
 Périphériques technologiques
IA
Nouvelle version open source de Stability AI : la génération 3D introduit un modèle de diffusion vidéo, une cohérence de qualité améliorée, une lecture en 4 090
Périphériques technologiques
IA
Nouvelle version open source de Stability AI : la génération 3D introduit un modèle de diffusion vidéo, une cohérence de qualité améliorée, une lecture en 4 090
Nouvelle version open source de Stability AI : la génération 3D introduit un modèle de diffusion vidéo, une cohérence de qualité améliorée, une lecture en 4 090

Stability AI, la société derrière Stable Diffusion, a lancé quelque chose de nouveau.
Cette période apporte de nouveaux progrès dans le domaine graphique 3D :
Stable Video 3D (SV3D) basé sur la diffusion vidéo stable peut générer des maillages 3D de haute qualité avec une seule image.

Stable Video Diffusion (SVD) est un modèle précédemment publié par Stability AI pour générer des vidéos haute résolution. L'avènement du SV3D marque la première fois que le modèle de diffusion vidéo est appliqué avec succès au domaine de la génération 3D.
A déclaré officiellement que sur cette base, SV3D a considérablement amélioré la qualité et la cohérence de la génération 3D.

Les poids des modèles sont toujours open source, mais ils ne peuvent être utilisés qu'à des fins non commerciales. Si vous souhaitez les utiliser à des fins commerciales, vous devez acheter un abonnement Stability AI~
Sans plus tarder, prenons. un regard sur les détails du document.
Utilisation du modèle de diffusion vidéo pour la génération 3D
Présentation du modèle de diffusion vidéo latente, l'objectif principal de SV3D est d'utiliser la cohérence temporelle du modèle vidéo pour améliorer la cohérence de la génération 3D.
Et les données vidéo elles-mêmes sont également plus faciles à obtenir que les données 3D.
Stability AI propose cette fois deux versions de SV3D :
- SV3D_u : Générez une vidéo orbitale basée sur une seule image.
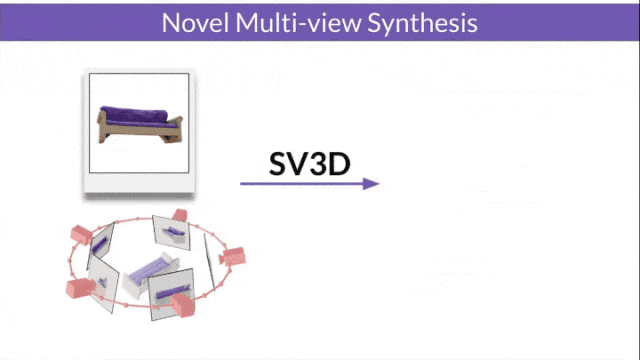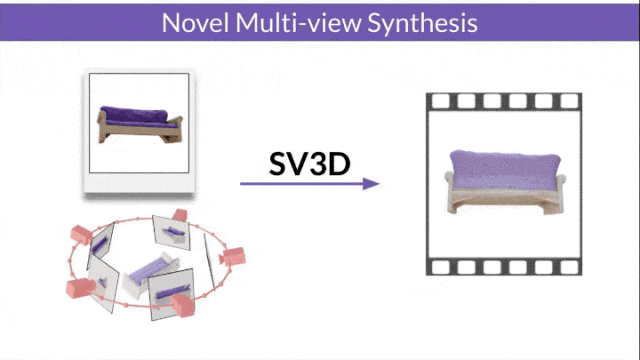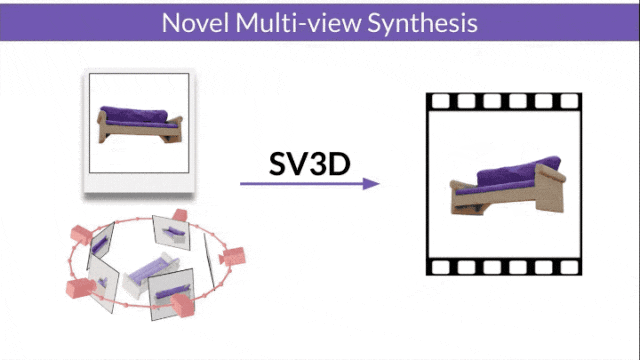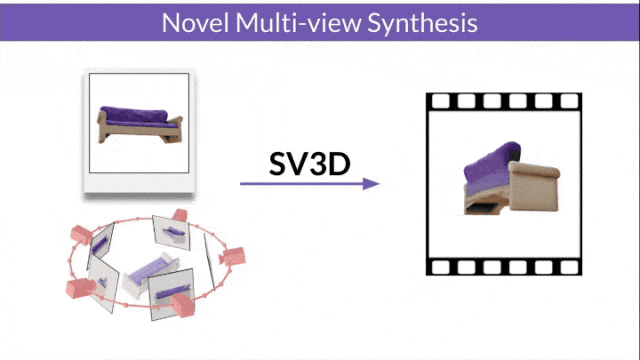
- SV3D_p : étend la fonctionnalité de SV3D_u pour créer des vidéos de modèles 3D basées sur des chemins de caméra spécifiés.
