

Interprétation intégrée de l'IA Big Data

1. Le moment « iPhone » de l'IA
Au cours de l'année écoulée, les grands modèles se sont développés très rapidement. L'empilement de la puissance de calcul et des données a donné au modèle une certaine construction générale et une capacité à répondre aux questions, ouvrant la voie. Les gens sont entrés dans l’étape de l’intelligence artificielle dont ils ont toujours rêvé. Par exemple, lorsque vous discutez avec un grand modèle de langage, vous aurez l'impression que vous n'êtes pas face à un robot brutal, mais à une personne en chair et en os. Cela ouvre plus d’espace à notre imagination. L'interaction homme-machine originale nécessitait l'utilisation du clavier et de la souris pour indiquer à la machine nos instructions via certaines méthodes de formatage. Désormais, les gens peuvent interagir avec les ordinateurs grâce au langage, et les machines peuvent comprendre ce que nous voulons dire et réagir.
Afin de suivre la tendance, de nombreuses entreprises technologiques ont commencé à se concentrer sur la recherche de grands modèles. 2023 est considérée comme la première année de l’intelligence artificielle, tout comme le lancement de l’iPhone a ouvert une nouvelle ère pour l’Internet mobile. La véritable avancée cette fois réside dans l’application d’une puissance de calcul à grande échelle et de données massives.
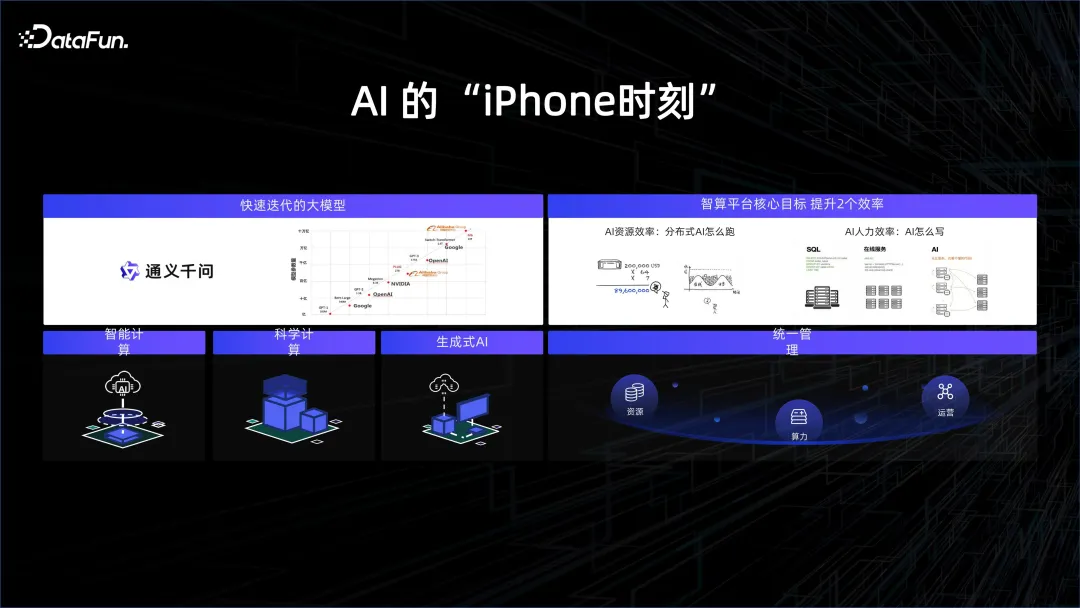
Du point de vue de la structure du modèle, la structure Transformer est en fait lancée depuis longtemps. En fait, le modèle GPT a été publié un an plus tôt que le modèle Bert. Cependant, en raison des limites de la puissance de calcul de l'époque, GPT était beaucoup moins efficace que Bert. Par conséquent, Bert est devenu populaire en premier et a été utilisé pour la traduction. de très bons résultats. Mais cette année, l'accent est mis sur GPT. La raison en est la puissance de calcul très élevée. Grâce aux efforts des fabricants de matériel et à certains progrès dans l'emballage et le stockage des particules, nous avons la capacité d'utiliser une puissance de calcul très élevée. ensemble, ils favorisent une compréhension approfondie d’un plus grand nombre de données et apportent des résultats révolutionnaires en matière d’IA. Grâce au solide support de la plateforme sous-jacente, les étudiants en algorithmie peuvent développer et itérer des modèles de manière plus pratique et plus efficace, favorisant ainsi une évolution rapide des modèles.
2. Paradigme de développement du modèle
Le cycle général de développement du modèle est illustré dans la figure ci-dessous :
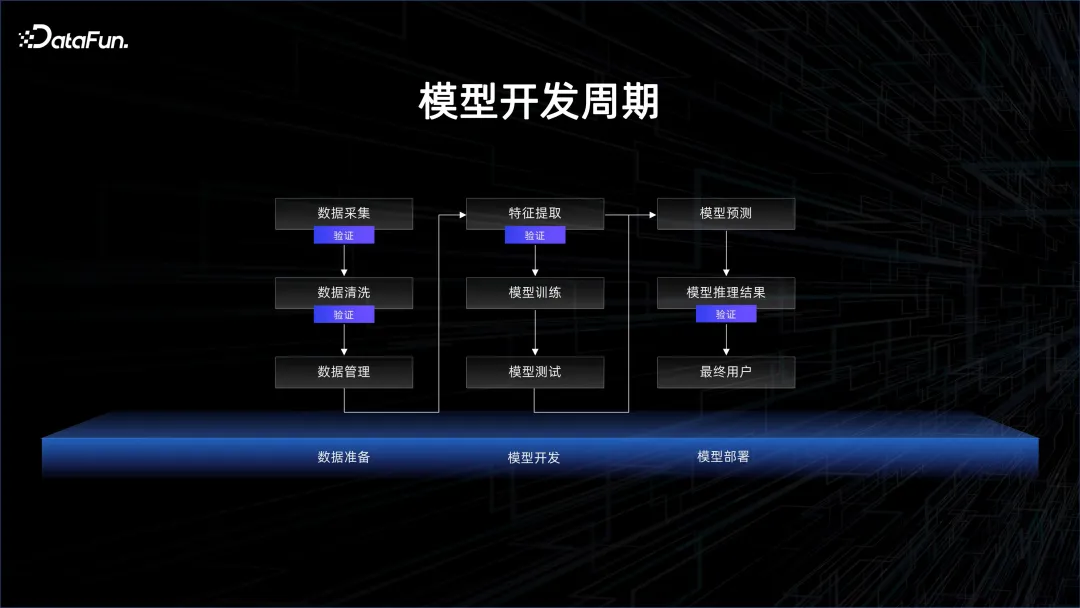
Beaucoup de gens pensent que la formation du modèle est l'étape la plus critique. Mais en réalité, avant la formation du modèle, une grande quantité de données doit être collectée, nettoyée et gérée. Dans ce processus, vous pouvez voir que de nombreuses étapes doivent être vérifiées, par exemple s'il existe des données sales et si la distribution statistique des données est représentative. Une fois le modèle publié, il doit être testé et vérifié. Il s'agit également de la vérification des données. Les données sont utilisées pour donner un retour sur l'efficacité du modèle.

Un meilleur apprentissage automatique, c'est 80 % de données plus 20 % de modèle, et l'accent doit être mis sur les données.
