
 Périphériques technologiques
IA
Cadre d'estimation de pose d'objet 6D à échantillon nul SAM-6D, un pas de plus vers l'intelligence incarnée
Périphériques technologiques
IA
Cadre d'estimation de pose d'objet 6D à échantillon nul SAM-6D, un pas de plus vers l'intelligence incarnée
Cadre d'estimation de pose d'objet 6D à échantillon nul SAM-6D, un pas de plus vers l'intelligence incarnée

L'estimation de la pose d'un objet joue un rôle clé dans de nombreuses applications du monde réel, telles que l'intelligence incarnée, la manipulation adroite de robots et la réalité augmentée.
Dans ce domaine, la première tâche à retenir l'attention est Estimation de pose 6D au niveau de l'instance, qui nécessite des données annotées sur l'objet cible pour la formation du modèle, ce qui rend le modèle profond spécifique à l'objet et impossible à transférer vers celui-ci. de nouveaux objets. Plus tard, l'accent de recherche s'est progressivement tourné vers estimation de pose 6D au niveau de la catégorie, qui est utilisée pour traiter des objets invisibles, mais nécessite que l'objet appartienne à une catégorie d'intérêt connue.
Et estimation de pose 6D sans tir est un paramètre de tâche plus général, étant donné un modèle CAO de n'importe quel objet, visant à détecter l'objet cible dans la scène et à estimer sa pose 6D. Malgré son importance, ce paramètre de tâche sans tir est confronté à des défis importants en matière de détection d'objets et d'estimation de pose.

Figure 1. Tâche d'estimation de la pose d'un objet 6D à échantillon nul
Récemment, le modèle de segmentation tout ce qui est SAM [1] a attiré beaucoup d'attention, et son excellente capacité de segmentation à échantillon zéro est accrocheuse. SAM réalise une segmentation de haute précision grâce à divers indices, tels que des pixels, des cadres de délimitation, du texte et des masques, etc., qui fournissent également un support fiable pour la tâche d'estimation de la pose d'objet 6D à échantillon nul, démontrant ainsi son potentiel prometteur.
Par conséquent, des chercheurs de l'Intelligence interdimensionnelle, de l'Université chinoise de Hong Kong (Shenzhen) et de l'Université de technologie de Chine du Sud ont proposé conjointement un cadre innovant d'estimation de la pose d'objet 6D à échantillon zéro, SAM-6D. Cette recherche a été incluse dans le CVPR 2024.

- Lien papier : https://arxiv.org/pdf/2311.15707.pdf
- Lien code : https://github.com/JiehongLin/SAM-6D
SAM-6D réalise une estimation de pose d'objet 6D à échantillon nul en deux étapes, y compris la segmentation d'instance et l'estimation de pose. De manière correspondante, pour tout objet cible, SAM-6D utilise deux sous-réseaux dédiés, à savoir le modèle de segmentation d'instance (ISM) et le modèle d'estimation de pose (PEM) , pour atteindre l'objectif à partir d'images de scène RVB-D où, ISM utilisant SAM ; En tant qu'excellent point de départ, combiné à des scores de correspondance d'objets soigneusement conçus pour réaliser une segmentation d'instance d'objets arbitraires, PEM résout le problème de pose d'objet grâce à un processus de correspondance d'ensembles de points local à local en deux étapes. Un aperçu du SAM-6D est présenté dans la figure 2.
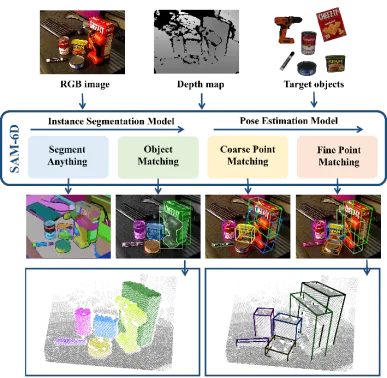
Figure 2. Présentation du SAM-6D
Dans l'ensemble, les contributions techniques du SAM-6D peuvent être résumées comme suit :
- SAM-6D est une pose 6D innovante sans échantillon estimation Le cadre, étant donné un modèle CAO de n'importe quel objet, réalise la segmentation d'instance et l'estimation de pose d'objets cibles à partir d'images RVB-D, et fonctionne parfaitement sur les sept ensembles de données de base de BOP [2].
