

L'heure du Mamba est arrivée ?
Depuis la publication du document de recherche fondateur « Attention is All You Need » en 2017, l'architecture des transformateurs a dominé le domaine de l'intelligence artificielle générative.
Cependant, l'architecture du Transformer présente en réalité deux inconvénients importants :
L'empreinte mémoire de Transformer varie en fonction de la longueur du contexte. Cela rend difficile l'exécution de longues fenêtres contextuelles ou un traitement parallèle massif sans ressources matérielles importantes, limitant ainsi l'expérimentation et le déploiement à grande échelle. L'empreinte mémoire des modèles Transformer évolue avec la longueur du contexte, ce qui rend difficile l'exécution de longues fenêtres de contexte ou un traitement fortement parallèle sans ressources matérielles importantes, limitant ainsi l'expérimentation et le déploiement à grande échelle.
Le mécanisme d'attention dans le modèle Transformer ajustera la vitesse en fonction de l'augmentation de la longueur du contexte. Ce mécanisme augmentera de manière aléatoire la longueur de la séquence et réduira le coût de calcul, car chaque jeton dépend de la séquence entière qui le précède, ainsi. réduire le contexte Appliqué en dehors du cadre d’une production efficace.
Transformer n'est pas la seule voie à suivre pour l'intelligence artificielle de production. Récemment, AI21 Labs a lancé et open source une nouvelle méthode appelée « Jamba » qui surpasse le transformateur sur plusieurs benchmarks.

Adresse Hugging Face : https://huggingface.co/ai21labs/Jamba-v0.1
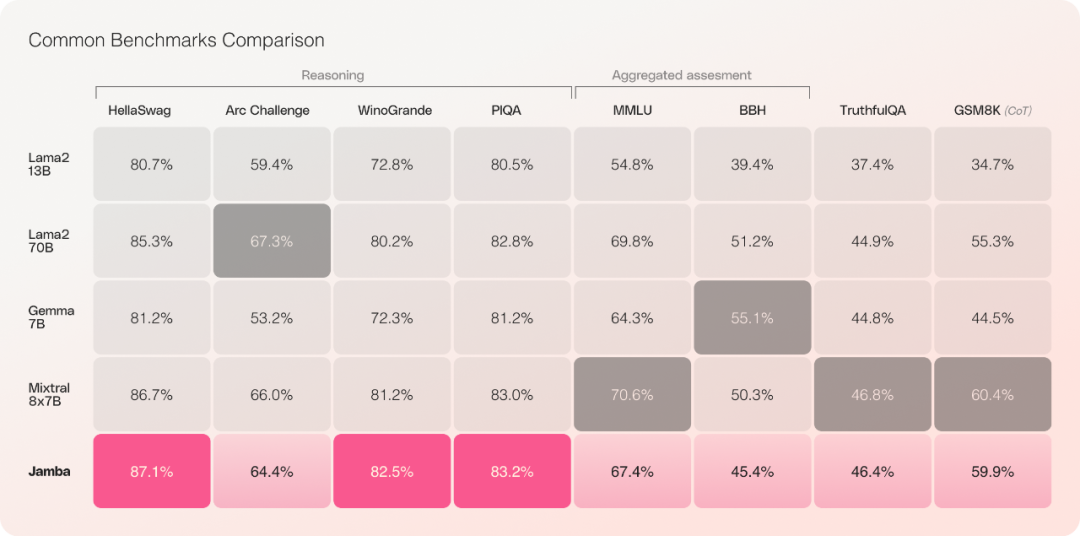
L'architecture SSM de Mamba peut bien résoudre les ressources mémoire et les problèmes de contexte du transformateur. Cependant, l’approche Mamba a du mal à fournir le même niveau de sortie que le modèle avec transformateur.
Jamba combine le modèle Mamba basé sur le modèle spatial à états structurés (SSM) avec l'architecture du transformateur, dans le but de combiner les meilleures propriétés du SSM et du transformateur.

Jamba est également accessible depuis le catalogue API NVIDIA en tant que microservice d'inférence NVIDIA NIM, que les développeurs d'applications d'entreprise peuvent déployer à l'aide de la plate-forme logicielle NVIDIA AI Enterprise.
