
 Périphériques technologiques
IA
Estimation de la profondeur SOTA ! Fusion adaptative de la profondeur monoculaire et surround pour la conduite autonome
Périphériques technologiques
IA
Estimation de la profondeur SOTA ! Fusion adaptative de la profondeur monoculaire et surround pour la conduite autonome
Estimation de la profondeur SOTA ! Fusion adaptative de la profondeur monoculaire et surround pour la conduite autonome

Écrit avant et compréhension personnelle
L'estimation de la profondeur multi-vues a atteint des performances élevées dans divers tests de référence. Cependant, presque tous les systèmes multi-vues actuels reposent sur une pose de caméra idéale donnée, qui n'est pas disponible dans de nombreux scénarios du monde réel, comme la conduite autonome. Ce travail propose un nouveau test de robustesse pour évaluer les systèmes d'estimation de profondeur dans divers paramètres de pose bruyante. Étonnamment, il s’avère que les méthodes actuelles d’estimation de la profondeur à vues multiples ou les méthodes de fusion à vues uniques et multi-vues échouent lorsque des paramètres de pose bruyants sont donnés. Pour relever ce défi, nous proposons ici AFNet, un système d'estimation de profondeur fusionnée à vue unique et multi-vue qui intègre de manière adaptative des résultats multi-vues et à vue unique de haute confiance pour obtenir une estimation de profondeur robuste et précise. Le module de fusion adaptative effectue une fusion en sélectionnant dynamiquement des régions à confiance élevée entre les deux branches sur la base de la carte de confiance des parcelles. Par conséquent, face à des scènes sans texture, à un calibrage imprécis, à des objets dynamiques et à d’autres conditions dégradées ou difficiles, le système a tendance à choisir la branche la plus fiable. Lors des tests de robustesse, la méthode surpasse les méthodes multi-vues et de fusion de pointe. De plus, des performances de pointe sont obtenues sur des tests de référence exigeants (KITTI et DDAD).
Lien du papier : https://arxiv.org/pdf/2403.07535.pdf
Nom du papier : Fusion adaptative de la profondeur à vue unique et multi-vue pour la conduite autonome
Arrière-plan de champ
L'estimation de la profondeur de l'image a toujours été un défi dans le domaine de la vision par ordinateur avec une large gamme d'applications. Pour les systèmes de conduite autonome basés sur la vision, la perception de la profondeur est essentielle, car elle permet de comprendre les objets sur la route et de créer des cartes 3D de l'environnement. Avec l'application des réseaux de neurones profonds à divers problèmes visuels, les méthodes basées sur les réseaux de neurones convolutifs (CNN) sont devenues la norme dans les tâches d'estimation de la profondeur.
Selon le format d'entrée, il est principalement divisé en estimation de profondeur multi-vues et estimation de profondeur en vue unique. L'hypothèse derrière les méthodes multi-vues pour estimer la profondeur est que, étant donné la profondeur correcte, le calibrage de la caméra et la pose de la caméra, les pixels des vues devraient être similaires. Ils s’appuient sur la géométrie épipolaire pour trianguler des mesures de profondeur de haute qualité. Cependant, la précision et la robustesse des méthodes multi-vues dépendent fortement de la configuration géométrique de la caméra et de la correspondance correspondante entre les vues. Premièrement, la caméra doit effectuer une translation suffisante pour permettre la triangulation. Dans un scénario de conduite autonome, le véhicule autonome peut s'arrêter à un feu de circulation ou tourner sans avancer, ce qui peut entraîner l'échec de la triangulation. De plus, les méthodes multi-vues souffrent des problèmes de cibles dynamiques et de zones sans texture, qui prédominent dans les scénarios de conduite autonome. Un autre problème est l’optimisation de l’attitude SLAM sur les véhicules en mouvement. Dans les méthodes SLAM existantes, le bruit est inévitable, sans parler des situations difficiles et inévitables. Par exemple, un robot ou une voiture autonome peut être déployé pendant des années sans recalibrage, ce qui entraîne des poses bruyantes. En revanche, étant donné que les méthodes à vue unique reposent sur la compréhension sémantique de la scène et des signaux de projection en perspective, elles sont plus robustes aux régions sans texture et aux objets dynamiques et ne reposent pas sur la pose de la caméra. Cependant, en raison de l’ambiguïté de l’échelle, ses performances sont encore loin derrière les méthodes multi-vues. Ici, nous avons tendance à examiner si les avantages de ces deux méthodes peuvent être bien combinés pour une estimation robuste et précise de la profondeur de la vidéo monoculaire dans des scénarios de conduite autonome.
