
 Périphériques technologiques
IA
StreamingT2V, un générateur de vidéo longue de deux minutes et 1 200 images, est là, et le code sera open source
Périphériques technologiques
IA
StreamingT2V, un générateur de vidéo longue de deux minutes et 1 200 images, est là, et le code sera open source
StreamingT2V, un générateur de vidéo longue de deux minutes et 1 200 images, est là, et le code sera open source

Plan large du champ de bataille, des stormtroopers courant...

invite : Plan large du champ de bataille, des stormtroopers courant...
Cette vidéo de 2 minutes avec 1 200 images est une vidéo générée à partir de texte (texte -à-vidéo). Même si les traces de l'IA sont encore évidentes, les personnages et les scènes font preuve d'une assez bonne cohérence.
Comment ça se fait ? Il faut savoir que bien que la qualité de génération et la qualité d'alignement du texte de la technologie vidéo Vincent aient été assez bonnes ces dernières années, la plupart des méthodes existantes se concentrent sur la génération de vidéos courtes (généralement de 16 ou 24 images). Cependant, les méthodes existantes qui fonctionnent pour les vidéos courtes échouent souvent avec les vidéos longues (≥ 64 images).
Même la génération de séquences courtes nécessite souvent une formation coûteuse, comme des étapes de formation dépassant 260 000 et des tailles de lots dépassant 4 500. Si vous ne vous entraînez pas sur des vidéos plus longues et n'utilisez pas un générateur de vidéos courtes pour produire de longues vidéos, les longues vidéos qui en résultent sont souvent de mauvaise qualité. La méthode autorégressive existante (génération d'une nouvelle vidéo courte en utilisant les dernières images de la vidéo courte, puis synthèse de la vidéo longue) présente également quelques problèmes tels qu'un changement de scène incohérent.
Afin de combler les lacunes des méthodes existantes, Picsart AI Research et d'autres institutions ont proposé conjointement une nouvelle méthode vidéo Vincent : StreamingT2V. Cette méthode utilise une technologie autorégressive et la combine à un module de mémoire long court terme, ce qui lui permet de générer de longues vidéos avec une forte cohérence temporelle.

