
 Périphériques technologiques
IA
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Périphériques technologiques
IA
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne

Écrit devant et compréhension personnelle de l'auteur
Actuellement, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome conduisant sur la route ne peut obtenir des informations précises que via le module de perception seulement après avoir détecté. les résultats permettent aux modules de régulation et de contrôle en aval du système de conduite autonome de prendre des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises.
L'algorithme de perception BEV basé sur la vision pure a reçu une large attention de la part de l'industrie et du monde universitaire en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval. Ces dernières années, de nombreux algorithmes de perception visuelle basés sur l’espace BEV ont vu le jour les uns après les autres et ont démontré d’excellentes performances de perception sur des ensembles de données publiques.
Actuellement, les algorithmes de perception basés sur l'espace BEV peuvent être grossièrement divisés en deux types de modèles d'algorithmes basés sur la manière de construire les caractéristiques BEV :
- Un type est la méthode de construction de caractéristiques BEV avant représentée par l'algorithme LSS. le modèle d'algorithme de perception est le premier. Le réseau d'estimation de profondeur dans le modèle perceptuel est utilisé pour prédire les informations sur les caractéristiques sémantiques et la distribution de probabilité de profondeur discrète de chaque pixel de la carte de caractéristiques, puis les informations sur les caractéristiques sémantiques obtenues et la probabilité de profondeur discrète sont utilisées pour construire le une caractéristique de tronc sémantique utilisant une opération de regroupement de produits externes et d'autres méthodes sont utilisées pour finalement achever le processus de construction des caractéristiques spatiales BEV.
- L'autre type est la méthode de construction de fonctionnalités BEV inversée représentée par l'algorithme BEVFormer. Ce type de modèle d'algorithme de perception génère d'abord explicitement des points de coordonnées de voxel 3D dans l'espace BEV perçu, puis utilise les paramètres internes et externes de la caméra pour convertir. la 3D Les points de coordonnées voxel sont projetés vers le système de coordonnées de l'image, et les caractéristiques de pixels aux positions de caractéristiques correspondantes sont extraites et agrégées pour construire les caractéristiques BEV dans l'espace BEV.
Bien que les deux algorithmes puissent générer avec précision des caractéristiques dans l'espace BEV et obtenir des résultats de perception 3D, il existe deux problèmes dans les algorithmes actuels de perception de cibles 3D basés sur l'espace BEV, tels que l'algorithme BEVFormer :
- Problème 1 : Depuis l'ensemble Le cadre du modèle d'algorithme de perception BEVFormer adopte la structure de réseau Encoder-Decoder, l'idée principale est d'utiliser le module Encoder pour obtenir les caractéristiques dans l'espace BEV, puis d'utiliser le module Decoder pour prédire le résultat de perception final et comparer la sortie. résultat de la perception avec Le processus de calcul de la perte pour atteindre les caractéristiques spatiales BEV prédites par le modèle. Cependant, la méthode de mise à jour des paramètres de ce modèle de réseau s'appuiera trop sur les performances perceptuelles du module décodeur, ce qui peut conduire au problème selon lequel les caractéristiques BEV produites par le modèle ne sont pas alignées avec la valeur réelle des caractéristiques BEV, limitant ainsi davantage la performance finale du modèle perceptuel.
- Question 2 : Étant donné que le module Decoder du modèle d'algorithme de perception BEVFormer utilise toujours les étapes du module d'auto-attention ->module d'attention croisée->réseau neuronal feedforward dans le Transformer pour terminer la construction de la fonctionnalité de requête et produire le résultat final de la détection. L'ensemble du processus est toujours un modèle de boîte noire, manquant d'une bonne interprétabilité. Dans le même temps, il existe également une grande incertitude dans le processus de correspondance biunivoque entre la requête d'objet et la véritable valeur cible au cours du processus de formation du modèle.
Afin de résoudre les problèmes du modèle d'algorithme de perception BEVFormer, nous l'avons amélioré et proposé un modèle d'algorithme de détection 3D CLIP-BEVFormer basé sur des images surround. En introduisant la méthode d'apprentissage contrastif, nous avons amélioré la capacité du modèle à construire des fonctionnalités BEV et atteint des performances perceptuelles de premier plan sur l'ensemble de données nuScenes.
