

Les pannes d'équipement posent de graves problèmes au secteur industriel, entraînant des pertes de production et des temps d'arrêt imprévus. Cette situation représente un défi de taille pour les fabricants de procédés du monde entier, entraînant des pertes pouvant atteindre des milliards de dollars par an. Par exemple, si un équipement de production clé tombe en panne soudainement, cela peut entraîner l’arrêt de toute la chaîne de production pendant plusieurs heures, affectant ainsi le fonctionnement de l’ensemble de la chaîne d’approvisionnement.

Heureusement, l'apprentissage automatique (ML) moderne offre une solution révolutionnaire. En analysant de grandes quantités de données de capteurs, les algorithmes de ML peuvent prédire les pannes et les retards avant qu'ils ne surviennent, permettant ainsi des réparations proactives et réduisant considérablement les temps d'arrêt. Mais ce n’est pas tout : le ML révèle également des modèles cachés dans les données de production, optimisant les processus, réduisant les déchets et améliorant l’efficacité globale.
Avant que les organisations puissent réaliser tout le potentiel de l’apprentissage automatique, elles doivent d’abord commencer à renforcer les éléments fondamentaux de la collaboration en équipe. Pour créer des modèles précis et percutants, les data scientists et les experts du domaine doivent développer des collaborations étroites et une compréhension approfondie des complexités des équipements industriels. Leur collaboration traduira l’expertise de l’atelier dans le langage des données, favorisant ainsi l’application réussie de solutions d’apprentissage automatique.
Utiliser les informations du ML pour améliorer l'efficacité opérationnelle ne peut pas être réalisé du jour au lendemain. Le premier défi consiste à donner du sens aux données industrielles brutes.
Dans leur format natif, les données industrielles sont massives, diverses et souvent remplies d'informations erronées ou non pertinentes, comme les journaux de pannes. Sans conseils, les data scientists perdent souvent un temps et des ressources précieux à passer au crible une complexité non pertinente, perdent un temps précieux et produisent souvent des modèles trompeurs. C'est pourquoi les experts du domaine, notamment les ingénieurs de procédés et les opérateurs, jouent un rôle essentiel dans la préparation des données pour des modèles précis. Leur connaissance approfondie des processus permet de déterminer les données correctes et les périodes pertinentes.
Cependant, identifier les bonnes données n’est que la première étape. Les données industrielles brutes sont souvent compliquées et nécessitent un contexte pour être comprises. Imaginez avoir un modèle où les relevés de température pendant la maintenance sont mélangés aux relevés de température pendant les opérations : cela plongerait un modèle prédictif dans le chaos. Insérer des données dans un modèle sans indice peut faire des ravages, suggérant que lors de l'analyse, l'importance du nettoyage et de la contextualisation des données ! préalablement. Les experts en processus peuvent aider à identifier ces considérations, à réduire les erreurs d’algorithme, à garantir la cohérence et à identifier les conditions de fonctionnement spécifiques les plus importantes pour le succès du modèle.
Une fois les données nettoyées, il reste encore beaucoup de travail à faire pour les préparer au ML. L'ingénierie des fonctionnalités comble cette lacune et nécessite la collaboration continue de scientifiques des données et d'experts en processus pour transformer les lectures brutes en informations contextuelles qui résolvent directement le problème en question. Ces informations, ou « signatures », incluent des résumés statistiques, des modèles de fréquence et d'autres combinaisons intelligentes de données de capteurs qui aident les algorithmes de ML à découvrir des modèles cachés, à améliorer la précision des modèles et à prendre des décisions opérationnelles complexes.
Le déploiement de modèles ML dans des environnements industriels nécessite plus qu'une simple précision. Pour véritablement générer de la valeur, les modèles doivent être facilement transférables aux opérateurs pour être utilisés dans le processus de production. Cela signifie que l’interface doit être facile à lire et présenter les prévisions, les alertes et les données en temps réel de manière claire et concise. De plus, lorsque cela est possible, l'inclusion d'explications dans l'interface opérationnelle renforce la confiance et la compréhension entre les utilisateurs finaux.
Les processus industriels évoluent avec le temps, c'est pourquoi le déploiement réussi du machine learning nécessite que les modèles soient régulièrement recyclés avec de nouvelles données pour garantir leur précision. Cela nécessite une collaboration étroite entre les data scientists et les équipes opérationnelles pour surveiller les performances et itérer en permanence sur les modèles.
