
 Périphériques technologiques
IA
Stable Video 3D fait des débuts choquants : une seule image génère une vidéo 3D sans angles morts et les poids des modèles sont ouverts
Périphériques technologiques
IA
Stable Video 3D fait des débuts choquants : une seule image génère une vidéo 3D sans angles morts et les poids des modèles sont ouverts
Stable Video 3D fait des débuts choquants : une seule image génère une vidéo 3D sans angles morts et les poids des modèles sont ouverts

Stability AI compte un nouveau membre dans sa grande famille de modèles.
Hier, après avoir lancé Stable Diffusion et Stable Video Diffusion, Stability AI a apporté à la communauté un grand modèle de génération de vidéo 3D "Stable Video 3D" (SV3D en abrégé).
Ce modèle est construit sur la base de la diffusion vidéo stable, son principal avantage est qu'il améliore considérablement la qualité de la génération 3D et la cohérence multi-vues. Par rapport au précédent Stable Zero123 lancé par Stability AI et au Zero123-XL open source commun, l'effet de ce modèle est encore meilleur.
Actuellement, Stable Video 3D prend en charge à la fois une utilisation commerciale, qui nécessite l'adhésion à Stability AI (adhésion) et une utilisation non commerciale, où les utilisateurs peuvent télécharger les poids du modèle sur Hugging Face.

Stability AI propose deux variantes de modèle, à savoir SV3D_u et SV3D_p. SV3D_u génère une vidéo orbitale basée sur une seule entrée d'image sans nécessiter de réglages de caméra, tandis que SV3D_p étend encore les capacités de génération en adaptant une seule image et une perspective orbitale, permettant aux utilisateurs de créer des vidéos 3D le long d'un chemin de caméra spécifié.
Actuellement, le document de recherche sur Stable Video 3D a été publié, avec trois auteurs principaux.

- Adresse papier : https://stability.ai/s/SV3D_report.pdf
- Adresse du blog : https://stability.ai/news/introducing-stable-video- 3d
- Huggingface Adresse : https://huggingface.co/stabilityai/sv3d
Aperçu technique
Stable Video 3D a réalisé des progrès significatifs dans le domaine de la génération 3D, en particulier dans la synthèse de génération de vues inédites. , NVS).
Les méthodes précédentes avaient souvent tendance à résoudre le problème des angles de vision limités et des entrées incohérentes, tandis que Stable Video 3D est capable de fournir une vue cohérente sous n'importe quel angle donné et de bien généraliser. En conséquence, le modèle augmente non seulement la contrôlabilité de la pose, mais garantit également une apparence cohérente des objets sur plusieurs vues, améliorant ainsi les problèmes clés affectant la génération 3D réaliste et précise.
Comme le montre la figure ci-dessous, par rapport à Stable Zero123 et Zero-XL, Stable Video 3D est capable de générer de nouvelles vues multiples avec des détails plus forts, une plus grande fidélité à l'image d'entrée et des points de vue multiples plus cohérents.

De plus, Stable Video 3D exploite sa cohérence multi-vues pour optimiser les champs de radiance neuronale 3D (NeRF) afin d'améliorer la qualité des maillages 3D générés directement à partir de nouvelles vues.
À cette fin, Stability AI a conçu un masque de perte d'échantillonnage par distillation fractionnée qui améliore encore la qualité 3D des régions invisibles dans la vue prédite. Également pour atténuer les problèmes d'éclairage, Stable Video 3D utilise un modèle d'éclairage découplé optimisé avec des formes et des textures 3D.
L'image ci-dessous montre un exemple de génération de maillage 3D améliorée grâce à l'optimisation 3D lors de l'utilisation du modèle Stable Video 3D et de sa sortie.

L'image ci-dessous montre la comparaison des résultats de maillage 3D générés à l'aide de Stable Video 3D avec ceux générés par EscherNet et Stable Zero123.

Détails de l'architecture
L'architecture du modèle Stable Video 3D est illustrée dans la figure 2 ci-dessous. Elle est construite sur la base de l'architecture Stable Video Diffusion et contient un UNet avec plusieurs couches, chacune d'elles. qui contient également une séquence de blocs résiduels avec une couche Conv3D et deux blocs de transformation avec des couches d'attention (spatiale et temporelle).