En général, le modèle Jamba présente les caractéristiques suivantes :
Le premier modèle de niveau production basé sur Mamba, utilisant la nouvelle architecture hybride SSM-Transformer
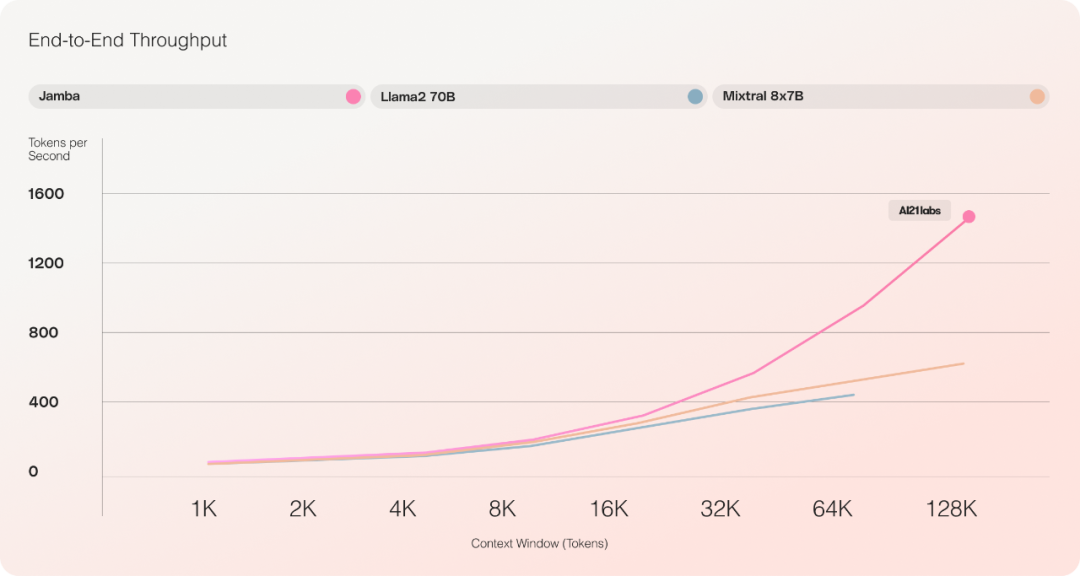
Par rapport à Mixtral 8x7B, contexte long Le débit est ; augmenté de 3 fois ;
donne accès à 256 000 fenêtres contextuelles ;
expose les poids des modèles
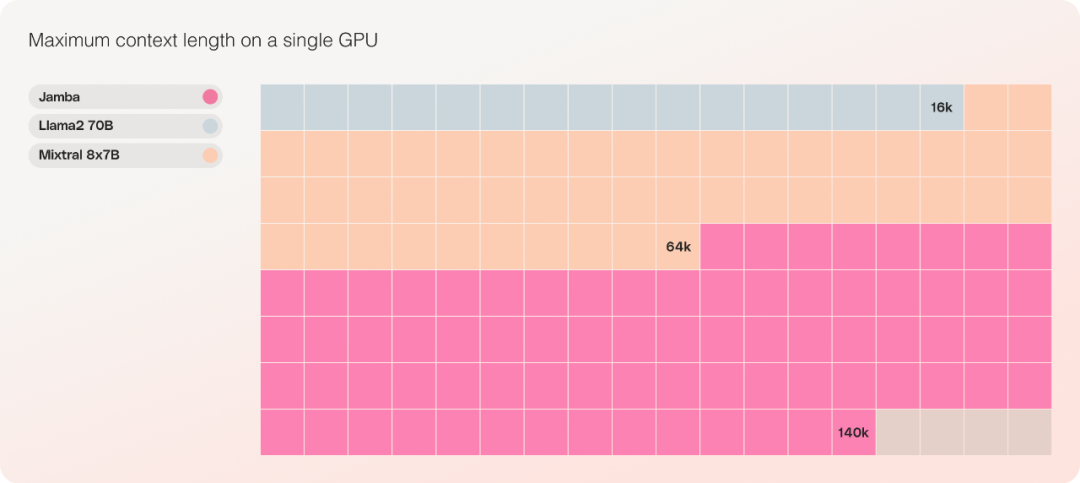
Le seul modèle de la même échelle de paramètres pouvant accueillir jusqu'à 140 000 contextes sur un seul GPU.
Architecture modèle
Comme le montre la figure ci-dessous, l'architecture de Jamba adopte une approche blocs et couches, permettant à Jamba d'intégrer les deux architectures. Chaque bloc Jamba est constitué d'une couche d'attention ou couche Mamba, suivie d'un perceptron multicouche (MLP), formant une couche de transformateur.