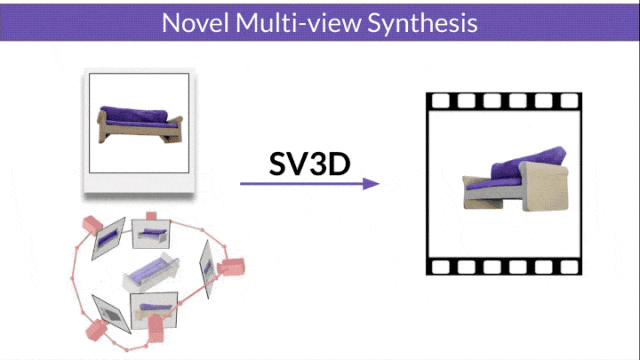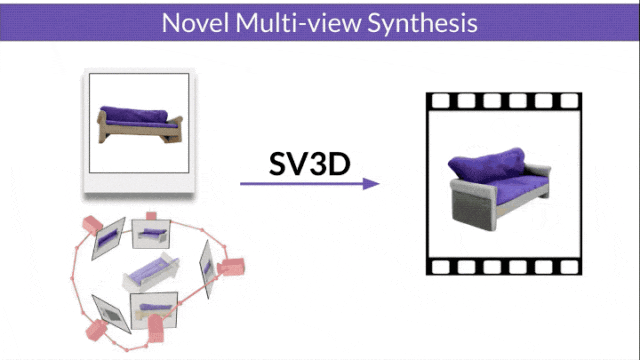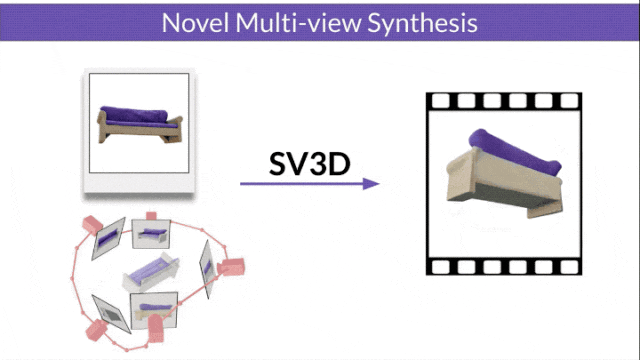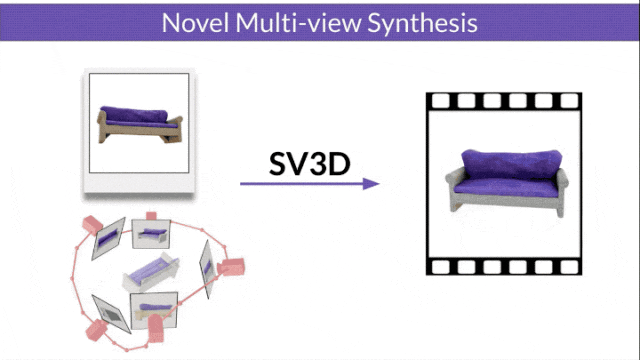
Les chercheurs ont également amélioré la technologie d'optimisation 3D : en utilisant une stratégie d'entraînement grossière à fine, en optimisant les maillages NeRF et DMTet pour générer des objets 3D.
