


CLIP signifie Contrastive Language-Image Pre-training, qui est une méthode ou un modèle de pré-entraînement basé sur des paires texte-image contrastées. Il s'agit d'un modèle multimodal qui repose sur l'apprentissage contrastif. paires d'images, où une image est associée à sa description textuelle correspondante. Grâce à l'apprentissage contrastif, le modèle vise à comprendre la relation entre les paires de texte et d'images

Open AI a publié DALL-E et CLIP, les deux modèles sont multi. -modèles modaux capables de combiner des images et du texte. DALL-E est un modèle qui génère des images basées sur du texte, tandis que CLIP utilise le texte comme signal de supervision pour former un modèle visuel transférable.
Dans le modèle de diffusion stable, les caractéristiques de texte extraites par l'encodeur de texte CLIP sont intégrées dans l'UNet du modèle de diffusion grâce à une attention croisée. Plus précisément, les fonctionnalités de texte sont utilisées comme clé et valeur d'attention, tandis que les fonctionnalités UNet sont utilisées comme requête. En d’autres termes, CLIP est en fait un pont clé entre le texte et les images, combinant de manière organique les informations textuelles et les informations image. Cette combinaison permet au modèle de mieux comprendre et traiter les informations entre différentes modalités, obtenant ainsi de meilleurs résultats lors du traitement de tâches complexes. De cette manière, le modèle de diffusion stable peut utiliser plus efficacement les capacités de codage de texte de CLIP, améliorant ainsi les performances globales et élargissant les domaines d'application.
CLIP
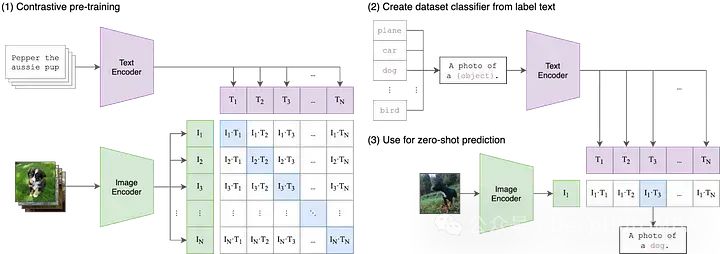
Il s'agit du premier article publié par OpenAI en 2021. Pour comprendre CLIP, nous devons déconstruire l'acronyme en trois composants : (1) Contraste, (2) Langage -Image, ( 3) Pré-formation.
Commençons par Langage-Image.
Dans les modèles d'apprentissage automatique traditionnels, une seule modalité de données d'entrée peut généralement être acceptée, comme du texte, des images, des données tabulaires ou de l'audio. Si vous devez utiliser des données provenant de différentes modalités pour effectuer des prédictions, vous devez entraîner plusieurs modèles différents. Dans CLIP, « Langue-Image » signifie que le modèle peut accepter à la fois des données d'entrée de texte (langue) et d'image. Cette conception permet à CLIP de traiter les informations de différentes modalités de manière plus flexible, améliorant ainsi ses capacités prédictives et sa portée d'application.
CLIP gère la saisie de texte et d'image en utilisant deux encodeurs différents, à savoir l'encodeur de texte et l'encodeur d'image. Ces deux encodeurs mappent les données d'entrée dans un espace latent de dimension inférieure, générant des vecteurs d'intégration correspondants pour chaque entrée. Un détail important est que les encodeurs de texte et d'image intègrent les données dans le même espace, c'est-à-dire que l'espace CLIP d'origine est un espace vectoriel à 512 dimensions. Cette conception permet une comparaison et une correspondance directes entre le texte et les images sans conversion ni traitement supplémentaire. De cette manière, CLIP peut représenter des descriptions de texte et le contenu d'images dans le même espace vectoriel, permettant ainsi des fonctions d'alignement sémantique et de récupération multimodales. La conception de cet espace d'intégration partagé confère à CLIP de meilleures capacités de généralisation et d'adaptabilité, lui permettant de bien fonctionner sur une variété de tâches et d'ensembles de données.
Contrastive
Bien que l'intégration de données de texte et d'image dans le même espace vectoriel puisse être un point de départ utile, le simple fait de cela ne garantit pas que le modèle puisse comparer efficacement la représentation du texte et des images. Par exemple, il est important d’établir une relation raisonnable et interprétable entre l’intégration de « chien » ou « une image de chien » dans un texte et l’intégration d’une image de chien. Il nous faut cependant trouver un moyen de combler le fossé entre ces deux modèles.
