
 Périphériques technologiques
IA
Google lance le modèle « Vlogger » : une seule image génère une vidéo de 10 secondes
Périphériques technologiques
IA
Google lance le modèle « Vlogger » : une seule image génère une vidéo de 10 secondes
Google lance le modèle « Vlogger » : une seule image génère une vidéo de 10 secondes

Google a publié un nouveau cadre vidéo :
Vous n'avez besoin que d'une photo de vous et d'un enregistrement de votre discours, et vous pouvez obtenir une vidéo réaliste de votre discours.
La durée de la vidéo est variable et l'exemple actuel vu va jusqu'à 10 secondes.
Vous pouvez voir que qu'il s'agisse de la forme de la bouche ou de l'expression du visage, c'est très naturel.
Si l'image d'entrée couvre tout le haut du corps, elle peut également être utilisée avec de riches gestes :

Après l'avoir lue, les internautes ont dit :
Avec elle, nous n'aurons plus besoin de tenir les vidéoconférences en ligne à l'avenir Finissez de vous coiffer et habillez-vous avant de partir.
Eh bien, prenez simplement un portrait et enregistrez l'audio de la parole (tête de chien manuelle)
Utilisez votre voix pour contrôler le portrait afin de générer une vidéo
Ce cadre s'appelle VLOGGER.
Il est principalement basé sur le modèle de diffusion et contient deux parties :
L'une est le modèle de diffusion aléatoire humain-à-3D-motion(humain à-3D-motion).
L'autre est une nouvelle architecture de diffusion pour améliorer les modèles texte-image.
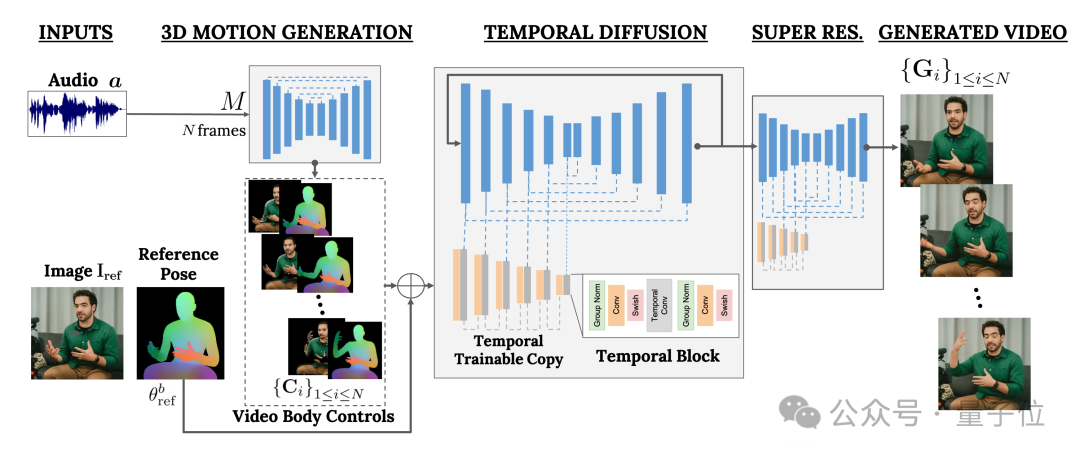
Parmi eux, le premier est chargé d'utiliser la forme d'onde audio comme entrée pour générer les actions de contrôle corporel du personnage, y compris les yeux, les expressions et les gestes, la posture globale du corps, etc.
Ce dernier est un modèle image à image de dimension temporelle qui est utilisé pour étendre le modèle de diffusion d'images à grande échelle et utiliser les actions qui viennent d'être prédites pour générer les images correspondantes.
Afin de rendre les résultats conformes à une image de personnage spécifique, VLOGGER prend également le diagramme de pose de l'image de paramètre en entrée.
La formation de VLOGGER est complétée sur un très grand ensemble de données (nommé MENTOR) .
Quelle est sa taille ? Il dure 2 200 heures et contient 800 000 vidéos de personnages.
Parmi eux, la durée vidéo de l'ensemble de test est également de 120 heures, avec un total de 4 000 caractères.
Google a présenté que la performance la plus remarquable de VLOGGER est sa diversité :
Comme le montre l'image ci-dessous, plus la partie (rouge) de l'image finale en pixels est sombre, plus les actions sont riches.

Par rapport aux méthodes similaires précédentes dans l'industrie, le plus grand avantage de VLOGGER est qu'il n'a pas besoin de former tout le monde, ne repose pas sur la détection et le recadrage des visages, et la vidéo générée est très complète (y compris les visages et lèvres, y compris les mouvements du corps) et ainsi de suite.

Plus précisément, comme le montre le tableau suivant :
La méthode de reconstitution du visage ne peut pas contrôler une telle génération de vidéo avec de l'audio et du texte.
Audio-to-motion peut générer de l'audio en codant l'audio en mouvements du visage 3D, mais l'effet qu'il génère n'est pas assez réaliste.
La synchronisation labiale peut gérer des vidéos de différents thèmes, mais elle ne peut que simuler les mouvements de la bouche.
En comparaison, les deux dernières méthodes, SadTaker et Styletalk, fonctionnent le plus proche de Google VLOGGER, mais elles sont également vaincues par l'incapacité de contrôler le corps et de modifier davantage la vidéo.

