

Une photo + une vidéo peuvent donner vie à la photo !
Récemment, Champ, un travail de génération de vision humaine contrôlable publié conjointement par Alibaba, l'Université de Fudan et l'Université de Nanjing, est devenu populaire partout sur Internet. Ce modèle n'est open source que depuis 5 jours et a reçu 1 000 étoiles sur GitHub. Il est devenu très populaire sur Twitter, attirant un grand nombre de blogueurs pour créer de nouveaux projets, et le nombre total de vues a atteint 300 000.
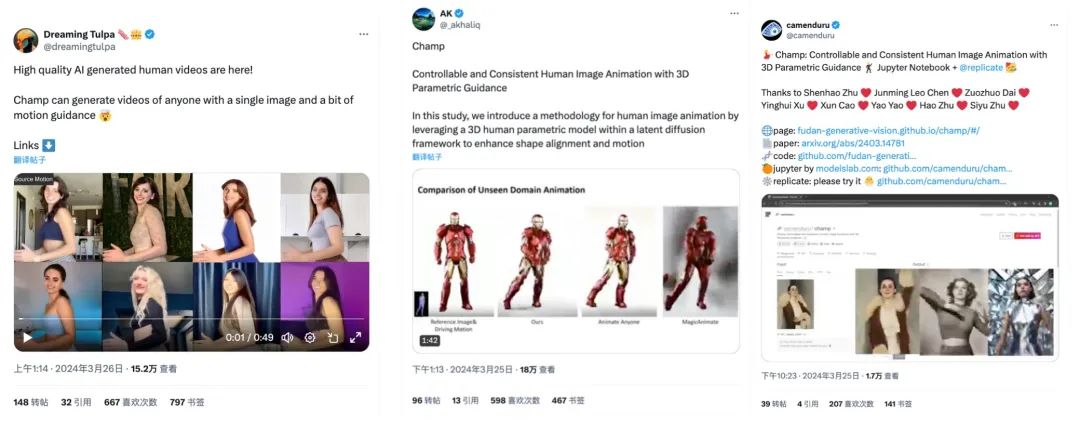
Actuellement, Champ a open source le code d'inférence et les poids, et les utilisateurs peuvent les télécharger et les utiliser directement depuis Github. La démo officielle Hugging Face a été lancée et le Champ-ComfyUI encapsulé est également promu simultanément. La page d'accueil de GitHub montre que l'équipe ouvrira prochainement le code de formation et les ensembles de données. Les partenaires intéressés peuvent continuer à prêter attention à la dynamique du projet. 
Page d'accueil du projet : https://fudan-generative-vision.github.io/champ/
Lien papier : https://arxiv.org/abs/2403.14781
Lien Github : https ://github.com/fudan-generative-vision/champ
Hugging Face Link : https://huggingface.co/fudan-generative-ai/champ
Effet vidéo Champ sur des portraits du monde réel, ce qui permet à différents portraits de "copier" la même action, en prenant comme entrée la vidéo d'action du coin supérieur gauche.

Bien que Champ ne soit formé qu'avec de vraies vidéos de corps humain, il a démontré une forte capacité de généralisation sur différents types d'images :

Les photos en noir et blanc, les peintures à l'huile, les aquarelles et d'autres effets sont remarquables, et il fonctionne bien sur différents types d'images. Images réalistes générées par des modèles graphiques, y compris des personnages virtuels :

