisez le fichier journal dans le répertoire racine.
sudo ddrescue—d—rX/dev/[block][path/name].
Remarque : remplacez [block], [path/name] et [logfile_name] du fichier image par le nom préféré en conséquence.Dans cet exemple, je récupère /dev/sda dans le répertoire racine en utilisant le nom de fichier image recovery.img. Les fichiers journaux (également appelés fichiers de carte) sont nécessaires si la récupération doit reprendre à tout moment.
Sudo dd Rescue -d-r2/dev/sda2 restaurer.img restaurer.log
Deux indicateurs importants sont utilisés dans la commande ci-dessus.
| D | —Indirect | Utilisé pour indiquer à l'outil d'accéder directement au disque et d'ignorer le cache du noyau |
| RX | -Réessayer-Réussi | Utilisé pour indiquer à l'outil de réessayer les secteurs défectueux X fois |
Lors de l'exécution de la commande ci-dessus, vous remarquerez que deux fichiers apparaissent dans le navigateur de fichiers nommés recovery.img et recovery.log.
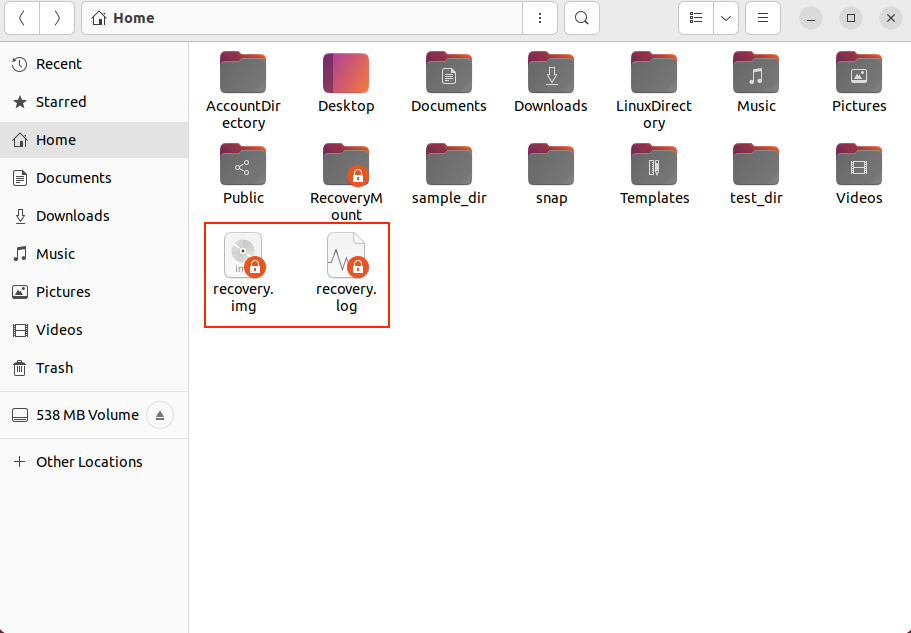
Le temps de récupération dépend de la taille du bloc d'entrée et de la corruption. Si vous souhaitez récupérer des blocs de données volumineux, je vous recommande d'utiliser des fichiers journaux, car le processus peut prendre des heures, voire des jours.