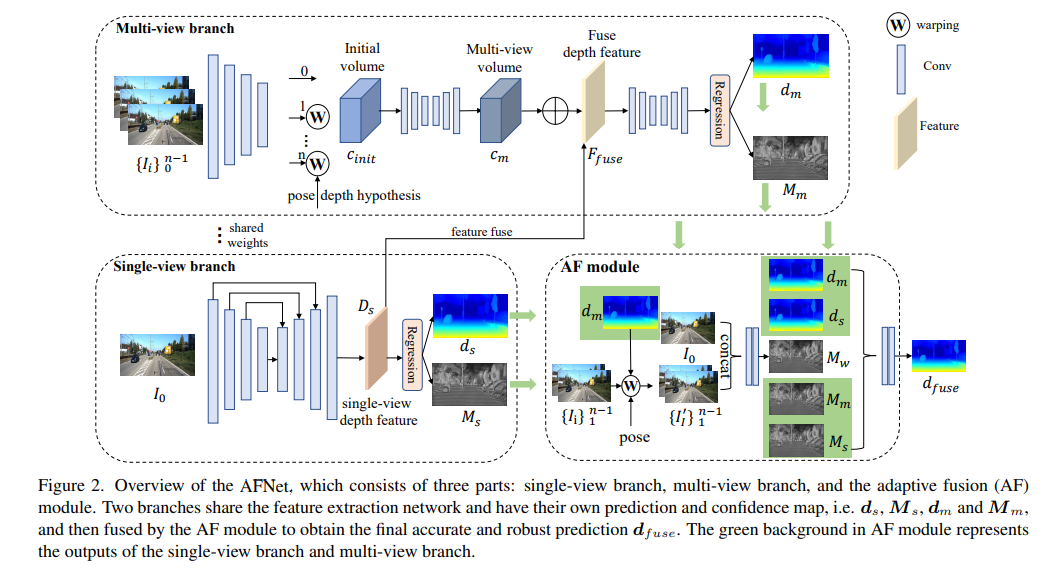
Structure du réseau AFNet
La structure AFNet est présentée ci-dessous. Elle se compose de trois parties : une branche à vue unique, une branche à vues multiples et un module de fusion adaptative (AF). Les deux branches partagent le réseau d'extraction de caractéristiques et ont leurs propres cartes de prédiction et de confiance, c'est-à-dire , , et , et sont ensuite fusionnées par le module AF pour obtenir la prédiction finale précise et robuste. Le fond vert dans le module AF représente l'unique. -branche vue et La sortie de la branche multi-vue.
Fonction de perte :

Modules de profondeur mono-vue et multi-vues
Afin de fusionner les fonctionnalités du backbone et d'obtenir les fonctionnalités profondes Ds, AFNet construit un décodeur multi-échelle. Dans ce processus, une opération softmax est effectuée sur les 256 premiers canaux de Ds pour obtenir le volume de probabilité de profondeur Ps. Le dernier canal de la fonction de profondeur est utilisé comme carte de confiance de profondeur à vue unique Ms. Enfin, la profondeur d'une vue unique est calculée grâce à une pondération douce.
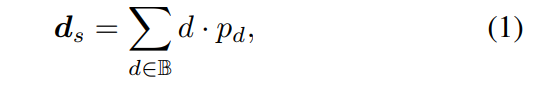
Branche multi-vues
La branche multi-vue partage l'épine dorsale avec la branche à vue unique pour extraire les caractéristiques de l'image de référence et de l'image source. Nous adoptons la déconvolution pour déconvoluer les caractéristiques basse résolution en quart de résolution et les combinons avec les caractéristiques quart initiales utilisées pour construire le volume de coût. Un volume de caractéristiques est formé en enveloppant les caractéristiques sources dans un plan hypothétique suivi par la caméra de référence. Pour une correspondance robuste qui ne nécessite pas trop d'informations, la dimension de canal de la fonctionnalité est conservée dans le calcul et un volume de coût 4D est construit, puis le nombre de canaux est réduit à 1 via deux couches convolutives 3D.