Les nombreuses étapes de création et de mise en œuvre de modèles de ML dans les flux de travail opérationnels ne sont pas faciles, mais les solutions d'analyse avancée modernes rationalisent le processus, fournissant une solution holistique pour l'intégration du ML dans les processus industriels.
Ces solutions éliminent l'encombrement des données industrielles courantes en connectant plusieurs sources de données en temps réel. En plus de l'agrégation, ces outils logiciels peuvent automatiser le nettoyage des données, éliminant ainsi de nombreux traitements et rapprochements manuels des données (Figure 1).
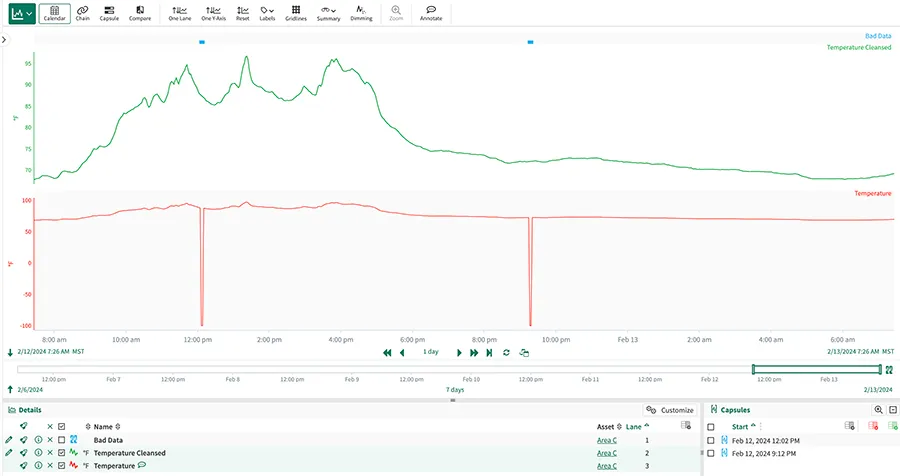
Figure 1 : Seeq automatise le nettoyage des données à l'aide d'une gamme de méthodes de lissage intégrées pour fournir une image contextualisée des performances de l'usine. Par exemple, deux relevés de température erronés sont automatiquement supprimés des variables de processus purifiées, qui sont utilisées pour la modélisation et la création d'informations sur les processus.
Cette adaptabilité est essentielle lorsque les processus changent, car elle maintient les modèles ML à jour et fournit des informations pertinentes pour refléter les conditions de fonctionnement actuelles. Par exemple, dans les scénarios de défaillance de la bande transporteuse, les solutions d'analyse avancées permettent aux ingénieurs d'identifier rapidement les anomalies, de gérer les incohérences et d'extraire immédiatement des informations significatives. Ces données de haute qualité peuvent ensuite éclairer les étapes de dépannage, fournir des informations exploitables sur le ML et accroître la confiance dans les décisions opérationnelles.
L'ingénierie des fonctionnalités est essentielle au succès de l'apprentissage automatique en milieu industriel, mais elle nécessite une collaboration. Les solutions d'analyse avancées contribuent à faciliter cette synergie nécessaire grâce à des profils d'utilisateurs clairement sélectionnés, conçus pour différents rôles d'experts, ainsi qu'aux outils nécessaires pour partager de manière transparente les résultats entre les équipes opérationnelles (Figure 2).
