
 Périphériques technologiques
IA
Dix outils d'annotation de texte gratuits open source recommandés
Périphériques technologiques
IA
Dix outils d'annotation de texte gratuits open source recommandés
Dix outils d'annotation de texte gratuits open source recommandés

Le travail d'annotation de texte est le travail d'étiquettes ou de marques correspondant à un contenu spécifique dans le texte. Son objectif principal est d’apporter des informations complémentaires au texte pour une analyse et un traitement plus approfondis, notamment dans le domaine de l’intelligence artificielle.

L'annotation de texte est cruciale pour les tâches d'apprentissage automatique supervisées dans les applications d'intelligence artificielle. Il est utilisé pour entraîner des modèles d'IA afin de mieux comprendre les informations textuelles en langage naturel et d'améliorer les performances de tâches telles que la classification de texte, l'analyse des sentiments et la traduction linguistique. Grâce à l'annotation de texte, nous pouvons apprendre aux modèles d'IA à reconnaître les entités dans le texte, à comprendre le contexte et à faire des prédictions précises lorsque de nouvelles données similaires apparaissent.
Cet article recommande principalement de meilleurs outils d'annotation de texte open source.
1.Label Studio
https://github.com/HumanSignal/label-studio

Label Studio est un outil d'annotation de données open source qui peut gérer plusieurs types de données et prend en charge l'exportation vers plusieurs formats de modèle. Il est largement utilisé pour préparer des données brutes ou améliorer les données de formation existantes afin d'améliorer la précision des modèles d'apprentissage automatique.
2.Doccano
https://github.com/doccano/doccano
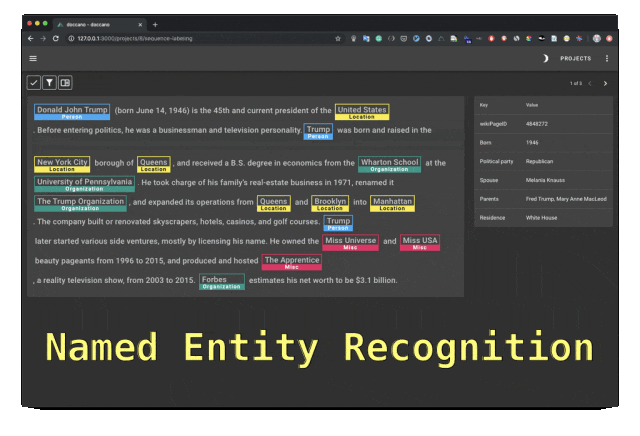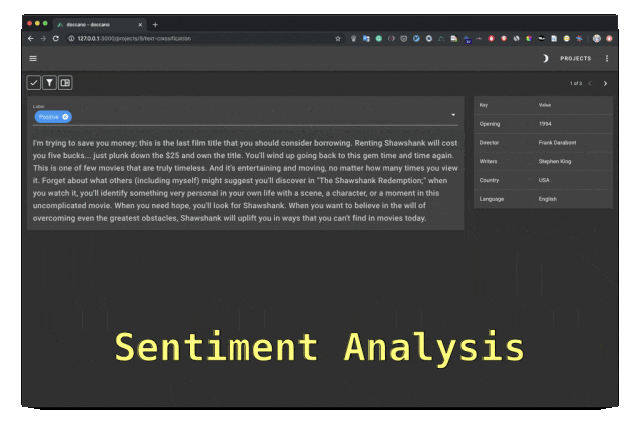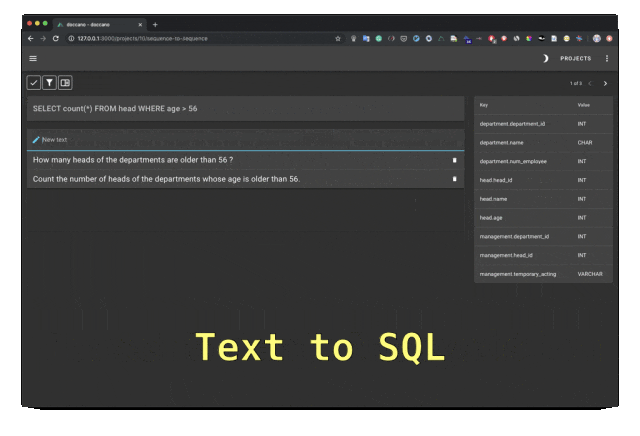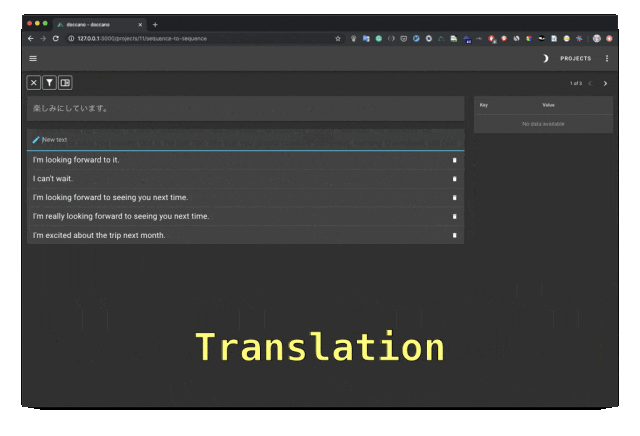
Doccano est un outil d'annotation de texte open source qui fournit des fonctions de classification de texte, d'étiquetage de séquence et de tâches de séquence. Il prend en charge la collaboration en équipe d'annotation de texte, les applications mobiles multilingues, les emojis, les thèmes sombres et les API de style REST. Peut être installé à l’aide de Docker et Docker Compose.
