
 Périphériques technologiques
IA
En plus de CNN, Transformer et Uniformer, nous disposons enfin d'une technologie de compréhension vidéo plus efficace
Périphériques technologiques
IA
En plus de CNN, Transformer et Uniformer, nous disposons enfin d'une technologie de compréhension vidéo plus efficace
En plus de CNN, Transformer et Uniformer, nous disposons enfin d'une technologie de compréhension vidéo plus efficace

L'objectif principal de la compréhension vidéo est de comprendre avec précision la représentation spatio-temporelle, mais elle est confrontée à deux défis principaux : il existe une grande redondance spatio-temporelle dans les courts clips vidéo et des dépendances spatio-temporelles complexes. Les réseaux neuronaux convolutifs tridimensionnels (CNN) et les transformateurs vidéo ont bien réussi à résoudre l'un de ces défis, mais ils présentent certaines lacunes pour relever les deux défis simultanément. UniFormer tente de combiner les avantages des deux approches, mais rencontre des difficultés pour modéliser de longues vidéos.
L'émergence de solutions low-cost telles que S4, RWKV et RetNet dans le domaine du traitement du langage naturel a ouvert de nouvelles voies pour les modèles visuels. Mamba se distingue par son modèle spatial à états sélectif (SSM), qui atteint un équilibre entre le maintien de la complexité linéaire tout en facilitant la modélisation dynamique à long terme. Cette innovation conduit à son application dans les tâches de vision, comme le démontrent Vision Mamba et VMamba, qui exploitent le SSM multidirectionnel pour améliorer le traitement des images 2D. Ces modèles sont comparables en performances aux architectures basées sur l'attention tout en réduisant considérablement l'utilisation de la mémoire.
Étant donné que les séquences produites par les vidéos sont elles-mêmes plus longues, une question naturelle se pose : Mamba fonctionne-t-il bien pour la compréhension des vidéos ?
Inspiré de Mamba, cet article présente VideoMamba, un SSM (Selective State Space Model) spécialement personnalisé pour la compréhension vidéo. VideoMamba s'appuie sur la philosophie de conception de Vanilla ViT et combine des mécanismes de convolution et d'attention. Il fournit une méthode de complexité linéaire pour la modélisation dynamique d’arrière-plan spatio-temporel, particulièrement adaptée au traitement de longues vidéos haute résolution. L'évaluation se concentre principalement sur quatre fonctionnalités clés de VideoMamba :
Évolutivité dans le champ visuel : Cet article examine l'évolutivité de VideoMamba et constate que le modèle Mamba pur a tendance à être facile à adopter à mesure qu'il continue de s'étendre. . En conséquence, cet article présente une stratégie d'auto-distillation simple mais efficace qui permet à VideoMamba d'obtenir des améliorations significatives des performances à mesure que la taille du modèle et de l'entrée augmente sans avoir besoin d'un pré-entraînement de jeux de données à grande échelle.
Sensibilité à la reconnaissance des actions à court terme : L'analyse de cet article s'étend à l'évaluation de la capacité de VideoMamba à distinguer avec précision les actions à court terme, en particulier celles présentant des différences de mouvement subtiles, telles que l'ouverture et la fermeture. Les résultats de la recherche montrent que VideoMamba présente d'excellentes performances par rapport aux modèles existants basés sur l'attention. Plus important encore, il convient également à la modélisation de masques, améliorant encore sa sensibilité temporelle.
Supériorité dans la compréhension des vidéos longues : Cet article évalue la capacité de VideoMamba à interpréter de longues vidéos. Avec une formation de bout en bout, elle démontre des avantages significatifs par rapport aux méthodes traditionnelles basées sur les fonctionnalités. Notamment, VideoMamba fonctionne 6 fois plus vite que TimeSformer sur une vidéo de 64 images et nécessite 40 fois moins de mémoire GPU (illustré dans la figure 1).

Compatibilité avec d'autres modalités : Enfin, cet article évalue l'adaptabilité de VideoMamba avec d'autres modalités. Les résultats de la récupération de texte vidéo montrent des performances améliorées par rapport à ViT, en particulier dans les longues vidéos avec des scénarios complexes. Cela met en évidence sa robustesse et ses capacités d’intégration multimodale.
