

Les inondations sont l’une des catastrophes naturelles les plus courantes, avec près de 1,5 milliard de personnes dans le monde (19 % de la population mondiale) confrontées au risque d’inondation. Les inondations causent non seulement d’énormes dégâts physiques, mais entraînent également des pertes économiques d’environ 50 milliards de dollars chaque année dans le monde.
Ces dernières années, le changement climatique d'origine humaine a encore augmenté la fréquence des inondations dans certaines régions. Cependant, les méthodes de prévision actuelles reposent principalement sur des stations d’observation construites le long des cours d’eau, qui sont inégalement répartis dans le monde. Cela rend plus difficile la prévision des cours d’eau non mesurés, et ses impacts négatifs se reflètent principalement dans les pays en développement. Améliorer les systèmes d’alerte précoce afin que ces groupes aient accès à des informations précises et actuelles pourrait sauver des milliers de vies chaque année.
Alors, comment parvenir à des prévisions fiables des inondations à l’échelle mondiale ? Les modèles d’intelligence artificielle (IA) peuvent être très prometteurs.
Gray Nearing et les membres de l'équipe de prévision des inondations de Google Research ont développé avec succès un modèle d'intelligence artificielle entraîné à l'aide de 5 680 jauges existantes. Ce modèle peut prédire avec précision le ruissellement quotidien dans les bassins versants non jaugés au cours des sept prochains jours, fournissant ainsi des données importantes pour l'alerte et la prévention des inondations. Gray Nearing a noté que la technologie a été développée pour améliorer la capacité de prédire les risques d'inondation afin que les mesures nécessaires puissent être prises en temps opportun pour réduire l'impact des catastrophes potentielles. Une démonstration réussie de ce résultat de recherche
Ensuite, ils ont mené un test comparatif de ce modèle d'intelligence artificielle avec le principal logiciel mondial de prévision des inondations à court et à long terme, le Global Flood Alert System (GloFAS). Les résultats montrent que le modèle est comparable, voire meilleur, que les systèmes existants en termes de précision des prévisions le jour même.
De plus, le modèle a démontré un niveau de précision comparable ou même supérieur à celui de GloFAS dans la prévision des événements météorologiques extrêmes avec une fenêtre de retour de cinq ans, par rapport à GloFAS dans la prévision des événements avec une fenêtre de retour d'un an.
Le document de recherche pertinent s'intitule « Prévision mondiale des inondations extrêmes dans les bassins versants non jaugeés » et a été publié dans la revue scientifique faisant autorité, Nature.
L'équipe de recherche a souligné que ce modèle peut fournir une alerte précoce en cas d'inondations à petite échelle et extrêmes pouvant survenir dans des bassins versants non mesurés, et fournit un délai d'alerte plus long que les méthodes précédentes. Cela contribuera à améliorer l’accès à des informations fiables sur les alertes aux inondations dans les régions des pays en développement.
Alors, comment ce modèle d’intelligence artificielle peut-il donner des prévisions de crues fiables ?
Le réseau de mémoire à long terme et à court terme (LSTM) a été utilisé comme modèle d'intelligence artificielle dans l'étude pour prédire le débit de la rivière. Le modèle fonctionne de manière similaire au cerveau humain et est capable de prédire les futurs débits fluviaux en apprenant des séquences de données météorologiques. Le modèle est divisé en deux parties : un encodeur et un décodeur. L'encodeur est responsable du traitement des données d'entrée et le décodeur est responsable de la génération des résultats de prédiction. De cette manière, le modèle peut fournir des prévisions précises et fiables du débit des rivières, apportant ainsi un soutien important aux efforts de gestion des ressources en eau et de prévention des catastrophes.