- SAM-6D exploite la capacité de segmentation sans tir du modèle Segment Everything pour générer tous les candidats possibles et conçoit un nouveau score de correspondance d'objets pour identifier les candidats correspondant aux objets cibles.
- SAM-6D traite l'estimation de pose comme un problème de correspondance d'ensembles de points local à local, adopte une conception de jeton d'arrière-plan simple mais efficace et propose d'abord un modèle de correspondance d'ensembles de points en deux étapes pour les objets arbitraires. une correspondance d'ensemble de points grossière pour obtenir la pose initiale de l'objet, et la deuxième étape utilise un nouveau transformateur d'ensemble de points clairsemé à dense pour effectuer une correspondance d'ensemble de points fine afin d'optimiser davantage la pose.
Modèle de segmentation d'instance (ISM)
SAM-6D utilise le modèle de segmentation d'instance (ISM) pour détecter et segmenter des masques d'objets arbitraires.
Étant donné une scène encombrée représentée par des images RVB, ISM exploite la capacité de transfert zéro-shot du Segmentation Everything Model (SAM) pour générer tous les candidats possibles. Pour chaque objet candidat, ISM calcule un score de correspondance d'objet pour estimer dans quelle mesure il correspond à l'objet cible en termes de sémantique, d'apparence et de géométrie. Enfin, en définissant simplement un seuil de correspondance, les instances correspondant à l'objet cible peuvent être identifiées.
Le score de correspondance d'objet est calculé par la somme pondérée de trois éléments correspondants :
Correspondance sémantique - Pour l'objet cible, ISM restitue les modèles d'objet sous plusieurs perspectives et utilise DINOv2 [3] Le modèle ViT pré-entraîné extrait les caractéristiques sémantiques des objets candidats et des modèles d'objets, et calcule le score de corrélation entre eux. Le score de correspondance sémantique est obtenu en faisant la moyenne des K scores les plus élevés, et le modèle d'objet correspondant au score de corrélation le plus élevé est considéré comme le meilleur modèle de correspondance.
Correspondance d'apparence - Pour le meilleur modèle de correspondance, le modèle ViT est utilisé pour extraire les caractéristiques du bloc d'image et calculer la corrélation entre celle-ci et les caractéristiques du bloc de l'objet candidat pour obtenir le score de correspondance d'apparence, qui est utilisé pour distinguer sémantiquement des objets similaires mais d'apparence différente.
Correspondance géométrique - En tenant compte de facteurs tels que les différences de forme et de taille de différents objets, ISM a également conçu un score de correspondance géométrique. La moyenne de la rotation correspondant au modèle le mieux adapté et au nuage de points de l'objet candidat peut donner une pose d'objet approximative, et le cadre de délimitation peut être obtenu en transformant et en projetant de manière rigide le modèle CAO d'objet à l'aide de cette pose. Le calcul du rapport d'intersection sur union (IoU) entre le cadre englobant et le cadre englobant candidat peut obtenir le score de correspondance géométrique.
Modèle d'estimation de pose (PEM)
Pour chaque objet candidat qui correspond à l'objet cible, SAM-6D utilise un modèle d'estimation de pose (PEM) pour prédire sa pose 6D par rapport au modèle CAO de l'objet.
