
 Périphériques technologiques
IA
Tsinghua Microsoft a open source un nouvel outil de compression de mots rapides, la longueur a chuté de 80 % ! GitHub obtient 3,1K étoiles
Périphériques technologiques
IA
Tsinghua Microsoft a open source un nouvel outil de compression de mots rapides, la longueur a chuté de 80 % ! GitHub obtient 3,1K étoiles
Tsinghua Microsoft a open source un nouvel outil de compression de mots rapides, la longueur a chuté de 80 % ! GitHub obtient 3,1K étoiles

Dans le traitement du langage naturel, de nombreuses informations sont en réalité répétées.
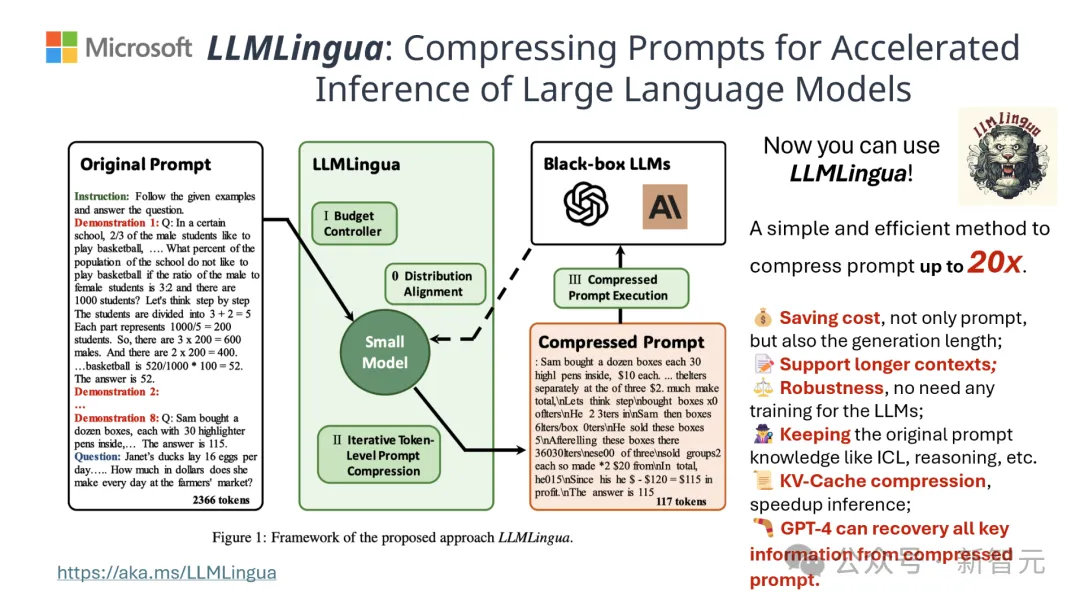
Si les mots d'invite peuvent être compressés efficacement, cela équivaut à étendre dans une certaine mesure la longueur du contexte pris en charge par le modèle.
Les méthodes d'entropie de l'information existantes réduisent cette redondance en supprimant certains mots ou expressions.
Cependant, le calcul basé sur l'entropie de l'information ne couvre que le contexte unidirectionnel du texte et peut ignorer les informations clés requises pour la compression. De plus, la méthode de calcul de l'entropie de l'information n'est pas complètement cohérente avec l'objectif réel de la compression de l'invite ; mots.
