
 Périphériques technologiques
IA
DeepMind met fin à l'illusion des grands modèles ? L'étiquetage des faits est plus fiable que celui des humains, 20 fois moins cher et entièrement open source
Périphériques technologiques
IA
DeepMind met fin à l'illusion des grands modèles ? L'étiquetage des faits est plus fiable que celui des humains, 20 fois moins cher et entièrement open source
DeepMind met fin à l'illusion des grands modèles ? L'étiquetage des faits est plus fiable que celui des humains, 20 fois moins cher et entièrement open source

L'illusion des grands modèles touche enfin à sa fin ?
Aujourd'hui, une publication sur la plateforme de médias sociaux Reddit a suscité de vives discussions parmi les internautes. L'article traite d'un article « Factualité longue dans les grands modèles de langage » soumis hier par Google DeepMind. Les méthodes et les résultats proposés dans l'article font conclure que l'illusion des grands modèles de langage n'est plus un problème.

Nous savons que les grands modèles linguistiques génèrent souvent du contenu contenant des erreurs factuelles lorsqu'ils répondent à des questions de recherche de faits sur des sujets ouverts. DeepMind a mené des recherches exploratoires sur ce phénomène.
Pour évaluer la factualité longue d'un modèle dans le domaine ouvert, les chercheurs ont utilisé GPT-4 pour générer LongFact, un ensemble d'invites contenant 38 sujets et des milliers de questions. Ils ont ensuite proposé d'utiliser le Search Augmented Fact Evaluator (SAFE) pour utiliser l'agent LLM comme évaluateur automatique de la factualité détaillée. L’objectif de SAFE est d’améliorer l’exactitude des évaluateurs de crédibilité factuelle.
Concernant SAFE, l'utilisation de LLM peut expliquer plus précisément l'exactitude de chaque instance. Ce processus de raisonnement en plusieurs étapes consiste à envoyer une requête de recherche à la recherche Google et à déterminer si les résultats de la recherche prennent en charge une instance spécifique.

Adresse papier : https://arxiv.org/pdf/2403.18802.pdf
Adresse GitHub : https://github.com/google-deepmind/long-form-factuality
De plus, les chercheurs ont proposé d'étendre le score F1 (F1@K) en un indicateur global pratique de forme longue. Ils équilibrent le pourcentage de faits pris en charge dans la réponse (précision) avec le pourcentage de faits fournis par rapport à un hyperparamètre qui représente la longueur de réponse préférée de l'utilisateur (rappel).
Les résultats empiriques montrent que les agents LLM peuvent atteindre des performances de notation supérieures à celles des humains. Sur un ensemble d'environ 16 000 faits individuels, SAFE était d'accord avec les annotateurs humains dans 72 % des cas, et sur un sous-ensemble aléatoire de 100 cas de désaccord, SAFE a atteint un taux de victoire de 76 %. Dans le même temps, SAFE est plus de 20 fois moins cher que les annotateurs humains.