Lien de l'article : https://arxiv.org/pdf/2403.08919.pdf
Architecture globale et détails du modèle de réseau
Avant d'introduire les détails du modèle d'algorithme de perception CLIP-BEVAncien proposé dans cet article, le La figure suivante montre la structure globale du réseau de l'algorithme CLIP-BEVFormer.
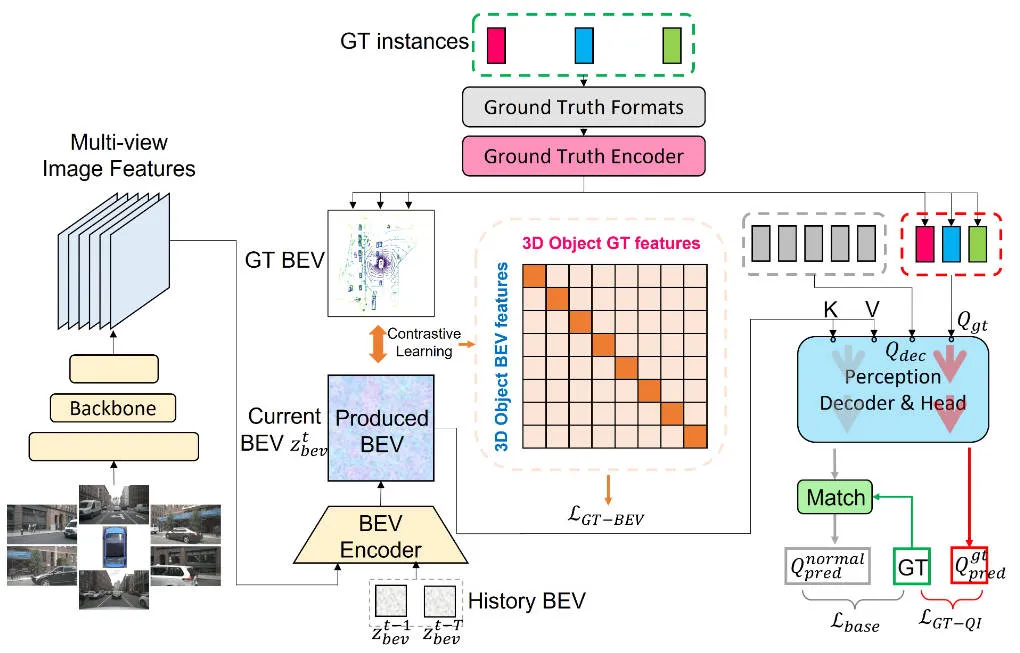 Organigramme général du modèle d'algorithme de perception CLIP-BEVAncien proposé dans cet article
Organigramme général du modèle d'algorithme de perception CLIP-BEVAncien proposé dans cet article
Il ressort de l'organigramme global de l'algorithme que le modèle d'algorithme CLIP-BEVFormer proposé dans cet article est amélioré sur la base du modèle d'algorithme BEVFormer. Voici un bref aperçu du processus de mise en œuvre du modèle d'algorithme de perception BEVFormer. . Premièrement, le modèle d'algorithme BEVFormer entre les données d'image surround collectées par le capteur de la caméra et utilise le réseau d'extraction de caractéristiques d'image 2D pour extraire les informations sur les caractéristiques sémantiques multi-échelles de l'image surround d'entrée. Deuxièmement, le module Encoder contenant l'auto-attention temporelle et l'attention croisée spatiale est utilisé pour compléter le processus de conversion des caractéristiques de l'image 2D en caractéristiques spatiales BEV. Ensuite, un ensemble de requêtes d'objets est généré sous la forme d'une distribution normale dans l'espace de perception 3D et envoyé au module Décodeur pour compléter l'utilisation interactive des caractéristiques spatiales avec les caractéristiques spatiales BEV produites par le module Encodeur. Enfin, le réseau neuronal feedforward est utilisé pour prédire les caractéristiques sémantiques interrogées par Object Query, et les résultats finaux de classification et de régression du modèle de réseau sont générés. Dans le même temps, pendant le processus de formation du modèle d'algorithme BEVFormer, la stratégie d'appariement un-à-un hongrois est utilisée pour compléter le processus de distribution des échantillons positifs et négatifs, et les pertes de classification et de régression sont utilisées pour terminer le processus de mise à jour de les paramètres globaux du modèle de réseau. Le processus de détection global du modèle d'algorithme BEVFormer peut être exprimé par la formule mathématique suivante :
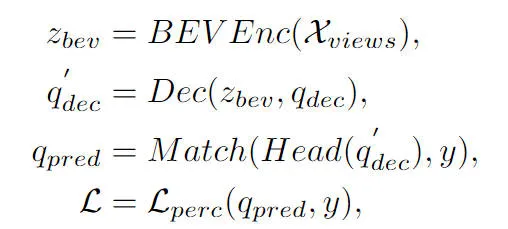
où, dans la formule représente le module d'extraction de fonctionnalités Encoder dans l'algorithme BEVFormer, représente le module de décodage Decoder dans l'algorithme BEVFormer, et représente la vraie valeur dans l'ensemble de données. Étiquette cible de valeur, représentant le résultat de la perception 3D généré par le modèle d'algorithme BEVFormer actuel.