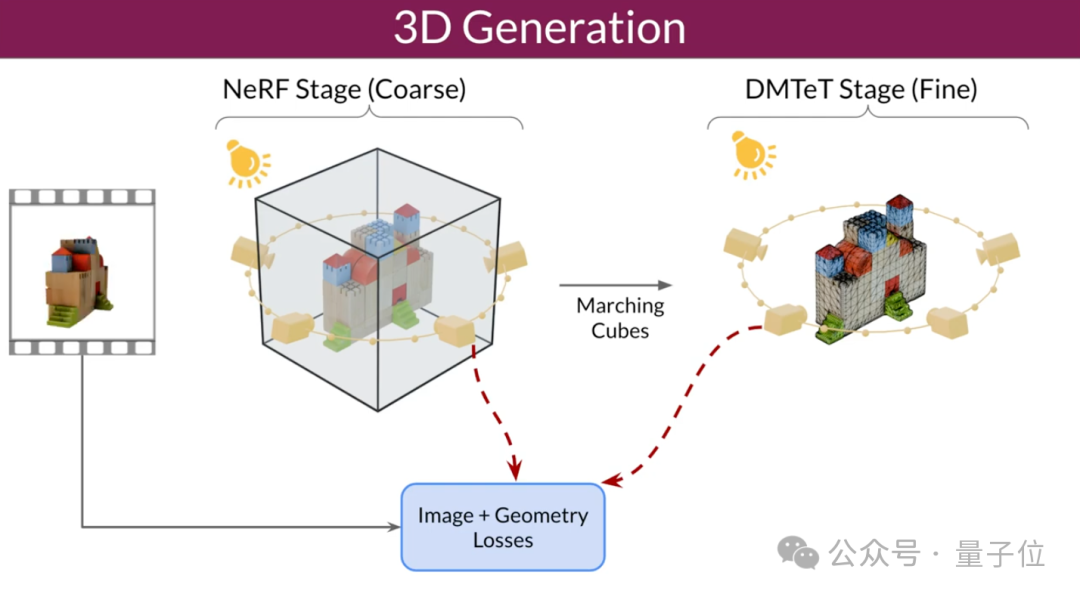
Ils ont également conçu une fonction de perte spéciale appelée échantillonnage de distillation de score masqué (SDS) pour améliorer la qualité et la cohérence des modèles 3D générés en optimisant les zones qui ne sont pas directement visibles dans les données d'entraînement.
Dans le même temps, SV3D introduit un modèle d'éclairage basé sur une gaussienne sphérique pour séparer les effets d'éclairage et les textures, réduisant ainsi efficacement les problèmes d'éclairage intégrés tout en conservant la clarté des textures.
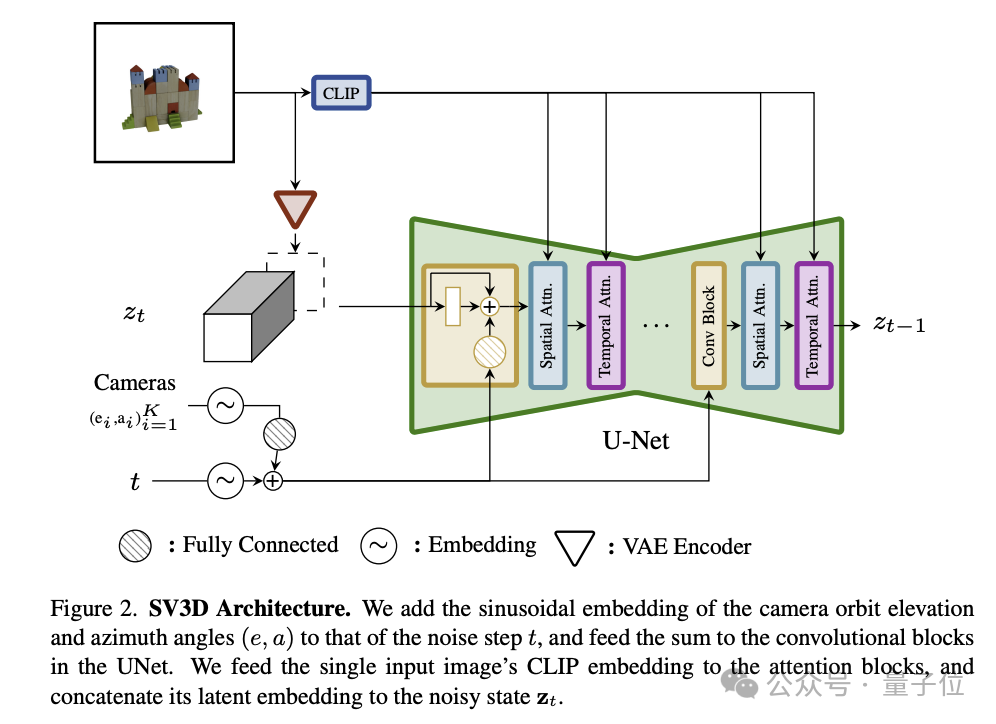
Spécifiquement en termes d'architecture, SV3D contient les composants clés suivants :
- UNet : SV3D est construit sur la base de SVD et contient un UNet multicouche, où chaque couche possède une série de blocs résiduels (y compris Couche de convolution 3D) et deux modules Transformer qui traitent respectivement les informations spatiales et temporelles.
