
 Périphériques technologiques
IA
Accélérant l'innovation GenAI d'entreprise de bout en bout, les microservices NVIDIA NIM sont devenus un point fort pour les éditeurs de logiciels !
Périphériques technologiques
IA
Accélérant l'innovation GenAI d'entreprise de bout en bout, les microservices NVIDIA NIM sont devenus un point fort pour les éditeurs de logiciels !
Accélérant l'innovation GenAI d'entreprise de bout en bout, les microservices NVIDIA NIM sont devenus un point fort pour les éditeurs de logiciels !


La société de développement de logiciels Cloudera a récemment annoncé un partenariat stratégique avec NVIDIA pour accélérer le déploiement d'applications d'IA générative. La collaboration impliquera l'intégration des microservices d'IA de NVIDIA dans la plateforme de données Cloudera (CDP) et est conçue pour aider les entreprises à créer et à mettre à l'échelle plus rapidement des modèles de langage étendus (LLM) personnalisés en fonction de leurs données. Cette initiative fournira aux entreprises des outils et des technologies plus puissants pour mieux utiliser leurs ressources de données et accélérer le processus de développement et de déploiement d'applications d'IA. Cette collaboration apportera davantage d'opportunités aux entreprises, les aidant à prendre des décisions plus efficaces basées sur les données et à stimuler le développement commercial. La coopération entre Cloudera et NVIDIA offrira aux entreprises plus de choix et de flexibilité, et devrait promouvoir l'application généralisée de la technologie de l'IA dans divers secteurs.
Dans cette collaboration, Cloudera prévoit d'exploiter pleinement la technologie NVIDIA AI Enterprise, y compris les microservices NVIDIA Inference Manager (NIM), pour découvrir des informations à partir de plus de 25 exaoctets de données dans les CDP. Ces précieuses informations d'entreprise seront importées dans la plateforme d'apprentissage automatique de Cloudera, un service de flux de travail d'IA de bout en bout fourni par l'entreprise, conçu pour piloter un nouveau cycle d'innovation en matière d'IA générative.
Priyank Patel, vice-président des produits IA/ML chez Cloudera, a noté que les données d'entreprise combinées à une plate-forme full-stack optimisée pour les grands modèles de langage sont essentielles pour faire passer les applications d'IA générative d'une organisation du stade pilote à la production. Cloudera intègre actuellement les microservices NVIDIA NIM et CUDA-X pour piloter sa plateforme d'apprentissage automatique et aider les clients à transformer le potentiel de l'IA en réalité commerciale.
Cette collaboration met en évidence la force de Cloudera et NVIDIA en matière d'innovation technologique et démontre également la demande croissante du marché pour les applications d'IA générative. En intégrant les ressources et les avantages techniques des deux parties, nous promouvrons conjointement l'application pratique de l'IA dans les entreprises et fournirons aux entreprises des solutions plus efficaces et plus intelligentes.
De plus, en exploitant les données massives de CDP et en les combinant avec les puissantes capacités de la plateforme d'apprentissage automatique Cloudera, les entreprises peuvent approfondir la valeur des données et prendre des décisions plus précises et des opérations commerciales plus efficaces. Cette coopération apportera un avenir plus intelligent et automatisé aux entreprises et favorisera le développement et le progrès de l'ensemble du secteur.
1. Connecter les modèles et les données
En connectant les modèles et les données, l'IA d'entreprise est confrontée à un défi clé : comment connecter le modèle sous-jacent aux données commerciales pertinentes pour générer une sortie précise et contextuelle. Les microservices NIM et NeMo Retriever de NVIDIA visent à combler cette lacune en permettant aux développeurs de connecter des LLM (Large Language Models) avec des données d'entreprise structurées et non structurées allant des documents texte aux images et visualisations.
Plus précisément, Cloudera Machine Learning fournira des capacités intégrées de service de modèles NIM pour améliorer les performances d'inférence et permettre la tolérance aux pannes, une faible latence et une mise à l'échelle automatique dans les environnements hybrides et multi-cloud. L'ajout de NeMo Retriever simplifiera le développement d'applications de génération augmentée de récupération (RAG), qui améliorent la précision de l'IA générative en récupérant des données pertinentes en temps réel.