Génération de la vraie valeur BEV
Comme mentionné ci-dessus, la plupart des algorithmes de détection de cibles 3D existants basés sur l'espace BEV ne supervisent pas explicitement les fonctionnalités de l'espace BEV générées, ce qui entraîne que les fonctionnalités BEV de génération de modèle peuvent être incompatibles avec les fonctionnalités BEV réelles. Cette différence de distribution des caractéristiques spatiales BEV limitera les performances perceptuelles finales du modèle. Sur la base de cette considération, nous avons proposé le module Ground Truth BEV. Notre idée principale dans la conception de ce module est de permettre aux fonctionnalités BEV générées par le modèle d'être alignées sur les fonctionnalités BEV de valeur réelle actuelles, améliorant ainsi les performances du modèle.
Plus précisément, comme le montre le diagramme global du cadre de réseau, nous utilisons un encodeur de vérité terrain () pour coder l'étiquette de catégorie et les informations de position du cadre de délimitation spatiale de toute instance de vérité terrain sur la carte des caractéristiques BEV. Le processus peut être exprimé comme suit. :
La dimension de caractéristique dans la formule a la même taille que la carte de caractéristiques BEV générée, représentant les informations de caractéristiques codées d'une véritable cible de valeur. Au cours du processus d'encodage, nous avons adopté deux formes, l'une est un grand modèle de langage (LLM) et l'autre est un perceptron multicouche (MLP). Grâce à des résultats expérimentaux, nous avons constaté que les deux méthodes obtenaient fondamentalement les mêmes performances.
De plus, afin d'améliorer davantage les informations sur les limites de la véritable cible sur la carte de caractéristiques BEV, nous recadrons la véritable cible sur la carte de caractéristiques BEV en fonction de sa position spatiale, et utilisons la mise en commun sur l'opération de définition des caractéristiques recadrées pour construire la représentation des informations sur les caractéristiques correspondantes. Le processus peut être exprimé sous la forme suivante :
Enfin, afin d'aligner davantage les caractéristiques BEV générées par le modèle avec les caractéristiques BEV à valeur réelle, nous avons utilisé la méthode d'apprentissage contrastif pour optimiser les deux catégories. La relation entre les éléments et la distance entre les caractéristiques BEV, le processus d'optimisation peut être exprimé sous la forme suivante :
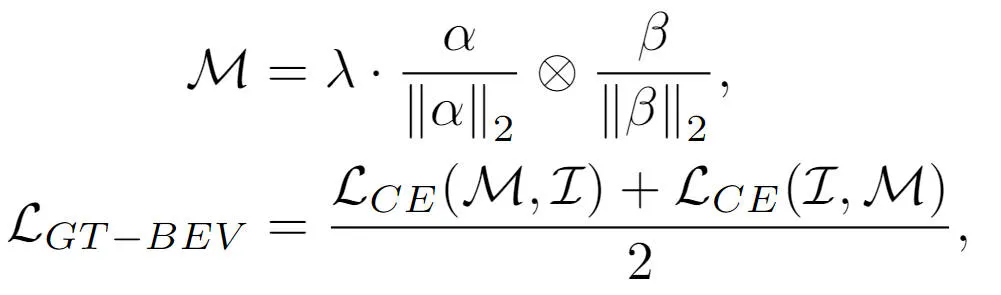
où la somme dans la formule représente respectivement la matrice de similarité entre les caractéristiques BEV générées et les caractéristiques BEV à valeur réelle, représentant la comparaison Le facteur d'échelle logique dans l'apprentissage représente l'opération de multiplication entre les matrices et représente la fonction de perte d'entropie croisée. Grâce à la méthode d'apprentissage contrastif ci-dessus, la méthode que nous proposons peut fournir un guidage plus clair des fonctionnalités BEV générées et améliorer la capacité de perception du modèle.