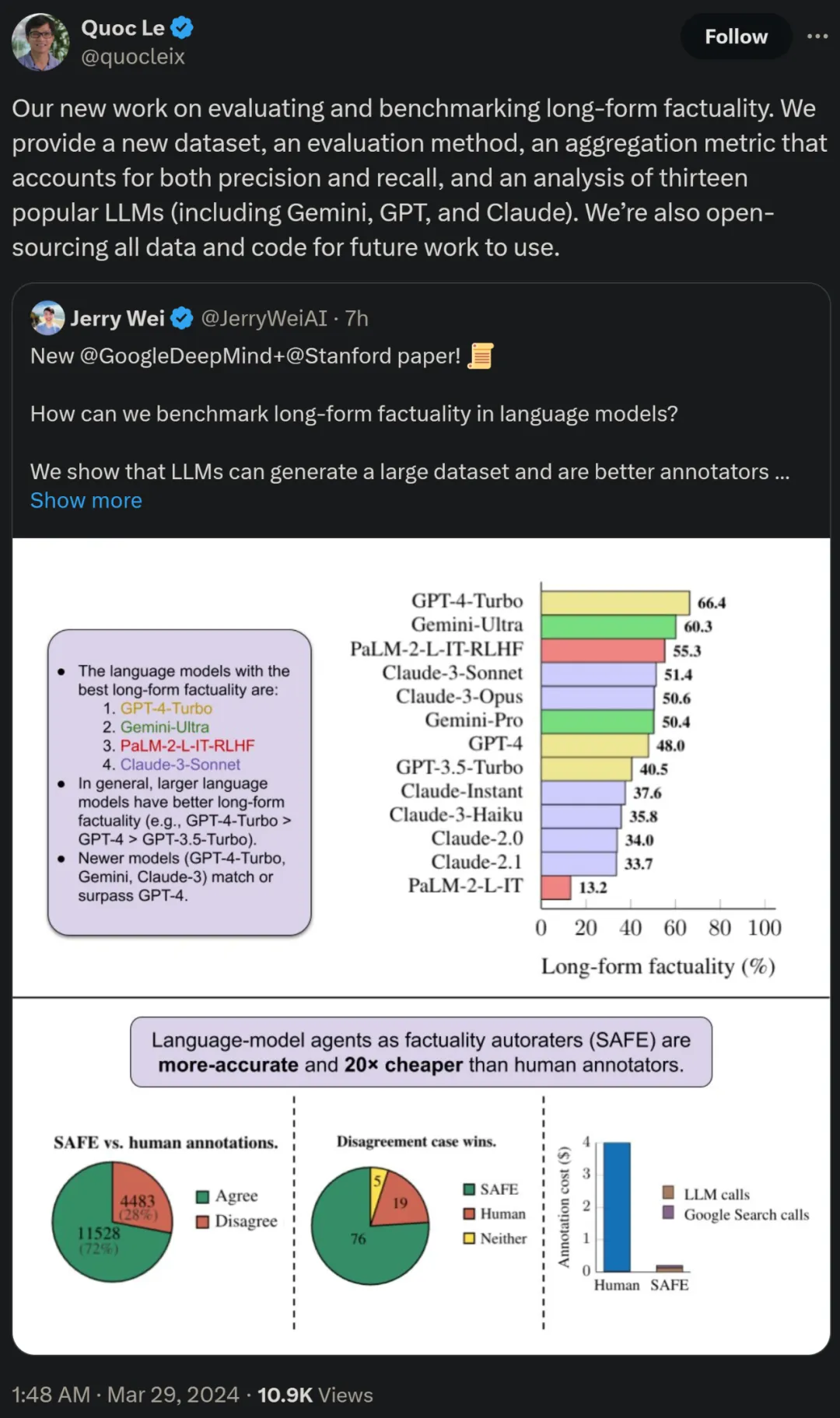
Les chercheurs ont également utilisé LongFact pour comparer 13 modèles de langage populaires dans quatre grandes séries de modèles (Gemini, GPT, Claude et PaLM-2), et ont constaté que des modèles de langage plus grands peuvent généralement obtenir de meilleurs résultats.
Quoc V. Le, l'un des auteurs de l'article et chercheur scientifique chez Google, a déclaré que ce nouveau travail sur l'évaluation et l'analyse comparative de la factualité longue durée propose un nouvel ensemble de données, une nouvelle méthode d'évaluation et une méthode qui équilibre la précision et la métrique agrégée de rappel. Dans le même temps, toutes les données et tous les codes seront open source pour les travaux futurs.
Présentation de la méthode
LONGFACT : Utiliser LLM pour générer de longs benchmarks factuels multi-sujets
Premier aperçu de l'ensemble d'invites LongFact généré à l'aide de GPT-4, qui contient 2 280 invites de recherche de faits qui nécessitait des réponses détaillées sur 38 sujets sélectionnés manuellement. Les chercheurs affirment que LongFact est le premier ensemble d’invites permettant d’évaluer la factualité détaillée dans divers domaines.