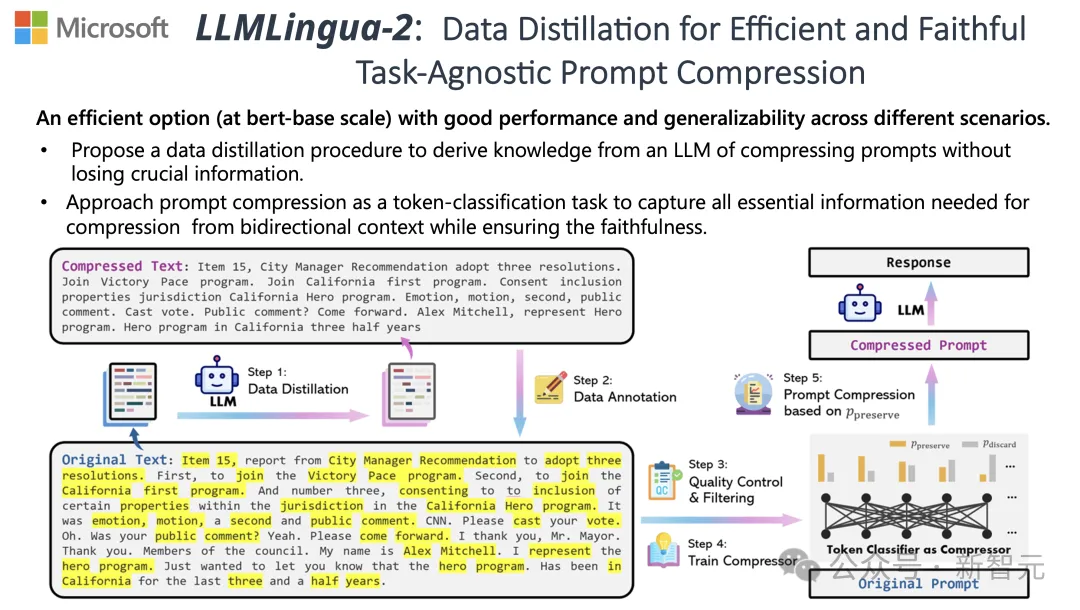
Pour relever ces défis, des chercheurs de l'Université Tsinghua et de Microsoft ont proposé conjointement un nouveau processus de traitement des données appelé LLMLingua-2. Il vise à extraire des connaissances à partir de grands modèles de langage (LLM) et à affiner les informations en compressant les mots d'invite tout en garantissant que les informations clés ne sont pas perdues.
Le projet a gagné 3,1 000 étoiles sur GitHub
Les résultats montrent que LLMLingua-2 peut réduire considérablement la longueur du texte jusqu'à 20 % d'origine, réduisant ainsi efficacement le temps et les coûts de traitement.
De plus, la vitesse de traitement de LLMLingua 2 est augmentée de 3 à 6 fois par rapport à la version précédente de LLMLingua et d'autres technologies similaires.

Adresse papier : https://arxiv.org/abs/2403.12968
Dans ce processus, le texte original est d'abord entré dans le modèle.
Le modèle évaluera l'importance de chaque mot et décidera de le conserver ou de le supprimer, tout en prenant également en compte la relation entre les mots.
Enfin, le modèle sélectionnera les mots avec les scores les plus élevés pour former un mot d'invite plus court.
L'équipe a testé le modèle LLMLingua-2 sur plusieurs ensembles de données, notamment MeetingBank, LongBench, ZeroScrolls, GSM8K et BBH.
Bien que ce modèle soit de petite taille, il a obtenu des améliorations de performances significatives lors des tests de référence et a prouvé ses performances dans différents grands modèles de langage (de GPT-3.5 à Mistral-7B) et langues (de l'anglais au chinois) excellente capacité de généralisation.
Invite système :
En tant que linguiste exceptionnel, vous êtes doué pour compresser des paragraphes plus longs en expressions courtes en supprimant les mots sans importance et en conservant autant d'informations que possible.
Conseils d'utilisation :
Veuillez compresser le texte donné en une expression courte afin que vous (GPT-4) puissiez restaurer le texte original aussi précisément que possible. Contrairement à la compression de texte classique, vous devez respecter les cinq conditions suivantes :
1. Supprimez uniquement les mots sans importance.
2. Gardez l'ordre des mots originaux inchangé.
3. Gardez le vocabulaire original inchangé.
4. N'utilisez aucune abréviation ni émoticône.
5. N'ajoutez aucun nouveau mot ou symbole.
Veuillez compresser le texte original autant que possible tout en conservant autant d'informations que possible. Si vous comprenez, veuillez compresser le texte suivant : {Texte à compresser}
Le texte compressé est : [...]
Les résultats montrent qu'en questions-réponses, l'écriture abstraite et le raisonnement logique Dans une variété de tâches linguistiques, LLMLingua-2 surpasse considérablement le modèle LLMLingua original et d'autres stratégies contextuelles sélectives.