Parmi eux, NVIDIA NeMo Retriever est un tout nouveau service de la série de frameworks et d'outils NVIDIA NeMo. NeMo est une famille de frameworks et d'outils permettant de créer, de personnaliser et de déployer des modèles d'IA génératifs. En tant que microservice de récupération sémantique, NeMo Retriever utilise des algorithmes optimisés par NVIDIA pour aider les applications d'IA générative à fournir des réponses plus précises. Les développeurs utilisant ce microservice peuvent connecter leurs applications d'IA aux données d'entreprise situées dans divers cloud et centres de données. Cette connexion améliore non seulement la précision des applications d'IA, mais permet également aux développeurs de traiter et d'utiliser les données de l'entreprise de manière plus flexible.
En résumé, les microservices tels que NIM et NeMo Retriever de NVIDIA offrent aux entreprises un moyen efficace d'intégrer étroitement les modèles d'IA aux données commerciales pour générer des résultats plus précis et plus utiles. Cela fournit aux entreprises des outils puissants pour promouvoir davantage l’application et le développement de l’IA dans divers domaines.
2. Des données au déploiement de l'IA générative, ce qui réduit considérablement les délais
La coopération entre NVIDIA et Cloudera ouvre une nouvelle porte aux entreprises, les amenant à utiliser plus efficacement les données massives pour créer des assistants collaboratifs personnalisés et améliorer la productivité. outils. Justin Boitano, vice-président des produits d'entreprise chez NVIDIA, a déclaré : « L'intégration des microservices NVIDIA NIM avec la plate-forme de données Cloudera offre aux développeurs un moyen plus flexible et plus simple de déployer de grands modèles de langage, favorisant ainsi la transformation des activités de l'entreprise. »
En simplifiant le passage des données au déploiement de l'IA générative, Cloudera et NVIDIA visent à accélérer l'adoption par les entreprises d'applications transformatrices telles que les assistants de codage, les chatbots, les outils de synthèse de documents et les outils de recherche sémantique. Cette collaboration s'appuie sur les efforts antérieurs des deux sociétés pour tirer parti de l'accélération GPU en intégrant NVIDIA RAPIDS dans CDP.
Patel a souligné les avantages commerciaux de la collaboration élargie, déclarant : « En plus de fournir aux clients de puissantes capacités et performances d'IA générative, les résultats de cette intégration permettront aux entreprises de prendre des décisions plus précises et plus rapides tout en permettant aux entreprises de prendre des décisions plus précises et plus rapides. réduire les inexactitudes, les illusions et les erreurs dans les prévisions : ce sont des facteurs essentiels pour naviguer dans l'environnement de données actuel.
Cloudera se tiendra à San Jose, en Californie, du 18 au 21 mars. NVIDIA GTC présentera ses nouvelles capacités d'IA générative. Alors que les grandes entreprises explorent le potentiel des modèles fondamentaux pour transformer leurs opérations, Cloudera et NVIDIA estiment que leur collaboration positionnera les clients à l'avant-garde de l'ère émergente de l'IA d'entreprise.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 « AI Factory » favorisera la refonte de l'ensemble de la pile logicielle, et NVIDIA fournit des conteneurs Llama3 NIM que les utilisateurs peuvent déployer
Jun 08, 2024 pm 07:25 PM