LongFact contient deux tâches : LongFact-Concepts et LongFact-Objects, distinguées selon que la question porte sur des concepts ou des objets. Les chercheurs ont généré 30 indices uniques pour chaque sujet, ce qui a donné 1 140 indices pour chaque tâche.

SAFE : agent LLM comme évaluateur automatique factuel
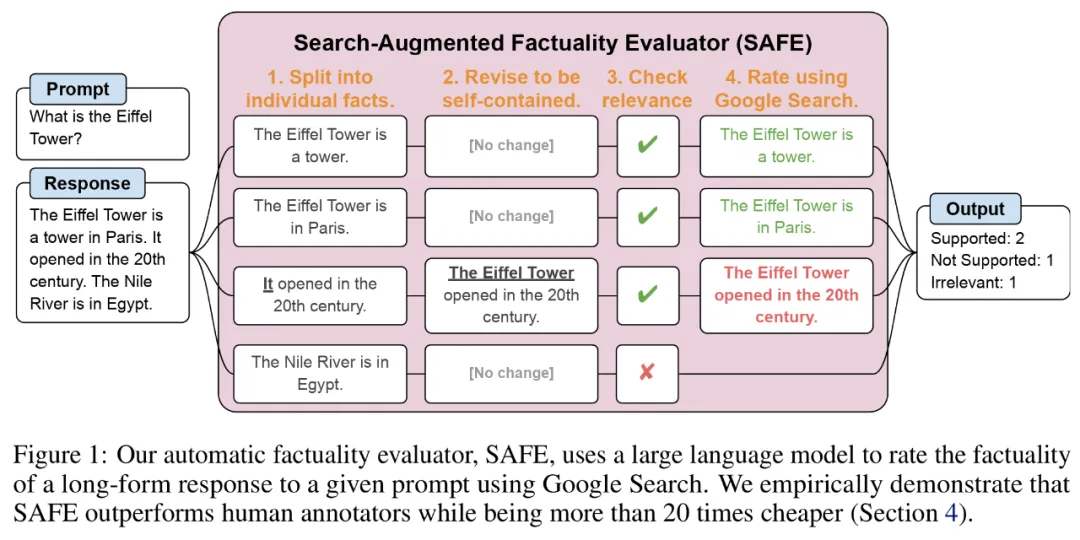
Les chercheurs ont proposé le Search Augmented Fact Evaluator (SAFE), et son principe de fonctionnement est le suivant :
a) Split réponses longues en faits indépendants distincts
b) Déterminer si chaque fait individuel est pertinent pour répondre à l'invite dans son contexte
;c) Pour chaque fait pertinent, lancez de manière itérative une requête de recherche Google dans un processus en plusieurs étapes et déterminez si les résultats de la recherche soutiennent ce fait.