Les expériences approfondies de cette étude révèlent l'énorme potentiel de VideoMamba pour la compréhension du contenu vidéo à court terme (K400 et SthSthV2) et à long terme (Breakfast, COIN et LVU). VideoMamba fait preuve d'une grande efficacité et précision, ce qui indique qu'il deviendra un élément clé dans le domaine de la compréhension des vidéos longues. Pour faciliter les recherches futures, tous les codes et modèles ont été rendus open source.

- Adresse papier : https://arxiv.org/pdf/2403.06977.pdf
- Adresse du projet : https://github.com/OpenGVLab/VideoMamba
- Papier Titre : VideoMamba : Modèle spatial d'état pour une compréhension efficace de la vidéo
Introduction à la méthode
La figure 2a ci-dessous montre les détails du module Mamba.

La figure 3 illustre le cadre global de VideoMamba. Cet article utilise d'abord la convolution 3D (c'est-à-dire 1×16×16) pour projeter la vidéo d'entrée Xv ∈ R 3×T ×H×W sur L patchs spatio-temporels non chevauchants Xp ∈ R L×C, où L=t×h ×w (t=T, h= H 16 et w= W 16). L'entrée de séquence de jetons dans l'encodeur VideoMamba suivant est 

Scan spatio-temporel : afin d'appliquer la couche B-Mamba à l'entrée spatio-temporelle, le scan 2D d'origine est étendu en différents scans 3D bidirectionnels dans la figure 4 de cet article :
(a) Spatial d'abord, organisez les jetons spatiaux par position, puis empilez-les image par image ;
(b) Le temps d'abord, organisez les jetons temporels en fonction des images, puis empilez-les selon les dimensions spatiales ;
( c) Hybride espace-temps, avec à la fois une priorité spatiale et une priorité temporelle, où v1 en exécute la moitié et v2 exécute tout (2 fois la quantité de calcul).
L'expérience de la figure 7a montre que le balayage bidirectionnel spatial est le plus efficace mais le plus simple. En raison de la complexité linéaire de Mamba, VideoMamba dans cet article peut traiter efficacement de longues vidéos haute résolution.

Pour SSM dans la couche B-Mamba, cet article utilise les mêmes paramètres d'hyperparamètres par défaut que Mamba, définissant la dimension d'état et le taux d'expansion à 16 et 2 respectivement. Suivant l'approche de ViT, cet article ajuste la profondeur et les dimensions d'intégration pour créer des modèles de taille comparable à ceux du tableau 1, notamment VideoMamba-Ti, VideoMamba-S et VideoMamba-M. Cependant, il a été observé lors d'expériences que des VideoMamba plus grands sont souvent sujets à un surajustement dans les expériences, ce qui entraîne des performances sous-optimales, comme le montre la figure 6a. Ce problème de surapprentissage existe non seulement dans le modèle proposé dans cet article, mais également dans VMamba, où les meilleures performances de VMamba-B sont obtenues aux trois quarts de la période de formation totale. Pour lutter contre le problème de surapprentissage des modèles Mamba plus grands, cet article présente une stratégie d'auto-distillation efficace qui utilise des modèles plus petits et bien formés comme « enseignants » pour guider la formation de modèles « étudiants » plus grands. Les résultats présentés dans la figure 6a montrent que cette stratégie conduit à la meilleure convergence attendue.


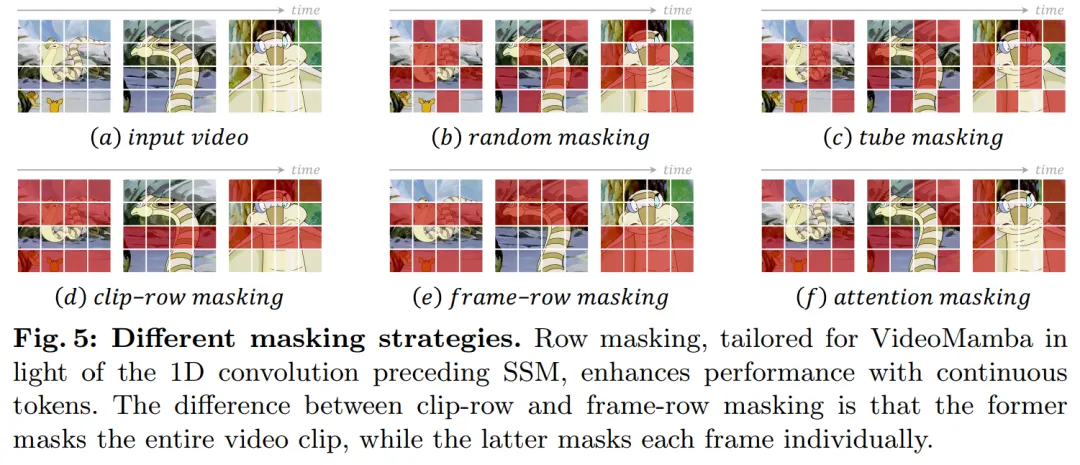
Concernant la stratégie de masquage, cet article propose différentes techniques de masquage de lignes, comme le montre la figure 5, ciblant spécifiquement la préférence du bloc B-Mamba pour les jetons consécutifs.