- Titre de l'article : StreamingT2V : Génération de vidéos longues cohérentes, dynamiques et extensibles à partir de texte
- Adresse de l'article : https://arxiv.org/abs/2403.14773
- Adresse du projet : https ://streamingt2v.github.io/
Ce qui suit est un résultat de génération vidéo de 600 images d'une minute. Vous pouvez voir que les abeilles et les fleurs ont une excellente cohérence :
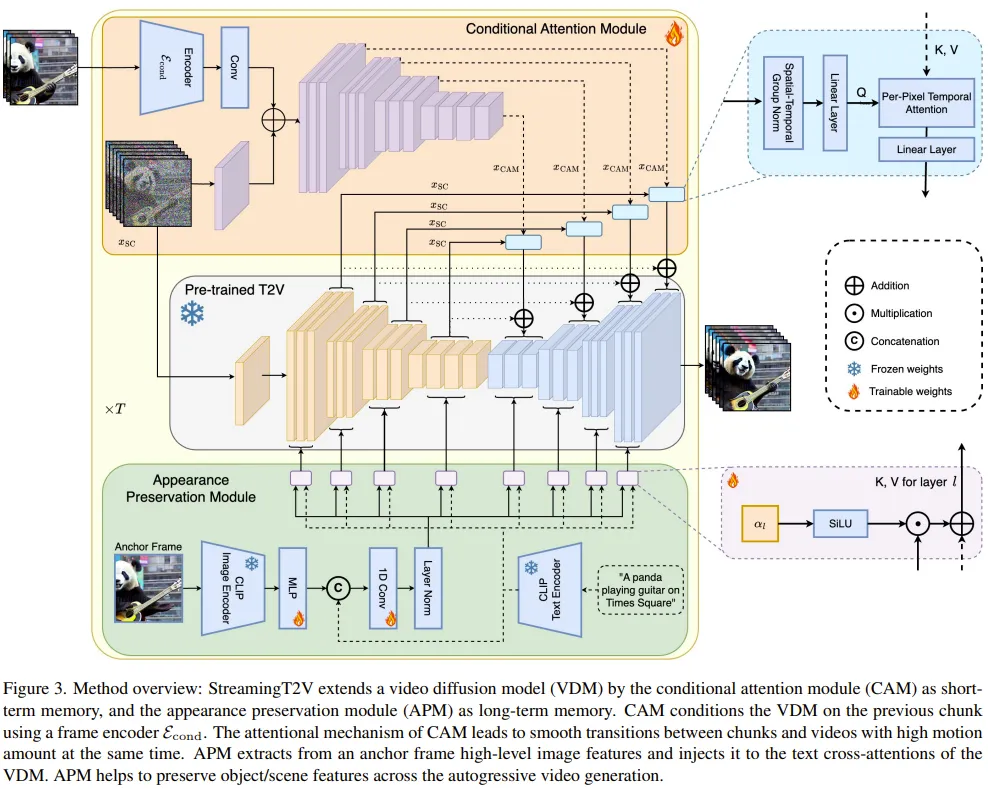
Par conséquent, l'équipe a proposé le. conditions Module d'attention (CAM). CAM utilise son mécanisme d'attention pour intégrer efficacement les informations des images précédentes afin de générer de nouvelles images, et peut gérer librement le mouvement dans les nouvelles images sans être limité par la structure ou la forme des images précédentes.
Afin de résoudre le problème des changements d'apparence des personnes et des objets dans la vidéo générée, l'équipe a également proposé le module de préservation de l'apparence (APM) : il peut extraire les informations d'apparence des objets ou des scènes globales à partir d'une image initiale ( frame d'ancrage) et utilisez ces informations pour réguler le processus de génération vidéo pour tous les blocs vidéo.
Pour améliorer encore la qualité et la résolution de la génération de vidéos longues, l'équipe a amélioré un modèle d'amélioration vidéo pour la tâche de génération autorégressive. Pour ce faire, l'équipe a sélectionné un modèle vidéo Vincent haute résolution et a utilisé la méthode SDEdit pour améliorer la qualité de 24 blocs vidéo consécutifs (avec 8 images superposées).
Pour faciliter la transition d'amélioration des blocs vidéo, ils ont également conçu une méthode de fusion aléatoire qui mélange les blocs vidéo améliorés qui se chevauchent de manière transparente.
Méthode
Tout d'abord, générez une vidéo de 5 secondes à une résolution de 256 × 256 (16 ips), puis améliorez-la à une résolution plus élevée (720 × 720). La figure 2 montre son flux de travail complet.
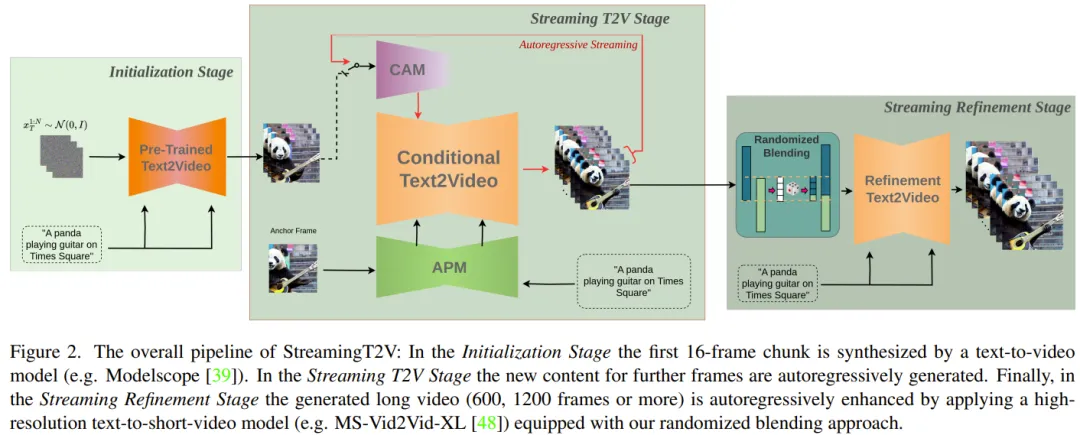
La partie de génération de vidéo longue comprend l'étape d'initialisation et l'étape de streaming T2V.