Aperçu technique
Champ utilise un modèle avancé de récupération de maillage humain pour extraire le corps humain tridimensionnel paramétré correspondant du corps humain tridimensionnel paramétré correspondant. entrée vidéo du corps humain La séquence SMPL du modèle de maillage (Skinned Multi-Person Linear Model) restitue en outre la carte de profondeur correspondante, la carte normale, la posture humaine et la carte sémantique humaine, qui sont utilisées comme conditions de contrôle de mouvement correspondantes pour guider la génération vidéo et transférer des actions vers l'entrée Sur le portrait de référence, cela peut améliorer considérablement la qualité de la vidéo du mouvement humain, ainsi que la cohérence géométrique et de l'apparence.
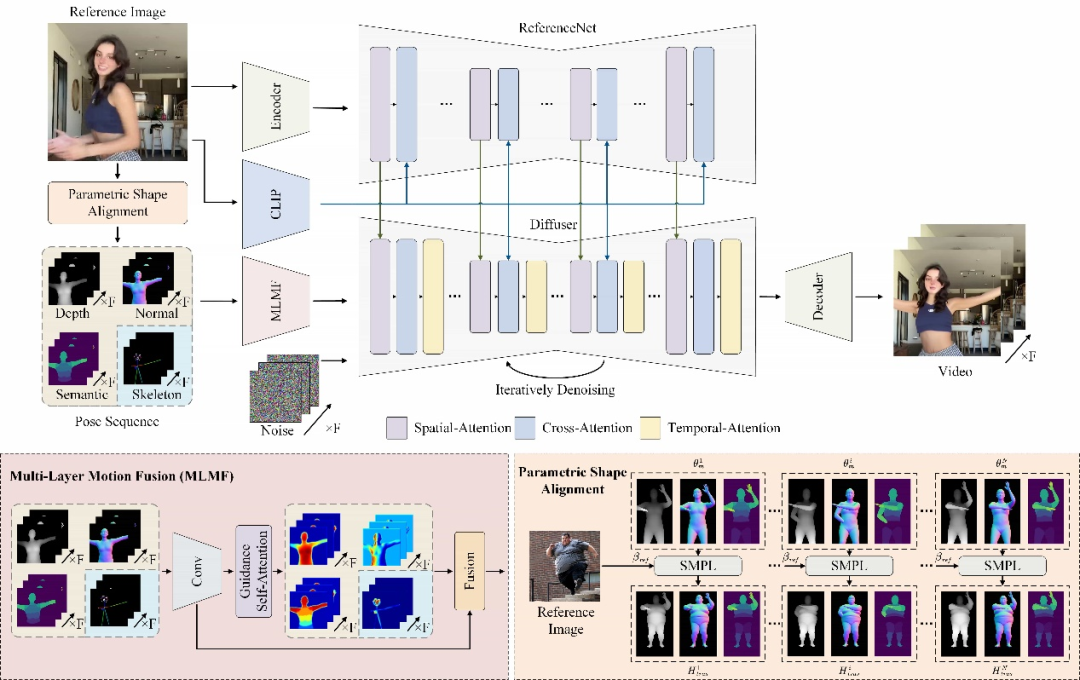
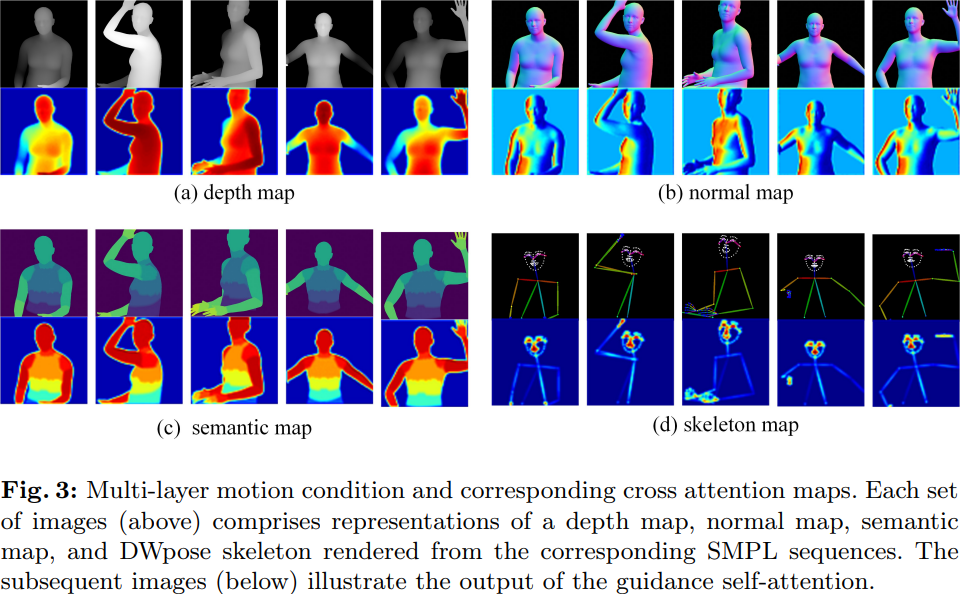
Pour différentes conditions de mouvement, Champ utilise un module de fusion de mouvement multicouche (MLMF), qui utilise le mécanisme d'auto-attention pour intégrer pleinement les caractéristiques entre différentes conditions afin d'obtenir un contrôle de mouvement plus raffiné. La figure suivante montre les résultats de visualisation de l'attention de ce module dans différentes conditions : la carte de profondeur se concentre sur les informations de contour géométrique de la forme humaine, la carte normale indique l'orientation du corps humain, la carte sémantique contrôle la correspondance d'apparence des différentes parties. du corps humain et du squelette de la posture humaine. Il se concentre uniquement sur les détails clés du visage et des mains.
D'un autre côté, Champ a découvert et résolu le problème de la migration de la forme du corps qui a été ignoré dans la génération de vidéos humaines. Les travaux antérieurs étaient soit basés sur le modèle du squelette humain, soit sur d'autres informations géométriques obtenues à partir de la vidéo d'entrée pour piloter le mouvement de la figure humaine. Cependant, ces méthodes n'ont pas réussi à dissocier le mouvement de la forme du corps humain, ce qui a généré le résultat. les résultats sont incompatibles avec le corps humain dans l’image de référence.
Par exemple, étant donné une grosse personne comme image de référence, le résultat de la comparaison est présenté dans la figure 7 ci-dessous :