« AI Factory » favorisera la refonte de l'ensemble de la pile logicielle, et NVIDIA fournit des conteneurs Llama3 NIM que les utilisateurs peuvent déployer
Jun 08, 2024 pm 07:25 PM
Selon les informations de ce site le 2 juin, lors du discours d'ouverture du Huang Renxun 2024 Taipei Computex, Huang Renxun a présenté que l'intelligence artificielle générative favoriserait la refonte de l'ensemble de la pile logicielle et a démontré ses microservices cloud natifs NIM (Nvidia Inference Microservices). . Nvidia estime que « l'usine IA » déclenchera une nouvelle révolution industrielle : en prenant comme exemple l'industrie du logiciel lancée par Microsoft, Huang Renxun estime que l'intelligence artificielle générative favorisera sa refonte complète. Pour faciliter le déploiement de services d'IA par les entreprises de toutes tailles, NVIDIA a lancé les microservices cloud natifs NIM (Nvidia Inference Microservices) en mars de cette année. NIM+ est une suite de microservices cloud natifs optimisés pour réduire les délais de commercialisation
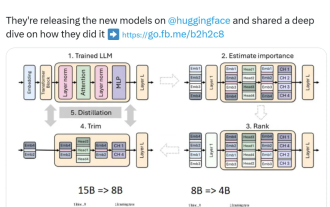 Nvidia joue avec l'élagage et la distillation : réduisant de moitié les paramètres de Llama 3.1 8B pour obtenir de meilleures performances avec la même taille
Aug 16, 2024 pm 04:42 PM
Nvidia joue avec l'élagage et la distillation : réduisant de moitié les paramètres de Llama 3.1 8B pour obtenir de meilleures performances avec la même taille
Aug 16, 2024 pm 04:42 PM
L’essor des petits modèles. Le mois dernier, Meta a publié la série de modèles Llama3.1, qui comprend le plus grand modèle Meta à ce jour, le modèle 405B, et deux modèles plus petits avec respectivement 70 milliards et 8 milliards de paramètres. Llama3.1 est considéré comme inaugurant une nouvelle ère de l'open source. Cependant, bien que les modèles de nouvelle génération soient puissants en termes de performances, ils nécessitent néanmoins une grande quantité de ressources informatiques lors de leur déploiement. Par conséquent, une autre tendance est apparue dans l’industrie, qui consiste à développer des petits modèles de langage (SLM) qui fonctionnent suffisamment bien dans de nombreuses tâches linguistiques et sont également très peu coûteux à déployer. Récemment, des recherches de NVIDIA ont montré qu'un élagage structuré combiné à une distillation des connaissances permet d'obtenir progressivement des modèles de langage plus petits à partir d'un modèle initialement plus grand. Lauréat du prix Turing, Meta Chief A
 Conforme à la spécification NVIDIA SFF-Ready, ASUS lance les cartes graphiques Prime GeForce RTX série 40
Jun 15, 2024 pm 04:38 PM
Conforme à la spécification NVIDIA SFF-Ready, ASUS lance les cartes graphiques Prime GeForce RTX série 40
Jun 15, 2024 pm 04:38 PM
Selon les informations de ce site du 15 juin, Asus a récemment lancé la carte graphique GeForce RTX40 "Ada" de la série Prime. Sa taille est conforme à la dernière spécification SFF-Ready de Nvidia, qui exige que la taille de la carte graphique ne dépasse pas 304. mm x 151 mm x 50 mm (longueur x hauteur x épaisseur). La série Prime GeForceRTX40 lancée par ASUS comprend cette fois RTX4060Ti, RTX4070 et RTX4070SUPER, mais elle n'inclut actuellement pas RTX4070TiSUPER ou RTX4080SUPER. Cette série de cartes graphiques RTX40 adopte une conception de circuit imprimé commune avec des dimensions de 269 mm x 120 mm x 50 mm. Les principales différences entre les trois cartes graphiques sont.