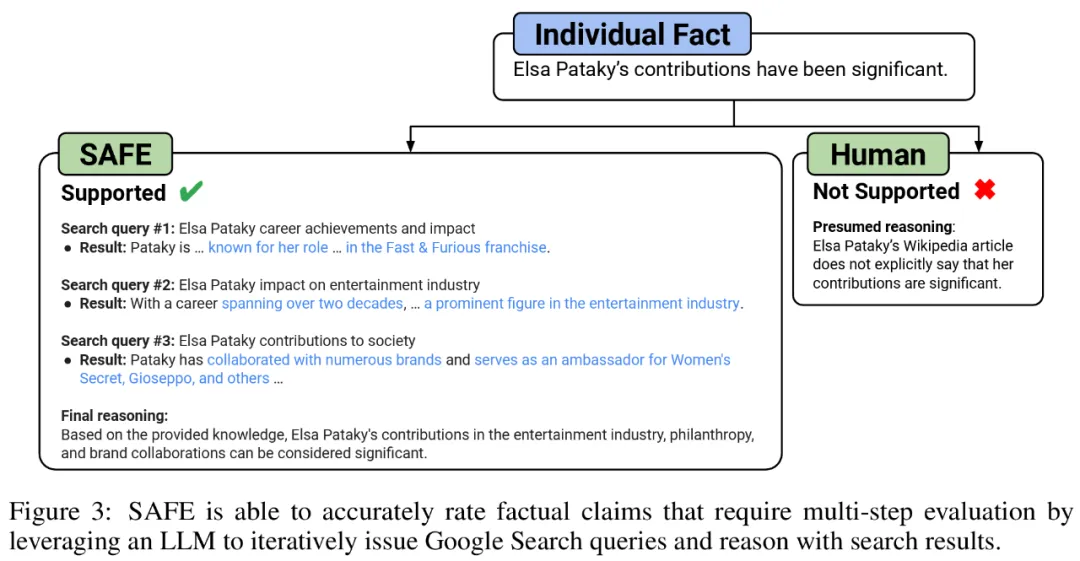
Ils pensent que l'innovation clé de SAFE est d'utiliser des modèles linguistiques comme agents pour générer des requêtes de recherche Google en plusieurs étapes et de réfléchir soigneusement pour savoir si les résultats de la recherche soutiennent les faits. La figure 3 ci-dessous montre un exemple de chaîne de raisonnement.
Pour diviser la réponse longue en faits indépendants distincts, les chercheurs ont d'abord incité le modèle linguistique à diviser chaque phrase de la réponse longue en faits distincts, puis ont ordonné au modèle de séparer les références ambiguës telles que les pronoms) avec les entités correctes auxquelles elles font référence dans le contexte de réponse, modifiant chaque fait individuel pour qu'il soit indépendant.
Pour noter chaque fait indépendant, ils utilisent un modèle de langage pour déterminer si ce fait est pertinent par rapport à l'invite répondue dans le contexte de réponse, puis utilisent une méthode en plusieurs étapes pour évaluer chaque fait pertinent restant comme « pris en charge ». ou "non pris en charge". Les détails sont présentés dans la figure 1 ci-dessous.
A chaque étape, le modèle génère une requête de recherche basée sur les faits à noter et les résultats de recherche précédemment obtenus. Après un certain nombre d'étapes, le modèle effectue une inférence pour déterminer si les résultats de