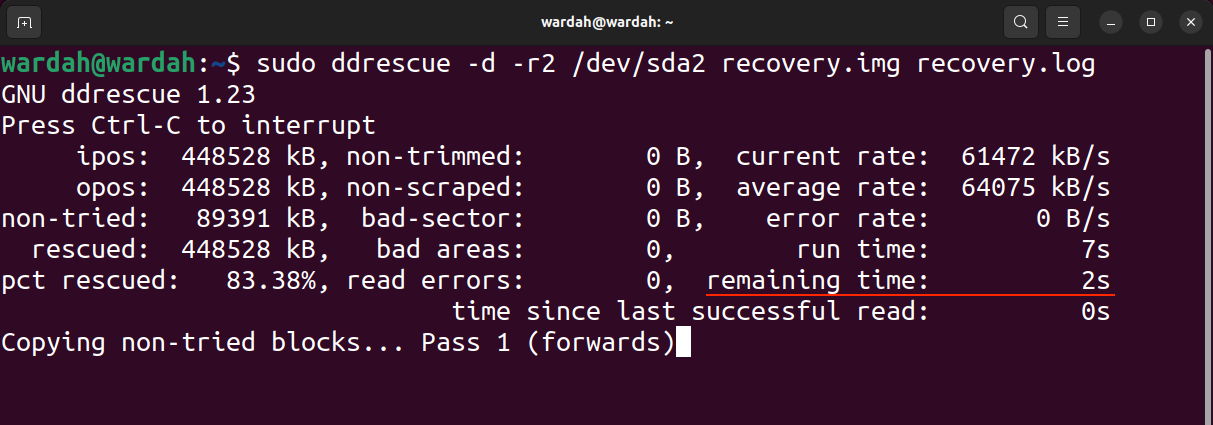
Le résultat de la commande ci-dessus est le suivant :
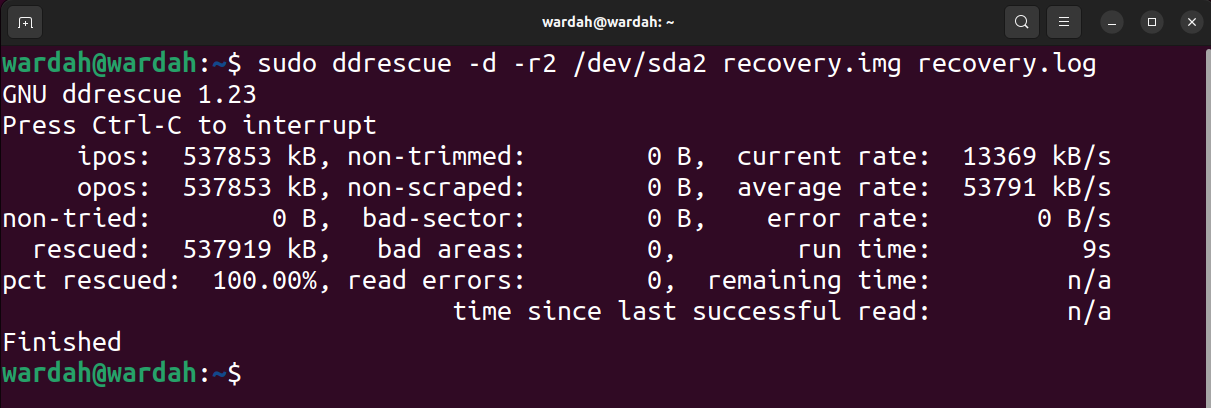
Dans l'image de sortie, ipos est l'emplacement d'entrée du fichier d'entrée à partir duquel la copie commence, et opos est l'emplacement de sortie des données écrites sur le fichier de sortie.
Non-try est la taille du bloc sans attendre un essai. Rescued représente la taille des blocs récupérés avec succès. Le PCT sauvé indique le pourcentage de données récupérées avec succès. Les termes non élagués, non rebuts, secteurs défectueux et zones défectueuses sont explicites. Cependant, les termes d’erreur de lecture représentent numériquement les tentatives de lecture ayant échoué.
Le temps d'exécution indique le temps qu'il a fallu à l'outil pour terminer le processus, tandis que le temps restant est le temps restant pour terminer le processus de récupération. La sortie ci-dessus montre que le temps restant est de 0 car le processus est terminé. Veuillez lire la sortie ci-dessous dans l'image du processus inachevé.
Voyons ce que nous obtenons dans le fichier journal ; pour ouvrir le fichier journal généré, utilisez la commande vim recovery.log.