 Nvidia lance la version mémoire GDDR6 de la carte graphique GeForce RTX 4070, disponible à partir de septembre
Aug 21, 2024 am 07:31 AM
Nvidia lance la version mémoire GDDR6 de la carte graphique GeForce RTX 4070, disponible à partir de septembre
Aug 21, 2024 am 07:31 AM
Selon les informations de ce site du 20 août, plusieurs sources ont rapporté en juillet que les cartes graphiques Nvidia RTX4070 et supérieures seraient en pénurie en août en raison du manque de mémoire vidéo GDDR6X. Par la suite, des spéculations se sont répandues sur Internet concernant le lancement d'une version mémoire GDDR6 de la carte graphique RTX4070. Comme indiqué précédemment par ce site, Nvidia a publié aujourd'hui le pilote GameReady pour "Black Myth : Wukong" et "Star Wars : Outlaws". Parallèlement, le communiqué de presse mentionnait également la sortie de la version mémoire vidéo GDDR6 de la GeForce RTX4070. Nvidia a déclaré que les spécifications du nouveau RTX4070 autres que la mémoire vidéo resteront inchangées (bien sûr, il continuera également à maintenir le prix de 4 799 yuans), offrant des performances similaires à la version originale dans les jeux et les applications, et que des produits associés seront lancés. depuis
 Frameworks et microservices PHP : déploiement et conteneurisation cloud natifs
Jun 04, 2024 pm 12:48 PM
Frameworks et microservices PHP : déploiement et conteneurisation cloud natifs
Jun 04, 2024 pm 12:48 PM
Avantages de la combinaison du framework PHP avec des microservices : Évolutivité : étendez facilement l'application, ajoutez de nouvelles fonctionnalités ou gérez plus de charge. Flexibilité : les microservices sont déployés et maintenus de manière indépendante, ce qui facilite les modifications et les mises à jour. Haute disponibilité : la défaillance d'un microservice n'affecte pas les autres parties, garantissant une disponibilité plus élevée. Cas pratique : Déployer des microservices à l'aide de Laravel et Kubernetes Étapes : Créer un projet Laravel. Définissez le contrôleur de microservice. Créez un fichier Docker. Créez un manifeste Kubernetes. Déployez des microservices. Testez les microservices.
 NVIDIA lance la spécification de châssis de petite taille SFF-Ready : 15 fabricants de cartes graphiques et de châssis participent pour garantir la compatibilité des cartes graphiques et des châssis
Jun 07, 2024 am 11:51 AM
NVIDIA lance la spécification de châssis de petite taille SFF-Ready : 15 fabricants de cartes graphiques et de châssis participent pour garantir la compatibilité des cartes graphiques et des châssis
Jun 07, 2024 am 11:51 AM
Selon les informations de ce site du 2 juin, Nvidia a coopéré avec les fabricants de cartes graphiques et de châssis pour introduire officiellement la spécification SFF-Ready pour les cartes graphiques et châssis de jeu GeForce RTX, simplifiant ainsi le processus de sélection des accessoires pour les châssis de petite taille. Selon les rapports, 15 fabricants de cartes graphiques et de châssis participent actuellement au projet SFF-Ready, dont ASUS, Cooler Master et Parting Technology. Les cartes graphiques de jeu GeForce SFF-Ready sont destinées aux modèles RTX4070 et supérieurs. Les exigences de taille sont les suivantes : Hauteur maximale : 151 mm, y compris le rayon de courbure du cordon d'alimentation Longueur maximale : 304 mm Épaisseur maximale : 50 mm ou 2,5 emplacements. 36 cartes graphiques GeForce RTX40 sont conformes aux spécifications, d'autres cartes graphiques seront disponibles à l'avenir
 Le modèle universel open source le plus puissant de NVIDIA, Nemotron-4 340B
Jun 16, 2024 pm 10:32 PM
Le modèle universel open source le plus puissant de NVIDIA, Nemotron-4 340B
Jun 16, 2024 pm 10:32 PM
Les performances dépassent Llama-3 et sont principalement utilisées pour les données synthétiques. Nemotron, le grand modèle à usage général de NVIDIA, a ouvert la dernière version de 340 milliards de paramètres. Vendredi, NVIDIA a annoncé le lancement du Nemotron-4340B. Il contient une série de modèles ouverts que les développeurs peuvent utiliser pour générer des données synthétiques afin de former des modèles de langage étendus (LLM), qui peuvent être utilisés pour des applications commerciales dans tous les secteurs tels que la santé, la finance, la fabrication et la vente au détail. Des données de formation de haute qualité jouent un rôle essentiel dans la réactivité, la précision et la qualité des LLM personnalisés, mais les ensembles de données robustes sont souvent coûteux et inaccessibles. Grâce à une licence de modèle ouvert unique, Nemotron-4340B offre aux développeurs