Interaction avec la requête cible à valeur réelle
Cette partie est également mentionnée dans l'article précédent. La requête d'objet dans le modèle d'algorithme de perception BEVFormer interagit avec les fonctionnalités BEV générées via le module Decoder pour obtenir les fonctionnalités de requête cible correspondantes, mais le processus global Il s'agit toujours d'un processus de boîte noire, sans une compréhension complète du processus. Pour résoudre ce problème, nous avons introduit le module d'interaction de requête de valeur de vérité, qui utilise la cible de valeur de vérité pour exécuter l'interaction de fonctionnalité BEV du module Decoder afin de stimuler le processus d'apprentissage des paramètres du modèle. Plus précisément, nous introduisons les informations de codage de cible de vérité produites par le module Truth Encoder () dans Object Query pour participer au processus de décodage du module Decoder. Comme la requête d'objet normale, nous participons au même module d'auto-attention, le module d'attention croisée. et Le réseau neuronal à action directe produit le résultat final de la perception. Cependant, il convient de noter que pendant le processus de décodage, toutes les requêtes d'objets utilisent un calcul parallèle pour empêcher la fuite d'informations cibles de valeur réelle. L'ensemble du processus d'interaction avec la requête cible de valeur de vérité peut être exprimé abstraitement sous la forme suivante :
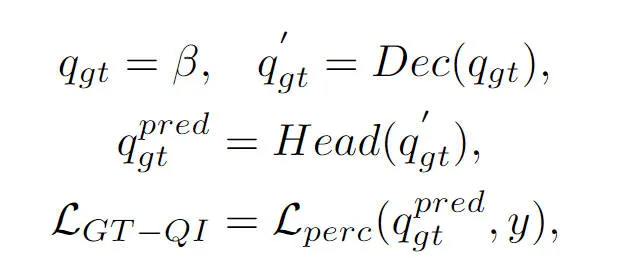
Parmi eux, dans la formule représente la requête d'objet initialisée et représente le résultat de sortie de la requête d'objet de valeur réelle via le module décodeur et la tête de détection respectivement. En introduisant le processus d'interaction de la vraie valeur cible dans le processus de formation du modèle, le module d'interaction de requête de vraie valeur cible que nous avons proposé peut réaliser l'interaction entre la vraie requête de valeur cible et la vraie valeur BEV, aidant ainsi le processus de mise à jour des paramètres du module décodeur modèle.
Résultats expérimentaux et indicateurs d'évaluation
Partie analyse quantitative
Afin de vérifier l'efficacité du modèle d'algorithme CLIP-BEVFormer que nous avons proposé, nous avons effectué sur l'ensemble de données nuScenes à partir de l'effet de perception 3D et de la durée de La catégorie cible dans l'ensemble de données. Des expériences pertinentes ont été menées du point de vue de la distribution de la queue et de la robustesse. Le tableau suivant montre la comparaison de précision entre le modèle d'algorithme que nous avons proposé et d'autres modèles d'algorithme de perception 3D sur l'ensemble de données nuScenes.