La méthode d'échantillonnage de l'hypothèse de profondeur est cohérente avec la branche à vue unique, mais le nombre d'échantillons n'est que de 128, puis régularisé à l'aide d'un réseau de sabliers 2D empilé pour obtenir le volume final de coût multi-vue. Afin de compléter les riches informations sémantiques des fonctionnalités à vue unique et les détails perdus en raison de la régularisation des coûts, une structure résiduelle est utilisée pour combiner les fonctionnalités de profondeur à vue unique Ds et le volume de coût pour obtenir des fonctionnalités de profondeur fusionnées comme suit :
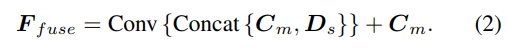
Module de fusion adaptatif
Afin d'obtenir la prédiction finale précise et robuste, le module AF est conçu pour sélectionner de manière adaptative la profondeur la plus précise entre les deux branches comme sortie finale, comme le montre la figure 2. La cartographie de fusion est réalisée à travers trois confiances, dont deux sont les cartes de confiance Ms et Mm générées respectivement par les deux branches. La plus critique est la carte de confiance Mw générée par Forward Wrap pour déterminer si la prédiction de la branche multi-vues est correcte. fiable. .
Résultats expérimentaux
DDAD (Dense Depth for Autonomous Driving) est une nouvelle référence de conduite autonome pour l'estimation de la profondeur dense dans des conditions urbaines difficiles et diverses. Il est capturé par 6 caméras synchronisées et contient une profondeur de sol précise (champ de vision