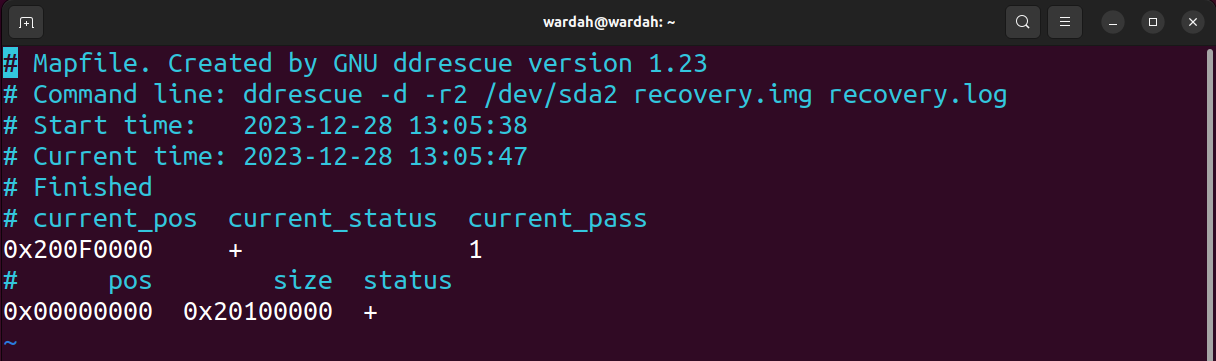
current_status est +, indiquant la fin du processus, et current_pos est la position sur le bloc.
Voir le tableau ci-dessous pour la liste des statuts actuels :
| ? | Copie |
| * | Taille |
| / | Ferraille |
| – | Réessayez |
| F | Remplissez le bloc spécifié |
| G | Générer des fichiers journaux |
| + | Le processus est terminé |
En dessous, le fichier journal affiche l'état des morceaux précédemment sauvés dans les caractères répertoriés ci-dessous :
| ? | Bloc pas encore essayé |
| * | Bloc de pépins non coupé |
| / | Blocs invalides qui ne sont pas supprimés |
| – | Échec du bloc de données du secteur défectueux |
| + | Blocage complet |
Récupérer des fichiers image dans de nouveaux blocs
Une fois que vous avez terminé le processus de récupération et que vous disposez du fichier image, vous souhaiterez peut-être maintenant le déplacer du lecteur endommagé vers le nouveau lecteur. Pour déplacer un fichier image vers un nouveau bloc, connectez d’abord le bloc au système, puis utilisez la commande lsblk pour identifier le nom du bloc.
En supposant qu'il s'agisse de /dev/sdb, utilisez la commande suivante pour copier l'image dans un nouveau bloc.
sudo ddrescue—f récupération img/dev/sdb logfile.log
S'il y a des données, utilisez l'indicateur -f pour écraser le nouveau bloc. N'oubliez pas que le fichier journal doit avoir un nom différent pour le distinguer des fichiers journaux précédemment stockés.
L'opération ci-dessus peut également être effectuée en utilisant dd, une autre commande puissante pour copier des fichiers.
sudo dd if = récupération img de =/dev/sdb
Avant de procéder à la restauration, n'oubliez pas que le nouveau bloc doit être suffisamment grand pour conserver l'intégralité du bloc récupéré ; par exemple, si le bloc récupéré fait 5 Go, le nouveau bloc doit être supérieur à 5 Go ;
Si le fichier image récupéré présente de nombreuses erreurs, elles peuvent alors être réparées dans une certaine mesure à l'aide de la commande fsck sous Linux. Sous Windows, vous pouvez utiliser la commande CHKDSK ou SFC pour ce faire. Cependant, la récupération dépend du nombre d'erreurs générées par le fichier corrompu.
Maintenant, le processus de récupération et les travaux de réparation sont terminés. Une autre chose importante à noter est qu'au lieu de créer un fichier image puis de le copier dans le nouveau bloc, vous pouvez récupérer le bloc corrompu directement sur un autre bloc. D'accord, dans la section suivante, j'entrerai dans les détails de ce processus.
Restaurer le bloc de données vers un autre bloc de données
Pour restaurer un bloc directement dans un nouveau bloc, connectez d'abord le bloc au système, puis utilisez à nouveau la commande lsblk pour identifier le nom du bloc. Des noms de bloc incorrects peuvent perturber l'ensemble du processus et vous risquez de perdre des données.
Après avoir identifié les blocs source et cible, utilisez la commande suivante pour restaurer le bloc :
sudo ddrescue—d—f—r2/dev/[source]/dev/[destination] backup.log
En supposant que /dev/sdb est le bloc cible, donc pour copier le répertoire /dev/sda dans le nouveau bloc, utilisez use :
Sudo ddue-d-f-r2/dev/sda/dev/sdb backup.log
Avant de tenter ce processus, veuillez vous référer aux principales considérations mentionnées dans les sections précédentes.