3.Universal Data Tool
https://github.com/UniversalDataTool/universal-data-tool
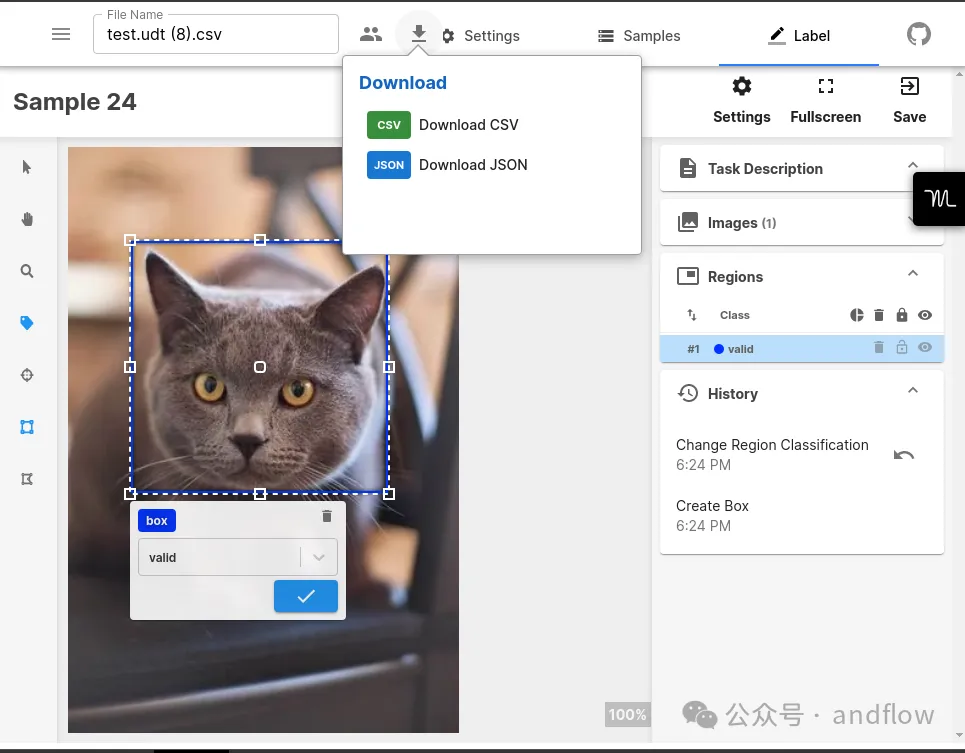
Universal Data Tool est un outil permettant d'éditer et d'annoter divers types de données (y compris des images, texte, audio et documents). Il prend en charge un large éventail de types de données et offre une collaboration en temps réel, une interface graphique facile à utiliser, la création de cours de formation pour les annotateurs de texte, et bien plus encore. L'outil est disponible sur le Web ou sous forme d'application de bureau et prend en charge le téléchargement et le téléchargement de données au format CSV ou JSON.