complet de 360 degrés) générée par un lidar haute densité. Il contient 12 650 échantillons d’apprentissage et 3 950 échantillons de validation dans une seule vue de caméra avec une résolution de 1 936 × 1 216. Toutes les données de 6 caméras sont utilisées pour la formation et les tests. L'ensemble de données KITTI fournit des images stéréoscopiques de scènes extérieures tournées sur des véhicules en mouvement et des scans laser 3D correspondants, avec une résolution d'environ 1241 × 376.
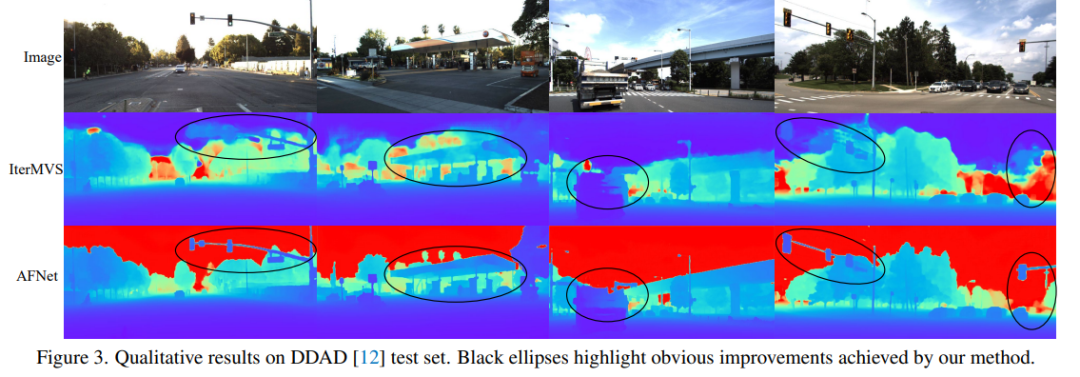
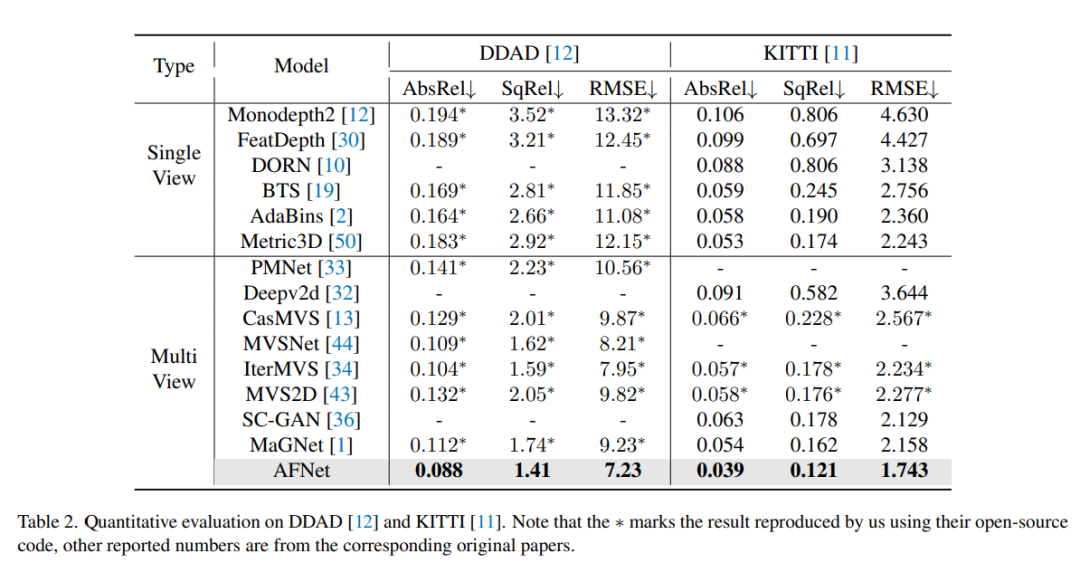
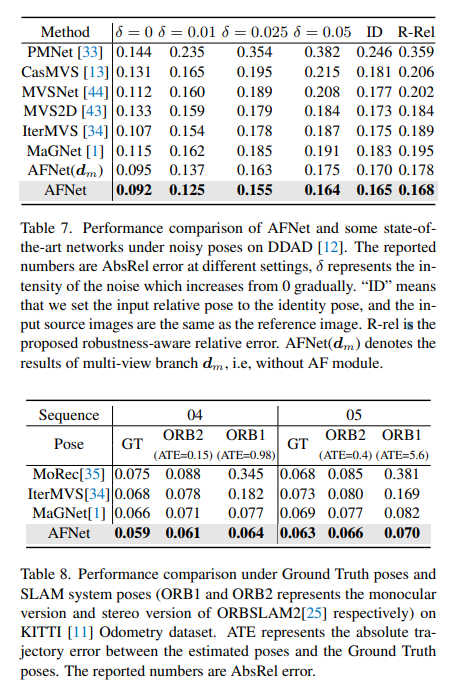
Comparaison des résultats d'évaluation sur DDAD et KITTI. Notez que * marque les résultats répliqués à l'aide de leur code open source, les autres chiffres rapportés proviennent des articles originaux correspondants.
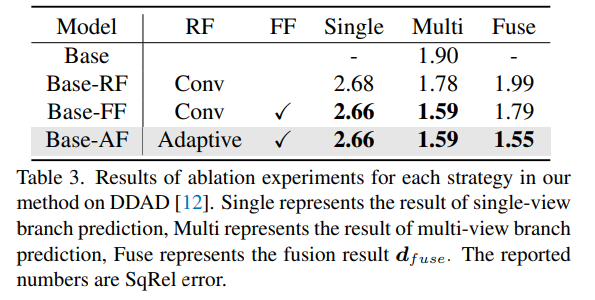
Résultats expérimentaux d'ablation pour chaque stratégie de la méthode sur DDAD. Single représente le résultat de la prédiction de branchement à vue unique, Multi- représente le résultat de la prédiction de branchement à vues multiples et Fuse représente le résultat de la fusion dfuse.
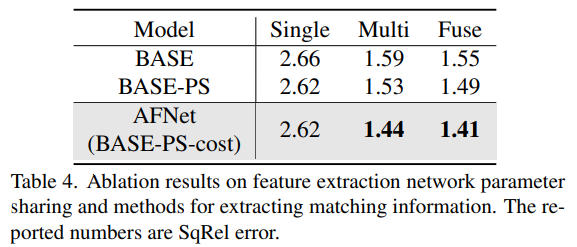
Une méthode pour partager les paramètres du réseau et extraire les informations correspondantes pour l'extraction des caractéristiques des résultats d'ablation.
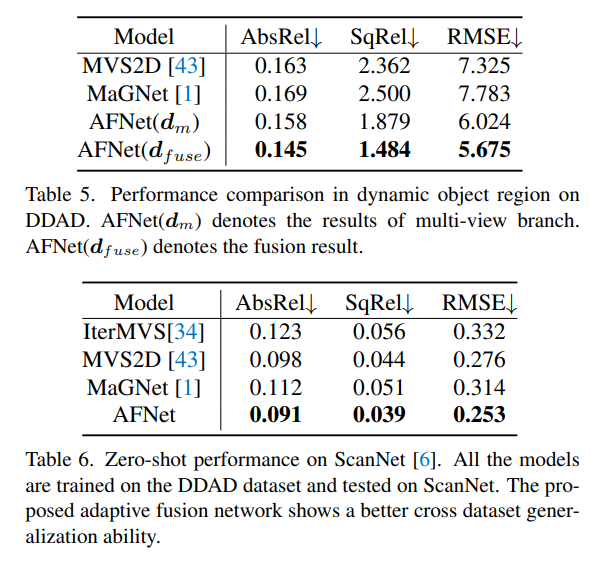

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle universelle de CUDA : de l'entrée à la maîtrise !