la recherche confirment ce fait, comme le montre la figure 3 ci-dessus. Une fois que tous les faits ont été évalués, les mesures de sortie de SAFE pour une paire invite-réponse donnée sont le nombre de faits « à l'appui », le nombre de faits « non pertinents » et le nombre de faits « non pris en charge ».
Résultats expérimentaux
Les agents LLM deviennent de meilleurs annotateurs de faits que les humains
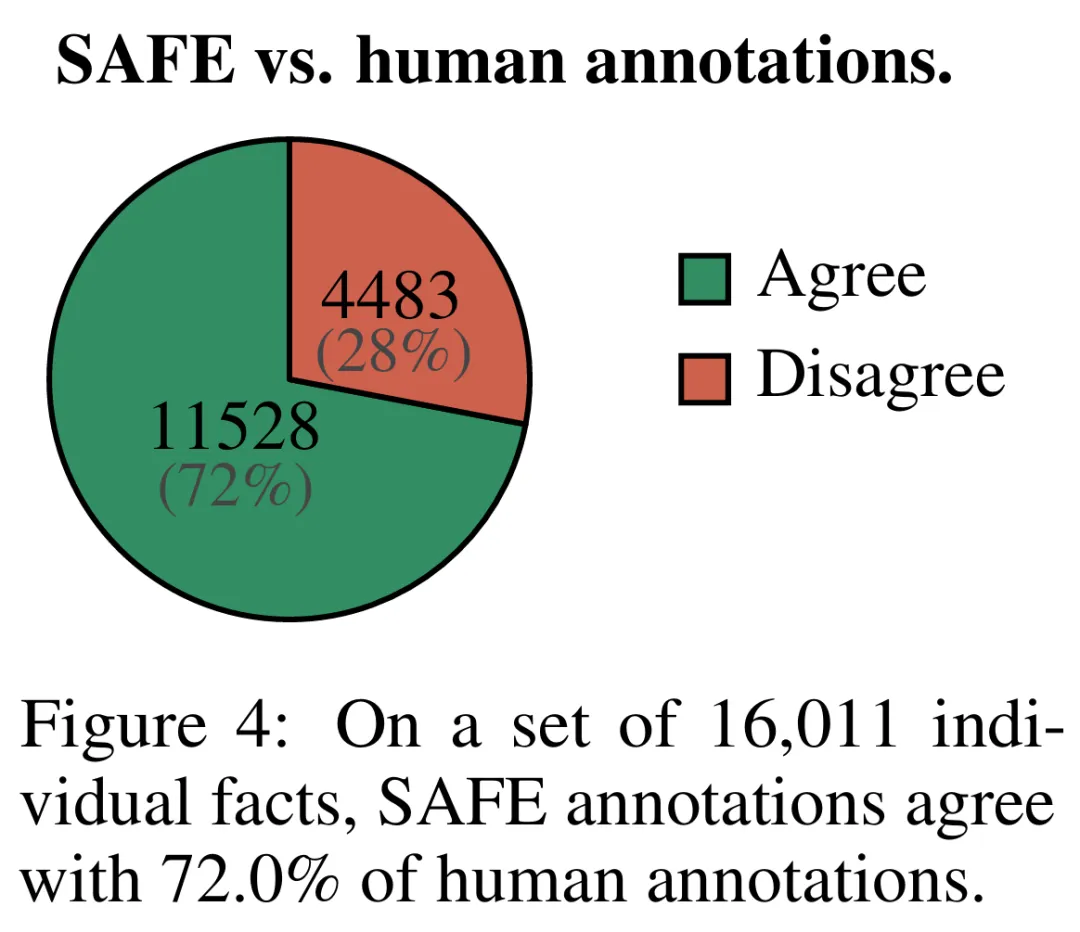
Pour évaluer quantitativement la qualité des annotations obtenues à l'aide de SAFE, les chercheurs ont utilisé des annotations humaines participatives. Les données contiennent 496 paires de réponses rapides, où les réponses ont été divisées manuellement en faits individuels (16 011 faits individuels au total), et chaque fait individuel a été manuellement étiqueté comme étant pris en charge, non pertinent ou non pris en charge.
Ils ont comparé directement les annotations SAFE et les annotations humaines pour chaque fait et ont constaté que SAFE était d'accord avec les humains sur 72,0 % des faits individuels, comme le montre la figure 4 ci-dessous. Cela montre que SAFE atteint des performances de niveau humain sur la plupart des faits individuels. Un sous-ensemble de 100 faits individuels issus d'entretiens aléatoires a ensuite été examiné pour lesquels les annotations de SAFE n'étaient pas cohérentes avec celles des évaluateurs humains.