Il convient de mentionner que cette méthode de compression est également efficace pour différents grands modèles de langues (de GPT-3.5 à Mistral-7B) et différentes langues (de l'anglais au chinois).
De plus, le déploiement de LLMLingua-2 peut être réalisé avec seulement deux lignes de code.
Actuellement, le modèle a été intégré aux frameworks RAG largement utilisés LangChain et LlamaIndex.
Méthode de mise en œuvre
Afin de surmonter les problèmes rencontrés par les méthodes existantes de compression de texte basées sur l'entropie des informations, LLMLingua-2 adopte une stratégie innovante d'extraction de données.
Cette stratégie permet une compression de texte efficace sans perdre le contenu clé et en évitant l'ajout d'informations erronées en extrayant les informations essentielles de grands modèles de langage tels que GPT-4.
Tips Design
Pour utiliser pleinement le potentiel de compression de texte de GPT-4, la clé réside dans la manière de définir des instructions de compression précises.
C'est-à-dire que lors de la compression du texte, demandez à GPT-4 de supprimer uniquement les mots les moins importants dans le texte original, tout en évitant l'introduction de nouveaux mots dans le processus.
Le but est de garantir que le texte compressé conserve autant que possible l'authenticité et l'intégrité du texte original.

Annotation et filtrage
Les chercheurs ont développé un nouvel algorithme d'annotation de données en utilisant les connaissances extraites de grands modèles de langage tels que GPT-4.
Cet algorithme peut étiqueter chaque mot du texte original et indiquer clairement quels mots doivent être conservés pendant le processus de compression.
Afin de garantir la haute qualité de l'ensemble de données construit, ils ont également conçu deux mécanismes de contrôle de la qualité spécifiquement pour identifier et éliminer les échantillons de données de mauvaise qualité.

Compressor
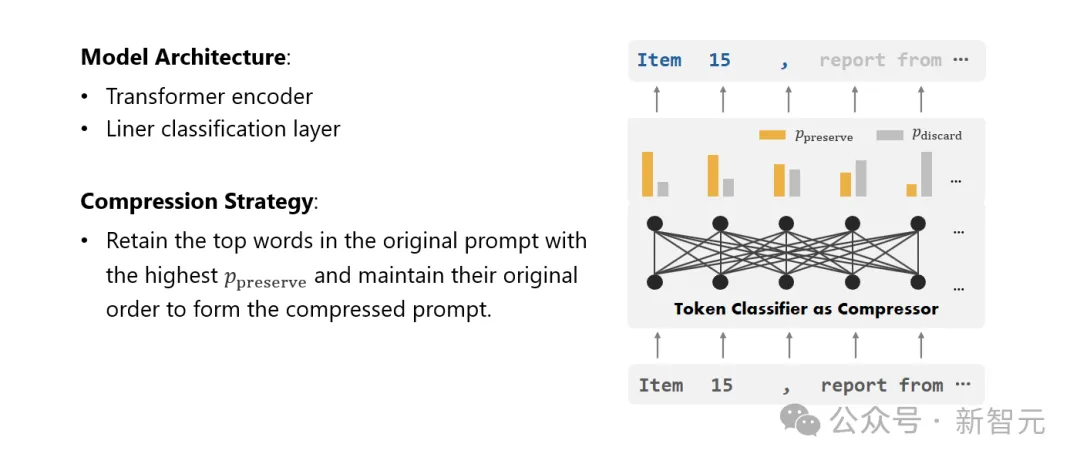
Enfin, les chercheurs ont transformé le problème de la compression de texte en une tâche de classification de chaque vocabulaire (Token) et ont utilisé un puissant Transformer comme extracteur de fonctionnalités.
Cet outil comprend le contexte du texte pour capturer avec précision les informations cruciales pour la compression du texte.
En s'entraînant sur un ensemble de données soigneusement construit, le modèle des chercheurs est capable de calculer une valeur de probabilité basée sur l'importance de chaque mot pour décider si le mot doit être conservé dans le texte compressé final ou doit être abandonné.