Mar 25, 2024 pm 12:30 PM
La multiplication matricielle générale (GEMM) est un élément essentiel de nombreuses applications et algorithmes, et constitue également l'un des indicateurs importants pour évaluer les performances du matériel informatique. Une recherche approfondie et l'optimisation de la mise en œuvre de GEMM peuvent nous aider à mieux comprendre le calcul haute performance et la relation entre les systèmes logiciels et matériels. En informatique, une optimisation efficace de GEMM peut augmenter la vitesse de calcul et économiser des ressources, ce qui est crucial pour améliorer les performances globales d’un système informatique. Une compréhension approfondie du principe de fonctionnement et de la méthode d'optimisation de GEMM nous aidera à mieux utiliser le potentiel du matériel informatique moderne et à fournir des solutions plus efficaces pour diverses tâches informatiques complexes. En optimisant les performances de GEMM
 Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le système de conduite intelligent Qiankun ADS3.0 de Huawei sera lancé en août et sera lancé pour la première fois sur Xiangjie S9
Jul 30, 2024 pm 02:17 PM
Le 29 juillet, lors de la cérémonie de lancement de la 400 000e nouvelle voiture d'AITO Wenjie, Yu Chengdong, directeur général de Huawei, président de Terminal BG et président de la BU Smart Car Solutions, a assisté et prononcé un discours et a annoncé que les modèles de la série Wenjie seraient sera lancé cette année En août, la version Huawei Qiankun ADS 3.0 a été lancée et il est prévu de pousser successivement les mises à niveau d'août à septembre. Le Xiangjie S9, qui sortira le 6 août, lancera le système de conduite intelligent ADS3.0 de Huawei. Avec l'aide du lidar, la version Huawei Qiankun ADS3.0 améliorera considérablement ses capacités de conduite intelligente, disposera de capacités intégrées de bout en bout et adoptera une nouvelle architecture de bout en bout de GOD (identification générale des obstacles)/PDP (prédictive prise de décision et contrôle), fournissant la fonction NCA de conduite intelligente d'une place de stationnement à l'autre et mettant à niveau CAS3.0
 Quelle version du système Apple 16 est la meilleure ?
Mar 08, 2024 pm 05:16 PM
Quelle version du système Apple 16 est la meilleure ?
Mar 08, 2024 pm 05:16 PM
La meilleure version du système Apple 16 est iOS16.1.4. La meilleure version du système iOS16 peut varier d'une personne à l'autre. Les ajouts et améliorations de l'expérience d'utilisation quotidienne ont également été salués par de nombreux utilisateurs. Quelle version du système Apple 16 est la meilleure ? Réponse : iOS16.1.4 La meilleure version du système iOS 16 peut varier d'une personne à l'autre. Selon les informations publiques, iOS16, lancé en 2022, est considéré comme une version très stable et performante, et les utilisateurs sont plutôt satisfaits de son expérience globale. De plus, l'ajout de nouvelles fonctionnalités et les améliorations de l'expérience d'utilisation quotidienne dans iOS16 ont également été bien accueillies par de nombreux utilisateurs. Surtout en termes de durée de vie de la batterie mise à jour, de performances du signal et de contrôle du chauffage, les retours des utilisateurs ont été relativement positifs. Cependant, compte tenu de l'iPhone14
 Toujours nouveau ! Mises à niveau de la série Huawei Mate60 vers HarmonyOS 4.2 : amélioration du cloud AI, le dialecte Xiaoyi est si facile à utiliser
Jun 02, 2024 pm 02:58 PM
Toujours nouveau ! Mises à niveau de la série Huawei Mate60 vers HarmonyOS 4.2 : amélioration du cloud AI, le dialecte Xiaoyi est si facile à utiliser
Jun 02, 2024 pm 02:58 PM
Le 11 avril, Huawei a officiellement annoncé pour la première fois le plan de mise à niveau de 100 machines HarmonyOS 4.2. Cette fois, plus de 180 appareils participeront à la mise à niveau, couvrant les téléphones mobiles, les tablettes, les montres, les écouteurs, les écrans intelligents et d'autres appareils. Au cours du mois dernier, avec la progression constante du plan de mise à niveau de 100 machines HarmonyOS4.2, de nombreux modèles populaires, notamment Huawei Pocket2, la série Huawei MateX5, la série nova12, la série Huawei Pura, etc., ont également commencé à être mis à niveau et à s'adapter, ce qui signifie qu'il y aura davantage d'utilisateurs de modèles Huawei pourront profiter de l'expérience commune et souvent nouvelle apportée par HarmonyOS. À en juger par les commentaires des utilisateurs, l'expérience des modèles de la série Huawei Mate60 s'est améliorée à tous égards après la mise à niveau d'HarmonyOS4.2. Surtout Huawei M
 Quels sont les systèmes d'exploitation informatiques ?