Expériences
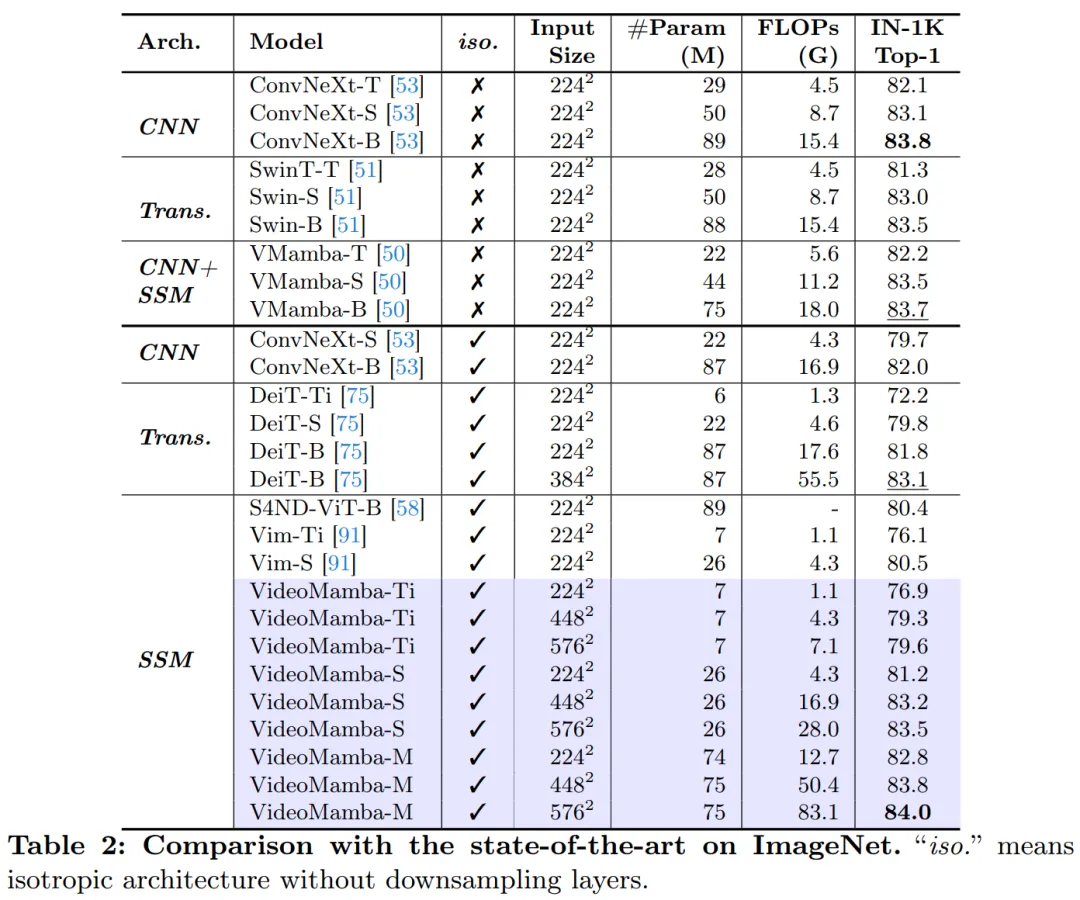
Le tableau 2 montre les résultats sur l'ensemble de données ImageNet-1K. Notamment, VideoMamba-M surpasse considérablement les autres architectures isotropes, s'améliorant de +0,8 % par rapport à ConvNeXt-B et de +2,0 % par rapport à DeiT-B, tout en utilisant moins de paramètres. VideoMamba-M fonctionne également bien dans une structure de base non isotrope qui utilise des fonctionnalités en couches pour des performances améliorées. Compte tenu de l'efficacité de Mamba dans le traitement de longues séquences, cet article améliore encore les performances en augmentant la résolution, atteignant une précision top-1 de 84,0 % en utilisant seulement 74 millions de paramètres.