Récupérer des données spécifiques à partir de fichiers image enregistrés
Dans de nombreux cas, le but de la récupération de données est de trouver des fichiers spécifiques à partir d'un disque endommagé. Pour accéder à des fichiers spécifiques, vous devez monter le fichier image. Sous Linux, le fichier image récupéré peut être exploré à l'aide de la commande mount.
Avant de monter le fichier image, créez un dossier ou un répertoire dans lequel vous souhaitez extraire le contenu du fichier image.
Monture de récupération mkdir
Ensuite, montez le fichier image à l'aide de la commande suivante :
sudo mount—o boucle de récupération img~/Recovery Mount
Le drapeau—o indique les options, tandis que l'option de boucle est utilisée pour traiter le fichier image comme un périphérique bloc.
Vous pouvez maintenant accéder au contenu du fichier image comme indiqué dans la capture d'écran ci-dessous.
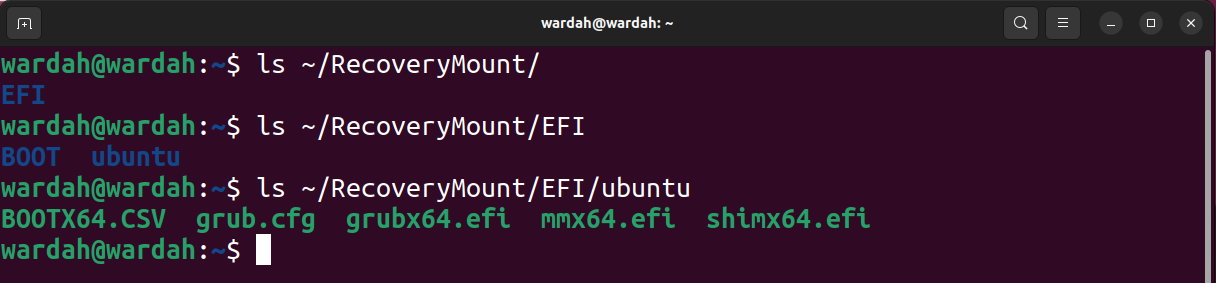
Pour démonter un bloc, utilisez la commande umount.
Désinstallation SUDO ~/restauration du chargement
Fonctionnalités avancées
Pour reprendre à partir d'un point spécifique, utilisez le drapeau -i ou -input-position. Il doit être en octets et la valeur par défaut est 0 octet. Il est important de reprendre la réplication à partir d'un point précis. Par exemple, si vous souhaitez démarrer le processus de copie à partir du point de 10 Go, utilisez la commande suivante.
sudo ddrescue—fichier image i10GiB/dev/sda img logfile.log
.Pour définir la taille maximale du périphérique d'entrée, l'indicateur -s sera utilisé. -s indique la taille, qui peut également être utilisée comme -size, en octets. Si l'outil ne reconnaît pas la taille du fichier d'entrée, utilisez cette option pour la spécifier.
Sudo ddreasure-s10GiB/dev/sda Imagefile.img log file.log
—L'option demander est très pratique car elle demande la confirmation des blocs d'entrée et de sortie avant de démarrer le processus de copie. Comme mentionné précédemment, le système attribue dynamiquement des noms aux blocs et modifie les noms au redémarrage. Dans ce cas, cette option peut être utile.
sudo ddrescue——ask/dev/sda imagefile.img logfile.log
Voici également d'autres alternatives :
| —R | —Inverser | Inverser le sens de la copie |
| —q | —Tout à fait | Annuler tous les messages de sortie |
| —V | —verbeux | Plus en détail, tous les messages de sortie |
| —p | -Pré-attribué | Pré-allouer un espace de stockage pour les fichiers de sortie |
| —P | -Aperçu des données | Les lignes d'affichage des dernières données lues sont 3 lignes par défaut |
Comment fonctionne le sauvetage
DDREASE utilise un puissant algorithme de récupération divisé en quatre étapes :
1.Copier
2.Taille
3.Rasage
4. Réessayez
L'exécution de l'algorithme ddrescue est illustrée dans la figure ci-dessous.