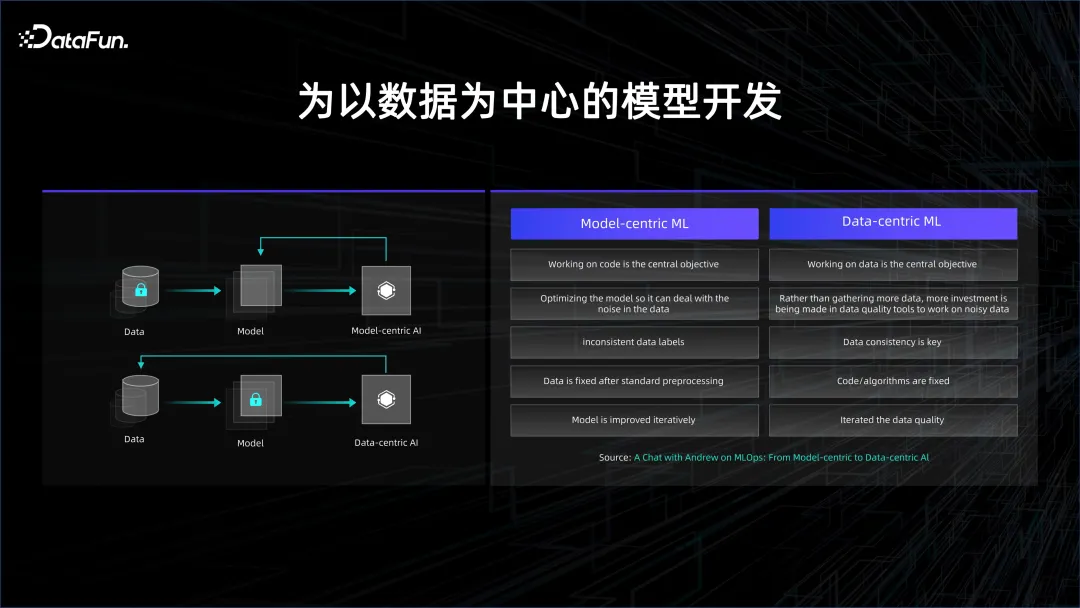
Cela reflète également la tendance évolutive du développement de modèles. Le développement du modèle d'origine était centré sur le modèle, mais il est maintenant devenu centré sur les données.
Au début de l'apprentissage profond, l'apprentissage supervisé était l'objectif principal, et le plus important était d'avoir des données étiquetées. Les données étiquetées sont divisées en deux catégories, l’une étant des données de formation et l’autre des données de vérification. Utilisez les données d'entraînement pour entraîner le modèle, puis vérifiez si le modèle peut donner de bons résultats sur les données de test. Le coût de l’étiquetage des données est très élevé car les personnes doivent les étiqueter. Si vous souhaitez améliorer l'effet du modèle, vous devez consacrer beaucoup de temps et de main-d'œuvre à la structure du modèle, améliorer la capacité de généralisation du modèle grâce à des changements structurels et réduire le surajustement du modèle. paradigme de développement centré.
Avec l'accumulation de données et de puissance de calcul, l'apprentissage non supervisé a progressivement commencé à être utilisé. Grâce à des données massives, le modèle a pu découvrir de manière autonome les relations existant dans les données. À cette époque, il est entré dans le développement centré sur les données. paradigme.
Dans le modèle de développement centré sur les données, les structures du modèle sont similaires, essentiellement une pile de Transformers, donc plus d'attention est accordée à la façon d'utiliser les données. Dans le processus d'utilisation des données, il y aura beaucoup de nettoyage et de comparaison des données, ce qui prendra beaucoup de temps car une quantité massive de données est nécessaire. La manière de contrôler finement les données détermine la vitesse de convergence et d'itération du modèle.
3. Intégration de l'IA Big Data
1. Panorama de l'IA Big Data

Alibaba Cloud a toujours mis l'accent sur l'intégration de l'IA et du Big Data. Par conséquent, nous avons construit une plate-forme dotée d'une très bonne infrastructure, notamment des clusters GPU à large bande passante pour fournir une puissance de calcul IA hautes performances, et des clusters CPU pour fournir des capacités de stockage et de gestion des données rentables. En plus de cela, nous avons construit une plate-forme PaaS intégrée au Big Data et à l'IA, qui comprend une plate-forme Big Data, une plate-forme IA, une plate-forme à haute puissance de calcul, une plate-forme cloud native, etc. La partie moteur comprend le calcul en streaming, le calcul hors ligne Big Data MaxCompute et PAI.
Dans la couche service, il y a la plateforme d'applications de grands modèles Bailian et la communauté de modèles open source ModelScope. Alibaba promeut activement le partage de communautés de modèles, dans l'espoir d'utiliser le concept de modèle en tant que service pour inciter davantage d'utilisateurs ayant des besoins en IA à utiliser les capacités de base de ces modèles pour créer rapidement des applications d'IA.
2. Pourquoi il est nécessaire de combiner big data et IA
Les deux cas suivants seront utilisés pour expliquer pourquoi le lien entre big data et IA est nécessaire.
Cas 1 : Système de réponse aux questions grand modèle avec récupération améliorée de la base de connaissances
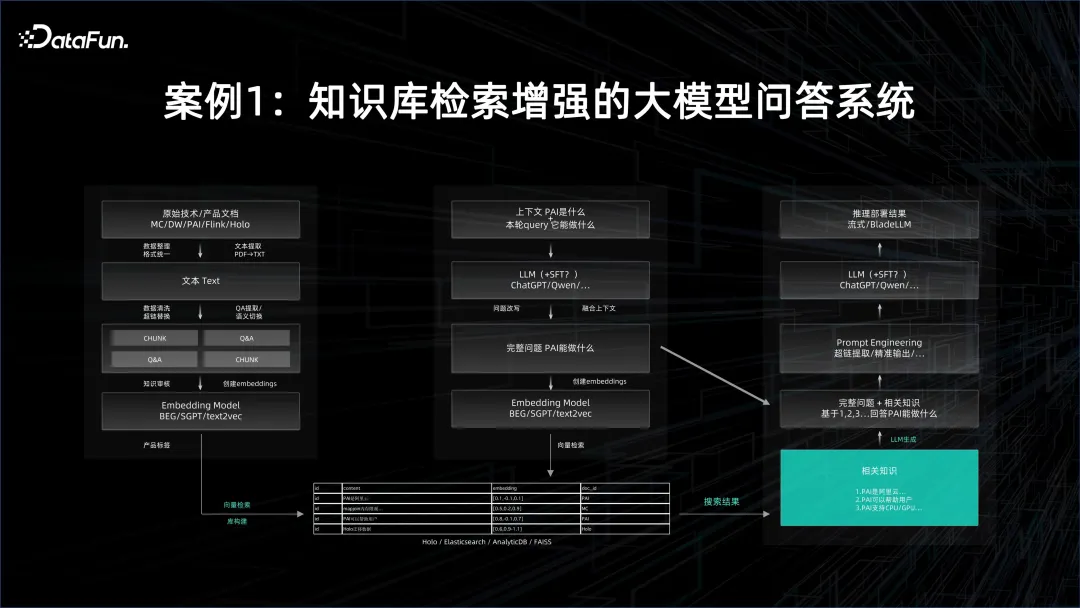
Dans le système de réponse aux questions grand modèle, le modèle de base doit d'abord être utilisé, puis le document cible doit être intégré et incorporé Les résultats sont stockés dans la base de données vectorielles. Le nombre de documents peut être très important, l'intégration nécessite donc des capacités de traitement par lots. Le service d'inférence du modèle de base lui-même est également très consommateur de ressources. Bien entendu, cela dépend également de la taille du modèle de base utilisé et de la manière de le paralléliser. Tous les plongements générés sont versés dans la base de données vectorielles. Lors de l'interrogation, la requête doit également être vectorisée, puis grâce à la récupération vectorielle, les connaissances pouvant être liées à la question et à la réponse sont extraites de la base de données vectorielles. Cela nécessite de très bonnes performances du service d'inférence.
Après avoir extrait le vecteur, vous devez utiliser le document représenté par le vecteur comme contexte, puis contraindre ce grand modèle et poser des questions et réponses sur cette base. L'effet de la réponse sera bien meilleur que les résultats obtenus. par votre propre méthode de recherche, et la réponse est en langage naturel humain.
Dans le processus ci-dessus, à la fois une plate-forme de Big Data distribuée hors ligne est nécessaire pour générer rapidement des intégrations, et une plate-forme d'IA pour la formation et les services de grands modèles est nécessaire pour connecter l'ensemble du processus afin de former un système de questions et réponses de grand modèle. .