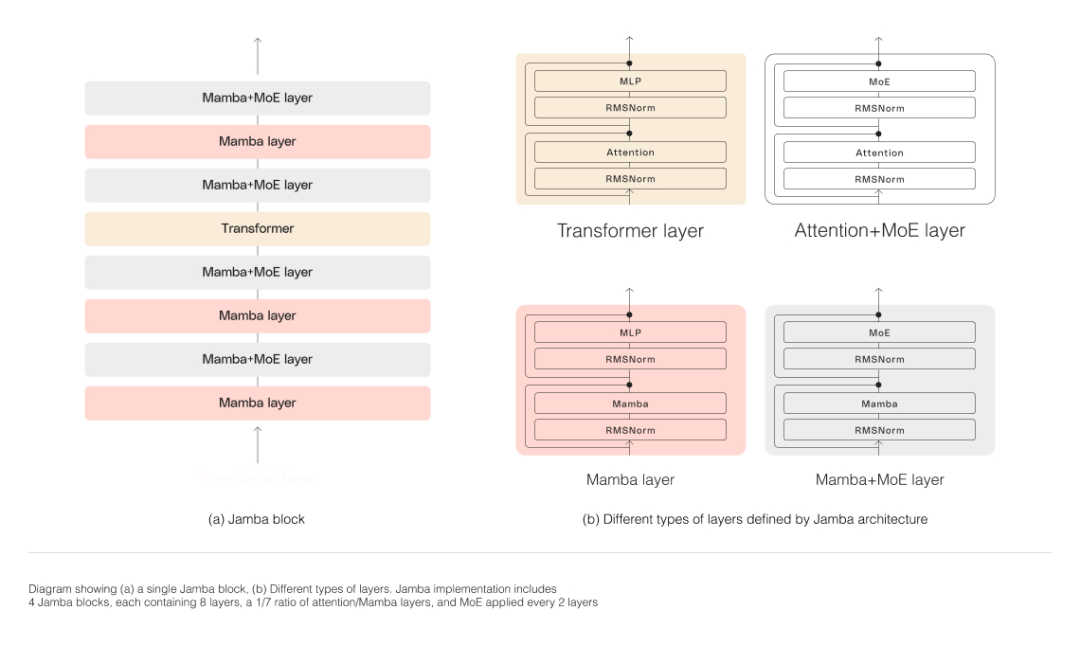
Jamba exploite MoE pour augmenter le nombre total de paramètres du modèle tout en simplifiant le nombre de paramètres actifs utilisés dans l'inférence, ce qui entraîne une capacité de modèle plus élevée sans augmentation correspondante des exigences de calcul. Pour maximiser la qualité et le débit du modèle sur un seul GPU de 80 Go, l'équipe de recherche a optimisé le nombre de couches MoE et d'experts utilisés, laissant suffisamment de mémoire pour les charges de travail d'inférence courantes.
La couche MoE de Jamba lui permet d'utiliser seulement 12B des 52B paramètres disponibles au moment de l'inférence, et son architecture hybride rend ces 12B paramètres actifs plus efficaces qu'un modèle de transformateur pur de même taille.
Personne n'a encore étendu Mamba au-delà des paramètres 3B. Jamba est la première architecture hybride de ce type à atteindre l'échelle de production.
Débit et efficacité
Les expériences d'évaluation préliminaires montrent que Jamba fonctionne bien sur des indicateurs clés tels que le débit et l'efficacité.
En termes d'efficacité, Jamba atteint 3x le débit de Mixtral 8x7B sur des contextes longs. Jamba est plus efficace que les modèles basés sur Transformer de taille similaire tels que Mixtral 8x7B.
En termes de coût, Jamba peut accueillir 140 000 contextes sur un seul GPU. Jamba offre plus d'opportunités de déploiement et d'expérimentation que les autres modèles open source actuels de taille similaire.
Il convient de noter qu'il est actuellement peu probable que Jamba remplace les grands modèles de langage (LLM) actuels basés sur Transformer, mais il pourrait devenir un complément dans certains domaines.
Lien de référence :
https://www.ai21.com/blog/announcing-jamba
https://venturebeat.com/ai/ai21-labs-juices-up- gen-ai-transformers-avec-jamba/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 vim sauvegarder et quitter la commande
vim sauvegarder et quitter la commande
 Comment définir la variable d'environnement de chemin
Comment définir la variable d'environnement de chemin
 Méthode de migration de base de données MySQL
Méthode de migration de base de données MySQL
 Tutoriel de modification du logiciel C++ en chinois
Tutoriel de modification du logiciel C++ en chinois
 La différence entre l'API de repos et l'API
La différence entre l'API de repos et l'API
 Comment utiliser l'atelier MySQL
Comment utiliser l'atelier MySQL
 Comment utiliser la fonction nanosleep
Comment utiliser la fonction nanosleep
 Quelles sont les méthodes pour redémarrer les applications sous Android ?
Quelles sont les méthodes pour redémarrer les applications sous Android ?
 utilisation du champ d'application de la transaction
utilisation du champ d'application de la transaction








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