4.YEDDA
https://github.com/jiesutd/YEDDA
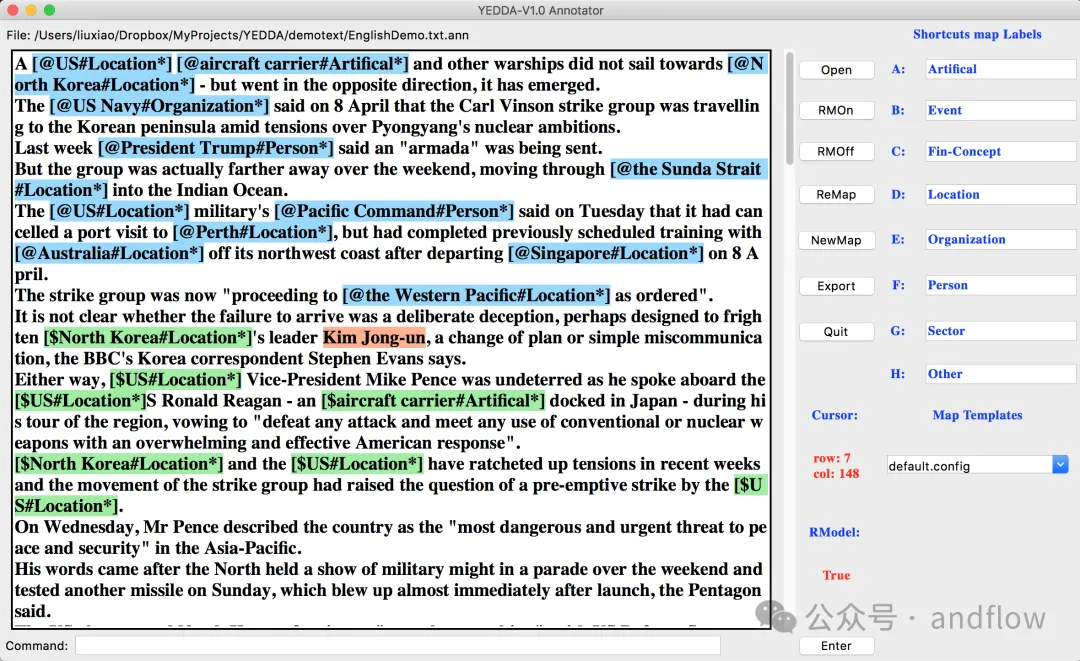
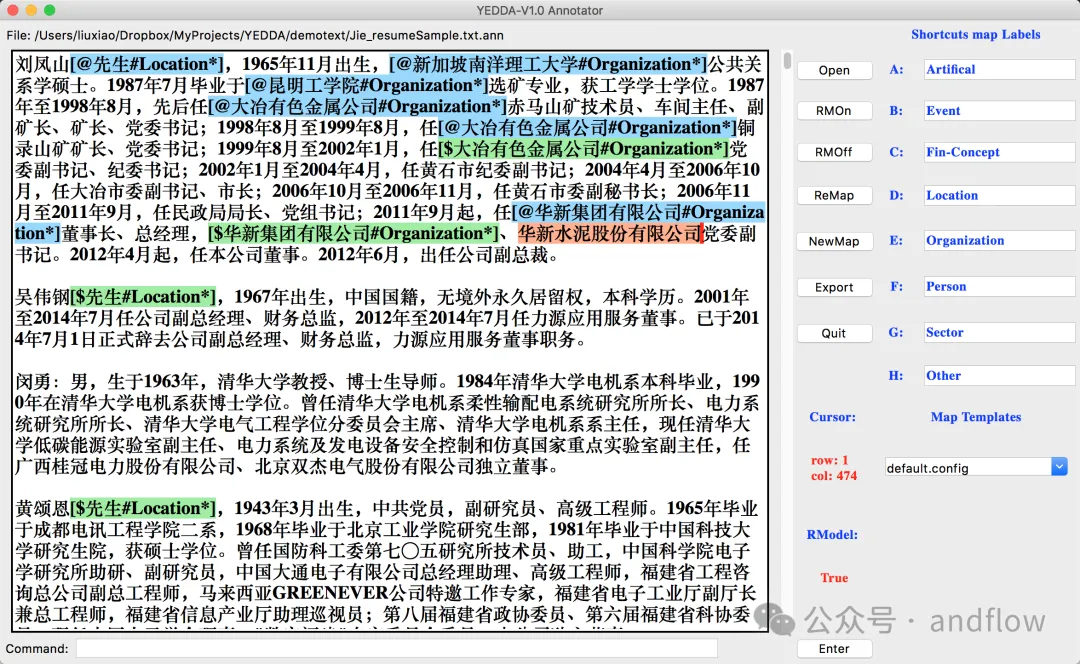
YEDDA est un outil d'annotation de texte qui peut être utilisé dans différentes langues, symboles et émoticônes. Il prend en charge l'utilisation de raccourcis, la commande du modèle et l'exportation du texte d'annotation sous forme de texte de séquence. Prend en charge des fonctions telles que les recommandations intelligentes et l'analyse de l'administrateur.
YEDDA est compatible avec tous les principaux systèmes d'exploitation, notamment Windows, Linux et MacOS.
5.Argilla
https://github.com/argilla-io/argilla
Argilla est une plate-forme de collaboration de données open source pour les ingénieurs en intelligence artificielle et les experts du domaine, fournissant une sortie de données efficace et de haute qualité.