Parmi eux, la phase d'initialisation utilise un modèle vidéo Vincent pré-entraîné (par exemple, vous pouvez utiliser Modelscope) pour générer le premier bloc vidéo de 16 images tandis que la phase de streaming vidéo Vincent génère les images suivantes de manière autorégressive ; . Nouveau contenu.
Pour le processus autorégressif (voir Figure 3), le CAM nouvellement proposé par l'équipe peut utiliser les informations à court terme des 8 dernières images du bloc vidéo précédent pour obtenir une commutation transparente entre les blocs. En outre, ils utiliseront le module APM récemment proposé pour extraire les informations à long terme d'une image d'ancrage fixe, afin que le processus autorégressif puisse faire face de manière robuste aux changements de choses et aux détails de la scène au cours du processus de génération.
Après avoir généré de longues vidéos (80, 240, 600, 1200 images ou plus), ils améliorent ensuite la qualité de la vidéo grâce à l'étape de raffinement du streaming. Ce processus utilise un modèle vidéo court Vison haute résolution (par exemple, MS-Vid2Vid-XL) de manière autorégressive, associé à une méthode de mélange stochastique récemment proposée pour un traitement transparent des blocs vidéo. De plus, cette dernière étape ne nécessite pas de formation supplémentaire, ce qui rend cette méthode moins coûteuse en calcul.
Module d'attention conditionnelle
Tout d'abord, le modèle vidéo Vincent (court) pré-entraîné utilisé est noté Vidéo-LDM. Le module d'attention (CAM) est constitué d'un extracteur de fonctionnalités et d'un injecteur de fonctionnalités injectés dans Video-LDM UNet.
L'extracteur de fonctionnalités utilise un encodeur d'image image par image, suivi de la même couche d'encodeur utilisée par Video-LDM UNet jusqu'à la couche intermédiaire (et initialisée par le poids d'UNet).
Pour l'injection de fonctionnalités, la conception ici est de permettre à chaque connexion de saut à longue portée dans UNet de se concentrer sur les fonctionnalités correspondantes générées par CAM grâce à une attention croisée.
Module de préservation de l'apparence
Le module APM intègre la mémoire à long terme dans le processus de génération vidéo en utilisant les informations des images d'ancrage fixes. Cela permet de conserver les caractéristiques de la scène et de l'objet pendant la génération du patch vidéo.
Afin qu'APM puisse équilibrer le traitement des informations de guidage fournies par les cadres d'ancrage et les instructions textuelles, l'équipe a apporté deux améliorations : (1) Mélanger le jeton d'image CLIP du cadre d'ancrage avec le jeton de texte CLIP de l'instruction textuelle (2) Un poids est introduit pour chaque couche d'attention croisée afin d'utiliser l'attention croisée.
Amélioration vidéo autorégressive
Pour améliorer de manière autorégressive les blocs vidéo générés de 24 images, un Refiner Video-LDM haute résolution (1280x720) est utilisé ici, voir image 3). Ce processus est effectué en ajoutant d'abord une grande quantité de bruit au bloc vidéo d'entrée, puis en utilisant ce modèle de diffusion vidéo Vincent pour effectuer un traitement de débruitage.
Cependant, cette méthode n'est pas suffisante pour résoudre le problème de l'inadéquation des transitions entre les blocs vidéo.