- Entrée conditionnelle : l'image d'entrée est intégrée dans l'espace latent via l'encodeur VAE, et sera fusionnée avec l'état latent du bruit et entrée ensemble dans UNet ; la matrice d'intégration CLIP de l'image d'entrée est utilisée comme clé de chaque transformateur ; paire de valeurs de couche d'attention croisée du module.
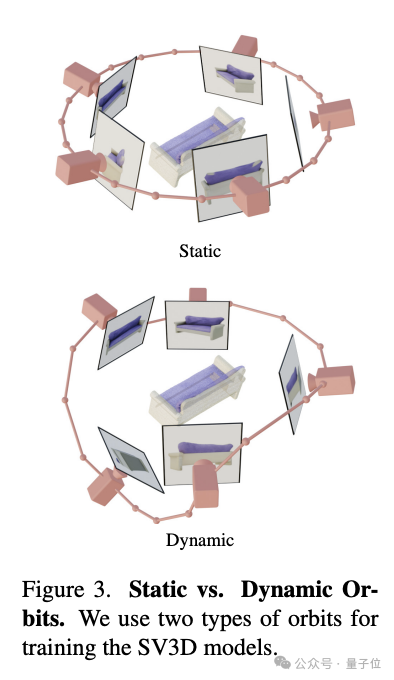
- Encodage de trajectoire de caméra : SV3D a conçu deux types de trajectoires, statiques et dynamiques, pour étudier l'impact des conditions d'attitude de la caméra. Dans une orbite statique, la caméra entoure l'objet selon des angles d'azimut régulièrement espacés ; dans une orbite dynamique, la caméra autorise des angles d'azimut irrégulièrement espacés et des angles d'élévation différents.
Les informations sur la trajectoire de mouvement de la caméra et les informations temporelles du bruit de diffusion seront entrées ensemble dans le module résiduel et converties en intégration de position sinusoïdale. Ensuite, ces informations d'intégration seront intégrées et transformées linéairement, et ajoutées au temps de bruit. intégration par étapes.
Une telle conception vise à améliorer la capacité du modèle à traiter les images en contrôlant finement les trajectoires de la caméra et l'entrée de bruit.
De plus, SV3D utilise CFG (guidage sans classificateur) pendant le processus de génération pour contrôler la netteté de la génération, en particulier lors de la génération des dernières images de la piste, la mise à l'échelle triangulaire CFG est utilisée pour éviter une netteté excessive .
Les chercheurs ont formé SV3D sur l'ensemble de données Objaverse, avec une résolution d'image de 575×576 et un champ de vision de 33,8 degrés. Le document révèle que les trois modèles (SV3D_u, SV3D_c, SV3D_p) ont été formés sur 4 nœuds pendant environ 6 jours, chaque nœud étant équipé de 8 GPU A100 de 80 Go.
Résultats expérimentaux
En termes de nouvelle synthèse de perspective (NVS) et de reconstruction 3D, SV3D surpasse les autres méthodes existantes et atteint SOTA.