Il aide à contrôler la qualité des données et à améliorer la qualité de la sortie de l'IA, et améliore l'efficacité en permettant une itération rapide des données et des modèles. Argilla fournit également des outils de gestion des données et de formation de modèles.
6.KernAI Refinery
https://github.com/code-kern-ai/refinery
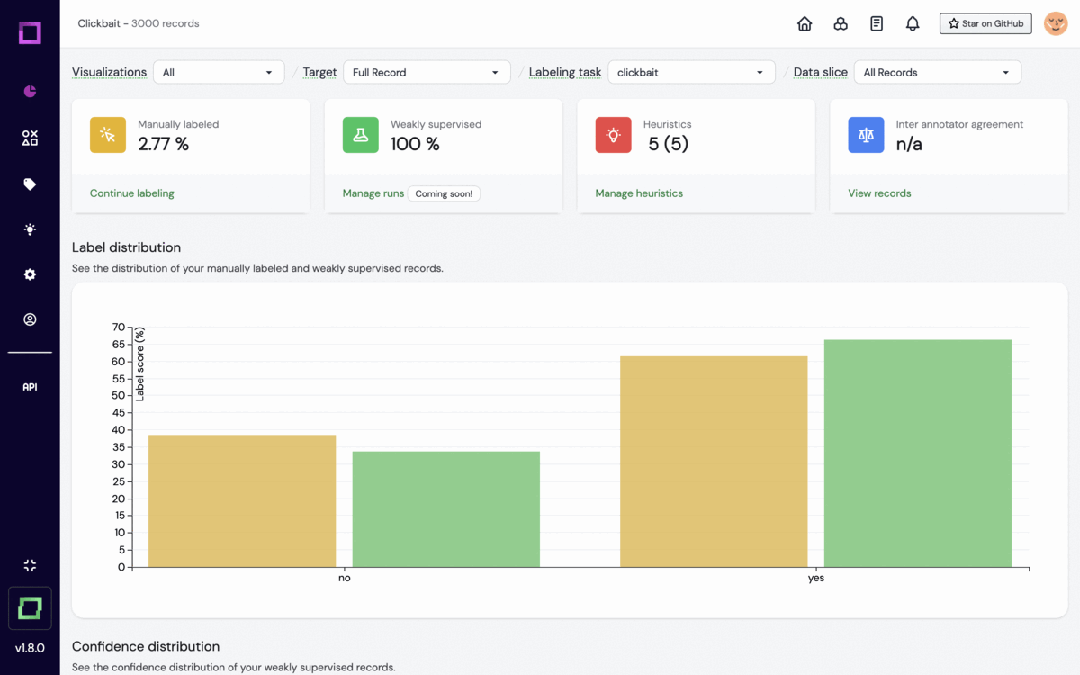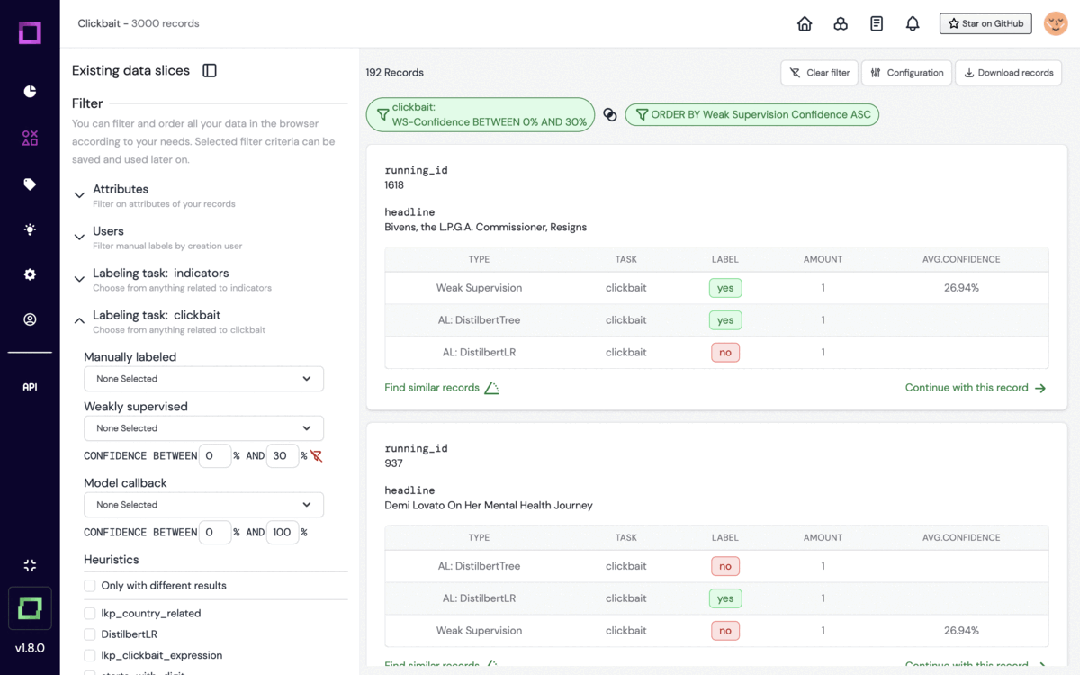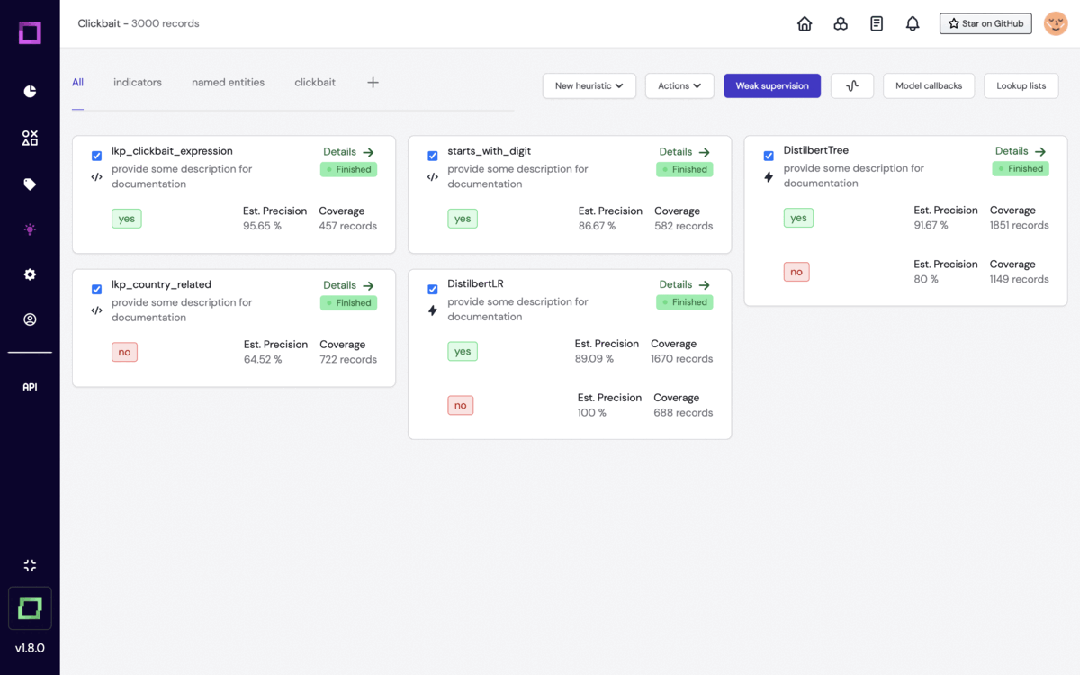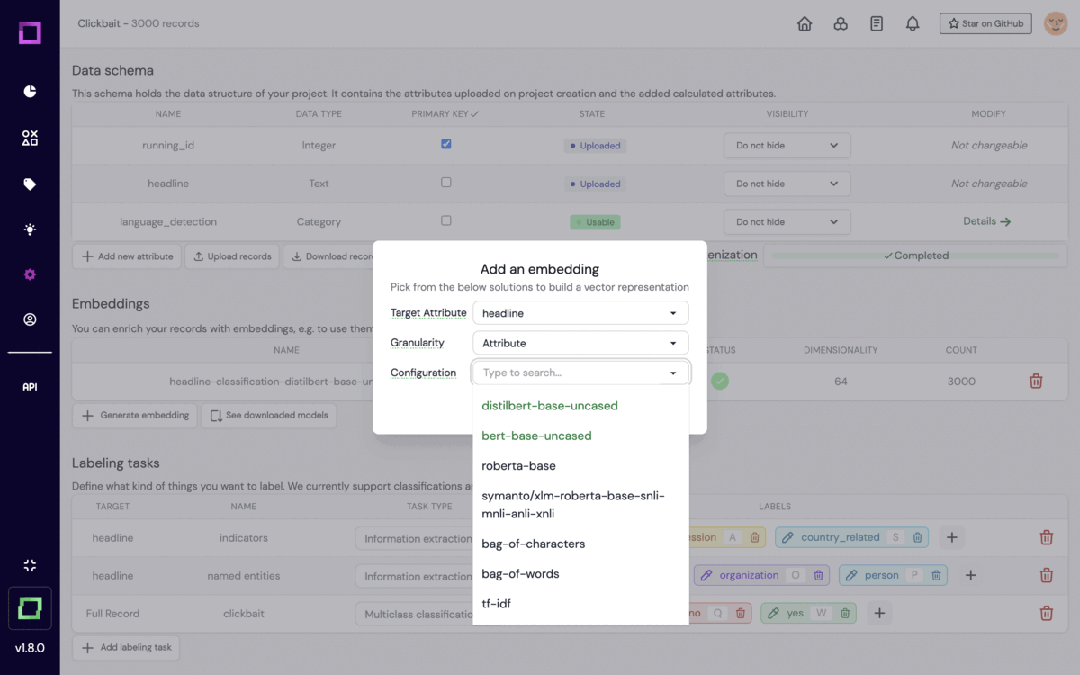
Refinery est une plateforme open source de KernAI conçue pour les data scientists qui traitent des données en langage naturel. Il fournit des fonctions telles que l'annotation semi-automatique des données, l'évaluation de la qualité des sous-ensembles de données et la surveillance centralisée des données, visant à améliorer l'efficacité de l'étiquetage manuel.