Dans l'apprentissage automatique multimodal, il existe différentes techniques pour aligner deux modalités, mais actuellement la méthode la plus populaire est le contraste. Les techniques contrastives prennent des paires d'entrées de deux modalités : disons une image et sa légende et entraînent les deux encodeurs du modèle pour représenter ces paires de données d'entrée aussi fidèlement que possible. Dans le même temps, le modèle est incité à prendre des entrées non appariées (telles que des images de chiens et le texte « photos de voitures ») et à les représenter aussi loin que possible. CLIP n'est pas la première technique d'apprentissage contrastif d'images et de texte, mais sa simplicité et son efficacité en ont fait un pilier des applications multimodales.
Pré-formation
Bien que CLIP lui-même soit utile pour des applications telles que la classification sans tir, la recherche sémantique et l'exploration de données non supervisée, CLIP est également utilisé comme élément de base pour un grand nombre de multi- applications modales, de la diffusion stable et DALL-E à StyleCLIP et OWL-ViT. Pour la plupart de ces applications en aval, le modèle CLIP initial est considéré comme le point de départ de la « pré-formation » et l'ensemble du modèle est affiné pour son nouveau cas d'utilisation.
Bien qu'OpenAI n'ait jamais explicitement spécifié ni partagé les données utilisées pour entraîner le modèle CLIP d'origine, l'article CLIP mentionne que le modèle a été formé sur 400 millions de paires image-texte collectées sur Internet.
https://www.php.cn/link/7c1bbdaebec5e20e91db1fe61221228f
ALIGN : améliorer l'apprentissage de la représentation visuelle et visuelle avec une supervision de texte bruyante

Grâce à CLIP, OpenAI utilise 4 milliards des paires image-texte Aucun détail n’étant fourni, il est impossible de savoir exactement comment l’ensemble de données a été construit. Mais pour décrire le nouvel ensemble de données, ils se sont inspirés des légendes conceptuelles de Google - un ensemble de données relativement petit (3,3 millions de paires image-légende) qui utilise des techniques de filtrage et de post-traitement coûteuses, bien que la technologie soit puissante, mais pas particulièrement évolutive) .
Les ensembles de données de haute qualité sont donc devenus la direction de la recherche. Peu de temps après CLIP, ALIGN a résolu ce problème grâce au filtrage à grande échelle. ALIGN ne s'appuie pas sur de petits ensembles de données de sous-titres d'images soigneusement annotés et organisés, mais exploite plutôt 1,8 milliard de paires d'images et de texte alternatif.
Bien que ces descriptions de texte alternatif soient en moyenne beaucoup plus bruyantes que les titres, la taille même de l'ensemble de données compense largement cela. Les auteurs ont utilisé un filtrage de base pour supprimer les doublons, les images contenant plus de 1 000 textes alternatifs pertinents, ainsi que les textes alternatifs non informatifs (soit trop courants, soit contenant des balises rares). Avec ces étapes simples, ALIGN atteint ou dépasse l'état de l'art sur diverses tâches de mise à zéro et de réglage fin.
https://arxiv.org/abs/2102.05918
K-LITE : apprentissage de modèles visuels transférables avec des connaissances externes

Comme ALIGN, K-LITE résout également la pré-formation comparative des des paires image-texte de haute qualité pour un nombre limité de problèmes.
K-LITE se concentre sur l'explication des concepts, c'est-à-dire des définitions ou des descriptions en tant que contexte et des concepts inconnus peuvent aider à développer une compréhension globale. Une explication populaire est que lorsque les gens introduisent pour la première fois des termes techniques et un vocabulaire inhabituel, ils les définissent généralement simplement ou utilisent une analogie avec quelque chose que tout le monde connaît !
Pour mettre en œuvre cette approche, des chercheurs de Microsoft et de l'UC Berkeley ont utilisé WordNet et Wiktionary pour améliorer le texte dans des paires image-texte. Pour certains concepts isolés, tels que les étiquettes de classe dans ImageNet, les concepts eux-mêmes sont améliorés, tandis que pour les titres (par exemple de GCC), les expressions nominales les moins courantes sont améliorées. Grâce à ces connaissances structurées supplémentaires, les modèles pré-entraînés montrent des améliorations substantielles sur les tâches d'apprentissage par transfert.