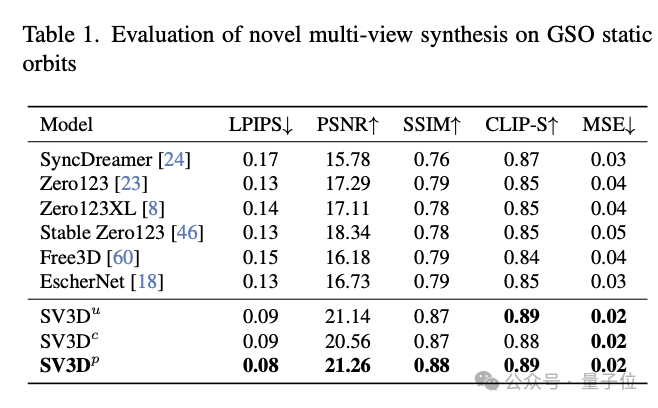
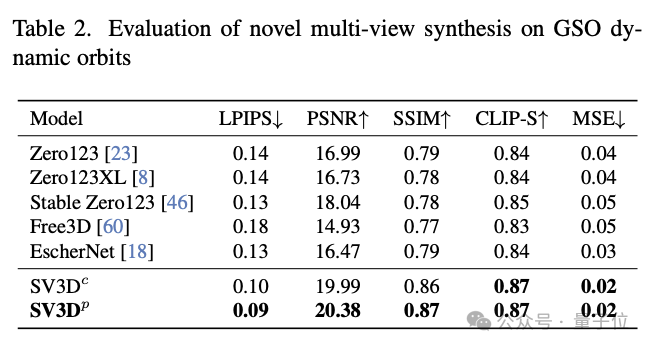
À en juger par les résultats de la comparaison qualitative, la vue multi-vue générée par SV3D a des détails plus riches et est plus proche de l'image d'entrée d'origine. En d’autres termes, SV3D peut capturer les détails avec plus de précision et maintenir la cohérence lors des changements d’angle de visualisation afin de comprendre et de reconstruire la structure 3D des objets.

De tels résultats ont suscité l'émotion de nombreux internautes :
Il est concevable que dans les 6 à 12 prochains mois, la technologie de génération 3D soit utilisée dans les jeux et les projets vidéo.

Il y a toujours des idées audacieuses dans la zone de commentaires...
Et le projet est open source La première vague d'amis y a déjà joué et peut l'exécuter sur 4090.

Lien de référence :
[1]https://twitter.com/StabilityAI/status/1769817136799855098.
[2]https://stability.ai/news/introducing-stable-video-3d.
[3]https://sv3d.github.io/index.html.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la méthode de conversion des chaînes Vue.js en objets?
Apr 07, 2025 pm 09:18 PM
Quelle est la méthode de conversion des chaînes Vue.js en objets?
Apr 07, 2025 pm 09:18 PM
L'utilisation de la chaîne JSON.Parse () à l'objet est la plus sûre et la plus efficace: assurez-vous que les chaînes sont conformes aux spécifications JSON et évitez les erreurs courantes. Utilisez Try ... Catch pour gérer les exceptions pour améliorer la robustesse du code. Évitez d'utiliser la méthode EVAL (), qui présente des risques de sécurité. Pour les énormes cordes JSON, l'analyse de fouet ou l'analyse asynchrone peut être envisagée pour optimiser les performances.
 Premier système d'IA de découverte scientifique entièrement automatisé, la startup auteur de Transformer, Sakana AI, lance AI Scientist
Aug 13, 2024 pm 04:43 PM
Premier système d'IA de découverte scientifique entièrement automatisé, la startup auteur de Transformer, Sakana AI, lance AI Scientist
Aug 13, 2024 pm 04:43 PM
Editeur | ScienceAI Il y a un an, Llion Jones, le dernier auteur de l'article Transformer de Google, a quitté son entreprise pour créer une entreprise et a cofondé la société d'intelligence artificielle SakanaAI avec l'ancien chercheur de Google, David Ha. SakanaAI prétend créer un nouveau modèle de base basé sur une intelligence inspirée de la nature ! Désormais, SakanaAI a remis sa feuille de réponses. SakanaAI annonce le lancement d'AIScientist, le premier système d'IA au monde pour la recherche scientifique automatisée et la découverte ouverte ! De la conception, l'écriture de code, la réalisation d'expériences et la synthèse des résultats, à la rédaction d'articles entiers et à la réalisation d'examens par les pairs, AIScientist ouvre la voie à la recherche et à l'accélération scientifiques basées sur l'IA.
 HyperOS 2.0 fait ses débuts avec Xiaomi 15, l'IA est au centre
Sep 01, 2024 pm 03:39 PM
HyperOS 2.0 fait ses débuts avec Xiaomi 15, l'IA est au centre
Sep 01, 2024 pm 03:39 PM
Récemment, la nouvelle a été annoncée selon laquelle Xiaomi lancerait la version très attendue d'HyperOS 2.0 en octobre. 1.HyperOS2.0 devrait être lancé simultanément avec le smartphone Xiaomi 15. HyperOS 2.0 améliorera considérablement les capacités de l'IA, notamment en matière de retouche photo et vidéo. HyperOS2.0 apportera une interface utilisateur (UI) plus moderne et raffinée, offrant des effets visuels plus fluides, plus clairs et plus beaux. La mise à jour HyperOS 2.0 inclut également un certain nombre d'améliorations de l'interface utilisateur, telles que des capacités multitâches améliorées, une gestion améliorée des notifications et davantage d'options de personnalisation de l'écran d'accueil. La sortie d'HyperOS 2.0 n'est pas seulement une démonstration de la force technique de Xiaomi, mais aussi de sa vision de l'avenir des systèmes d'exploitation pour smartphones.