L'outil exploite des technologies telles que Hugging Face et spaCy pour créer des modèles de langage prédéfinis et s'intègre à d'autres outils d'étiquetage pour un traitement flexible des données.
Caractéristiques :
- Flux de travail d'étiquetage (semi-)automatisé pour les tâches PNL
- Classification manuelle et programmatique et étiquetage des étendues
- Prend en charge l'intégration avec des bibliothèques et des frameworks de pointe
- Créer et gérer des tables de recherche/bases de connaissances
- Recherche neuronale similarité basée sur l'enregistrement et la récupération des valeurs aberrantes
- Sessions de marquage découpées
- Plusieurs tâches de marquage par projet
- Riche bibliothèque d'automatisation
- Gestion et surveillance étendues des données
- Intégré à Hugging Face pour la création automatique d'intégrations
- Basé sur un modèle de données pour JSON pour le téléchargement/le téléchargement des données
- Aperçu des métriques du projet
- Accès et extension des données via le SDK Python
- Modifications des propriétés sur site
- Collaboration en équipe dans la version hébergée
- Accès basé sur les rôles pour plusieurs utilisateurs et vue réduite des balises
- Groupe intégré workflow de marquage
- Calcule automatiquement le consensus entre les annotateurs
7.Recogito.js
https://github.com/recogito/recogito-js
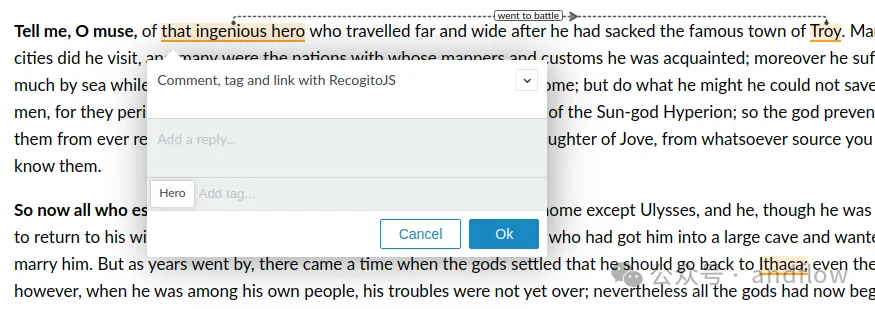
ApplitoJS est une bibliothèque JavaScript pour l'annotation de texte, utilisée pour ajouter une fonctionnalité d'annotation de texte aux pages Web ou créer des programmes d'annotation de texte personnalisés. Il peut être installé via npm ou en téléchargeant la dernière version.
8. Label Sleuth
https://github.com/label-sleuth/label-sleuth

Label Sleuth est un système open source sans code pour l'étiquetage et la classification de texte. Il permet aux experts de domaines tels que les médecins, les avocats et les psychologues de créer des modèles PNL personnalisés sans la coopération d'experts en PNL.
Habituellement, la création de modèles NLP nécessite une expertise en matière de domaine et d'apprentissage automatique. Label Sleuth contourne l'exigence d'une expertise en PNL grâce à l'annotation de texte intuitive et à la création de modèles d'IA. Pendant que les utilisateurs étiquetent les données, les modèles d'apprentissage automatique sont entraînés en arrière-plan, effectuant des prédictions et suggérant quoi étiqueter ensuite.
En tant que système sans code, il ne nécessite aucune connaissance en apprentissage automatique et permet un développement rapide de modèles, de la définition des tâches au modèle terminé en quelques heures seulement.