Désignons les ensembles de points d'échantillonnage des objets candidats segmentés et des modèles CAO d'objets comme 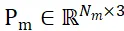 et
et 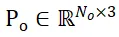 respectivement, où N_m et N_o représentent le nombre de leurs points en même temps, les caractéristiques de ces deux ensembles de points ; sont exprimés par
respectivement, où N_m et N_o représentent le nombre de leurs points en même temps, les caractéristiques de ces deux ensembles de points ; sont exprimés par 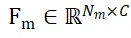 et
et 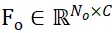 , C représente le nombre de canaux de la fonctionnalité. L'objectif de PEM est d'obtenir une matrice d'affectation qui représente la correspondance locale à locale de P_m à P_o ; en raison de l'occlusion, P_o ne correspond que partiellement à P_m, et en raison de l'imprécision de la segmentation et du bruit du capteur, P_m ne correspond que partiellement aux correspondances ET partielles. P_o.
, C représente le nombre de canaux de la fonctionnalité. L'objectif de PEM est d'obtenir une matrice d'affectation qui représente la correspondance locale à locale de P_m à P_o ; en raison de l'occlusion, P_o ne correspond que partiellement à P_m, et en raison de l'imprécision de la segmentation et du bruit du capteur, P_m ne correspond que partiellement aux correspondances ET partielles. P_o.
Afin de résoudre le problème de l'attribution de points qui ne se chevauchent pas entre deux ensembles de points, ISM les équipe de jetons d'arrière-plan, enregistrés sous les noms 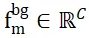 et
et 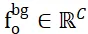 , qui peuvent établir efficacement une correspondance locale à locale basée sur similitude des caractéristiques. Plus précisément, la matrice d'attention peut être calculée d'abord comme suit :
, qui peuvent établir efficacement une correspondance locale à locale basée sur similitude des caractéristiques. Plus précisément, la matrice d'attention peut être calculée d'abord comme suit :
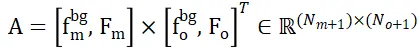
Ensuite, la matrice de distribution
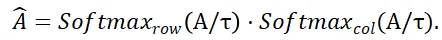
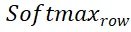 et
et 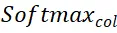 représentent respectivement l'opération softmax le long des lignes et des colonnes,
représentent respectivement l'opération softmax le long des lignes et des colonnes, 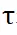 représente une constante. La valeur de chaque ligne de
représente une constante. La valeur de chaque ligne de 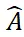 (sauf la première ligne) représente la probabilité de correspondance de chaque point P_m dans l'ensemble de points P_m avec l'arrière-plan et le point médian de P_o. En localisant l'indice du score maximum, le point correspondant à P_m. peut être trouvé (y compris l'arrière-plan).
(sauf la première ligne) représente la probabilité de correspondance de chaque point P_m dans l'ensemble de points P_m avec l'arrière-plan et le point médian de P_o. En localisant l'indice du score maximum, le point correspondant à P_m. peut être trouvé (y compris l'arrière-plan).
Une fois 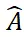 calculé, toutes les paires de points correspondantes {(P_m,P_o)} et leurs scores correspondants peuvent être rassemblés, et enfin le SVD pondéré est utilisé pour calculer la pose de l'objet.
calculé, toutes les paires de points correspondantes {(P_m,P_o)} et leurs scores correspondants peuvent être rassemblés, et enfin le SVD pondéré est utilisé pour calculer la pose de l'objet.
Figure 3. Diagramme schématique du modèle d'estimation de pose (PEM) dans SAM-6D
À l'aide de la stratégie basée sur les jetons d'arrière-plan ci-dessus, deux étapes de correspondance d'ensembles de points sont conçues dans PEM, et son modèle La structure est comme le montre la figure Comme le montre la figure 3, elle contient trois modules : extraction de fonctionnalités, correspondance d'ensembles de points grossiers et correspondance d'ensembles de points fins.
Le module de correspondance d'ensemble de points approximatifs implémente une correspondance clairsemée pour calculer la pose initiale de l'objet, puis utilise cette pose pour transformer l'ensemble de points de l'objet candidat afin d'obtenir un apprentissage du codage de position.