À cette fin, la solution de l’équipe est une méthode de mélange aléatoire. Veuillez vous référer au document original pour plus de détails.
Expérience
Dans l'expérience, les mesures d'évaluation utilisées par l'équipe comprennent : le score SCuts pour évaluer la cohérence temporelle, l'erreur de torsion sensible au mouvement (MAWE) pour évaluer l'erreur de mouvement et de torsion, le score de similarité texte-image CLIP (CLIP) et score esthétique (AE) pour évaluer la qualité de l’alignement du texte.
Étude d'ablation
Pour évaluer l'efficacité de divers nouveaux composants, l'équipe a réalisé une étude d'ablation sur 75 invites échantillonnées au hasard dans l'ensemble de validation.
CAM pour le traitement conditionnel : CAM aide le modèle à générer des vidéos plus cohérentes, avec des scores SCuts 88 % inférieurs à ceux des autres modèles de base en comparaison.
Mémoire à long terme : La figure 6 montre que la mémoire à long terme peut grandement aider à maintenir la stabilité des caractéristiques des objets et des scènes pendant le processus de génération autorégressive.

Sur une mesure d'évaluation quantitative (score de réidentification de la personne), APM a obtenu une amélioration de 20 %.
Mélange aléatoire pour l'amélioration vidéo : par rapport aux deux autres benchmarks, le mixage aléatoire peut apporter des améliorations de qualité significatives. Cela peut également être vu sur la figure 4 : StreamingT2V peut obtenir des transitions plus fluides.

StreamingT2V par rapport au modèle de base
L'équipe a comparé l'intégration du StreamingT2V amélioré ci-dessus avec plusieurs modèles, y compris la méthode image-vidéo I2VGen en utilisant une approche autorégressive, par le biais de méthodes quantitatives et évaluations qualitatives XL, SVD, DynamiCrafter-XL, SEINE, méthode vidéo à vidéo SparseControl, méthode texte à vidéo longue FreeNoise.
Évaluation quantitative : comme le montre le tableau 8, l'évaluation quantitative sur l'ensemble de test montre que StreamingT2V fonctionne le mieux en termes de transition transparente des blocs vidéo et de cohérence des mouvements. Le score MAWE de la nouvelle méthode est également nettement meilleur que celui de toutes les autres méthodes – voire plus de 50 % inférieur à celui de la deuxième meilleure SEINE. Un comportement similaire est observé dans les scores SCuts.
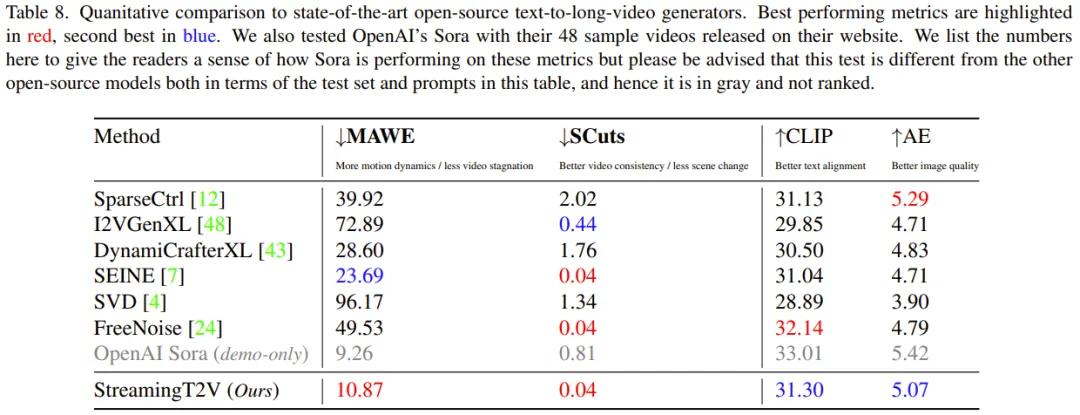
De plus, StreamingT2V n'est que légèrement inférieur à SparseCtrl en termes de qualité d'image unique de la vidéo générée. Cela montre que cette nouvelle méthode est capable de générer de longues vidéos de haute qualité avec une meilleure cohérence temporelle et une meilleure dynamique de mouvement que les autres méthodes de comparaison.