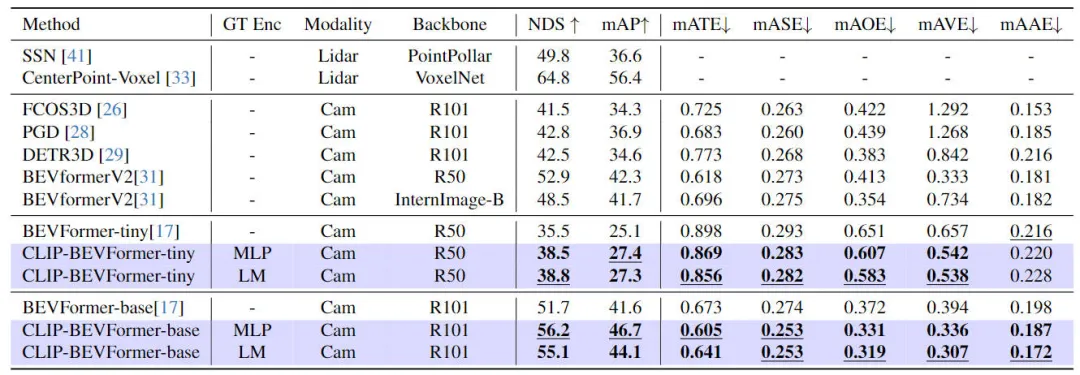
Résultats comparatifs entre la méthode proposée dans cet article et d'autres modèles d'algorithmes de perception
Dans cette partie de l'expérience, nous avons évalué les performances de perception sous différentes configurations de modèle. Plus précisément, nous avons appliqué le modèle d'algorithme CLIP-BEVFormer. variantes minuscules et de base de BEVFormer. En outre, nous avons également exploré l'impact de l'utilisation de modèles CLIP ou de couches MLP pré-entraînés comme encodeurs de cible de vérité terrain sur les performances de perception du modèle. Les résultats expérimentaux montrent que, qu'il s'agisse de la variante originale minuscule ou de base, après avoir appliqué l'algorithme CLIP-BEVFormer que nous avons proposé, les indicateurs NDS et mAP présentent des améliorations de performances stables. De plus, grâce aux résultats expérimentaux, nous pouvons constater que le modèle d'algorithme que nous avons proposé n'est pas sensible au fait que la couche MLP ou le modèle de langage soit sélectionné pour l'encodeur cible de vérité terrain. Cette flexibilité peut rendre l'algorithme CLIP-BEVFormer que nous avons proposé plus. efficace. Adaptable et facile à déployer sur le véhicule. En résumé, les indicateurs de performance des diverses variantes du modèle d'algorithme proposé indiquent systématiquement que le modèle d'algorithme CLIP-BEVFormer proposé présente une bonne robustesse perceptuelle et peut atteindre d'excellentes performances de détection sous différentes complexités de modèle et quantités de paramètres.
En plus de vérifier les performances de notre proposition CLIP-BEVFormer sur les tâches de perception 3D, nous avons également mené des expériences de distribution longue traîne pour évaluer la robustesse et la généralisation de notre algorithme face à la présence d'une distribution longue traîne dans les données. capacité de définition, les résultats expérimentaux sont résumés dans le tableau ci-dessous
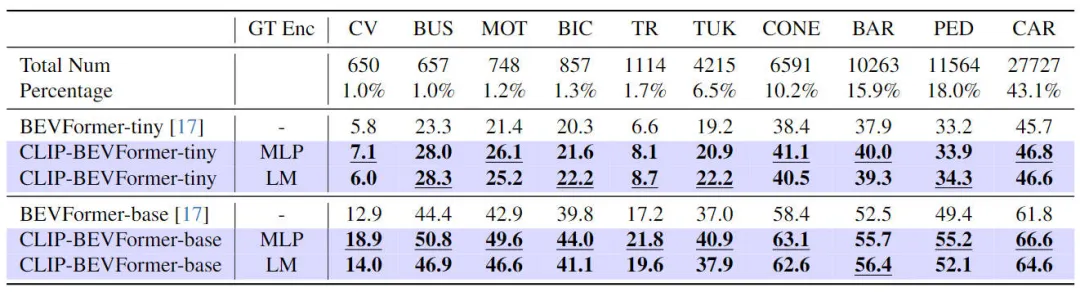
Les performances du modèle d'algorithme CLIP-BEVFormer proposé sur les problèmes à longue traîne
Il ressort des résultats expérimentaux du tableau ci-dessus que le L'ensemble de données nuScenes montre un grand nombre de catégories. Le problème du déséquilibre quantitatif est que certaines catégories telles que (véhicules de construction, bus, motos, vélos, etc.) ont une très faible proportion, mais la proportion de voitures est très élevée. Nous évaluons les performances perceptuelles du modèle d'algorithme CLIP-BEVFormer proposé sur les catégories de caractéristiques en menant des expériences pertinentes avec des distributions à longue traîne, vérifiant ainsi sa capacité de traitement à résoudre des catégories moins courantes. Il ressort des données expérimentales ci-dessus que le modèle d'algorithme CLIP-BEVFormer proposé a obtenu des améliorations de performances dans toutes les catégories, et dans les catégories qui représentent une très petite proportion, le modèle d'algorithme CLIP-BEVFormer a démontré une amélioration substantielle évidente des performances.