9.Markup
https://github.com/samueldobbie/markup
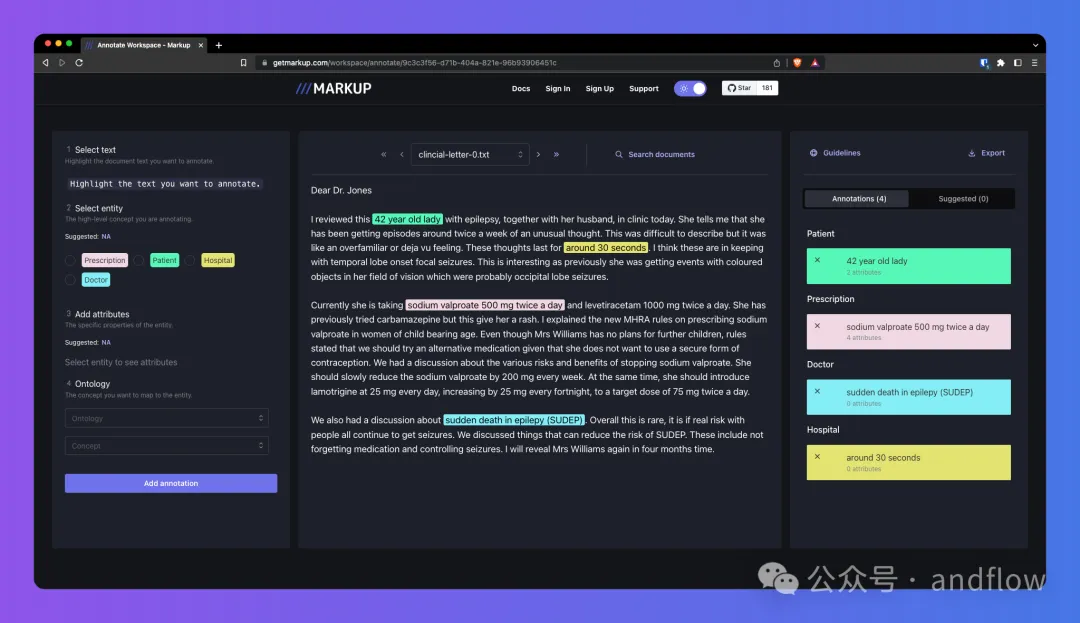
Markup est un outil d'annotation en ligne qui peut être utilisé pour convertir des documents non structurés en documents structurés pour les tâches NLP et ML Format, par exemple : reconnaissance d'entité. Apprentissage simultané au fur et à mesure que vous annotez pour prédire et recommander des annotations plus complexes, et fournit également un accès intégré à des ontologies communes et personnalisées pour la cartographie conceptuelle.
Caractéristiques :
- Annotation prédictive : la fonction d'annotation prédictive basée sur l'apprentissage automatique de Markup peut recommander des annotations plus complexes au fur et à mesure que vous travaillez, rendant le processus d'annotation plus efficace.
- Balises d'accès aux ontologies intégrées : fournit un accès intégré à un large éventail d'ontologies courantes (par exemple UMLS, SNOMED-CT, ICD-10), ainsi que la possibilité de télécharger des ontologies personnalisées pour la cartographie conceptuelle.
- Mappage d'ontologie prédictif : la fonctionnalité de mappage d'ontologie prédictif de Markup utilise l'apprentissage automatique pour recommander des mappages appropriés aux termes standard et personnalisés en fonction du texte que vous annotez.
- Interface conviviale : que vous soyez un expert technique ou un débutant, l'interface conviviale de Markup permet à quiconque de commencer facilement à annoter des documents avec une configuration minimale.