Cas 2 : Système de recommandation intelligent
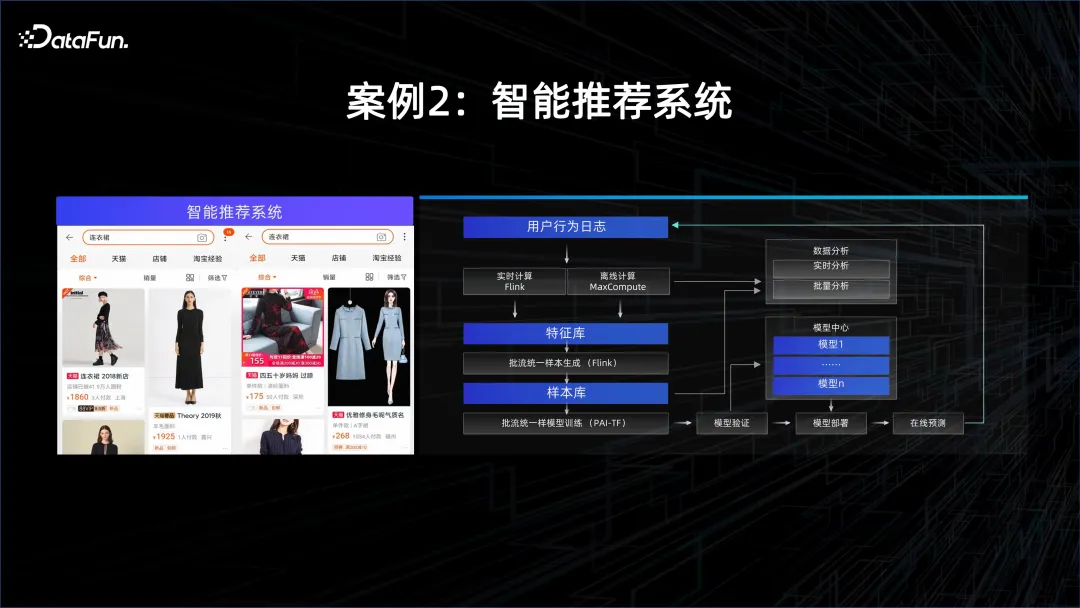
Un autre exemple est la recommandation personnalisée. Ce modèle nécessite souvent une grande rapidité car les intérêts et la personnalité de chacun vont changer, et ces changements doivent être capturés, il est nécessaire d'utiliser un. système informatique de streaming pour analyser les données obtenues dans l'APP, puis laisser continuellement le modèle apprendre en ligne grâce aux fonctionnalités extraites. Chaque fois que de nouvelles données arrivent, le modèle sera mis à jour, puis via un nouveau modèle pour servir les clients. Par conséquent, dans ce scénario, des capacités de calcul en continu sont requises, ainsi que des capacités de diffusion de modèles et de formation.
3. Comment combiner le big data avec l'IA
À travers les cas ci-dessus, nous pouvons voir que la combinaison de l'IA et du big data est devenue une tendance de développement inévitable. Sur la base de ce concept, nous devons d'abord disposer d'un espace de travail capable de gérer ensemble la plateforme Big Data et la plateforme IA. C'est pourquoi l'espace de travail IA est né.
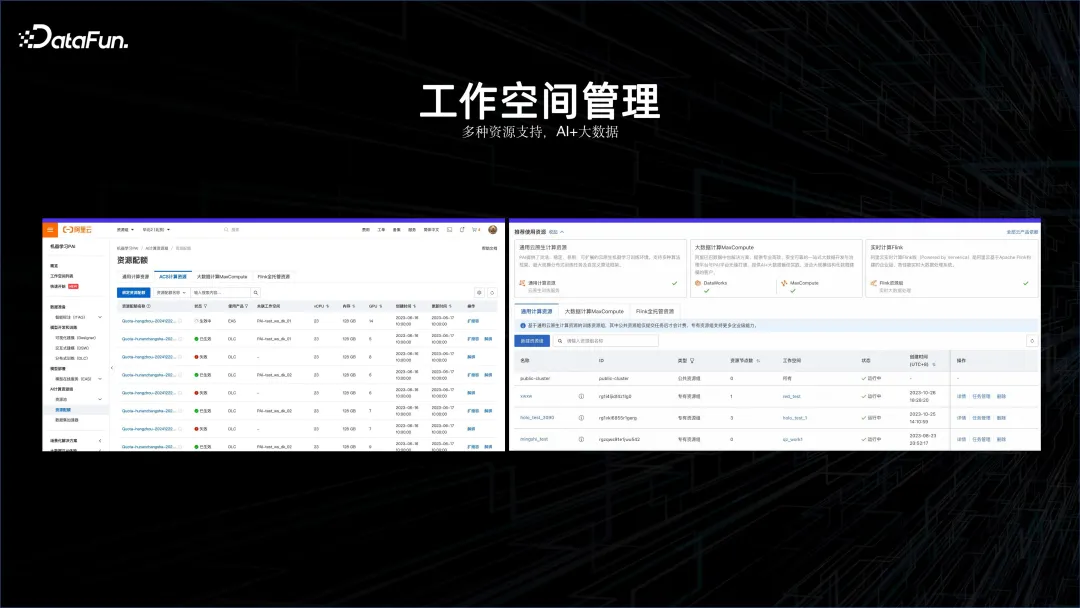
Dans cet espace de travail d'IA, il prend en charge les clusters Flink, le cluster informatique hors ligne MaxCompute, les plateformes d'IA, les plateformes informatiques de services de conteneurs, etc.
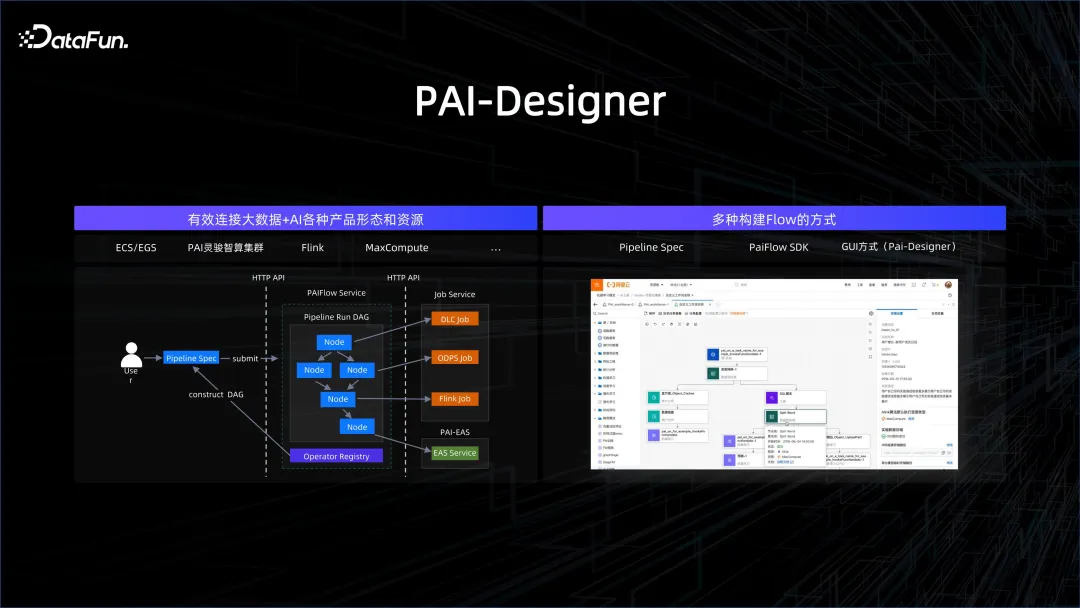
Unifier la gestion du Big Data et de l'IA n'est que la première étape. Le plus important est de les connecter dans un workflow. Les flux de travail peuvent être établis de plusieurs manières, telles que SDK, graphiques, interface graphique, écriture SPEC, etc. Les nœuds du flux de travail peuvent être des nœuds de traitement de Big Data ou des nœuds de traitement d'IA, afin que les processus complexes puissent être bien connectés.