https://arxiv.org/abs/2204.09222
OpenCLIP : lois d'échelle reproductibles pour l'apprentissage contrastif langage-image
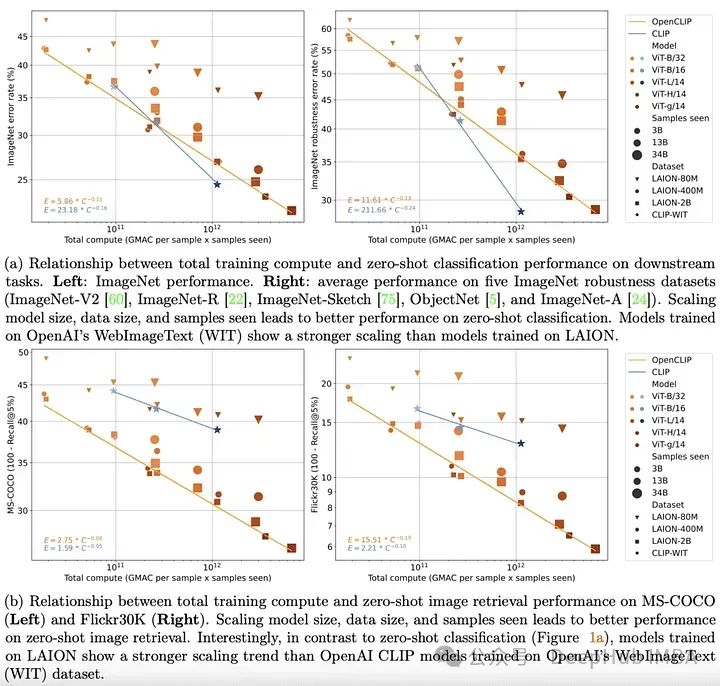
D'ici fin 2022, des modèles de transformateur ont été établis dans le texte et domaines visuels. Des travaux empiriques pionniers dans les deux domaines ont également clairement montré que les performances des modèles de transformateur sur des tâches unimodales peuvent être bien décrites par de simples lois d'échelle. Cela signifie qu'à mesure que la quantité de données d'entraînement, le temps d'entraînement ou la taille du modèle augmentent, on peut prédire les performances du modèle avec assez de précision.
OpenCLIP étudie systématiquement les performances des modèles de paires de données d'entraînement dans les tâches de mise à zéro et de réglage fin en étendant la théorie ci-dessus à des scénarios multimodaux en utilisant le plus grand ensemble de données de paires image-texte open source publié à ce jour (5B) Impact . Comme dans le cas unimodal, cette étude révèle que les performances du modèle sur les tâches multimodales évoluent selon une loi de puissance en termes de calcul, de nombre d'échantillons observés et de nombre de paramètres du modèle.
Encore plus intéressante que l'existence de lois de puissance est la relation entre la mise à l'échelle des lois de puissance et les données de pré-entraînement. En conservant l'architecture et la méthode de formation du modèle CLIP d'OpenAI, le modèle OpenCLIP présente des capacités de mise à l'échelle plus fortes sur les tâches de récupération d'images d'échantillons. Pour la classification d'images sans prise de vue sur ImageNet, le modèle d'OpenAI (entraîné sur son ensemble de données propriétaire) a montré des capacités de mise à l'échelle plus fortes. Ces résultats soulignent l’importance des procédures de collecte et de filtrage des données sur les performances en aval.
https://arxiv.org/abs/2212.07143Cependant, peu de temps après la publication d'OpenCLIP, l'ensemble de données LAION a été supprimé d'Internet car il contenait des images illégales.
MetaCLIP : Démystifier les données CLIP
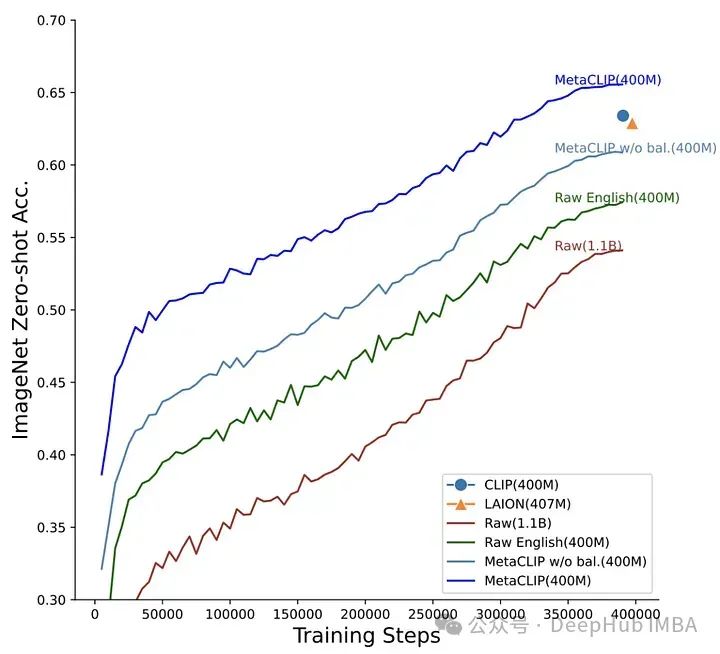
OpenCLIP tente de comprendre comment les performances des tâches en aval changent en fonction de la quantité de données, de l'effort de calcul et du nombre de paramètres du modèle, tandis que MetaCLIP se concentre sur la façon de sélectionner les données. Comme le disent les auteurs : « Nous pensons que le principal facteur de succès de CLIP réside dans ses données, plutôt que dans l'architecture du modèle ou les objectifs de pré-formation.