 L'ancien PDG de Google, Schmidt, a fait une déclaration surprenante : l'entrepreneuriat en IA peut d'abord être 'volé' et 'traité' plus tard.
Aug 15, 2024 am 11:53 AM
L'ancien PDG de Google, Schmidt, a fait une déclaration surprenante : l'entrepreneuriat en IA peut d'abord être 'volé' et 'traité' plus tard.
Aug 15, 2024 am 11:53 AM
Selon des informations publiées sur ce site le 15 août, un discours prononcé hier par l'ancien PDG et président de Google, Eric Schmidt, à l'Université de Stanford, a suscité une énorme controverse. En plus de susciter la controverse en affirmant que les employés de Google estiment que « le travail à domicile est plus important que de gagner », en parlant du développement futur de l'intelligence artificielle, il a ouvertement déclaré que les startups d'IA peuvent d'abord voler la propriété intellectuelle (PI) grâce à des outils d'IA. puis embauchez des avocats pour gérer les litiges juridiques. Schmidt parle de l'impact de l'interdiction de TikTok Schmidt prend comme exemple la plateforme de vidéos courtes TikTok, affirmant que si TikTok est interdit, n'importe qui peut utiliser l'IA pour générer une application similaire et voler directement tous les utilisateurs, toute la musique et tout autre contenu (MakemeacopyofTikTok). , voler toute l'utilisation
 Comment faire la distinction entre la fermeture d'un onglet de navigateur et la fermeture du navigateur entier à l'aide de JavaScript?
Apr 04, 2025 pm 10:21 PM
Comment faire la distinction entre la fermeture d'un onglet de navigateur et la fermeture du navigateur entier à l'aide de JavaScript?
Apr 04, 2025 pm 10:21 PM
Comment faire la distinction entre la fermeture des onglets et la fermeture du navigateur entier à l'aide de JavaScript sur votre navigateur? Pendant l'utilisation quotidienne du navigateur, les utilisateurs peuvent ...
 Quelles sont les meilleures pratiques pour convertir le XML en images?
Apr 02, 2025 pm 08:09 PM
Quelles sont les meilleures pratiques pour convertir le XML en images?
Apr 02, 2025 pm 08:09 PM
La conversion de XML en images peut être réalisée via les étapes suivantes: analyser les données XML et extraire les informations d'élément visuel. Sélectionnez la bibliothèque graphique appropriée (telle que Pillow in Python, JFreechart en Java) pour rendre l'image. Comprendre la structure XML et déterminer comment les données sont traitées. Choisissez les bons outils et méthodes basés sur la structure XML et la complexité de l'image. Pensez à utiliser la programmation multithread ou asynchrone pour optimiser les performances tout en maintenant la lisibilité et la maintenabilité du code.
 C Structure des données du langage: Le rôle clé des structures de données dans l'intelligence artificielle
Apr 04, 2025 am 10:45 AM
C Structure des données du langage: Le rôle clé des structures de données dans l'intelligence artificielle
Apr 04, 2025 am 10:45 AM
C Structure des données du langage: Aperçu du rôle clé de la structure des données dans l'intelligence artificielle dans le domaine de l'intelligence artificielle, les structures de données sont cruciales pour traiter de grandes quantités de données. Les structures de données fournissent un moyen efficace d'organiser et de gérer les données, d'optimiser les algorithmes et d'améliorer l'efficacité du programme. Les structures de données courantes utilisées couramment les structures de données dans le langage C comprennent: les tableaux: un ensemble d'éléments de données stockés consécutivement avec le même type. Structure: un type de données qui organise différents types de données ensemble et leur donne un nom. Liste liée: une structure de données linéaire dans laquelle les éléments de données sont connectés ensemble par des pointeurs. Stack: Structure de données qui suit le dernier principe de premier-out (LIFO). File: Structure de données qui suit le premier principe de première sortie (FIFO). Cas pratique: le tableau adjacent dans la théorie des graphiques est l'intelligence artificielle
 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