Évaluation des performances
Les chercheurs ont testé les performances de LLMLingua-2 sur une gamme de tâches, notamment l'apprentissage du contexte, le résumé de texte, la génération de dialogues, les questions-réponses multi-documents et monodocuments, la génération de code et Les tâches de synthèse incluent à la fois des ensembles de données dans le domaine et des ensembles de données hors domaine.
Les résultats des tests montrent que la méthode des chercheurs réduit une perte de performances minimale tout en maintenant des performances élevées, et offre des performances exceptionnelles parmi les méthodes de compression de texte non spécifiques à des tâches.
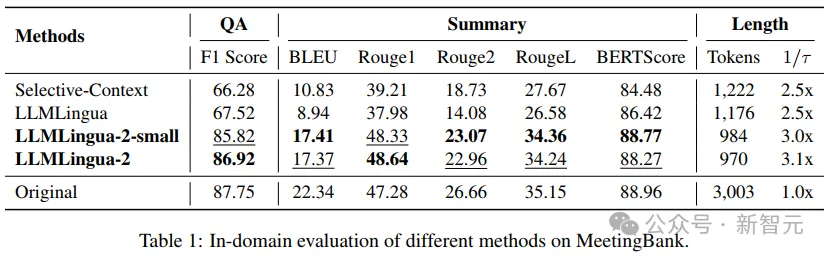
- Tests dans le domaine (MeetingBank)
Les chercheurs ont comparé les performances de LLMLingua-2 sur l'ensemble de tests MeetingBank avec d'autres méthodes de base puissantes.
Bien que la taille de leur modèle soit beaucoup plus petite que le LLaMa-2-7B utilisé dans la ligne de base, pour les tâches de réponse aux questions et de résumé de texte, la méthode des chercheurs a non seulement amélioré de manière significative les performances, mais a également fonctionné presque aussi bien que » le texte original vous invite.
- Tests hors domaine (LongBench, GSM8K et BBH)
Considérant que le modèle des chercheurs a été formé uniquement sur les données des enregistrements de réunions de MeetingBank, les chercheurs ont exploré plus en détail son utilisation en capacité de généralisation dans différents scénarios tels que le texte long, le raisonnement logique et l'apprentissage contextuel.
Il convient de mentionner que bien que LLMLlingua-2 n'ait été formé que sur un seul ensemble de données, lors de tests hors domaine, ses performances étaient non seulement comparables aux méthodes de compression actuelles de pointe non spécifiques aux tâches, mais même dans certains cas, c'est encore pire.
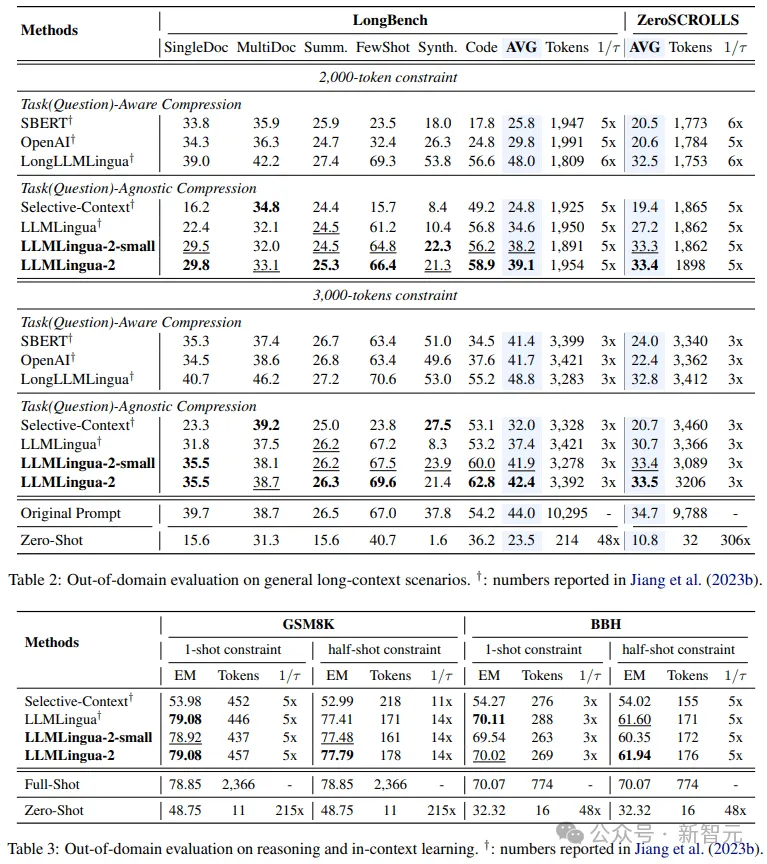
Même le modèle le plus petit des chercheurs (taille de base BERT) a pu atteindre des performances comparables, et dans certains cas même légèrement meilleures, que les indications originales.