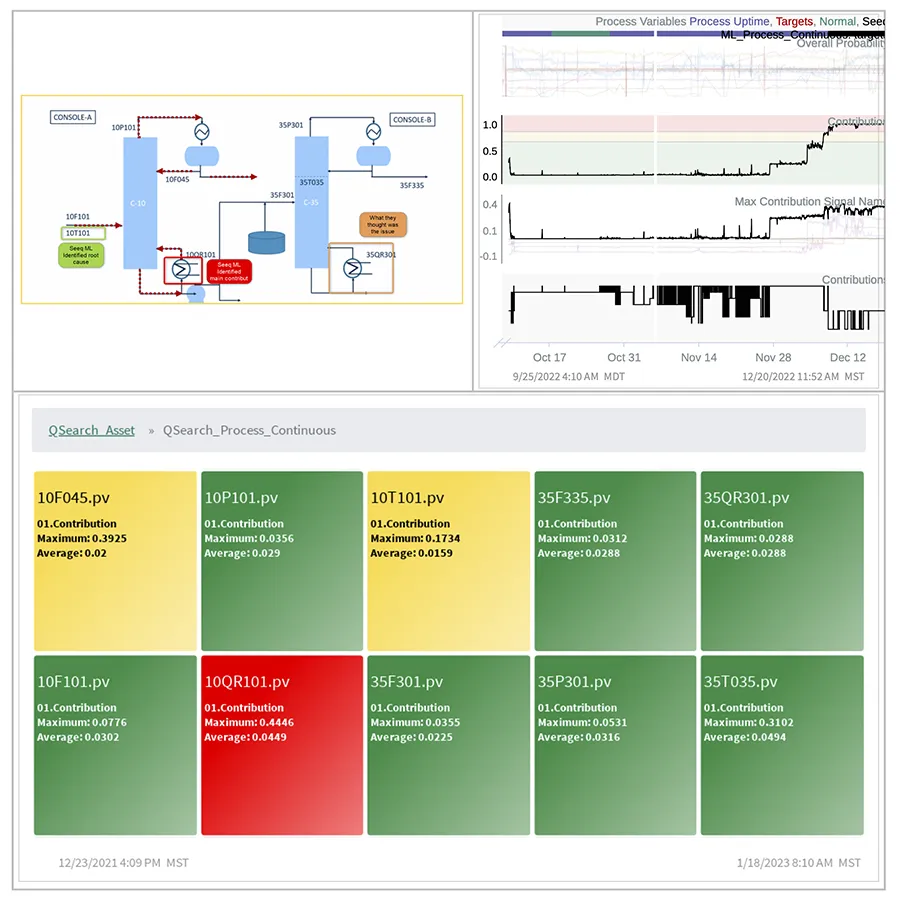
Figure 2 : Seeq facilite la création de rapports et de tableaux de bord automatisés où les ingénieurs et les data scientists peuvent partager leurs analyses avec les équipes métiers et opérationnelles, en mettant en œuvre le ML pour générer de la valeur quotidienne.
Par exemple, le Data Lab de Seeq permet aux data scientists de déployer facilement des modèles destinés à une utilisation directe par les équipes d'ingénierie et d'exploitation, qui peuvent fournir des commentaires pour aider à améliorer les modèles. Les prédictions et les alertes sont ensuite transférées vers Workbench, Organizer et des outils de visualisation externes, qui sont généralement accessibles aux utilisateurs administratifs. Les solutions d'analyse avancée relient ces départements historiquement séparés, transformant les modèles en outils puissants qui permettent un contrôle plus strict des processus, une optimisation opérationnelle et une prise de décision plus intelligente dans l'ensemble de l'organisation.
Des résultats réels montrent que les solutions d'analyse avancées peuvent réduire efficacement les temps d'arrêt coûteux. Par exemple, un grand fabricant de produits chimiques en proie à des pannes inattendues de compresseurs critiques a utilisé la solution Seeq pour identifier les écarts subtils des compresseurs d'un cycle de fonctionnement à l'autre. Avec des pertes estimées à 1 million de dollars par incident, trouver un moyen de prédire et de prévenir ces pannes est rapidement devenu une priorité.
L'entreprise a commencé à collecter de grandes quantités de données de processus, mais celles-ci étaient si volumineuses et complexes, avec plus de 170 variables, qu'il était difficile de discerner les véritables modèles à partir du bruit. Les méthodes d'analyse traditionnelles ne peuvent pas identifier la combinaison de facteurs qui ont pu provoquer la défaillance.
Le fabricant s'est tourné vers Seeq, tirant parti des outils ML intégrés au logiciel pour permettre à ses experts du domaine de résoudre les problèmes de développement de modèles sans s'appuyer entièrement sur des data scientists. L'interface conviviale de la solution met la puissance du ML directement entre les mains d'ingénieurs de procédés possédant une expertise complète en matière de compresseurs, contribuant ainsi à combler le fossé de connaissances entre les PME et les data scientists, ce qui est plus difficile à réaliser avec l'analyse traditionnelle. Cela permet de garantir que les modèles prédictifs intègrent la compréhension et l’évolution correctes du domaine.
En tirant parti des capacités spécialement conçues dans les solutions d'analyse avancées, l'entreprise transforme les résultats des modèles en informations opérationnelles en temps quasi réel. Les modèles se concentrent sur les écarts subtils des paramètres du compresseur qui indiquent des problèmes, et les tableaux de bord visuels aident à alerter les équipes d'exploitation et d'ingénierie dès le début pour qu'elles prennent des mesures préventives afin d'éviter des pannes coûteuses. Cette approche prédictive permet aux équipes de transformer la maintenance réactive en une stratégie proactive.
