
 Périphériques technologiques
IA
La version 3D de Sora arrive-t-elle ? UMass, MIT et d'autres proposent des modèles du monde en 3D et les robots intelligents incarnés franchissent de nouvelles étapes
Périphériques technologiques
IA
La version 3D de Sora arrive-t-elle ? UMass, MIT et d'autres proposent des modèles du monde en 3D et les robots intelligents incarnés franchissent de nouvelles étapes
La version 3D de Sora arrive-t-elle ? UMass, MIT et d'autres proposent des modèles du monde en 3D et les robots intelligents incarnés franchissent de nouvelles étapes

Dans des recherches récentes, l'entrée du modèle vision-langage-action (VLA, vision-langage-action) est essentiellement des données 2D, sans intégrer le monde physique 3D plus général.
De plus, les modèles existants effectuent des prédictions d'actions en apprenant la « cartographie directe des actions perçues », ignorant la dynamique du monde et la relation entre les actions et la dynamique.
En revanche, lorsque les humains réfléchissent, ils introduisent des modèles du monde, qui peuvent décrire leur imagination de scénarios futurs et planifier leurs prochaines actions.
À cette fin, des chercheurs de l'Université du Massachusetts Amherst, du MIT et d'autres institutions ont proposé le modèle 3D-VLA en introduisant une nouvelle classe de modèles de fondation incarnés, il peut être basé sur le modèle mondial généré. raisonnement et action. 
Page d'accueil du projet : https://vis-www.cs.umass.edu/3dvla/
Adresse papier : https://arxiv.org/abs/2403.09631
Plus précisément, 3D-VLA est construit sur un grand modèle de langage (LLM) basé sur la 3D et introduit un ensemble de jetons d'interaction pour participer à des environnements incarnés.
L'équipe de Qianchuang a formé une série de modèles de diffusion incorporés, injecté des capacités génératives dans les modèles et les a alignés dans LLM pour prédire les images cibles et les nuages de points.
Afin d'entraîner le modèle 3D-VLA, nous avons extrait une grande quantité d'informations liées à la 3D de l'ensemble de données de robot existant et construit un énorme ensemble de données d'instructions incarnées en 3D.
Les résultats de recherche montrent que le 3D-VLA fonctionne bien dans la gestion des tâches de raisonnement, de génération multimodale et de planification dans des environnements incarnés, ce qui met en évidence sa valeur d'application potentielle dans des scénarios réels.
Ensemble de données de réglage des instructions incorporées en 3D
En raison des milliards d'ensembles de données sur Internet, VLM a démontré d'excellentes performances dans plusieurs tâches et des millions de données d'action vidéo. L'ensemble pose également les bases d'un VLM concret pour le contrôle des robots .
Cependant, la plupart des ensembles de données actuels ne peuvent pas fournir une profondeur suffisante, des annotations 3D et un contrôle précis pour les opérations robotiques. Cela nécessite que l'ensemble de données contienne un raisonnement spatial et un contenu d'interaction 3D. Le manque d'informations 3D rend difficile pour les robots de comprendre et d'exécuter des instructions qui nécessitent un raisonnement spatial 3D, telles que « Mettez la tasse la plus éloignée dans le tiroir du milieu ».

Pour combler cette lacune, les chercheurs ont construit un ensemble de données de réglage des instructions 3D à grande échelle, qui fournit suffisamment d'« informations liées à la 3D » et d'« instructions textuelles correspondantes » pour entraîner le modèle.
Les chercheurs ont conçu un pipeline pour extraire des paires d'actions de langage 3D à partir d'ensembles de données incorporées existantes, obtenant ainsi des annotations de nuages de points, des cartes de profondeur, des cadres de délimitation 3D, des actions 7D du robot et des descriptions textuelles.
Modèle de base 3D-VLA
3D-VLA est un modèle mondial utilisé pour le raisonnement tridimensionnel, la génération de cibles et la prise de décision dans un environnement incarné.