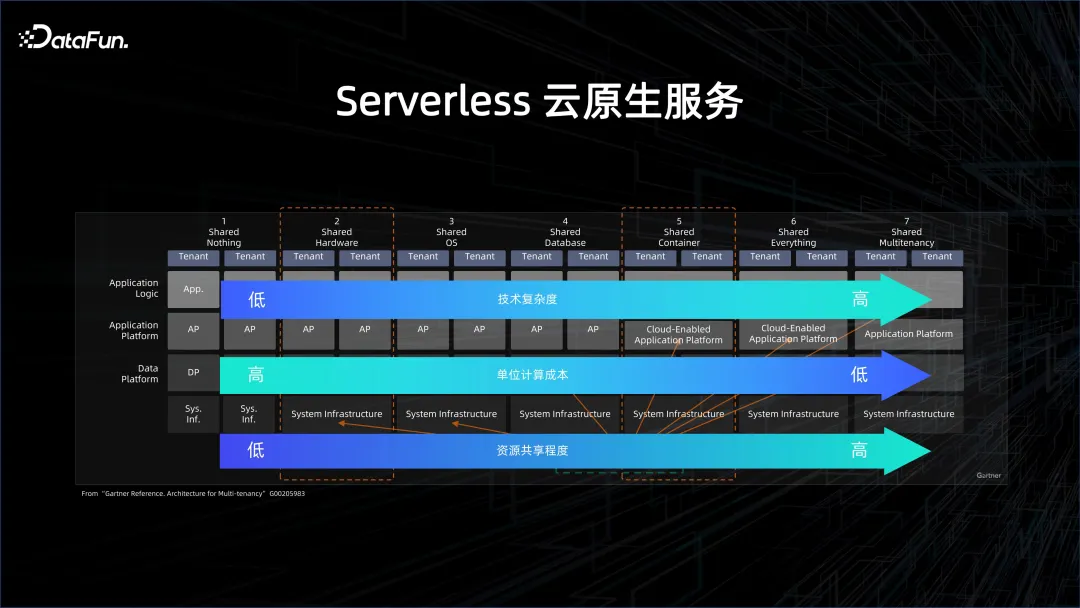
Pour améliorer encore l'efficacité et réduire les coûts, des services cloud natifs sans serveur sont nécessaires. Ce qu'est Severless est décrit en détail dans l'image ci-dessus. Le cloud natif a de nombreux niveaux différents, de ne rien partager (approche non cloud) à tout partager (approche très cloud). Plus le niveau est élevé, plus le degré de partage des ressources est élevé, plus le coût unitaire de calcul est faible, mais plus la pression sur le système est forte.

Le domaine du Big Data et des bases de données a lentement commencé à évoluer vers le sans serveur au cours des deux dernières années, également sur la base de considérations de coûts. À l’origine, même les serveurs utilisés sur le cloud, comme les bases de données sur le cloud, existaient sous forme d’instanciations. Derrière ces instances se cachent les ombres des ressources, telles que le nombre de processeurs et de cœurs dont dispose cette instance. Se transformant lentement et progressivement en Serverless, le premier niveau est l'informatique à locataire unique, qui fait référence à la mise en place d'un cluster sur le cloud, puis au déploiement de plateformes de big data ou de bases de données dans celui-ci. Mais ce cluster est à locataire unique, c'est-à-dire qu'il partage la machine physique avec d'autres personnes. La machine physique est virtualisée en une machine virtuelle, qui est utilisée pour créer une plate-forme Big Data. C'est ce qu'on appelle l'informatique à locataire unique. le stockage des locataires, ainsi que la gestion et le contrôle d'un seul locataire. Ce que les utilisateurs obtiennent, c'est une machine ECS élastique sur le cloud, mais les solutions de gestion et d'exploitation et de maintenance du Big Data doivent être réalisées par eux-mêmes. Le DME est une solution classique à cet égard.
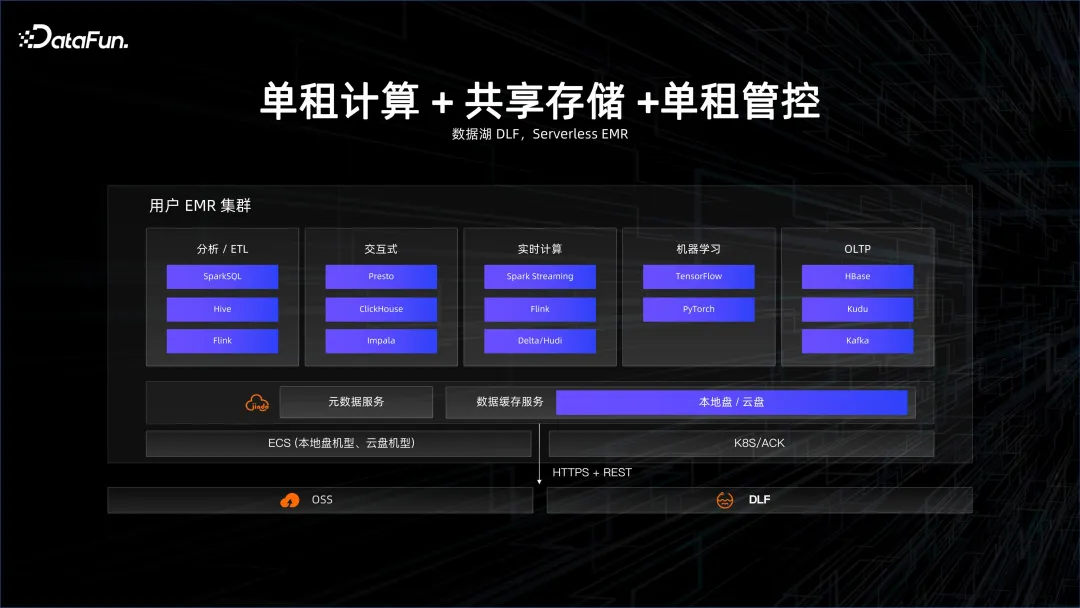
passera lentement du stockage à locataire unique au stockage partagé, qui est la solution du lac de données. Les données se trouvent dans un système Big Data plus partagé. Le calcul consiste à extraire dynamiquement un cluster. Une fois le calcul terminé, le cluster mourra, mais les données ne mourront pas car elles se trouvent du côté du stockage d'une télécommande fiable. . Il s'agit d'un stockage partagé. Les solutions typiques sont les solutions DLF de lac de données et les solutions EMR sans serveur.

La chose la plus extrême est Partager tout. Si vous utilisez BigQuery ou MaxCompute d'Alibaba Cloud, ce que vous verrez est une plate-forme qui gère certains projets virtualisés. L'utilisateur fournit une requête et la plate-forme utilise la requête. Comptage de facturation.

Cela peut apporter de nombreux avantages. Par exemple, il existe de nombreux nœuds dans les calculs Big Data et ne nécessitent pas de code utilisateur, car ces nœuds sont en fait des opérateurs intégrés, tels que la jointure et l'agrégateur. Ces résultats déterministes ne nécessitent pas un bac à sable relativement lourd car ils sont déterministes. opérateurs qui ont été rigoureusement testés et ne contiennent aucun code malveillant ou code UDF arbitraire, ils peuvent éliminer la surcharge de la virtualisation.
L'avantage de l'UDF est la flexibilité, qui nous permet de traiter des données riches et a une bonne évolutivité lorsque la quantité de données est importante. Mais l’un des défis que posera l’UDF est le besoin de sécurité et d’isolement.
BigQuery et MaxComputer de Google sont tous deux basés sur l'architecture de partage de tout. Nous pensons que ce n'est qu'avec l'amélioration continue de la technologie que les ressources peuvent être utilisées plus étroitement, que les coûts de puissance de calcul peuvent être économisés et que davantage de puissance de calcul peut être économisée. les entreprises peuvent se permettre de consommer ces données, favorisant ainsi leur utilisation dans la formation des modèles.