Pour vérifier cette hypothèse, les auteurs ont corrigé l'architecture du modèle et les étapes de formation. » mené des expériences. L'équipe MetaCLIP a testé diverses stratégies liées à la correspondance des sous-chaînes, au filtrage et à l'équilibrage de la distribution des données, et a constaté que les meilleures performances étaient obtenues lorsque chaque texte apparaissait au maximum 20 000 fois dans l'ensemble de données d'entraînement. Pour tester cette théorie, ils ont testé cette théorie. même Le mot « photo », apparu 54 millions de fois dans le pool de données initial, était également limité à 20 000 paires image-texte dans les données d'entraînement. Grâce à cette stratégie, MetaCLIP a été formé sur 400 millions de paires image-texte de l'ensemble de données Common Crawl, surpassant ainsi le modèle CLIP d'OpenAI sur divers benchmarks.
https://arxiv.org/abs/2309.16671
DFN : Data Filtering Networks
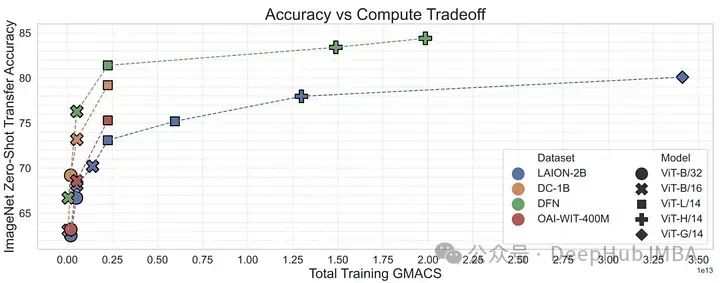
Avec la recherche sur MetaCLIP, il peut être démontré que la gestion des données peut être un outil important pour la formation de haut niveau. -des modèles multimodaux performants (tels que CLIP). La stratégie de filtrage de MetaCLIP est très réussie, mais elle repose aussi principalement sur des méthodes heuristiques. Les chercheurs se sont ensuite demandé si un modèle pouvait être formé pour effectuer ce filtrage plus efficacement.
Pour vérifier cela, l'auteur utilise des données de haute qualité du conceptuel 12M pour entraîner le modèle CLIP afin de filtrer les données de haute qualité à partir des données de faible qualité. Ce réseau de filtrage de données (DFN) est utilisé pour créer un ensemble de données plus vaste et de haute qualité en sélectionnant uniquement des données de haute qualité à partir d'un ensemble de données non organisé (dans ce cas, Common Crawl). Les modèles CLIP formés sur des données filtrées ont surpassé les modèles formés uniquement sur des données initiales de haute qualité et les modèles formés sur de grandes quantités de données non filtrées.
https://arxiv.org/abs/2309.17425
Summary
Le modèle CLIP d'OpenAI change considérablement la façon dont nous traitons les données multimodales. Mais CLIP n’est qu’un début. Des données de pré-entraînement aux détails des méthodes d'entraînement et aux fonctions de perte contrastées, la famille CLIP a réalisé des progrès incroyables au cours des dernières années. ALIGN met à l'échelle le texte bruité, K-LITE améliore les connaissances externes, OpenCLIP étudie les lois de mise à l'échelle, MetaCLIP optimise la gestion des données et DFN améliore la qualité des données. Ces modèles approfondissent notre compréhension du rôle de CLIP dans le développement de l’intelligence artificielle multimodale, démontrant les progrès dans la connexion des images et du texte.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