On peut voir que dans les résultats générés par Animate Any et MagicAnimate, le gros ventre est lissé, même Le cadre a également un peu rétréci. Champ utilise les paramètres de forme du corps dans SMPL pour l'aligner sur la séquence SMPL qui pilote la vidéo dans une forme de corps paramétrée, obtenant ainsi la meilleure cohérence dans la forme du corps et l'action (avec PST dans l'image).
Résultats expérimentaux
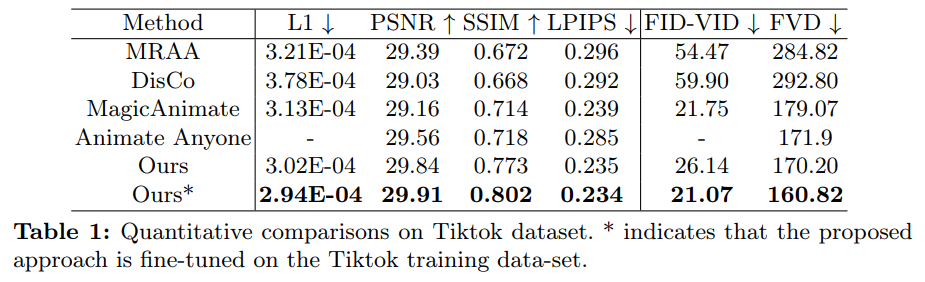
Comme le montre le tableau 4 ci-dessous, comparé à d'autres travaux SOTA, Champ a un meilleur contrôle de mouvement et moins d'artefacts :

Dans le même temps, Champ démontre également ses performances de généralisation supérieures et sa stabilité dans la correspondance d'apparence :


Pour plus de détails techniques et de résultats expérimentaux, veuillez vous référer à l'article et au code originaux de Champ. Vous pouvez également accéder à HuggingFace ou télécharger le code source officiel pour une expérience pratique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Tutoriel de saisie de symboles pleine largeur
Tutoriel de saisie de symboles pleine largeur
 Outils de téléchargement et d'installation Linux courants
Outils de téléchargement et d'installation Linux courants
 Comment résoudre l'erreur 0xc000409
Comment résoudre l'erreur 0xc000409
 Qu'est-ce qu'un lecteur optique
Qu'est-ce qu'un lecteur optique
 Comment utiliser l'expression de point d'interrogation en langage C
Comment utiliser l'expression de point d'interrogation en langage C
 Utilisation de la commande source sous Linux
Utilisation de la commande source sous Linux
 Quels sont les systèmes d'exploitation mobiles ?
Quels sont les systèmes d'exploitation mobiles ?
 Activer le numéro qq
Activer le numéro qq
 Quelle devise est MULTI ?
Quelle devise est MULTI ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