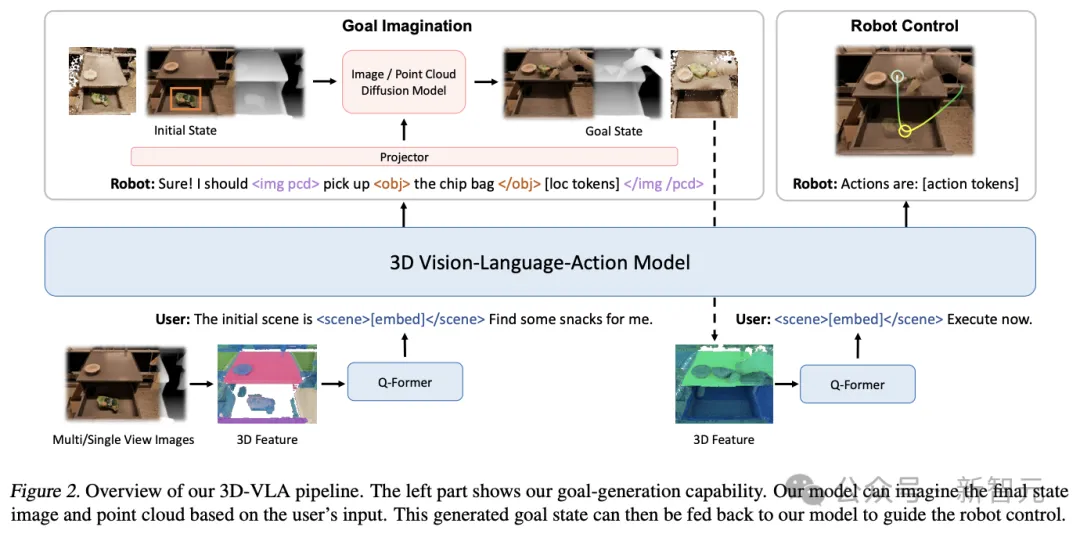
Construisez d'abord le réseau principal au-dessus de 3D-LLM, puis améliorez davantage la capacité du modèle à interagir avec le monde 3D en ajoutant une série de jetons d'interaction, puis pré-entraînez le modèle de diffusion et utilisez la projection pour ; aligner le LLM et le modèle de diffusion, en injectant des capacités de génération de cibles dans le 3D-VLA
backbone network
Dans la première étape, les chercheurs ont suivi la méthode 3D-LLM pour développer le modèle de base 3D-VLA : depuis le l'ensemble de données collecté n'a pas atteint L'échelle d'un milliard requise pour former un LLM multimodal à partir de zéro nécessite l'utilisation de fonctionnalités multi-vues pour générer des fonctionnalités de scène 3D afin que les fonctionnalités visuelles puissent être intégrées de manière transparente dans le VLM pré-entraîné sans avoir besoin pour l'adaptation.
Dans le même temps, l'ensemble de données d'entraînement de 3D-LLM comprend principalement des objets et des scènes d'intérieur, qui ne sont pas directement cohérents avec les paramètres spécifiques, les chercheurs ont donc choisi d'utiliser BLIP2-PlanT5XL comme modèle de pré-entraînement.
Pendant le processus de formation, débloquez les intégrations d'entrée et de sortie des jetons ainsi que les poids de Q-Former.
Jetons d'interaction
Afin d'améliorer la compréhension du modèle des scènes 3D et de l'interaction dans l'environnement, les chercheurs ont introduit un nouvel ensemble de jetons d'interaction
Tout d'abord, des jetons d'objet ont été ajoutés à l'entrée, y compris des noms d'objet dans des phrases analysées (telles que < ; obj> une barre de chocolat [loc tokens] sur la table) afin que le modèle puisse mieux capturer les objets manipulés ou mentionnés.
Deuxièmement, afin de mieux exprimer les informations spatiales dans le langage, les chercheurs ont conçu un ensemble de jetons de position
Troisièmement, afin de mieux effectuer l'encodage dynamique,
L'architecture est encore améliorée en étendant l'ensemble de marqueurs spécialisés représentant les actions du robot. L'action du robot a 7 degrés de liberté. Des jetons discrets tels que
Injecter des capacités de génération d'objectifs
Les humains peuvent pré-visualiser l'état final de la scène pour améliorer la précision de la prédiction des actions ou de la prise de décision, ce qui est également un aspect clé de la construction d'un modèle mondial ; Lors des expériences préliminaires, les chercheurs ont également découvert que fournir des états finaux réalistes peut améliorer les capacités de raisonnement et de planification du modèle.
Mais entraîner MLLM à générer des images, de la profondeur et des nuages de points n'est pas simple :
Tout d'abord, le modèle de diffusion vidéo n'est pas fait sur mesure pour les scènes incarnées, comme Runway, pour générer de futures images de "open tiroir" , des problèmes tels que des changements de vue, une déformation d'objet, un remplacement de texture étrange et une distorsion de mise en page se produiront dans la scène.