Bien que l'approche des chercheurs ait donné des résultats prometteurs, elle présente encore des lacunes par rapport à d'autres méthodes de compression sensibles aux tâches telles que LongLLMlingua sur Longbench.
Les chercheurs attribuent cet écart de performance aux informations supplémentaires qu'ils obtiennent du problème. Cependant, le modèle des chercheurs est indépendant des tâches, ce qui en fait une option efficace avec une bonne généralisabilité lorsqu'elle est déployée dans différents scénarios.
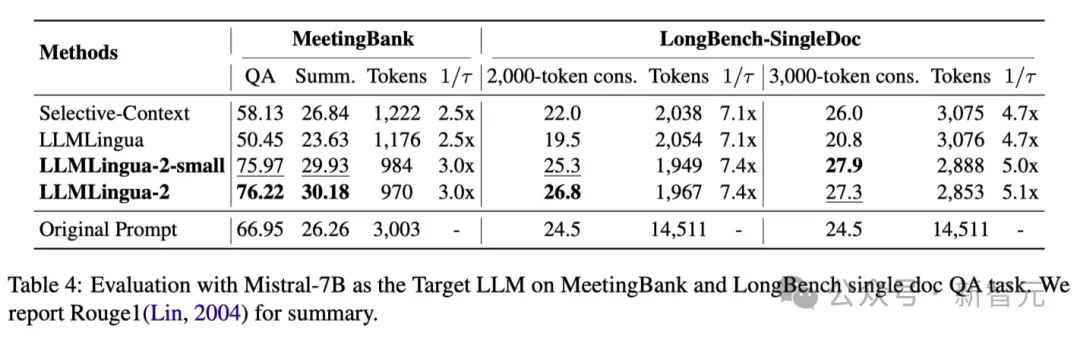
Le tableau 4 ci-dessus répertorie les résultats de différentes méthodes utilisant Mistral-7Bv0.1 4 comme LLM cible.
Par rapport aux autres méthodes de base, la méthode des chercheurs présente une amélioration significative des performances, démontrant sa bonne capacité de généralisation sur le LLM cible.
Il convient de noter que LLMLingua-2 fonctionne encore mieux que l'invite d'origine.
Les chercheurs pensent que Mistral-7B n'est peut-être pas aussi efficace pour gérer des contextes longs que GPT-3.5-Turbo.
L'approche des chercheurs améliore efficacement les performances d'inférence finale de Mistral7B en fournissant de courts indices avec une densité d'informations plus élevée.
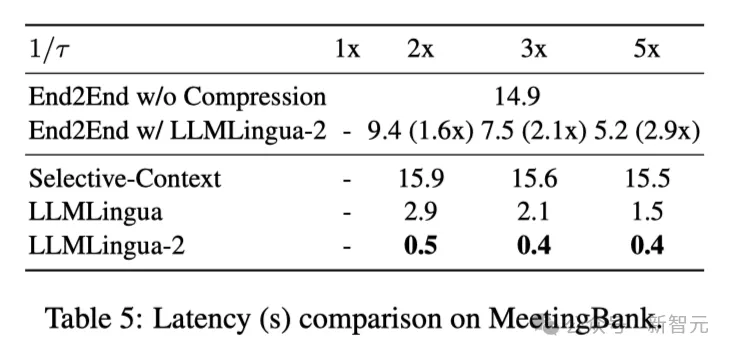
Le tableau 5 ci-dessus montre la latence des différents systèmes sur GPU V100-32G avec différents taux de compression.