En résolvant les problèmes avant qu’ils ne surviennent, l’entreprise réduit considérablement les temps d’arrêt coûteux. Les solutions d'analyse avancée fournissent non seulement la base technique, mais offrent également une nouvelle fluidité des données, donnant aux ingénieurs un meilleur contrôle sur l'état des équipements.
Les compteurs gelés menacent la rentabilité des fournisseurs de pétrole et de gaz, entraînant des erreurs de mesure et un gaspillage de produits coûteux. L'ampleur du problème est amplifiée par le vaste réseau d'un opérateur, qui s'étend sur 32 000 milles de pipelines et traite 7,4 milliards de pieds cubes de gaz naturel par jour. Les données encombrées et le recours à des approches basées sur des règles pour identifier les événements de gel se sont avérés longs et peu fiables, et la maintenance des règles consommait des ressources précieuses en plus du filtrage de nombreux faux positifs et détections manquées.
L'entreprise avait besoin d'une nouvelle façon de rationaliser le nettoyage et d'accéder à sa vaste quantité de données de compteurs. Les experts du domaine utilisent des outils logiciels pour améliorer la qualité des données et annoter les événements gelés passés, tandis que les data scientists travaillent avec les ingénieurs pour développer des modèles précis, aller au-delà des règles rigides et adopter le ML.
Dans les solutions d'analyse avancée, les opérateurs établissent un flux de travail entièrement automatisé qui comprend le prétraitement des données, la configuration du modèle et le recyclage automatisé pour maintenir la précision du modèle à mesure que les conditions de fonctionnement changent. Les prédictions des modèles alimentent directement les tableaux de bord visuels et les rapports alimentés, fournissant aux parties prenantes des informations en temps réel sur les problèmes potentiels de gel.
Ce flux de travail rationalisé est capable d'intervenir de manière proactive pour atténuer les problèmes de gel, et même s'il y a une légère amélioration de la précision quelque part, il permettra d'économiser des millions de dollars chaque année en réduction des cadeaux de produits. En plus d'améliorer la précision, la solution facilite la collaboration basée sur les données, essentielle à l'amélioration continue de l'efficacité opérationnelle.
Ce travail a apporté trois révélations importantes aux fournisseurs :
Il est indéniable que le machine learning change le processus de fabrication. Sa capacité à automatiser des tâches complexes, à optimiser les cycles de production et à permettre une maintenance prédictive offre des avantages évidents par rapport aux méthodes traditionnelles. Le ML génère des gains d’efficacité et des économies de coûts dans de nombreux secteurs industriels en augmentant la disponibilité des actifs, en augmentant le débit et en améliorant les processus de prise de décision.
Bien que la mise en œuvre du ML comporte ses propres défis, les énormes avantages dépassent de loin les obstacles, et des solutions d'analyse avancées peuvent contribuer à garantir des déploiements réussis. Ces outils logiciels offrent de puissantes capacités d'analyse de données et sont spécifiquement conçus pour répondre aux besoins des données de séries chronologiques et des applications ML dans les environnements industriels. Grâce à des interfaces conviviales et à l'accent mis sur la collaboration, ces solutions permettent aux entreprises d'adopter pleinement les informations basées sur l'apprentissage automatique, offrant ainsi des avantages significatifs en termes d'efficacité et de rentabilité sur un marché manufacturier de plus en plus concurrentiel.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Qu'est-ce qu'un plug-in de navigateur
Qu'est-ce qu'un plug-in de navigateur
 La différence entre l'écran externe et l'écran interne cassé
La différence entre l'écran externe et l'écran interne cassé
 Qu'est-ce que le langage machine
Qu'est-ce que le langage machine
 Sur quelle touche appuyez-vous pour récupérer lorsque votre ordinateur tombe en panne ?
Sur quelle touche appuyez-vous pour récupérer lorsque votre ordinateur tombe en panne ?
 La différence entre les notes de bas de page et les notes de fin
La différence entre les notes de bas de page et les notes de fin
 utilisation du latex
utilisation du latex
 Quelles sont les méthodes de maintenance informatique à distance ?
Quelles sont les méthodes de maintenance informatique à distance ?
 La différence entre le masque de pâte et le masque de soudure
La différence entre le masque de pâte et le masque de soudure








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