Considérant que les systèmes de conduite autonome dans des environnements réels doivent faire face à des problèmes tels que des pannes matérielles, des conditions météorologiques extrêmes ou des pannes de capteurs facilement causées par des obstacles artificiels, nous avons en outre vérifié expérimentalement la robustesse du modèle d'algorithme proposé. Plus précisément, afin de simuler le problème de défaillance du capteur, nous avons bloqué de manière aléatoire la caméra d'une caméra pendant le processus d'inférence de mise en œuvre du modèle, afin de simuler la scène où la caméra peut tomber en panne. Les résultats expérimentaux pertinents sont présentés dans le tableau ci-dessous
. 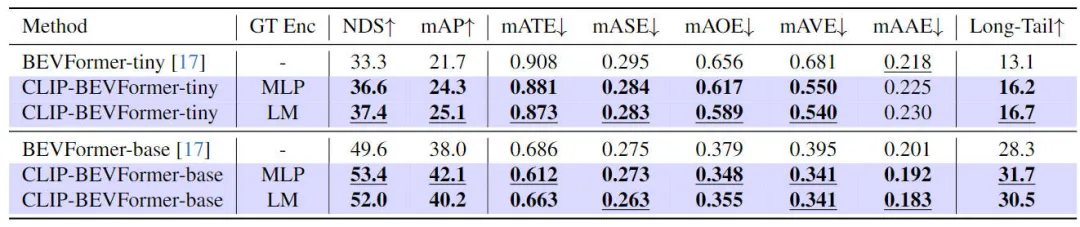 Les résultats expérimentaux de robustesse du modèle d'algorithme CLIP-BEVFormer proposé
Les résultats expérimentaux de robustesse du modèle d'algorithme CLIP-BEVFormer proposé
Il ressort des résultats expérimentaux que le modèle d'algorithme CLIP-BEVFormer que nous avons proposé est toujours meilleur que BEVFormer, quelle que soit la configuration des paramètres du modèle (minuscule ou base). Le modèle avec la même configuration vérifie les performances supérieures et l'excellente robustesse de notre modèle d'algorithme dans la simulation des conditions de défaillance des capteurs.
Partie analyse qualitative
La figure suivante montre la comparaison visuelle des résultats de perception de notre modèle d'algorithme CLIP-BEVFormer proposé et du modèle d'algorithme BEVFormer. Il ressort des résultats visuels que les résultats de perception du modèle d'algorithme CLIP-BEVFormer que nous avons proposé sont plus proches de la vraie valeur cible, indiquant l'efficacité du module de génération de fonctionnalités BEV de vraie valeur et du module d'interaction de requête cible de vraie valeur que nous avons proposé. .

Comparaison visuelle des résultats de perception du modèle d'algorithme CLIP-BEVFormer proposé et du modèle d'algorithme BEVFormer
Conclusion
Dans cet article, l'algorithme BEVFormer original se concentre sur le manque de supervision de l'affichage dans le processus de génération Cartes de fonctionnalités BEV Outre l'incertitude de la requête interactive entre les fonctionnalités Object Query et BEV dans le module Decoder, nous avons proposé le modèle d'algorithme CLIP-BEVFormer et mené des expériences sur les aspects des performances de perception 3D du modèle d'algorithme, de la distribution cible à longue traîne. , et la robustesse aux pannes de capteurs. Un grand nombre de résultats expérimentaux montrent l'efficacité de notre modèle d'algorithme CLIP-BEVFormer proposé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Jan 25, 2024 am 11:36 AM
Apprentissage des connaissances sur l'occupation intermodale : RadOcc utilisant la technologie de distillation assistée par rendu
Jan 25, 2024 am 11:36 AM
Titre original : Radocc : LearningCross-ModalityOccupancyKnowledgethroughRenderingAssistedDistillation Lien vers l'article : https://arxiv.org/pdf/2312.11829.pdf Unité auteur : FNii, CUHK-ShenzhenSSE, CUHK-Shenzhen Conférence du laboratoire Huawei Noah's Ark : AAAI2024 Idée d'article : la prédiction d'occupation 3D est une tâche émergente qui vise à estimer l'état d'occupation et la sémantique de scènes 3D à l'aide d'images multi-vues. Cependant, en raison du manque d’a priori géométriques, les scénarios basés sur des images