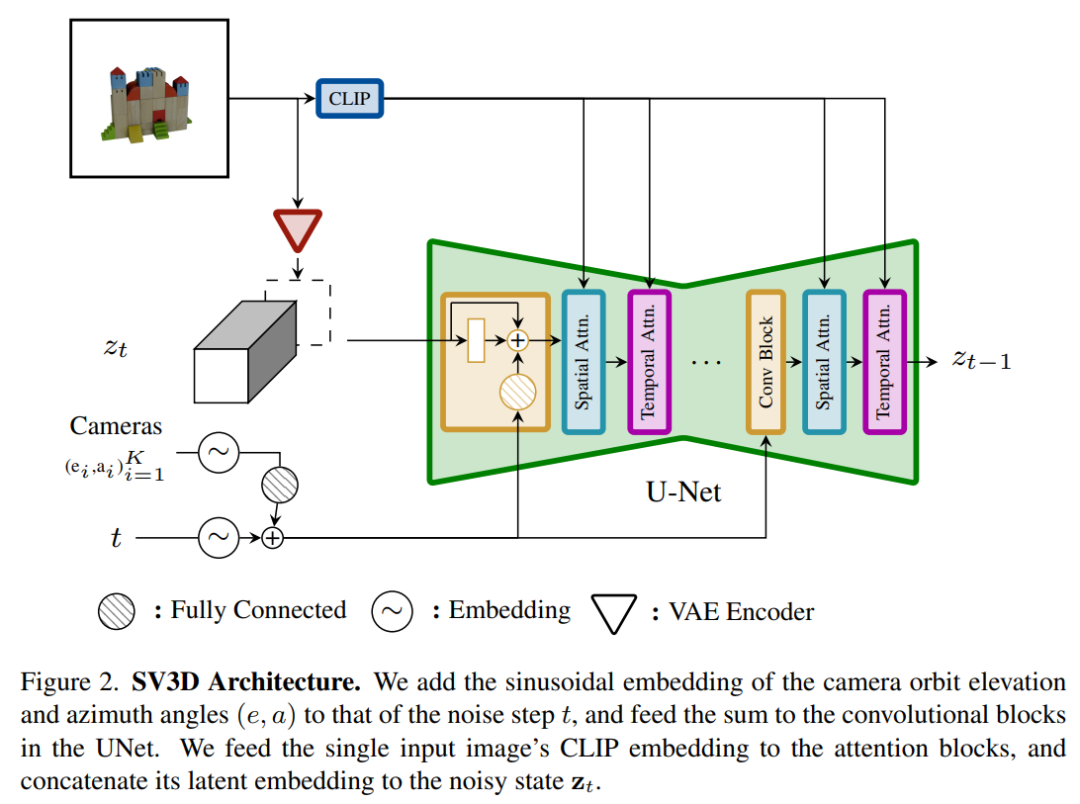
Le processus spécifique est le suivant :
(i) Supprimez les conditions vectorielles "fps id" et "motion bucket id" car elles n'ont rien à voir avec Stable Video 3D
(ii) Le l'image conditionnelle passe L'encodeur VAE de Stable Video Diffusion est intégré dans l'espace latent puis connecté à l'entrée d'état latent du bruit zt au pas de temps de bruit t menant à UNet
(iii) La matrice CLIPembedding de l'image conditionnelle est fournie ; à chaque bloc de transformateur Les couches d'attention croisée agissent comme des clés et des valeurs, et les requêtes deviennent des caractéristiques de la couche correspondante
(iv) La trajectoire de la caméra est introduite dans le bloc résiduel le long du pas de temps du bruit de diffusion ; Les angles de pose de la caméra ei et ai et le pas de temps de bruit t sont d'abord intégrés dans l'intégration de position sinusoïdale, puis les intégrations de pose de caméra sont concaténées ensemble pour une transformation linéaire et ajoutées à l'intégration de pas de temps de bruit, et enfin introduites dans chaque bloc résiduel et est ajouté aux fonctionnalités d’entrée du bloc.
De plus, Stability AI a conçu des orbites statiques et des orbites dynamiques pour étudier l'impact des ajustements de pose de la caméra, comme le montre la figure 3 ci-dessous.