Et comment intégrer des modèles de diffusion de différents modes dans un seul modèle de base reste un problème difficile.
Ainsi, le nouveau cadre proposé par les chercheurs pré-entraîne d'abord le modèle de diffusion spécifique basé sur différentes formes telles que les images, la profondeur et les nuages de points, puis aligne le décodeur du modèle de diffusion sur l'espace d'intégration du 3D-VLA. en phase d'alignement.

Résultats expérimentaux
3D-VLA est un modèle mondial génératif polyvalent basé sur la 3D qui peut effectuer un raisonnement et une localisation dans le monde 3D, imaginer un contenu cible multimodal et générer des opérations de robot Action, chercheurs a principalement évalué le 3D-VLA sous trois aspects : le raisonnement et la localisation 3D, la génération de cibles multimodales et la planification d'action incarnée.
Inférence et localisation 3D
3D-VLA surpasse toutes les méthodes VLM 2D sur les tâches de raisonnement linguistique, ce que les chercheurs attribuent à l'exploitation des informations 3D, qui fournissent des informations spatiales de raisonnement plus précises.
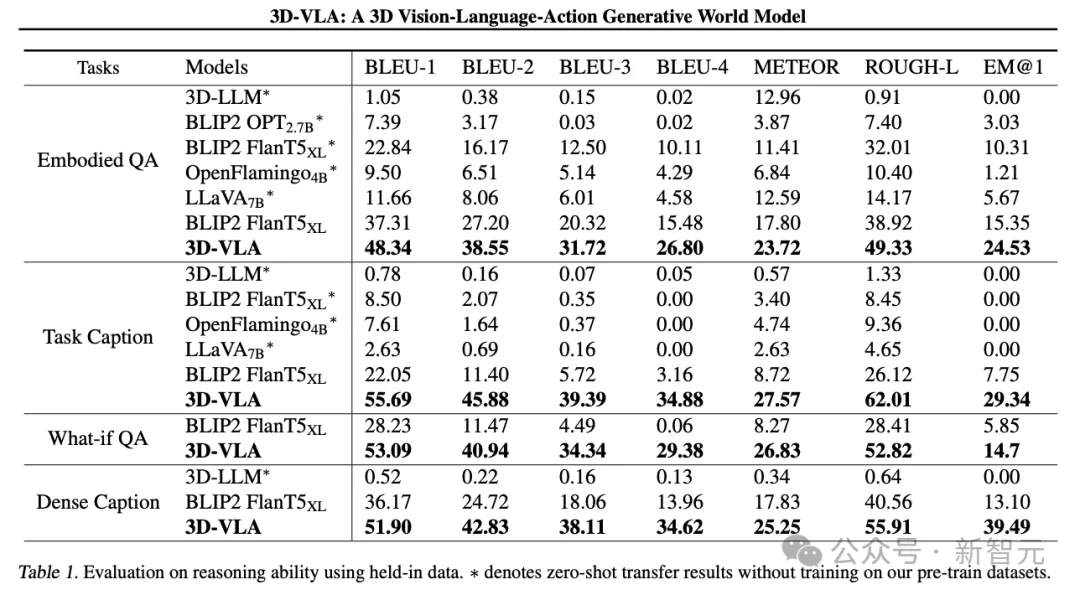
De plus, puisque l'ensemble de données contient un ensemble d'annotations de positionnement 3D, 3D-VLA apprend à localiser les objets pertinents, aidant ainsi le modèle à se concentrer davantage sur les objets clés pour le raisonnement.
Les chercheurs ont découvert que le 3D-LLM fonctionnait mal sur ces tâches d'inférence robotique, démontrant la nécessité de collecter et de former des ensembles de données 3D liés à la robotique.
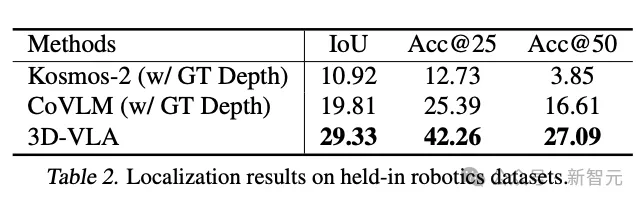
Et 3D-VLA a obtenu des résultats nettement meilleurs que la méthode de base 2D en termes de performances de localisation. Cette découverte fournit également des preuves convaincantes de l'efficacité du processus d'annotation, aidant le modèle à obtenir de puissantes capacités de positionnement 3D.