En parlant de montage vidéo, comme le montre l'image ci-dessous, l'une des applications du modèle VLOGGER est la suivante : il peut faire taire le personnage, fermer les yeux, fermer uniquement l'œil gauche ou ouvrir l'œil entier. en un clic :

Une autre application est la traduction vidéo :
Par exemple, changer le discours anglais de la vidéo originale en espagnol avec la même forme de bouche.
Les internautes se sont plaints
Enfin, selon "l'ancienne règle", Google n'a pas publié le modèle. Maintenant, tout ce que nous pouvons voir, ce sont plus d'effets et de papiers.
Eh bien, il y a beaucoup de plaintes :
La qualité d'image du modèle, la synchronisation labiale ne correspond pas, ça a toujours l'air très robotique, etc.
Certaines personnes n'ont donc pas hésité à laisser un avis négatif :
Est-ce le niveau de Google ?

Je suis un peu désolé pour le nom « VLOGGER ».

——Par rapport à Sora d'OpenAI, la déclaration de l'internaute n'est en effet pas déraisonnable. .
Qu'en pensez-vous ?
Plus d'effets :https://enriccorona.github.io/vlogger/
Article complet : https://enriccorona.github.io/vlogger/paper.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment enregistrer une vidéo d'écran avec un téléphone OPPO (opération simple)
May 07, 2024 pm 06:22 PM
Comment enregistrer une vidéo d'écran avec un téléphone OPPO (opération simple)
May 07, 2024 pm 06:22 PM
Compétences de jeu ou démonstrations pédagogiques, dans la vie quotidienne, nous avons souvent besoin d'utiliser des téléphones portables pour enregistrer des vidéos d'écran afin de montrer certaines étapes de fonctionnement. Sa fonction d'enregistrement vidéo sur écran est également très bonne et le téléphone mobile OPPO est un smartphone puissant. Vous permettant d'effectuer la tâche d'enregistrement facilement et rapidement, cet article présentera en détail comment utiliser les téléphones mobiles OPPO pour enregistrer des vidéos d'écran. Préparation - Déterminer les objectifs d'enregistrement Vous devez clarifier vos objectifs d'enregistrement avant de commencer. Voulez-vous enregistrer une vidéo de démonstration étape par étape ? Ou souhaitez-vous enregistrer un merveilleux moment d'un jeu ? Ou souhaitez-vous enregistrer une vidéo pédagogique ? Seulement en organisant mieux le processus d’enregistrement et en fixant des objectifs clairs. Ouvrez la fonction d'enregistrement d'écran du téléphone mobile OPPO et recherchez-la dans le panneau de raccourcis. La fonction d'enregistrement d'écran se trouve dans le panneau de raccourcis.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Comment changer de langue dans Adobe After Effects cs6 (Ae cs6) Étapes détaillées pour basculer entre le chinois et l'anglais dans Ae cs6 - Téléchargement ZOL
May 09, 2024 pm 02:00 PM
Comment changer de langue dans Adobe After Effects cs6 (Ae cs6) Étapes détaillées pour basculer entre le chinois et l'anglais dans Ae cs6 - Téléchargement ZOL
May 09, 2024 pm 02:00 PM
1. Recherchez d’abord le dossier AMTLanguages . Nous avons trouvé de la documentation dans le dossier AMTLanguages. Si vous installez le chinois simplifié, il y aura un document texte zh_CN.txt (le contenu du texte est : zh_CN). Si vous l'avez installé en anglais, il y aura un document texte en_US.txt (le contenu du texte est : en_US). 3. Par conséquent, si nous voulons passer au chinois, nous devons créer un nouveau document texte de zh_CN.txt (le contenu du texte est : zh_CN) sous le chemin AdobeAfterEffectsCCSupportFilesAMTLanguages . 4. Au contraire, si on veut passer à l'anglais,
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 Comment filmer des vidéos sur TikTok ? Comment allumer le microphone pour l'enregistrement vidéo ?
May 09, 2024 pm 02:40 PM
Comment filmer des vidéos sur TikTok ? Comment allumer le microphone pour l'enregistrement vidéo ?
May 09, 2024 pm 02:40 PM
En tant que l’une des plateformes de vidéos courtes les plus populaires aujourd’hui, la qualité et l’effet des vidéos de Douyin affectent directement l’expérience visuelle de l’utilisateur. Alors, comment filmer des vidéos de haute qualité sur TikTok ? 1. Comment filmer des vidéos sur Douyin ? 1. Ouvrez l'application Douyin et cliquez sur le bouton « + » au milieu en bas pour accéder à la page de tournage vidéo. 2. Douyin propose une variété de modes de prise de vue, notamment la prise de vue normale, le ralenti, la vidéo courte, etc. Choisissez le mode de prise de vue approprié en fonction de vos besoins. 3. Sur la page de prise de vue, cliquez sur le bouton « Filtre » en bas de l'écran pour choisir différents effets de filtre afin de rendre la vidéo plus personnalisée. 4. Si vous devez ajuster des paramètres tels que l'exposition et le contraste, vous pouvez cliquer sur le bouton « Paramètres » dans le coin inférieur gauche de l'écran pour le définir. 5. Pendant la prise de vue, vous pouvez cliquer sur le côté gauche de l'écran