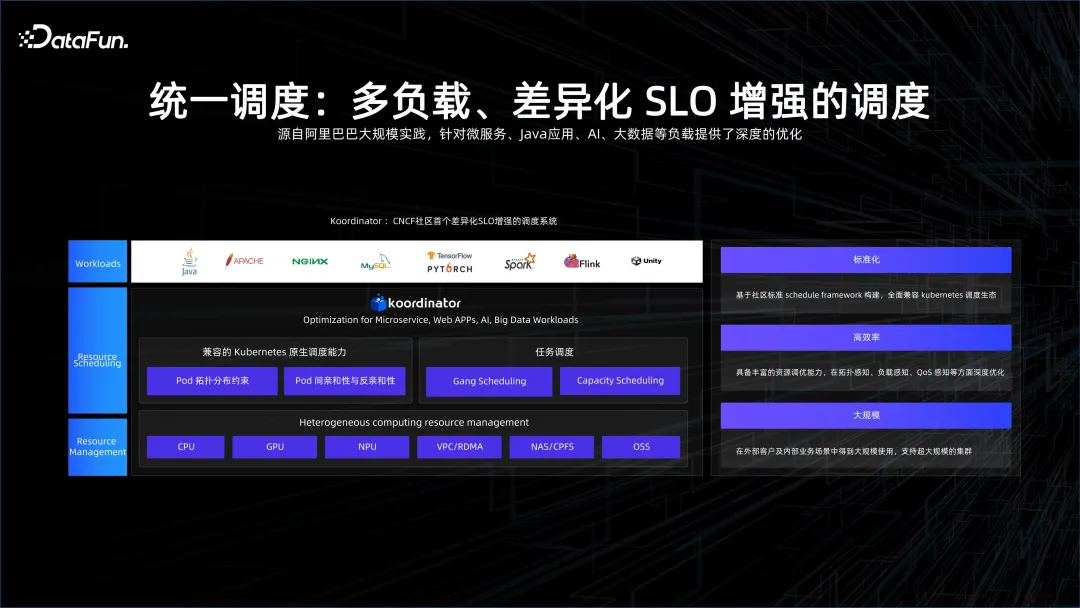
C'est précisément grâce au partage de tout que nous pouvons non seulement gérer le Big Data et l'IA de manière unifiée à travers l'espace de travail, les connecter via PAI-flow, mais également effectuer une planification unifiée de manière à tout partager . De cette manière, les coûts de recherche et développement de l'IA d'entreprise + du big data seront encore réduits.
À ce stade, il y a beaucoup de travail à faire. La planification du K8S lui-même est orientée vers les microservices, qui seront confrontés à de grands défis pour le Big Data, car la granularité de la planification des services du Big Data est très faible et de nombreuses tâches ne survivront que de quelques secondes à des dizaines de secondes. augmenter de plusieurs ordres de grandeur. Nous devons principalement trouver comment étendre cette capacité de planification sur K8S. Le projet open source Koordinator que nous avons lancé vise à améliorer la capacité de planification et à intégrer le Big Data et l'IA dans l'écosystème K8S.

Une autre tâche importante est l'isolement sécuritaire de plusieurs locataires. Comment implémenter la multi-location dans la couche de service et la couche de contrôle de K8S, et comment implémenter la multi-location sur le réseau, afin que plusieurs utilisateurs puissent être servis sur un K8S et que les données et les ressources de chaque utilisateur puissent être efficacement isolé.
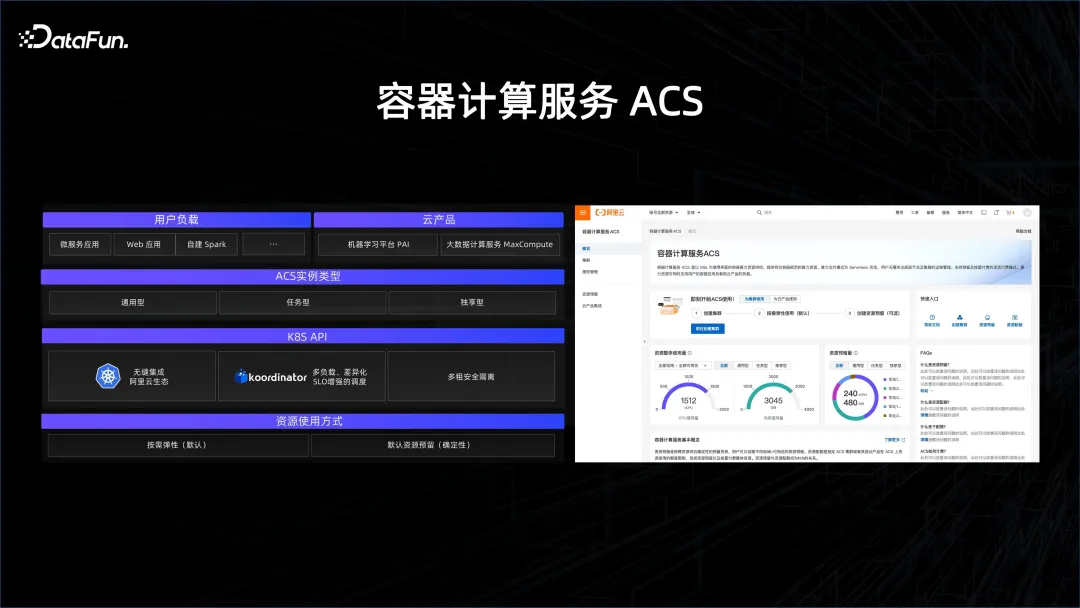
Alibaba a lancé un service de conteneur appelé ACS, qui utilise les deux technologies introduites précédemment pour exposer toutes les ressources via la conteneurisation, permettant aux utilisateurs d'utiliser de manière transparente la plate-forme Big Data et la plate-forme d'IA. Il s'agit d'une méthode multi-tenant et peut répondre aux besoins du Big Data. Les exigences de planification du Big Data sont plusieurs fois supérieures à celles des microservices et de l’IA, et doivent être bien exécutées. Sur cette base, les produits ACS peuvent aider les clients à bien gérer leurs ressources.
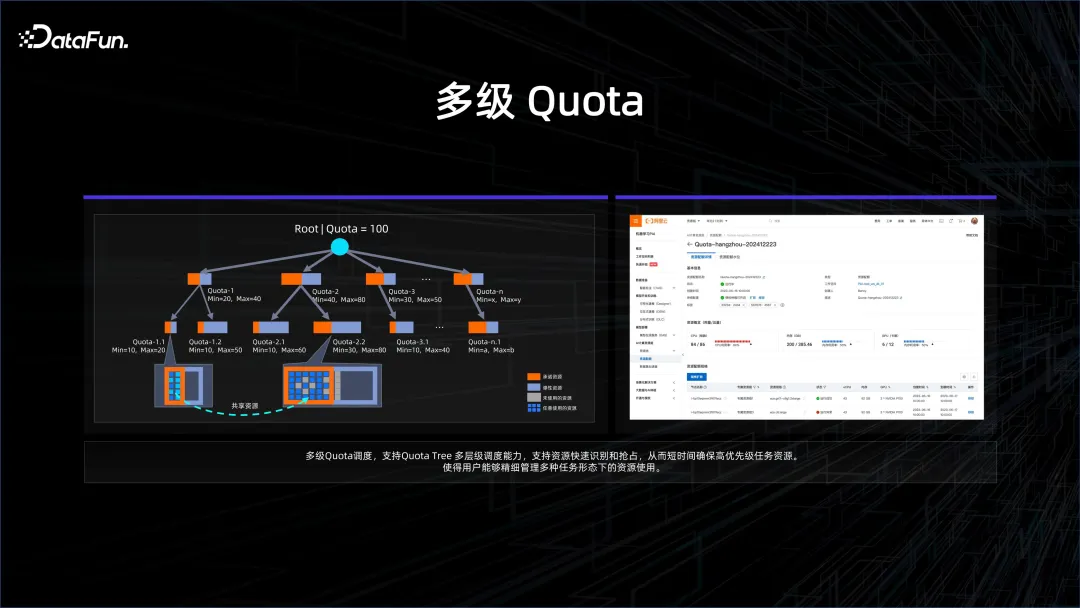
Les entreprises sont confrontées à de nombreuses demandes et doivent gérer leurs ressources avec plus de soin. Par exemple, une entreprise est divisée en plusieurs départements et sous-équipes. Lors de la construction d’un grand modèle, les ressources seront divisées en plusieurs directions pour voir dans quels scénarios ce modèle de base peut être bien utilisé. Mais à un moment donné, j'espère me concentrer sur de grandes choses et mettre en commun toute la puissance de calcul et les ressources pour former la prochaine itération du modèle de base. Afin de résoudre ce problème, nous avons introduit une gestion des quotas à plusieurs niveaux, ce qui signifie que lorsque des tâches avec des exigences plus élevées arrivent, il peut y avoir un niveau supérieur pour fusionner et consolider tous les sous-quotas ci-dessous.