Les résultats montrent que par rapport à d'autres méthodes de compression, LLMLingua2 a beaucoup moins de temps de calcul et peut atteindre une amélioration de la vitesse de bout en bout de 1,6x à 2,9x.
De plus, la méthode des chercheurs peut réduire de 8 fois les coûts de mémoire GPU, réduisant ainsi la demande en ressources matérielles.
Observation contextuelle Les chercheurs ont observé qu'à mesure que le taux de compression augmente, LLMLingua-2 peut efficacement conserver les mots les plus informatifs avec un contexte complet.
C'est grâce à l'adoption d'un extracteur de fonctionnalités bidirectionnel sensible au contexte et à une stratégie qui optimise explicitement vers l'objectif d'une compression rapide.
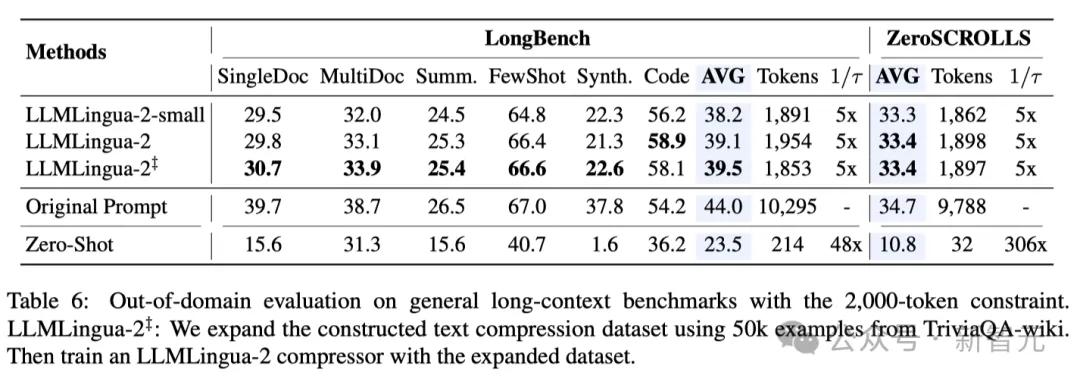
Les chercheurs ont observé qu'à mesure que le taux de compression augmente, LLMLingua-2 peut efficacement conserver les mots les plus informatifs liés au contexte complet.
C'est grâce à l'adoption d'un extracteur de fonctionnalités bidirectionnel sensible au contexte et à une stratégie qui optimise explicitement vers l'objectif d'une compression rapide.
Enfin, les chercheurs ont demandé à GPT-4 de reconstruire le ton original à partir de l'indice de compression LLMLlingua-2.
Les résultats montrent que GPT-4 peut reconstruire efficacement la pointe d'origine, indiquant qu'aucune information essentielle n'est perdue pendant le processus de compression LLMLlingua-2.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Adresse d'entrée de la version internationale de Microsoft Bing (entrée du moteur de recherche Bing)
Mar 14, 2024 pm 01:37 PM
Adresse d'entrée de la version internationale de Microsoft Bing (entrée du moteur de recherche Bing)
Mar 14, 2024 pm 01:37 PM
Bing est un moteur de recherche en ligne lancé par Microsoft. La fonction de recherche est très puissante et comporte deux entrées : la version nationale et la version internationale. Où sont les entrées de ces deux versions ? Comment accéder à la version internationale ? Jetons un coup d'œil aux détails ci-dessous. Entrée du site Web de la version chinoise de Bing : https://cn.bing.com/ Entrée du site Web de la version internationale de Bing : https://global.bing.com/ Comment accéder à la version internationale de Bing ? 1. Entrez d'abord l'URL pour ouvrir Bing : https://www.bing.com/ 2. Vous pouvez voir qu'il existe des options pour les versions nationales et internationales. Il suffit de sélectionner la version internationale et de saisir les mots-clés.