Jan 12, 2024 pm 03:12 PM
Quels sont les systèmes d'exploitation informatiques ?
Jan 12, 2024 pm 03:12 PM
Un système d'exploitation informatique est un système utilisé pour gérer du matériel informatique et des logiciels. C'est également un programme de système d'exploitation développé sur la base de tous les systèmes logiciels. Alors, quels sont les systèmes informatiques ? Ci-dessous, l'éditeur partagera avec vous ce que sont les systèmes d'exploitation informatiques. Le soi-disant système d'exploitation consiste à gérer le matériel informatique et les logiciels. Tous les logiciels sont développés sur la base des programmes du système d'exploitation. En fait, il existe de nombreux types de systèmes d’exploitation, notamment ceux à usage industriel, commercial et personnel, couvrant un large éventail d’applications. Ci-dessous, l'éditeur vous expliquera ce que sont les systèmes d'exploitation informatiques. Quels systèmes d'exploitation informatiques sont les systèmes Windows ? Le système Windows est un système d'exploitation développé par Microsoft Corporation des États-Unis. que le plus
 Différences et similitudes des commandes cmd dans les systèmes Linux et Windows
Mar 15, 2024 am 08:12 AM
Différences et similitudes des commandes cmd dans les systèmes Linux et Windows
Mar 15, 2024 am 08:12 AM
Linux et Windows sont deux systèmes d'exploitation courants, représentant respectivement le système Linux open source et le système Windows commercial. Dans les deux systèmes d'exploitation, il existe une interface de ligne de commande permettant aux utilisateurs d'interagir avec le système d'exploitation. Sur les systèmes Linux, les utilisateurs utilisent la ligne de commande Shell, tandis que sur les systèmes Windows, les utilisateurs utilisent la ligne de commande cmd. La ligne de commande Shell dans le système Linux est un outil très puissant qui peut effectuer presque toutes les tâches de gestion du système.
 Explication détaillée de la façon de modifier la date système dans la base de données Oracle
Mar 09, 2024 am 10:21 AM
Explication détaillée de la façon de modifier la date système dans la base de données Oracle
Mar 09, 2024 am 10:21 AM
Explication détaillée de la méthode de modification de la date système dans la base de données Oracle. Dans la base de données Oracle, la méthode de modification de la date système consiste principalement à modifier le paramètre NLS_DATE_FORMAT et à utiliser la fonction SYSDATE. Cet article présentera en détail ces deux méthodes et leurs exemples de code spécifiques pour aider les lecteurs à mieux comprendre et maîtriser l'opération de modification de la date système dans la base de données Oracle. 1. Modifier la méthode du paramètre NLS_DATE_FORMAT NLS_DATE_FORMAT correspond aux données Oracle
 Où se trouve le chemin de stockage des polices système ?
Feb 19, 2024 pm 09:11 PM
Où se trouve le chemin de stockage des polices système ?
Feb 19, 2024 pm 09:11 PM
Dans quel dossier se trouvent les polices système ? Dans les systèmes informatiques modernes, les polices jouent un rôle essentiel, affectant notre expérience de lecture et la beauté de l’expression du texte. Pour certains utilisateurs férus de personnalisation et de personnalisation, il est particulièrement important de comprendre l'emplacement de stockage des polices système. Alors, dans quel dossier les polices système sont-elles stockées ? Cet article les dévoilera un par un pour tout le monde. Dans le système d'exploitation Windows, les polices système sont stockées dans un dossier appelé « Polices ». Ce dossier se trouve par défaut dans le lecteur Win C.