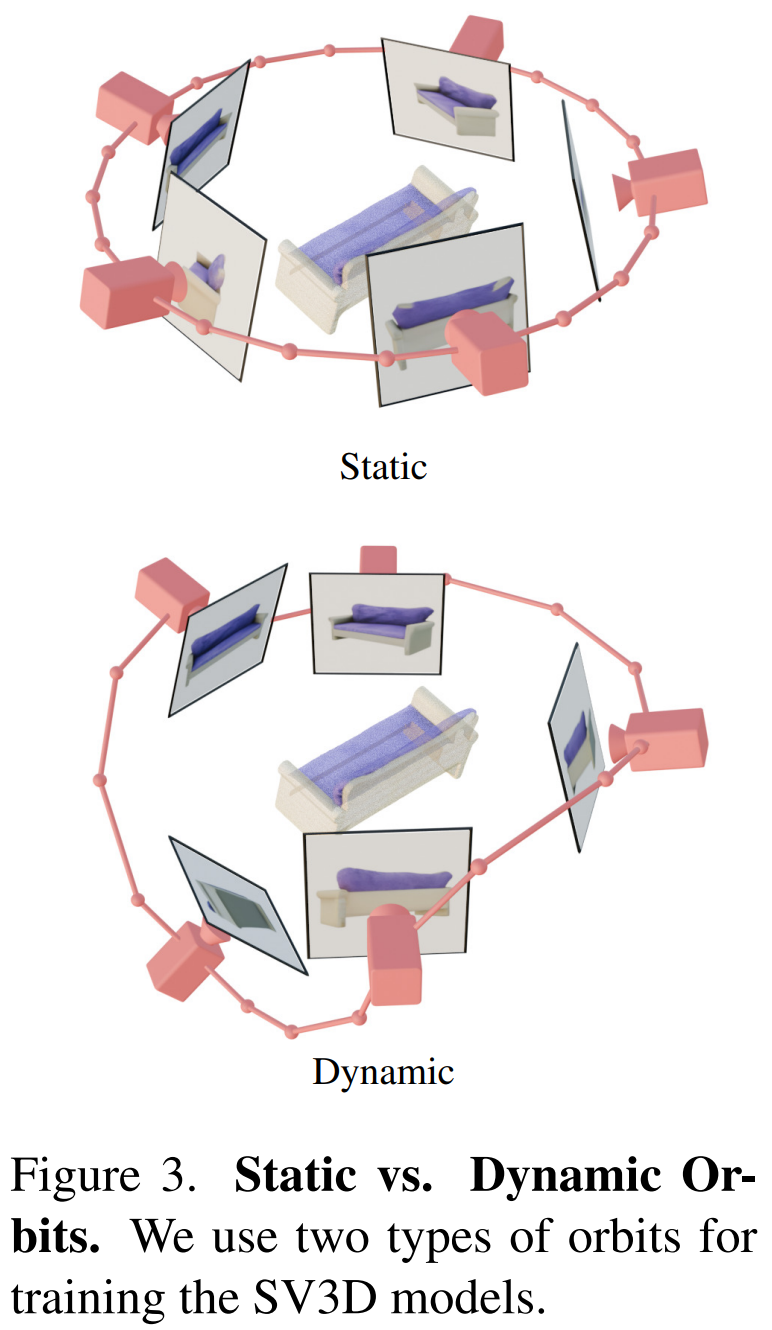
Sur une orbite statique, la caméra tourne autour de l'objet dans un azimut équidistant en utilisant le même angle d'élévation que l'image de condition. L'inconvénient est qu'en fonction de l'angle d'élévation ajusté, vous risquez de ne pas obtenir d'informations sur le haut ou le bas de l'objet. Dans une orbite dynamique, les angles d'azimut peuvent être inégaux et les angles d'élévation de chaque vue peuvent également être différents.
Pour construire une orbite dynamique, Stability AI échantillonne une orbite statique, ajoute un petit bruit aléatoire à son azimut et une combinaison pondérée aléatoirement de sinusoïdes de différentes fréquences à son élévation. Cela assure une fluidité temporelle et garantit que la trajectoire de la caméra se termine le long de la même boucle d'azimut et d'élévation que l'image de condition.
Résultats expérimentaux
Stability AI évalue les effets multi-vues composites Stable Video 3D sur des orbites statiques et dynamiques sur des ensembles de données GSO et OmniObject3D invisibles. Les résultats, présentés dans les tableaux 1 à 4 ci-dessous, montrent que Stable Video 3D atteint des performances de pointe en matière de nouvelle synthèse multi-vues.
Le Tableau 1 et le Tableau 3 montrent les résultats de Stable Video 3D par rapport à d'autres modèles sur des orbites statiques, montrant que même le modèle SV3D_u sans ajustement de pose fonctionne mieux que toutes les méthodes précédentes.
Les résultats de l'analyse d'ablation montrent que SV3D_c et SV3D_p surpassent SV3D_u dans la génération de trajectoires statiques, bien que cette dernière soit entraînée exclusivement sur des trajectoires statiques.