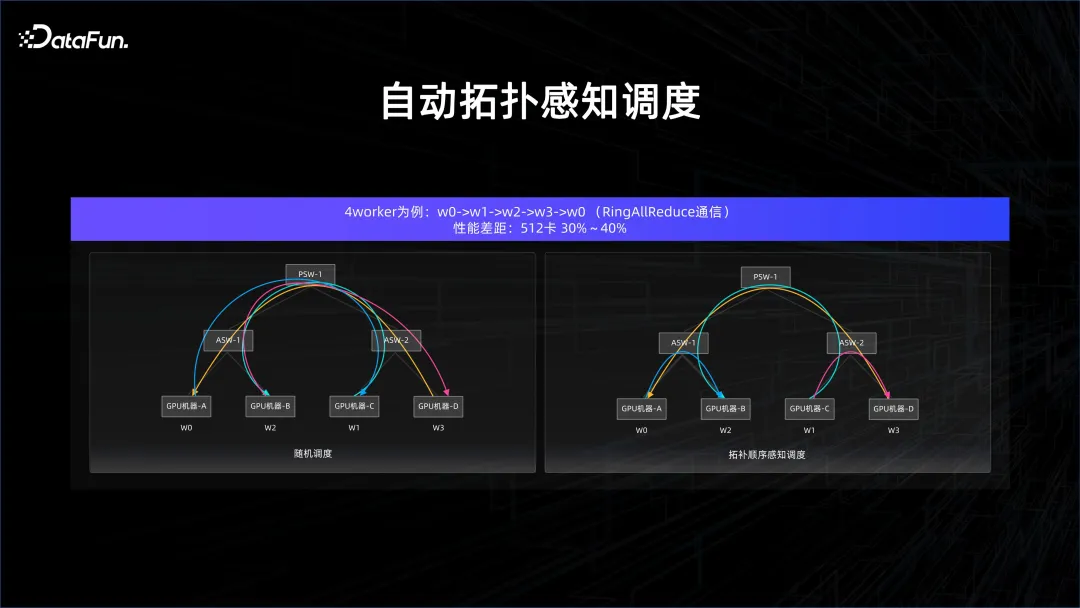
En fait, il existe de nombreuses particularités dans le scénario de l'IA. Dans de nombreux cas, un calcul synchrone est requis, et le calcul synchrone est très sensible au retard, et la densité de calcul de l'IA est élevée, ce qui nécessite un réseau. très haut. Si vous souhaitez garantir la puissance de calcul, vous devez fournir des données et échanger des informations sur les gradients, et lorsque le modèle est parallèle, davantage de choses seront échangées. Dans ces cas, afin de garantir l’absence de problèmes de communication, une planification tenant compte de la topologie est nécessaire.
Par exemple, dans le lien All Reduction de la formation du modèle, si une planification aléatoire est effectuée, il y aura beaucoup de connexions de commutateurs entre ports, mais si l'ordre est soigneusement contrôlé, alors les connexions de commutateurs entre ports seront très propre, donc le délai sera Il peut être bien garanti car aucun conflit ne se produira dans le commutateur de couche supérieure.
Après ces optimisations, les performances peuvent être grandement améliorées. Comment transférer ces planifications tenant compte de la topologie au gestionnaire de l'ensemble de la plateforme est également une question qui doit être prise en compte lorsque l'IA augmente la gestion de la plateforme de données.
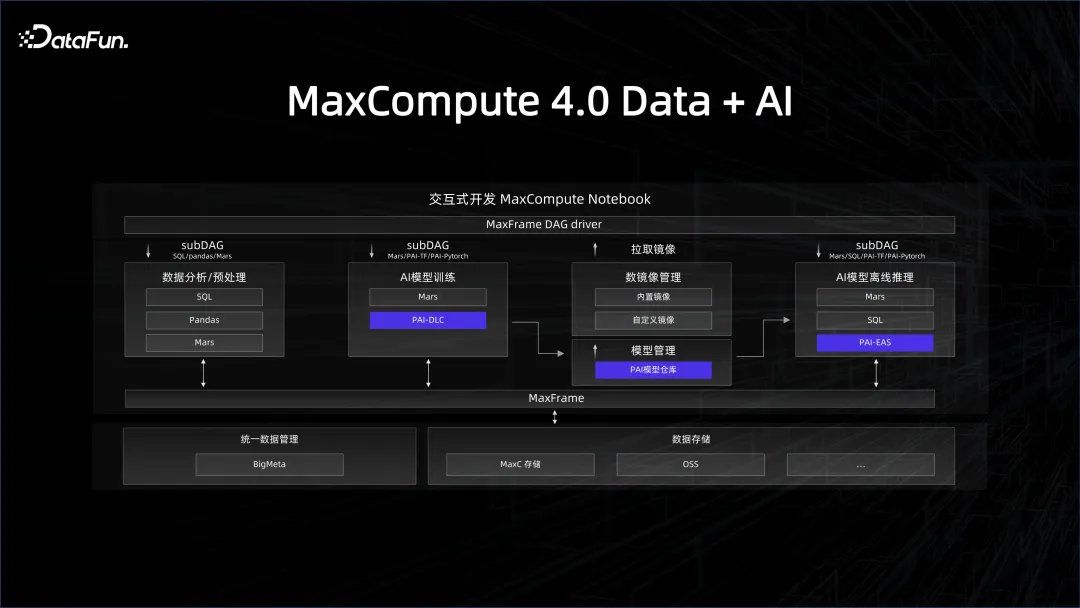
Ce que nous avons introduit plus tôt, c'est la gestion des ressources et des plateformes. La gestion des données est également cruciale. Ce sur quoi nous avons travaillé, c'est le système d'entrepôt de données, comme la gouvernance des données, la qualité des données, etc. Pour associer le système de données au système d'IA, l'entrepôt de données doit fournir une liaison de données conviviale pour l'IA. Par exemple, dans le processus de développement de l'IA, l'écosystème Python est utilisé. Comment le côté données peut-il utiliser cette plate-forme via un SDK Python. La bibliothèque la plus populaire de Python est une structure de données de trame de données similaire à celle des pandas. Nous pouvons intégrer le côté client du moteur Big Data dans une interface pandas, afin que tous les développeurs d'IA familiers avec Python puissent bien l'utiliser. . C'est également la philosophie derrière le framework MaxFrame que nous avons lancé sur MaxCompute cette année.
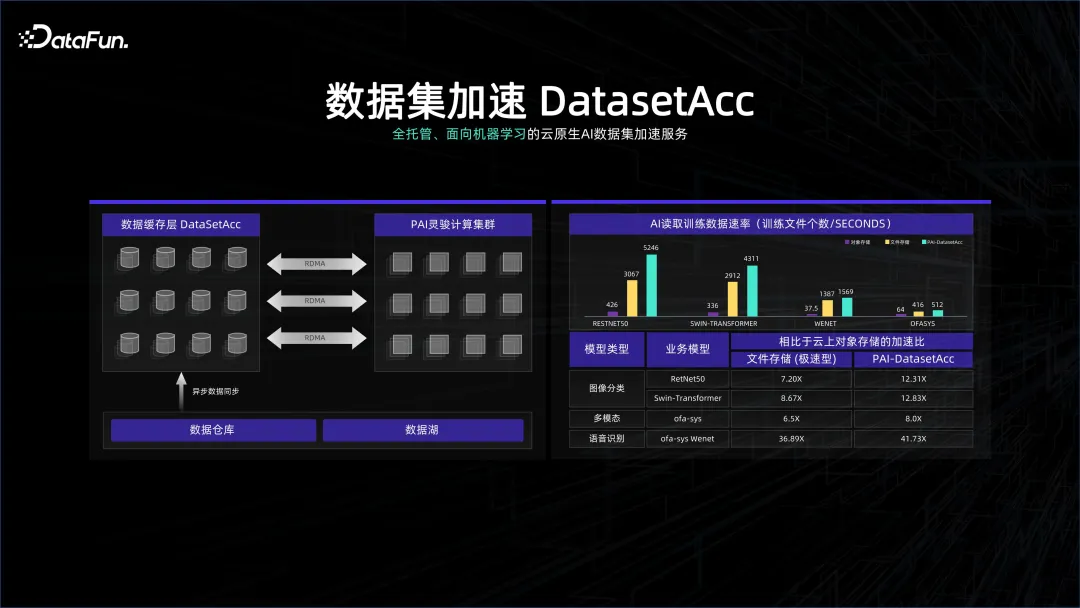
Dans de nombreux cas, les systèmes de traitement de données sont très sensibles au coût. Parfois, des systèmes de stockage à plus haute densité sont utilisés pour stocker les systèmes d'entrepôt de données. Cependant, afin de ne pas gaspiller ce système, de nombreux GPU y sont déployés. système de stockage Le cluster est très gourmand en réseau et en GPU, et les deux systèmes sont susceptibles d'être séparés du stockage et du calcul. Notre système de données peut être orienté vers la gouvernance et la gestion, tandis que le système informatique peut être orienté vers le calcul. Bien que les deux soient sous la gestion d'un K8S, afin d'éviter d'attendre les données pendant le calcul. ont créé l'accélération des ensembles de données DataSetAcc est en fait un cache de données qui se connecte de manière transparente aux données des nœuds de stockage distants, aidant les ingénieurs en algorithmes à extraire les données vers la mémoire locale ou le SSD en arrière-plan pour les calculs.