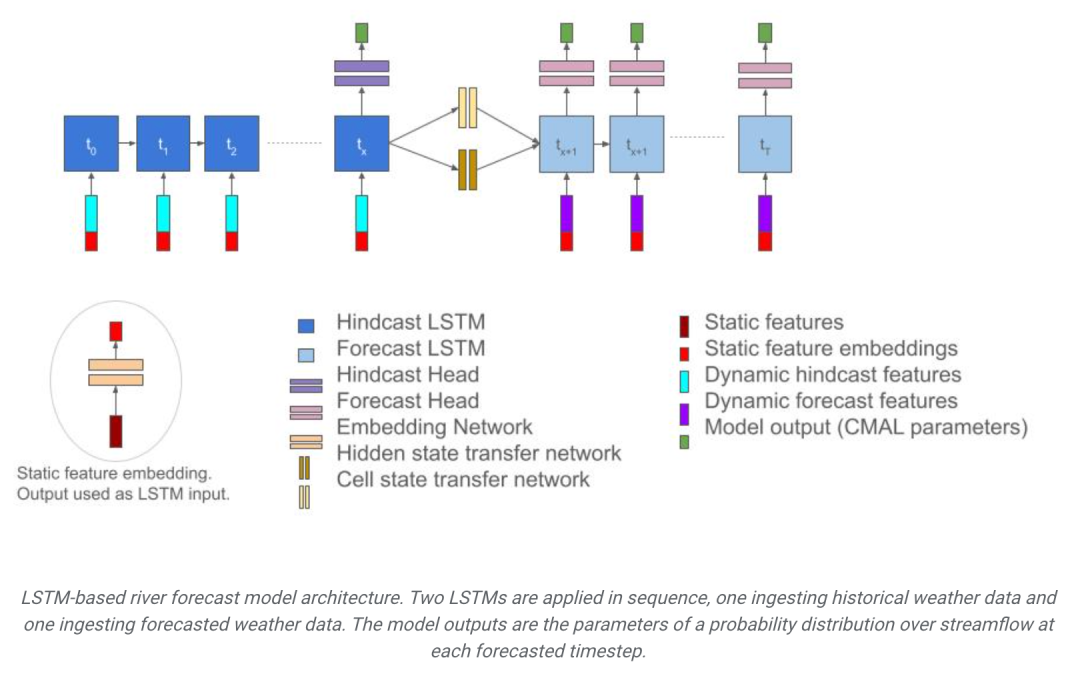
Architecture de modèle de prévision fluviale basée sur LSTM. Deux LSTM sont appliqués séquentiellement, l'un recevant des données météorologiques historiques et l'autre recevant des données météorologiques prévues. Le résultat du modèle correspond aux paramètres de distribution de probabilité de débit à chaque pas de temps de prévision.
Tout d'abord, l'encodeur est chargé d'extraire les informations des données météorologiques de la période précédente. Il comprend les changements de débit de la rivière à partir des conditions météorologiques passées. Il convertit les données météorologiques historiques en une forme d'information pouvant être utilisée par les décodeurs. En apprenant les caractéristiques et les modèles temporels des données météorologiques, le modèle développe une compréhension abstraite des conditions météorologiques passées, fournissant ainsi une contribution essentielle aux prévisions de débit ultérieures.
L'encodeur reçoit une série de données météorologiques (telles que les précipitations, la température, le rayonnement, etc.) en entrée et apprend à extraire des informations sur les caractéristiques clés de ces données. Ces informations caractéristiques peuvent inclure les changements saisonniers, les événements météorologiques (tels que les fortes pluies, les températures élevées, etc.) et leur impact sur le débit fluvial.
En même temps, l'encodeur est capable de capturer les dépendances temporelles entre les données météorologiques. Cela signifie qu’il prend en compte non seulement les conditions météorologiques du moment actuel, mais également les tendances des changements météorologiques au cours de la période précédente. En apprenant des données historiques, l'encodeur est capable de comprendre les modèles de séries chronologiques de données météorologiques et de les intégrer dans le modèle.
Dans l'encodeur, le réseau LSTM est utilisé pour traiter les données de séries chronologiques. LSTM dispose d'une unité de mémoire interne qui peut mémoriser les informations passées et mettre à jour l'état interne en fonction de l'entrée actuelle. Cela permet à l'encodeur de bien gérer les dépendances à long terme et de préserver les informations historiques importantes pendant le processus de modélisation.
Enfin, l'encodeur convertit les données météorologiques historiques en une représentation potentielle contenant une compréhension et un résumé des conditions météorologiques passées. Cette représentation est la sortie du codeur et est transmise au décodeur pour prédire le trafic futur.
La partie décodeur utilise ensuite ces informations pour prédire le débit de la rivière sur les prochains jours. Il prend en compte les prévisions météorologiques actuelles, ainsi que l'impact des conditions météorologiques passées sur les flux futurs. De cette façon, vous pouvez obtenir les prévisions de trafic pour la semaine prochaine.

Le décodeur est chargé de combiner les informations météorologiques historiques et les prévisions futures dans le modèle, de générer des prévisions du débit futur de la rivière et de produire la distribution de probabilité de débit correspondante.
Le décodeur reçoit d'abord une représentation latente de l'encodeur, qui contient une compréhension abstraite des données météorologiques historiques. Le décodeur utilise ces informations pour comprendre l’impact des conditions météorologiques passées sur les débits fluviaux et pour établir des liens entre les données historiques et les prévisions futures.