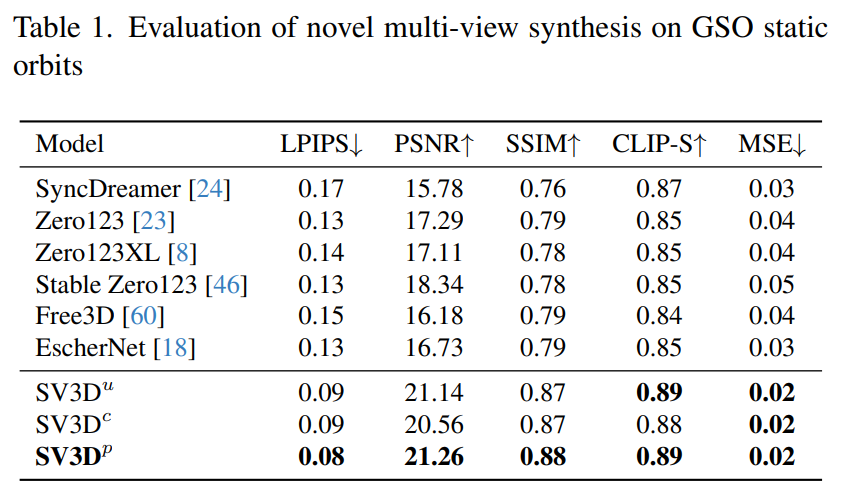
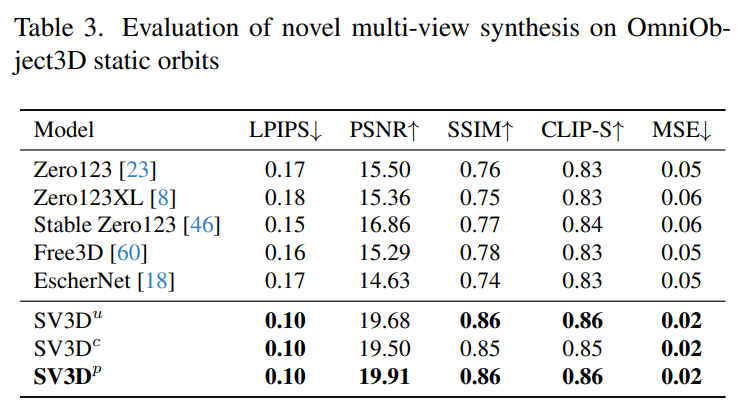
Le Tableau 2 et le Tableau 4 ci-dessous montrent les résultats de génération d'orbites dynamiques, y compris les modèles d'ajustement de pose SV3D_c et SV3D_p, ce dernier atteignant SOTA sur toutes les métriques.
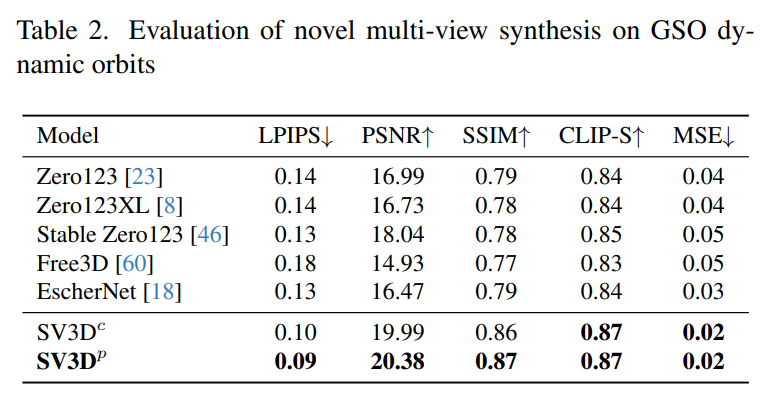
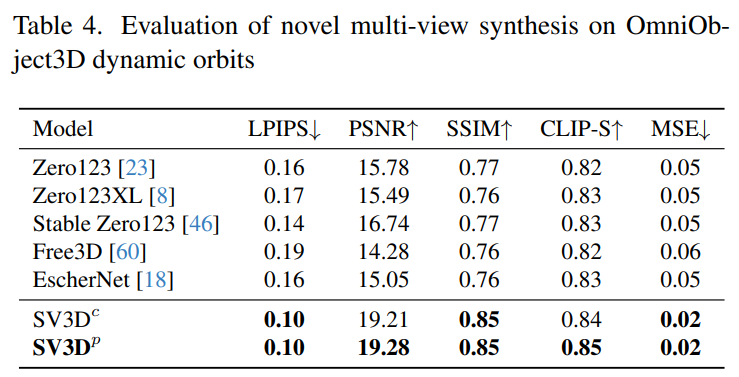
Les résultats de la comparaison visuelle dans la figure 6 ci-dessous démontrent en outre que par rapport aux travaux précédents, les images générées par Stable Video 3D sont plus détaillées, plus fidèles à l'image conditionnelle et plus cohérentes dans plusieurs perspectives. .

Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
Comment rédiger le dernier tutoriel sur la déclaration d'insertion SQL
Apr 09, 2025 pm 01:48 PM
L'instruction INSERT SQL est utilisée pour ajouter de nouvelles lignes à une table de base de données, et sa syntaxe est: Insérer dans Table_Name (Column1, Column2, ..., Columnn) VALEUR (VALEUR1, Value2, ..., Valuen);. Cette instruction prend en charge l'insertion de plusieurs valeurs et permet d'insérer des valeurs nulles dans des colonnes, mais il est nécessaire de s'assurer que les valeurs insérées sont compatibles avec le type de données de la colonne pour éviter de violer les contraintes d'unicité.
 Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Ajoutez de nouvelles colonnes à une table existante dans SQL en utilisant l'instruction ALTER TABLE. Les étapes spécifiques comprennent: la détermination des informations du nom de la table et de la colonne, rédaction des instructions de la table ALTER et exécution des instructions. Par exemple, ajoutez une colonne de messagerie à la table des clients (VARCHAR (50)): Alter Table Clients Ajouter un e-mail VARCHAR (50);
 Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
La syntaxe pour ajouter des colonnes dans SQL est alter table table_name Ajouter Column_name data_type [pas null] [default default_value]; Lorsque Table_Name est le nom de la table, Column_name est le nouveau nom de colonne, DATA_TYPE est le type de données, et non Null Spécifie si les valeurs NULL sont autorisées, et default default_value spécifie la valeur par défaut.
 Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Définissez la valeur par défaut des colonnes nouvellement ajoutées, utilisez l'instruction ALTER TABLE: Spécifiez des colonnes Ajouter et définissez la valeur par défaut: alter table table_name Ajouter Column_name data_type default_value; Utilisez la clause CONSTRAINT pour spécifier la valeur par défaut: ALTER TABLE TABLE_NAME ADD COLUMN COLUMN_NAME DATA_TYPE CONSTRAINT DEFAULT_CONSTRAINT DEFAULT_VALUE;
 Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Conseils pour améliorer les performances de compensation de la table SQL: utilisez une table tronquée au lieu de supprimer, libre d'espace et réinitialiser la colonne d'identité. Désactivez les contraintes de clés étrangères pour éviter la suppression en cascade. Utilisez les opérations d'encapsulation des transactions pour assurer la cohérence des données. Supprimer les mégadonnées et limiter le nombre de lignes via Limit. Reconstruisez l'indice après la compensation pour améliorer l'efficacité de la requête.
 SQL Classic 50 Question Answers
Apr 09, 2025 pm 01:33 PM
SQL Classic 50 Question Answers
Apr 09, 2025 pm 01:33 PM
SQL (Language de requête structuré) est un langage de programmation utilisé pour créer, gérer et interroger les bases de données. Les fonctions principales incluent: la création de bases de données et de tables, d'insertion, de mise à jour et de suppression de données, de tri et de filtrage des résultats, d'agrégation des fonctions, de jonction de tables, de sous-requêtes, d'opérateurs, de fonctions, de mots clés, de manipulation de données / de définition / langage de contrôle, de types de connexion, d'optimisation de requête, de sécurité, d'outils, de ressources, de versions, d'erreurs communes, de techniques de débogage, de meilleurs pratiques, de tristes et de pliées.
 Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Oui, l'instruction Delete peut être utilisée pour effacer une table SQL, les étapes sont les suivantes: Utilisez l'instruction Delete: Delete de Table_Name; Remplacez Table_Name par le nom de la table à effacer.
 Comment ajouter une colonne à une table SQL
Apr 09, 2025 pm 02:06 PM
Comment ajouter une colonne à une table SQL
Apr 09, 2025 pm 02:06 PM
L'ajout d'une colonne dans une table SQL nécessite les étapes suivantes: Ouvrez l'environnement SQL et sélectionnez la base de données. Sélectionnez le tableau que vous souhaitez modifier et utiliser la clause "Ajouter la colonne" pour ajouter une colonne qui inclut le nom de la colonne, le type de données et l'opportunité d'autoriser les valeurs nulles. Exécutez l'instruction "ALTER TABLE" pour terminer l'ajout.