Génération de cibles multimodales
Par rapport aux méthodes de génération existantes pour le transfert zéro-shot vers le domaine de la robotique, 3D-VLA atteint de meilleures performances dans la plupart des métriques, confirmant l'utilisation de "spécialement conçus pour les applications robotiques". concevoir des ensembles de données pour former des modèles mondiaux.
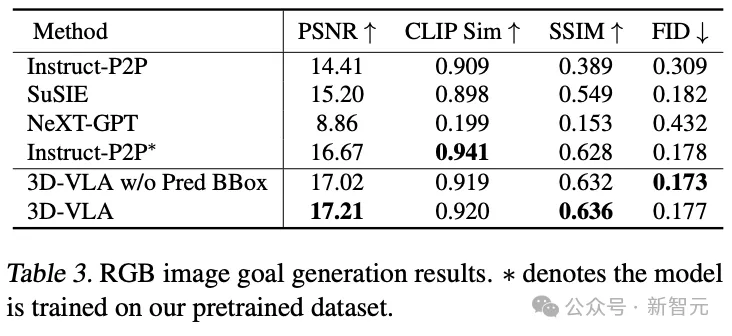
Même en comparaison directe avec Instruct-P2P*, 3D-VLA fonctionne systématiquement mieux, et les résultats montrent que l'intégration de grands modèles de langage dans 3D-VLA permet une compréhension plus complète et plus approfondie des instructions de fonctionnement du robot, améliorant ainsi les performances de génération d’images cibles.
De plus, lors de l'exclusion des cadres de délimitation prédits de l'invite de saisie, une légère diminution des performances peut être observée, confirmant l'efficacité de l'utilisation des cadres de délimitation prédits intermédiaires, qui peuvent aider le modèle à comprendre la scène entière, permettant au modèle d'incorporer une plus grande attention est accordée aux objets spécifiques mentionnés dans une instruction donnée, améliorant finalement sa capacité à imaginer l'image cible finale.
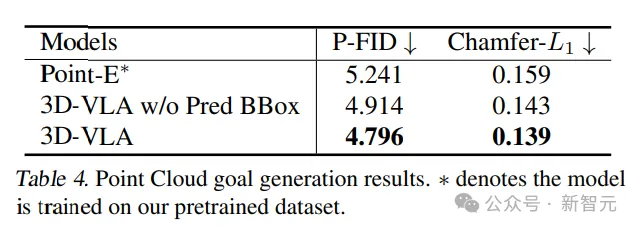
Dans une comparaison des résultats générés à partir de nuages de points, le 3D-VLA avec des cadres de délimitation prédits intermédiaires a donné les meilleurs résultats, confirmant l'importance de combiner de grands modèles de langage et une localisation précise des objets dans le contexte de la compréhension des instructions et des scènes.
Planification d'action incorporée
3D-VLA dépasse les performances du modèle de base dans la plupart des tâches de prédiction d'action RLBench, montrant ses capacités de planification.
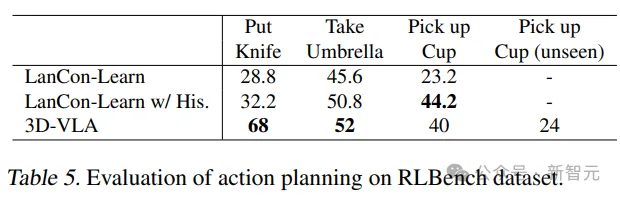
Il convient de noter que le modèle de base nécessite l'utilisation d'observations historiques, de l'état de l'objet et des informations sur l'état actuel, tandis que le modèle 3D-VLA ne s'exécute que via un contrôle en boucle ouverte.
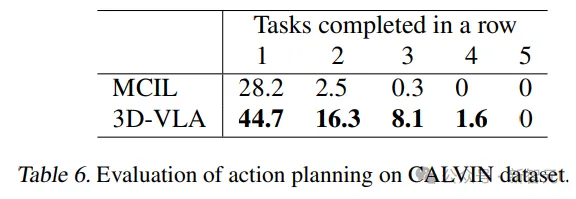
De plus, la capacité de généralisation du modèle a également été prouvée dans la tâche de ramassage de gobelets. Les chercheurs ont également obtenu de bons résultats dans CALVIN. d'intérêt et imaginer des états d'objectif, fournit des informations riches pour déduire des actions.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