Le décodeur reçoit également en entrée les données de prévisions météorologiques futures. Ces données de prévision incluent généralement les précipitations, la température et d’autres indicateurs météorologiques pour les prochains jours. Le décodeur combine des informations historiques et des prévisions futures pour prédire les futurs débits fluviaux en apprenant la relation entre eux.
Après avoir compris les conditions météorologiques historiques et les prévisions futures, le décodeur génère des prévisions du débit futur de la rivière via un réseau LSTM indépendant. Ce réseau peut être compris comme un générateur de séries chronologiques qui génère des séquences de trafic basées sur des informations passées et des prévisions futures.
Le décodeur prédit non seulement les valeurs futures du débit de la rivière, mais génère également une distribution de probabilité. Plus précisément, le modèle utilise une distribution de Laplace unilatérale pour décrire l'incertitude du débit. Lors de la prévision de la valeur du débit à chaque pas de temps, il génère les paramètres d'une distribution de Laplace unilatérale plutôt qu'une valeur déterminée. Cela permet au modèle de prendre en compte l'incertitude des prévisions de débit, fournissant ainsi plus d'informations pour la prise de décision.
Le résultat final de la prévision du trafic est obtenu en intégrant la sortie de plusieurs modèles de décodeur. Le modèle utilise trois réseaux LSTM de décodeurs formés indépendamment, puis prend la médiane de leurs prédictions, réduisant ainsi la variance des prédictions et améliorant la stabilité des prédictions.
Les chercheurs ont collecté une grande quantité de données météorologiques et de données sur le débit des rivières pour entraîner ce modèle. Les données proviennent de différentes sources de données, notamment des prévisions météorologiques, des enregistrements historiques et des informations géographiques. En normalisant les données, le modèle les comprend correctement.
Ensuite, les données sont divisées en deux types : l'ensemble d'entraînement et l'ensemble de test. L'ensemble de formation est utilisé pour entraîner le modèle, tandis que l'ensemble de test est utilisé pour évaluer les performances du modèle. Les chercheurs ont utilisé une approche de « validation croisée » pour garantir que le modèle fonctionnait efficacement dans le temps et dans les lieux.
Enfin, l'équipe de recherche a évalué les performances du modèle et l'a comparé aux modèles de prévision de trafic existants.
L'équipe de recherche a utilisé des mesures d'erreur courantes pour quantifier la différence entre les prédictions du modèle et les observations réelles. Étant donné que le modèle prédit non seulement des valeurs spécifiques du débit futur, mais donne également l'incertitude dans la prévision du débit, ils ont utilisé un tracé de transformation intégrale probabiliste (PIT) pour évaluer l'exactitude de la distribution prévue.
L'équipe de recherche évalue également les performances du modèle proposé en le comparant à d'autres modèles de prévision du trafic. Cela inclut les modèles physiques traditionnels et d’autres modèles d’apprentissage automatique. En comparant les indicateurs d'erreur de différents modèles, les avantages du modèle proposé en termes de précision et de fiabilité peuvent être démontrés intuitivement.
De plus, l'équipe de recherche a également utilisé des bassins versants ou des rivières spécifiques comme études de cas, appliqué le modèle à des situations réelles et analysé en détail les performances prédictives du modèle dans différentes saisons et différentes conditions climatiques. Cela permet d'évaluer la faisabilité et la stabilité du modèle dans des applications pratiques.
En plus des indicateurs quantitatifs, l'équipe de recherche a également mené une analyse approfondie de l'incertitude des prédictions des modèles. Cela comprend l'évaluation de l'impact de différentes sources d'incertitude (telles que l'incertitude des données d'entrée, l'incertitude de la structure du modèle, etc.) sur les résultats des prévisions, ainsi que la mesure dans laquelle les modèles peuvent encore fournir des prévisions utiles en présence d'incertitude.
Les résultats montrent que le modèle présente une précision et un rappel élevés, en particulier pour les événements avec des périodes de retour à court terme. Cela signifie que le modèle est capable d'identifier avec précision les événements d'inondation et de manquer moins d'événements.
Combinant précision et rappel, le modèle a obtenu un score F1 élevé sur des événements avec différentes périodes de retour, indiquant qu'il a atteint un bon équilibre entre précision et exhaustivité.