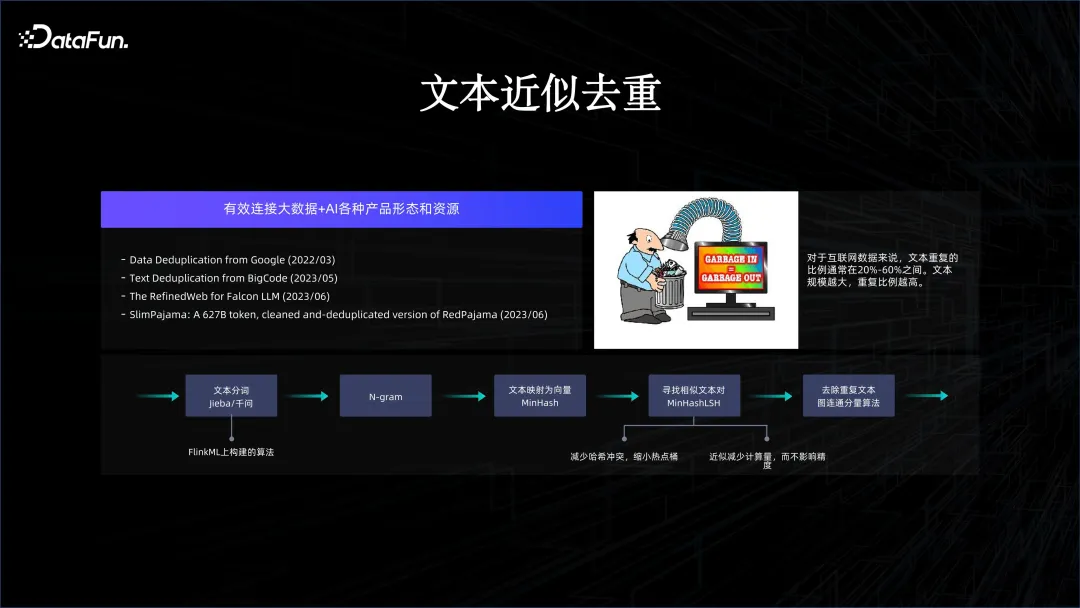
Grâce aux méthodes ci-dessus, les plateformes d'IA et de Big Data peuvent être combinées de manière organique, afin que nous puissions réaliser quelques innovations. Par exemple, lors de la prise en charge de la formation de modèles pour de nombreuses séries de signification générale, de nombreuses données doivent être nettoyées, car les données Internet comportent de nombreuses duplications. Il est donc essentiel de savoir comment dédupliquer les données via un système Big Data. C'est précisément parce que nous avons combiné de manière organique les deux systèmes qu'il est facile de nettoyer les données sur la plate-forme Big Data et que les résultats peuvent être immédiatement intégrés à la formation du modèle.

L'article précédent présente principalement comment le Big Data prend en charge la formation de modèles d'IA. D’un autre côté, la technologie de l’IA peut également être utilisée pour faciliter la compréhension des données et évoluer vers un modèle de traitement des données BI + IA.
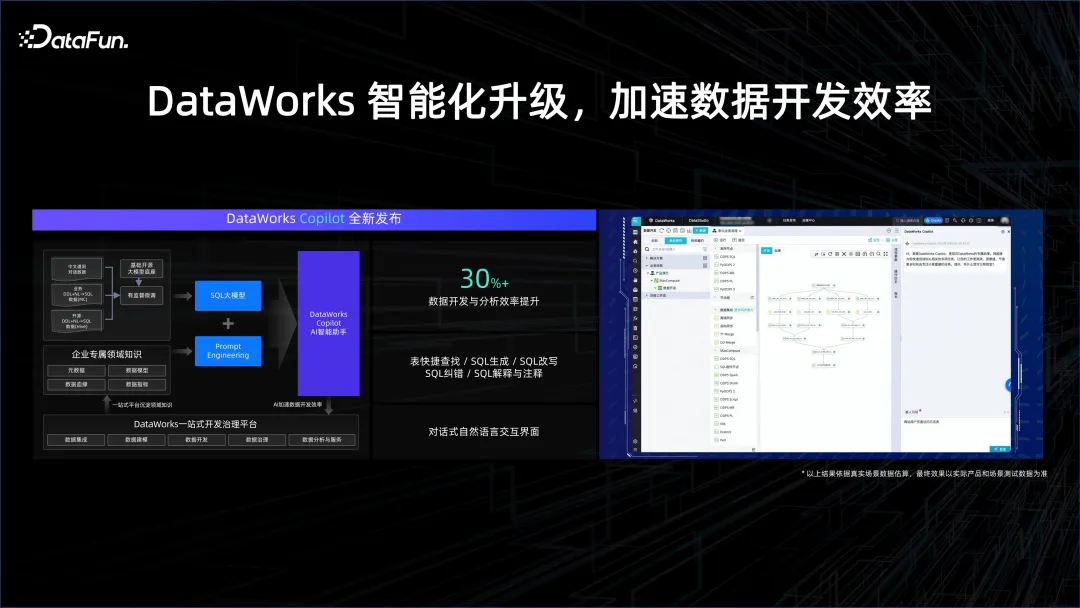
Dans le processus de traitement des données, cela peut aider les analystes de données à créer des analyses plus facilement. À l'origine, ils devaient peut-être écrire du SQL et apprendre à utiliser des outils pour interagir avec le système de données. Cependant, l'ère de l'IA a changé la manière dont l'interaction homme-machine se produit et peut interagir avec les systèmes de données via le langage naturel. Par exemple, l'assistant de programmation Copilot peut aider à générer du SQL et à compléter diverses étapes du processus de développement de données, améliorant ainsi considérablement l'efficacité du développement.

De plus, l'analyse des données peut également être réalisée grâce à l'IA. Par exemple, une donnée, le nombre de clés uniques et la méthode adaptée à la visualisation peuvent tous être obtenus à l’aide de l’IA. L'IA peut observer et comprendre les données sous différents angles, réaliser une exploration automatique des données, une requête de données intelligente, la génération de graphiques et la génération en un clic de rapports d'analyse, etc. Il s'agit d'un service d'analyse intelligent.