 La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
Selon l'actualité du 3 juin, Microsoft envoie activement des notifications en plein écran à tous les utilisateurs de Windows 10 pour les encourager à passer au système d'exploitation Windows 11. Ce déplacement concerne les appareils dont les configurations matérielles ne prennent pas en charge le nouveau système. Depuis 2015, Windows 10 occupe près de 70 % des parts de marché, établissant ainsi sa domination en tant que système d'exploitation Windows. Cependant, la part de marché dépasse largement la part de marché de 82 %, et la part de marché dépasse largement celle de Windows 11, qui sortira en 2021. Même si Windows 11 est lancé depuis près de trois ans, sa pénétration sur le marché est encore lente. Microsoft a annoncé qu'il mettrait fin au support technique de Windows 10 après le 14 octobre 2025 afin de se concentrer davantage sur
 Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Selon les informations de ce site du 14 août, lors de la journée d'événement Patch Tuesday d'aujourd'hui, Microsoft a publié des mises à jour cumulatives pour les systèmes Windows 11, notamment la mise à jour KB5041585 pour 22H2 et 23H2 et la mise à jour KB5041592 pour 21H2. Après l'installation de l'équipement mentionné ci-dessus avec la mise à jour cumulative d'août, les changements de numéro de version attachés à ce site sont les suivants : Après l'installation de l'équipement 21H2, le numéro de version est passé à Build22000.314722H2. le numéro de version est passé à Build22621.403723H2. Après l'installation de l'équipement, le numéro de version est passé à Build22631.4037. Le contenu principal de la mise à jour KB5041585 pour Windows 1121H2 est le suivant : Amélioration : Amélioré.
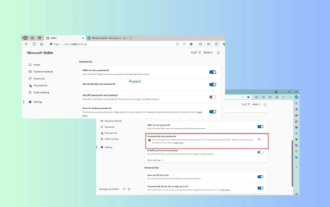 Mise à niveau de Microsoft Edge : la fonction de sauvegarde automatique du mot de passe interdite ? ! Les utilisateurs ont été choqués !
Apr 19, 2024 am 08:13 AM
Mise à niveau de Microsoft Edge : la fonction de sauvegarde automatique du mot de passe interdite ? ! Les utilisateurs ont été choqués !
Apr 19, 2024 am 08:13 AM
Actualités du 18 avril : Récemment, certains utilisateurs du navigateur Microsoft Edge utilisant le canal Canary ont signalé qu'après la mise à niveau vers la dernière version, ils avaient constaté que l'option d'enregistrement automatique des mots de passe était désactivée. Après enquête, il a été constaté qu'il s'agissait d'un ajustement mineur après la mise à niveau du navigateur, plutôt que d'une suppression de fonctionnalités. Avant d'utiliser le navigateur Edge pour accéder à un site Web, les utilisateurs ont signalé que le navigateur ouvrait une fenêtre leur demandant s'ils souhaitaient enregistrer le mot de passe de connexion au site Web. Après avoir choisi d'enregistrer, Edge remplira automatiquement le numéro de compte et le mot de passe enregistrés lors de votre prochaine connexion, offrant ainsi aux utilisateurs une grande commodité. Mais la dernière mise à jour ressemble à un ajustement, modifiant les paramètres par défaut. Les utilisateurs doivent choisir d'enregistrer le mot de passe, puis activer manuellement le remplissage automatique du compte et du mot de passe enregistrés dans les paramètres.