Le module de correspondance d'ensembles de points fins combine le codage de position des ensembles de points d'échantillonnage de l'objet candidat et de l'objet cible, injectant ainsi la correspondance approximative dans la première étape et établissant davantage une correspondance dense pour obtenir une pose d'objet plus précise. Afin d'apprendre efficacement les interactions denses à ce stade, PEM introduit un nouveau transformateur d'ensemble de points clairsemé à dense, qui implémente des interactions sur des versions clairsemées de fonctionnalités denses et utilise le transformateur linéaire [5] pour transformer les fonctionnalités clairsemées améliorées en retour de diffusion. en traits denses.
Résultats expérimentaux
Pour les deux sous-modèles de SAM-6D, le modèle de segmentation d'instance (ISM) est construit sur la base de SAM sans nécessiter de recyclage et de réglage du réseau, tandis que le modèle d'estimation de pose (PEM) Les ensembles de données synthétiques à grande échelle ShapeNet-Objects et Google-Scanned-Objects fournis par MegaPose [4] sont utilisés pour la formation.
Pour vérifier sa capacité à échantillon zéro, SAM-6D a été testé sur sept ensembles de données de base de BOP [2], notamment LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB et YCB. -V. Les tableaux 1 et 2 montrent respectivement la comparaison de la segmentation des instances et les résultats de l'estimation de pose de différentes méthodes sur ces sept ensembles de données. Comparé à d’autres méthodes, SAM-6D fonctionne très bien sur les deux méthodes, démontrant pleinement sa forte capacité de généralisation.
Tableau 1. Comparaison des résultats de segmentation d'instance de différentes méthodes sur les sept ensembles de données de base de BOP
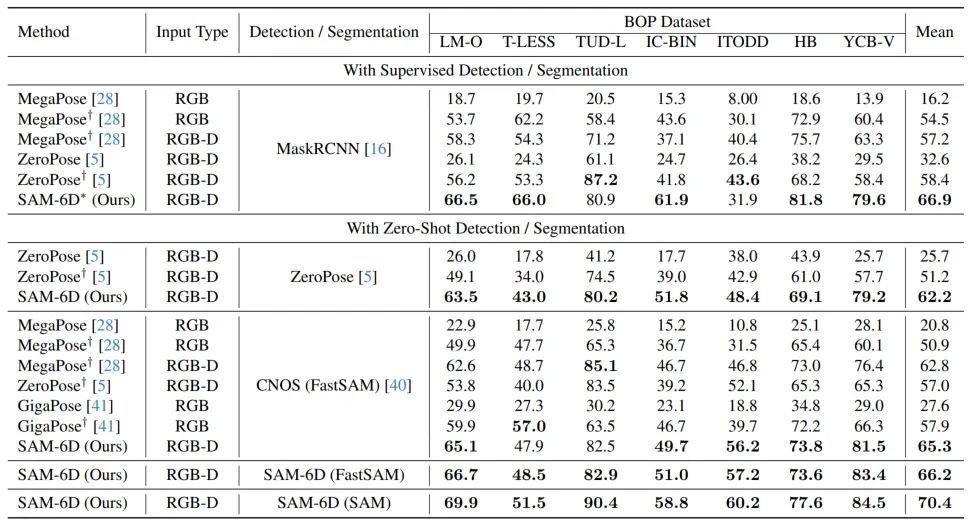
Tableau 2. Comparaison des résultats d'estimation de pose de différentes méthodes sur les sept ensembles de données de base de BOP
La figure 4 montre les résultats de visualisation de la segmentation de détection et de l'estimation de pose 6D de SAM-6D sur sept ensembles de données BOP, où (a) et (b) sont respectivement les images RVB et les cartes de profondeur testées, (c) est un objet cible donné, tandis que (d) et (e) sont respectivement les résultats de visualisation de la segmentation de détection et de la pose 6D.

Figure 4. Résultats de visualisation de SAM-6D sur les sept ensembles de données de base de BOP.
Pour plus de détails sur la mise en œuvre de SAM-6D, n'hésitez pas à lire l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