Conclusion
ddrescue est un puissant outil de récupération permettant de récupérer les données d'un disque endommagé ou défectueux en copiant les données sur un autre disque. Il peut être installé sans effort sur n'importe quelle distribution Linux à l'aide du gestionnaire de packages par défaut. Veuillez noter les considérations importantes avant d’utiliser cet outil mentionné dans ce guide. Le processus de copie des données est simple, démontez le lecteur et utilisez la commande ddrescue avec le nom du lecteur source et le nom du lecteur de destination. N'oubliez pas d'utiliser le fichier journal car il devient très utile pendant le processus de récupération.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment interpréter les résultats de sortie de Debian Sniffer
Apr 12, 2025 pm 11:00 PM
Comment interpréter les résultats de sortie de Debian Sniffer
Apr 12, 2025 pm 11:00 PM
DebianSniffer est un outil de renifleur de réseau utilisé pour capturer et analyser les horodatages du paquet de réseau: affiche le temps de capture de paquets, généralement en quelques secondes. Adresse IP source (SourceIP): l'adresse réseau de l'appareil qui a envoyé le paquet. Adresse IP de destination (DestinationIP): l'adresse réseau de l'appareil recevant le paquet de données. SourcePort: le numéro de port utilisé par l'appareil envoyant le paquet. Destinatio
 Comment vérifier la configuration de Debian OpenSSL
Apr 12, 2025 pm 11:57 PM
Comment vérifier la configuration de Debian OpenSSL
Apr 12, 2025 pm 11:57 PM
Cet article présente plusieurs méthodes pour vérifier la configuration OpenSSL du système Debian pour vous aider à saisir rapidement l'état de sécurité du système. 1. Confirmez d'abord la version OpenSSL, vérifiez si OpenSSL a été installé et des informations de version. Entrez la commande suivante dans le terminal: si OpenSSLVersion n'est pas installée, le système invitera une erreur. 2. Affichez le fichier de configuration. Le fichier de configuration principal d'OpenSSL est généralement situé dans /etc/ssl/opensessl.cnf. Vous pouvez utiliser un éditeur de texte (tel que Nano) pour afficher: Sutonano / etc / ssl / openssl.cnf Ce fichier contient des informations de configuration importantes telles que la clé, le chemin de certificat et l'algorithme de chiffrement. 3. Utiliser OPE
 Quels sont les paramètres de sécurité des journaux debian Tomcat?
Apr 12, 2025 pm 11:48 PM
Quels sont les paramètres de sécurité des journaux debian Tomcat?
Apr 12, 2025 pm 11:48 PM
Pour améliorer la sécurité des journaux Debiantomcat, nous devons prêter attention aux politiques clés suivantes: 1. Contrôle d'autorisation et gestion des fichiers: Autorisations du fichier journal: Les autorisations de fichier journal par défaut (640) restreignent l'accès. Il est recommandé de modifier la valeur UMask dans le script Catalina.sh (par exemple, de passer de 0027 à 0022), ou de définir directement des filepermissions dans le fichier de configuration log4j2 pour garantir les autorisations de lecture et d'écriture appropriées. Emplacement du fichier journal: Les journaux Tomcat sont généralement situés dans / opt / tomcat / journaux (ou chemin similaire), et les paramètres d'autorisation de ce répertoire doivent être vérifiés régulièrement. 2. Rotation du journal et format: rotation du journal: configurer server.xml
 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Comparaison entre Debian Sniffer et Wireshark
Apr 12, 2025 pm 10:48 PM
Comparaison entre Debian Sniffer et Wireshark
Apr 12, 2025 pm 10:48 PM
Cet article traite de l'outil d'analyse de réseau Wireshark et de ses alternatives dans Debian Systems. Il devrait être clair qu'il n'y a pas d'outil d'analyse de réseau standard appelé "Debiansniffer". Wireshark est le principal analyseur de protocole de réseau de l'industrie, tandis que Debian Systems propose d'autres outils avec des fonctionnalités similaires. Comparaison des fonctionnalités fonctionnelles Wireshark: Il s'agit d'un puissant analyseur de protocole de réseau qui prend en charge la capture de données réseau en temps réel et la visualisation approfondie du contenu des paquets de données, et fournit des fonctions de prise en charge, de filtrage et de recherche et de recherche riches pour faciliter le diagnostic des problèmes de réseau. Outils alternatifs dans le système Debian: le système Debian comprend des réseaux tels que TCPDump et Tshark
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