 La fonction de compression des fichiers 7z et TAR de Microsoft Win11 a été rétrogradée des versions 24H2 aux versions 23H2/22H2
Apr 28, 2024 am 09:19 AM
La fonction de compression des fichiers 7z et TAR de Microsoft Win11 a été rétrogradée des versions 24H2 aux versions 23H2/22H2
Apr 28, 2024 am 09:19 AM
Selon les informations de ce site le 27 avril, Microsoft a publié la mise à jour de la version préliminaire de Windows 11 Build 26100 sur les canaux Canary et Dev plus tôt ce mois-ci, qui devrait devenir une version RTM candidate de la mise à jour Windows 1124H2. Les principaux changements de la nouvelle version sont l'explorateur de fichiers, l'intégration de Copilot, l'édition des métadonnées des fichiers PNG, la création de fichiers compressés TAR et 7z, etc. @PhantomOfEarth a découvert que Microsoft a délégué certaines fonctions de la version 24H2 (Germanium) à la version 23H2/22H2 (Nickel), comme la création de fichiers compressés TAR et 7z. Comme le montre le schéma, Windows 11 prendra en charge la création native de TAR
 Mise à jour du navigateur Microsoft Edge : ajout de la fonction 'zoomer sur l'image' pour améliorer l'expérience utilisateur
Mar 21, 2024 pm 01:40 PM
Mise à jour du navigateur Microsoft Edge : ajout de la fonction 'zoomer sur l'image' pour améliorer l'expérience utilisateur
Mar 21, 2024 pm 01:40 PM
Selon l'actualité du 21 mars, Microsoft a récemment mis à jour son navigateur Microsoft Edge et ajouté une fonction pratique « agrandir l'image ». Désormais, lorsqu'ils utilisent le navigateur Edge, les utilisateurs peuvent facilement trouver cette nouvelle fonctionnalité dans le menu contextuel en cliquant simplement avec le bouton droit sur l'image. Ce qui est plus pratique, c'est que les utilisateurs peuvent également passer le curseur sur l'image, puis double-cliquer sur la touche Ctrl pour appeler rapidement la fonction de zoom avant sur l'image. Selon la compréhension de l'éditeur, le nouveau navigateur Microsoft Edge a été testé pour les nouvelles fonctionnalités du canal Canary. La version stable du navigateur a également officiellement lancé la fonction pratique « agrandir l'image », offrant aux utilisateurs une expérience de navigation d'images plus pratique. Les médias scientifiques et technologiques étrangers y ont également prêté attention.
 Microsoft prévoit de supprimer progressivement NTLM dans Windows 11 au second semestre 2024 et de passer entièrement à l'authentification Kerberos
Jun 09, 2024 pm 04:17 PM
Microsoft prévoit de supprimer progressivement NTLM dans Windows 11 au second semestre 2024 et de passer entièrement à l'authentification Kerberos
Jun 09, 2024 pm 04:17 PM
Au second semestre 2024, le blog officiel de sécurité Microsoft a publié un message en réponse à l'appel de la communauté de la sécurité. La société prévoit d'éliminer le protocole d'authentification NTLAN Manager (NTLM) dans Windows 11, publié au second semestre 2024, pour améliorer la sécurité. Selon des explications précédentes, Microsoft a déjà pris des mesures similaires auparavant. Le 12 octobre dernier, Microsoft a proposé un plan de transition dans un communiqué de presse officiel visant à supprimer progressivement les méthodes d'authentification NTLM et à inciter davantage d'entreprises et d'utilisateurs à passer à Kerberos. Pour aider les entreprises susceptibles de rencontrer des problèmes avec les applications et services câblés après avoir désactivé l'authentification NTLM, Microsoft fournit IAKerb et
 Microsoft lance un nouveau PC Windows 11 AI : équipé d'une fonction innovante « review »
Jun 06, 2024 pm 01:52 PM
Microsoft lance un nouveau PC Windows 11 AI : équipé d'une fonction innovante « review »
Jun 06, 2024 pm 01:52 PM
Selon les informations du 21 mai, Microsoft a annoncé au public un nouveau produit PC Windows, Windows 11 AI PC, lors d'un grand événement organisé aujourd'hui sur son nouveau campus. Ce nouveau produit est spécialement conçu pour l'expérience de l'IA. Le PC Windows 11 AI est doté d'excellentes performances et d'une conception intelligente, visant à offrir aux utilisateurs une expérience informatique plus intelligente et plus efficace. Ce produit utilisera la technologie de l'intelligence artificielle pour obtenir une méthode d'interaction plus humaine et offrir aux utilisateurs l'expérience utilisateur ultime. Dans le même temps, Windows 11 AI PC intègre également de nombreuses fonctions intelligentes. Ruzhi Windows 11 AI peut offrir un atout majeur aux utilisateurs de PC, à savoir sa fonction unique « Rappel ». Cette « mémoire » sans précédent