10.Potato
https://github.com/davidjurgens/potato
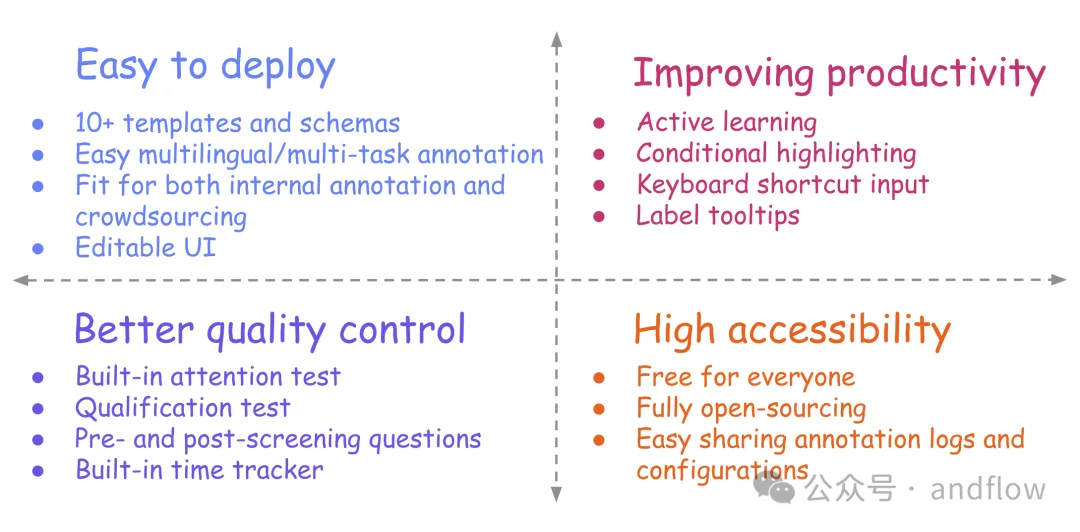
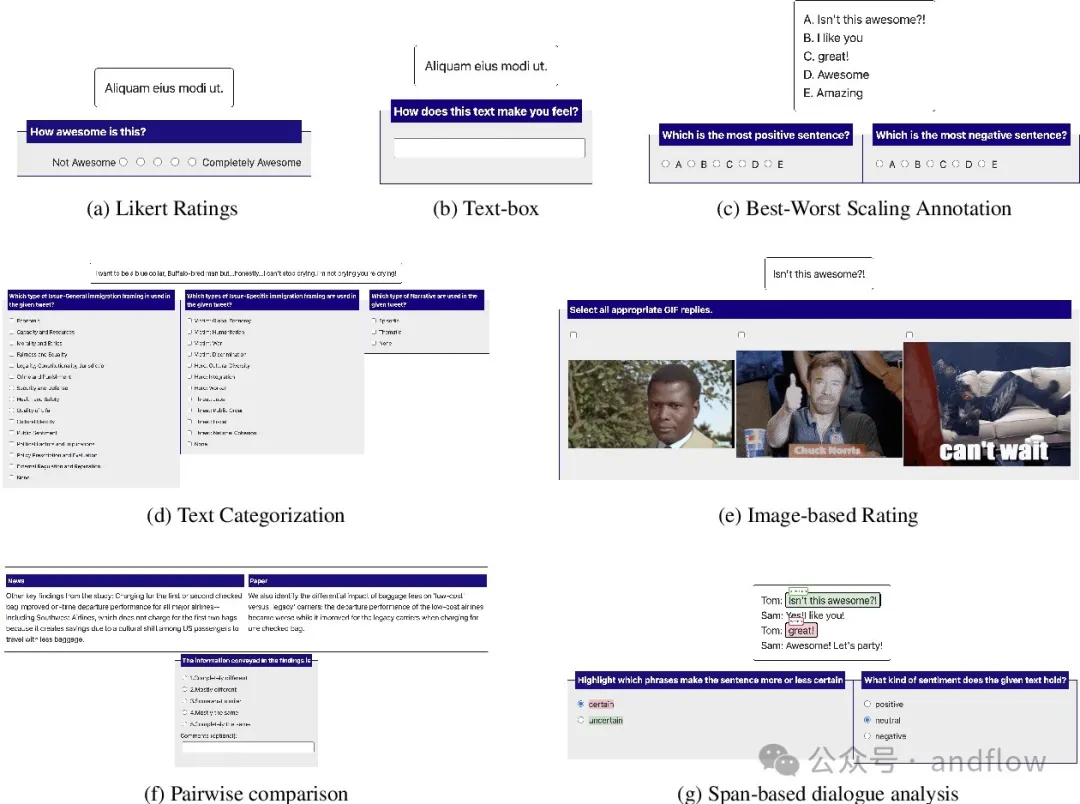
Potato est un outil d'annotation de texte basé sur le Web qui prend en charge la configuration et le déploiement rapides de diverses annotations de texte. Tâche. Peut fonctionner en tant que serveur Web, piloté par un seul fichier de configuration, ne nécessitant aucun codage de démarrage. Mais Potato est facile à personnaliser et ne nécessite généralement pas de conception Web supplémentaire pour ajuster l'interface utilisateur des annotateurs de texte.
Caractéristiques principales :
- Facile à configurer et à personnaliser
- Modèles et modèles intégrés étendus
- Prend en charge plusieurs types de données
- Prend en charge la configuration multitâche
- Avec des fonctionnalités telles que les raccourcis clavier, la mise en évidence dynamique et les info-bulles d'étiquettes Améliorer efficacité de l'annotation
- Mieux comprendre les capacités de l'annotateur, telles que les questions de pré- et post-filtrage
- Fonctionnalités de contrôle qualité, telles que les tests d'attention, les tests de qualification et les contrôles de temps intégrés
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