Le Tableau 3 et le Tableau 4 répertorient les résultats sur l'ensemble de données vidéo à court terme. (a) Apprentissage supervisé : par rapport aux méthodes d'attention pure, VideoMamba-M basé sur SSM a obtenu des avantages évidents, surpassant ViViT-L sur les ensembles de données K400 liés à la scène et Sth-SthV2 liés au temps, respectivement +2,0 % et +3,0 %. Cette amélioration s'accompagne d'exigences de calcul considérablement réduites et de moins de données de pré-entraînement. Les résultats de VideoMamba-M sont comparables à ceux de SOTA UniFormer, qui intègre intelligemment la convolution et l'attention dans une architecture non isotrope. (b) Apprentissage auto-supervisé : avec le pré-entraînement au masque, VideoMamba surpasse VideoMAE, connu pour sa motricité fine. Cette réalisation met en évidence le potentiel de notre modèle purement basé sur SSM pour comprendre les vidéos à court terme de manière efficace et efficiente, soulignant son adéquation aux paradigmes d'apprentissage supervisé et auto-supervisé.


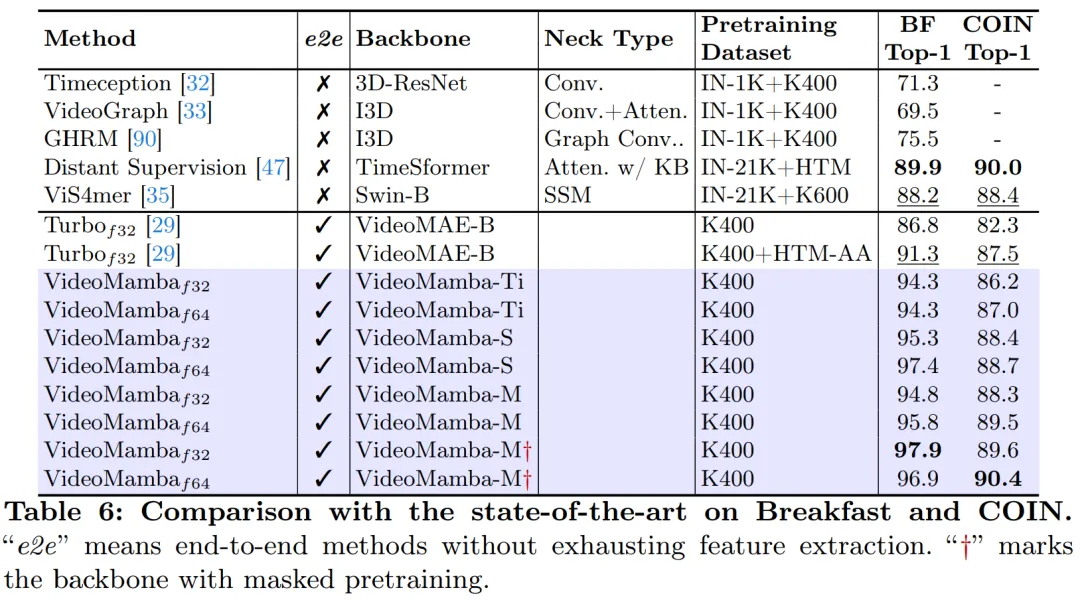
Comme le montre la figure 1, la complexité linéaire de VideoMamba le rend très approprié pour une formation de bout en bout avec des vidéos de longue durée. La comparaison dans les tableaux 6 et 7 met en évidence la simplicité et l'efficacité de VideoMamba par rapport aux méthodes traditionnelles basées sur les fonctionnalités dans ces tâches. Il apporte des améliorations significatives des performances, permettant d'obtenir des résultats SOTA même sur des modèles de plus petite taille. VideoMamba-Ti présente une amélioration significative de +6,1 % par rapport à ViS4mer en utilisant les fonctionnalités de Swin-B, ainsi qu'une amélioration de +3,0 % par rapport à la méthode d'alignement multimodal de Turbo. Les résultats mettent notamment en évidence l’impact positif des modèles de mise à l’échelle et des fréquences d’images pour les tâches à long terme. Sur neuf tâches diverses et difficiles proposées par LVU, cet article adopte une approche de bout en bout pour affiner VideoMamba-Ti et obtient des résultats comparables ou supérieurs aux méthodes SOTA actuelles. Ces résultats mettent non seulement en évidence l’efficacité de VideoMamba, mais démontrent également son grand potentiel pour la compréhension future des vidéos longues.