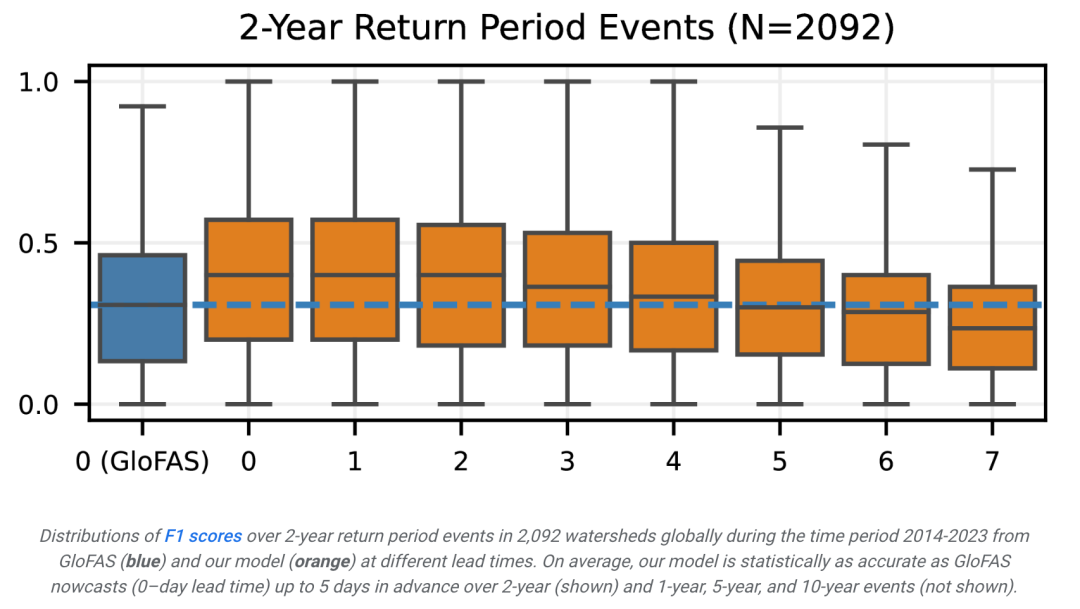
De plus, les résultats de prédiction du modèle sont statistiquement significativement meilleurs que le modèle de base grâce au test bilatéral de rang signé de Wilcoxon. Cela démontre l’efficacité du modèle dans la prévision des crues.
L'indice d de Cohen montre que l'effet de l'amélioration des performances du modèle est significatif, ce qui vérifie en outre les avantages du modèle par rapport aux méthodes traditionnelles.
Sur les indicateurs hydrologiques tels que l'efficacité de Nash-Sutcliffe et l'efficacité de Kling-Gupta, le modèle montre également une bonne précision de prévision et une bonne sensibilité aux changements dans les processus hydrologiques.
Cependant, cette étude présente également certaines limites.
Par exemple, l'échantillon utilisé dans l'expérience peut être petit, ce qui limite l'applicabilité générale et la puissance statistique des résultats de la recherche. Il existe un manque de diversité dans les ensembles de données utilisés dans l'étude, ce qui peut affecter la capacité de généralisation du modèle. Le modèle adopté présente une grande complexité, ce qui peut augmenter le coût de calcul et limiter son interprétabilité et sa commodité.
De plus, la recherche se concentre sur des tâches ou des domaines spécifiques, ce qui peut limiter la large application de la méthode ; cette méthode manque d'évaluation de l'impact à long terme, ce qui entraîne un manque de compréhension des performances du modèle dans le temps, et les critères d'évaluation peuvent ne pas refléter pleinement les performances du modèle ; et le degré d'amélioration par rapport à la technologie existante peut être relativement limité.
À cet égard, l'équipe de recherche a déclaré que des travaux futurs sont nécessaires pour étendre davantage la couverture des prévisions d'inondations à davantage d'endroits dans le monde, ainsi qu'à d'autres types d'événements et de catastrophes liés aux inondations, notamment les crues soudaines et les catastrophes urbaines. inondation. La technologie de l’intelligence artificielle continuera également à jouer un rôle clé en contribuant à faire progresser la recherche scientifique et à promouvoir l’action climatique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 utilisation de la fonction de palette de couleurs Matlab
utilisation de la fonction de palette de couleurs Matlab
 Quels sont les cycles de vie de vue3
Quels sont les cycles de vie de vue3
 Comment lire les fichiers py en python
Comment lire les fichiers py en python
 Quelles sont les fonctions de création de sites Web ?
Quelles sont les fonctions de création de sites Web ?
 La différence entre python et pycharm
La différence entre python et pycharm
 Que signifie le contexte ?
Que signifie le contexte ?
 Comment définir le style des points CAO
Comment définir le style des points CAO
 Windows ne peut pas ouvrir ajouter une imprimante
Windows ne peut pas ouvrir ajouter une imprimante








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