Évaluation qualitative : La figure ci-dessous montre la comparaison des effets du StreamingT2V avec d'autres méthodes. On voit que la nouvelle méthode peut maintenir une meilleure cohérence tout en assurant l'effet dynamique de la vidéo.

Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
 Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Le cœur des instructions Oracle SQL est sélectionné, insérer, mettre à jour et supprimer, ainsi que l'application flexible de diverses clauses. Il est crucial de comprendre le mécanisme d'exécution derrière l'instruction, tel que l'optimisation de l'indice. Les usages avancés comprennent des sous-requêtes, des requêtes de connexion, des fonctions d'analyse et PL / SQL. Les erreurs courantes incluent les erreurs de syntaxe, les problèmes de performances et les problèmes de cohérence des données. Les meilleures pratiques d'optimisation des performances impliquent d'utiliser des index appropriés, d'éviter la sélection *, d'optimiser les clauses et d'utiliser des variables liées. La maîtrise d'Oracle SQL nécessite de la pratique, y compris l'écriture de code, le débogage, la réflexion et la compréhension des mécanismes sous-jacents.
 Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Comment ajouter, modifier et supprimer le guide de fonctionnement du champ de table de données MySQL
Apr 11, 2025 pm 05:42 PM
Guide de fonctionnement du champ dans MySQL: Ajouter, modifier et supprimer les champs. Ajouter un champ: alter table table_name Ajouter Column_name data_type [pas null] [Default default_value] [Clé primaire] [Auto_increment] Modifier le champ: alter table table_name modifie Column_name data_type [pas null] [default default_value] [clé primaire]
 Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Quelles sont les contraintes d'intégrité des tables de base de données Oracle?
Apr 11, 2025 pm 03:42 PM
Les contraintes d'intégrité des bases de données Oracle peuvent garantir la précision des données, notamment: Not Null: les valeurs nulles sont interdites; Unique: garantie l'unicité, permettant une seule valeur nulle; Clé primaire: contrainte de clé primaire, renforcer unique et interdire les valeurs nulles; Clé étrangère: maintenir les relations entre les tableaux, les clés étrangères se réfèrent aux clés primaires primaires; Vérifiez: limitez les valeurs de colonne en fonction des conditions.
 Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Explication détaillée des instances de requête imbriquées dans la base de données MySQL
Apr 11, 2025 pm 05:48 PM
Les requêtes imbriquées sont un moyen d'inclure une autre requête dans une requête. Ils sont principalement utilisés pour récupérer des données qui remplissent des conditions complexes, associer plusieurs tables et calculer des valeurs de résumé ou des informations statistiques. Les exemples incluent la recherche de salaires supérieurs aux employés, la recherche de commandes pour une catégorie spécifique et le calcul du volume des commandes totales pour chaque produit. Lorsque vous écrivez des requêtes imbriquées, vous devez suivre: écrire des sous-requêtes, écrire leurs résultats sur les requêtes extérieures (référencées avec des alias ou en tant que clauses) et optimiser les performances de la requête (en utilisant des index).
 Que fait Oracle
Apr 11, 2025 pm 06:06 PM
Que fait Oracle
Apr 11, 2025 pm 06:06 PM
Oracle est la plus grande société de logiciels de gestion de base de données au monde (SGBD). Ses principaux produits incluent les fonctions suivantes: Outils de développement du système de gestion de la base de données relationnels (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud Service (Oracle Cloud Infrastructure) Analyse et Oracle Blockchain Pla Intelligence (Oracle Analytic
 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