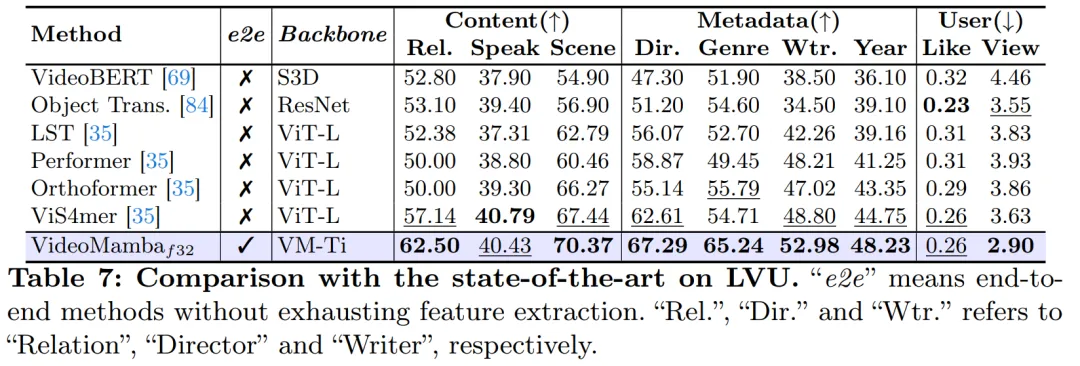
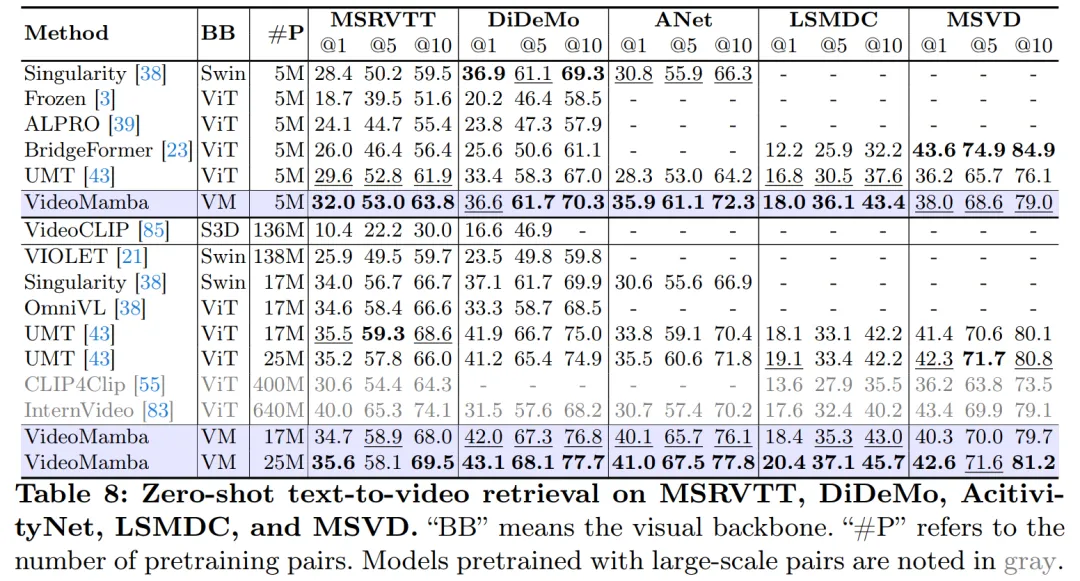
Comme le montre le tableau 8, avec le même corpus de pré-formation et une stratégie de formation similaire, VideoMamba surpasse l'UMT basé sur ViT en termes de performances de récupération vidéo zéro plan. Cela met en évidence l'efficacité et l'évolutivité comparables de Mamba à celles de ViT dans le traitement des tâches vidéo multimodales. Notamment, VideoMamba montre des améliorations significatives pour les ensembles de données avec des durées vidéo plus longues (par exemple, ANet et DiDeMo) et des scénarios plus complexes (par exemple, LSMDC). Cela démontre les capacités de Mamba dans des environnements multimodaux difficiles, même là où un alignement multimodal est requis.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