IV. Résumé
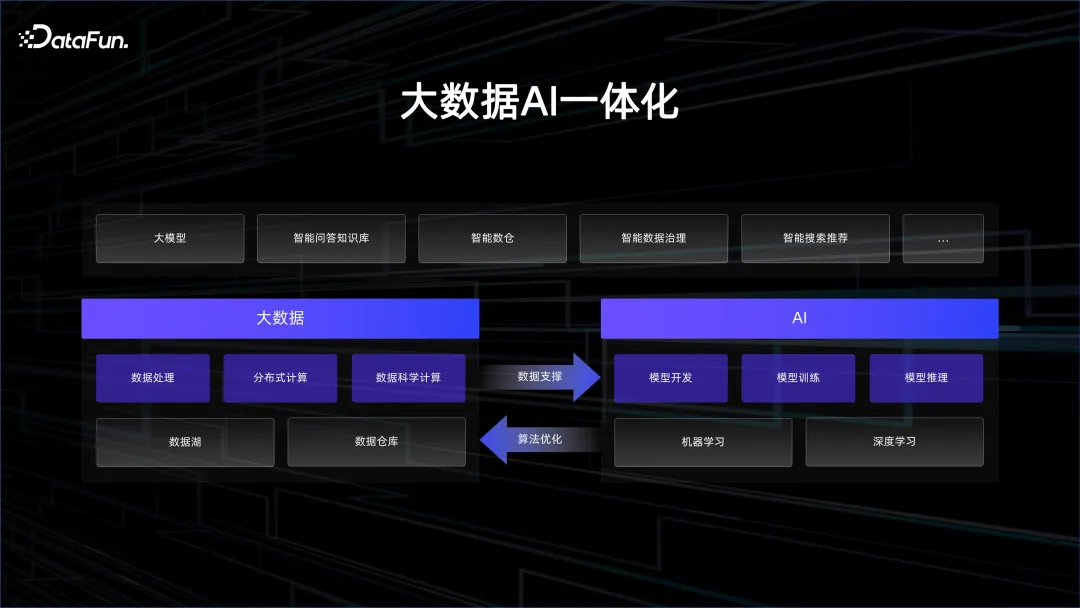
Poussés par le big data et l'IA, des développements technologiques très gratifiants ont eu lieu ces dernières années. Pour rester invincible dans cette tendance, il est nécessaire de relier le big data et l'IA. Ce n'est que lorsque les deux se complètent que nous pourrons obtenir une meilleure accélération des itérations de l'IA et une meilleure compréhension des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 iPhone 16 Pro et iPhone 16 Pro Max officiels avec de nouveaux appareils photo, un SoC A18 Pro et des écrans plus grands
Sep 10, 2024 am 06:50 AM
iPhone 16 Pro et iPhone 16 Pro Max officiels avec de nouveaux appareils photo, un SoC A18 Pro et des écrans plus grands
Sep 10, 2024 am 06:50 AM
Apple a enfin dévoilé ses nouveaux modèles d'iPhone haut de gamme. L'iPhone 16 Pro et l'iPhone 16 Pro Max sont désormais dotés d'écrans plus grands que leurs homologues de dernière génération (6,3 pouces sur le Pro, 6,9 pouces sur le Pro Max). Ils obtiennent un Apple A1 amélioré
 Le verrouillage d'activation des pièces d'iPhone repéré dans iOS 18 RC — pourrait être le dernier coup porté par Apple au droit de réparation vendu sous couvert de protection des utilisateurs
Sep 14, 2024 am 06:29 AM
Le verrouillage d'activation des pièces d'iPhone repéré dans iOS 18 RC — pourrait être le dernier coup porté par Apple au droit de réparation vendu sous couvert de protection des utilisateurs
Sep 14, 2024 am 06:29 AM
Plus tôt cette année, Apple a annoncé qu'elle étendrait sa fonctionnalité de verrouillage d'activation aux composants de l'iPhone. Cela relie efficacement les composants individuels de l'iPhone, tels que la batterie, l'écran, l'assemblage FaceID et le matériel de l'appareil photo, à un compte iCloud.
 Gate.io Trading Platform Office Application Téléchargement et Adresse d'installation
Feb 13, 2025 pm 07:33 PM
Gate.io Trading Platform Office Application Téléchargement et Adresse d'installation
Feb 13, 2025 pm 07:33 PM
Cet article détaille les étapes pour enregistrer et télécharger la dernière application sur le site officiel de Gate.io. Premièrement, le processus d'enregistrement est introduit, notamment le remplissage des informations d'enregistrement, la vérification du numéro de messagerie électronique / téléphone portable et la réalisation de l'enregistrement. Deuxièmement, il explique comment télécharger l'application gate.io sur les appareils iOS et les appareils Android. Enfin, les conseils de sécurité sont soulignés, tels que la vérification de l'authenticité du site officiel, l'activation de la vérification en deux étapes et l'alerte aux risques de phishing pour assurer la sécurité des comptes et des actifs d'utilisateurs.
 Le verrouillage d'activation des pièces d'iPhone pourrait être le dernier coup porté par Apple au droit de réparation vendu sous couvert de protection de l'utilisateur
Sep 13, 2024 pm 06:17 PM
Le verrouillage d'activation des pièces d'iPhone pourrait être le dernier coup porté par Apple au droit de réparation vendu sous couvert de protection de l'utilisateur
Sep 13, 2024 pm 06:17 PM
Plus tôt cette année, Apple a annoncé qu'elle étendrait sa fonctionnalité de verrouillage d'activation aux composants de l'iPhone. Cela relie efficacement les composants individuels de l'iPhone, tels que la batterie, l'écran, l'assemblage FaceID et le matériel de l'appareil photo, à un compte iCloud.
 ANBI App Office Télécharger V2.96.2 Dernière version Installation de la version Android officielle de l'ANBI
Mar 04, 2025 pm 01:06 PM
ANBI App Office Télécharger V2.96.2 Dernière version Installation de la version Android officielle de l'ANBI
Mar 04, 2025 pm 01:06 PM
Les étapes d'installation officielles de l'application Binance: Android doit visiter le site officiel pour trouver le lien de téléchargement, choisissez la version Android pour télécharger et installer; iOS recherche "Binance" sur l'App Store. Tous devraient prêter attention à l'accord par le biais des canaux officiels.
 Plusieurs utilisateurs d'iPhone 16 Pro signalent des problèmes de gel de l'écran tactile, éventuellement liés à la sensibilité au rejet de la paume
Sep 23, 2024 pm 06:18 PM
Plusieurs utilisateurs d'iPhone 16 Pro signalent des problèmes de gel de l'écran tactile, éventuellement liés à la sensibilité au rejet de la paume
Sep 23, 2024 pm 06:18 PM
Si vous avez déjà mis la main sur un appareil de la gamme iPhone 16 d'Apple, plus précisément le 16 Pro/Pro Max, il est probable que vous ayez récemment rencontré un problème avec l'écran tactile. Le bon côté des choses, c'est que vous n'êtes pas seul – rapporte
 Télécharger le lien du package d'installation de la version ouyi iOS
Feb 21, 2025 pm 07:42 PM
Télécharger le lien du package d'installation de la version ouyi iOS
Feb 21, 2025 pm 07:42 PM
OUYI est un échange de crypto-monnaie de pointe avec son application iOS officielle qui offre aux utilisateurs une expérience de gestion des actifs numériques pratique et sécurisée. Les utilisateurs peuvent télécharger gratuitement le package d'installation de la version ouyi iOS via le lien de téléchargement fourni dans cet article, et profiter des principales fonctions suivantes: plateforme de trading pratique: les utilisateurs peuvent facilement acheter et vendre des centaines de crypto-monnaies sur l'application OUYI iOS, y compris Bitcoin et Ethereum . Stockage sûr et fiable: OUYI adopte une technologie de sécurité avancée pour fournir aux utilisateurs un stockage d'actifs numériques sûrs et fiables. 2FA, l'authentification biométrique et d'autres mesures de sécurité garantissent que les actifs des utilisateurs ne sont pas violés. Données de marché en temps réel: l'application OUYI iOS fournit des données et des graphiques de marché en temps réel, permettant aux utilisateurs de saisir le cryptage à tout moment
 Comment résoudre le problème de la 'Erreur du signe de la clé de tableau non définie' lors de l'appel d'alipay easysdk à l'aide de PHP?
Mar 31, 2025 pm 11:51 PM
Comment résoudre le problème de la 'Erreur du signe de la clé de tableau non définie' lors de l'appel d'alipay easysdk à l'aide de PHP?
Mar 31, 2025 pm 11:51 PM
Description du problème Lors de l'appel d'Alipay Easysdk en utilisant PHP, après avoir rempli les paramètres en fonction du code officiel, un message d'erreur a été signalé pendant l'opération: "UNDEFINED ...