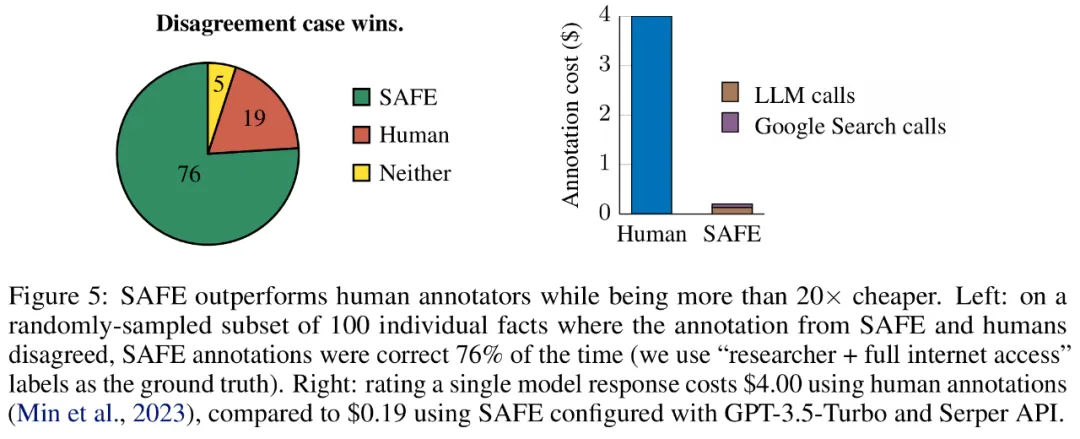
Les chercheurs ont réannoté manuellement chaque fait (permettant d'accéder à la recherche Google, et pas seulement à Wikipédia, pour une annotation plus complète) et ont utilisé ces étiquettes comme vérité terrain. Ils ont constaté que dans ces cas de désaccord, les annotations SAFE étaient correctes dans 76 % des cas, tandis que les annotations humaines n'étaient correctes que dans 19 % des cas, ce qui représente un taux de victoire de 4 contre 1 pour SAFE. Les détails sont présentés dans la figure 5 ci-dessous.
Ici, les prix des deux plans d'annotation méritent qu'on s'y attarde. Le coût de l'évaluation d'une réponse de modèle unique à l'aide d'annotations humaines est de 4 $, tandis que le SAFE utilisant GPT-3.5-Turbo et l'API Serper n'est que de 0,19 $.
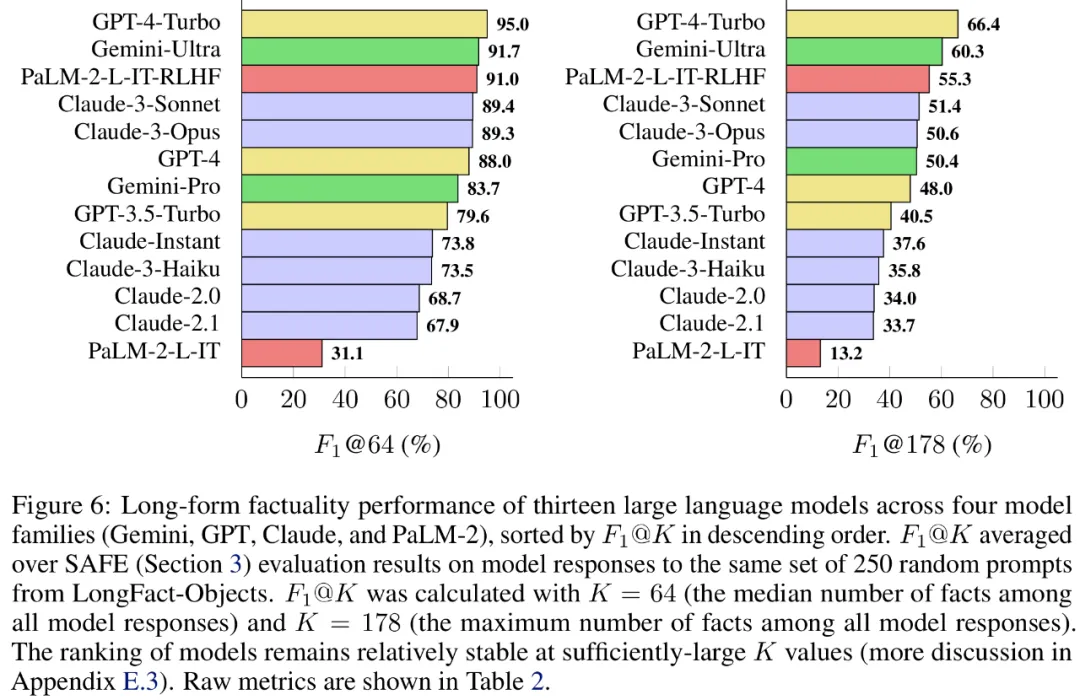
Tests de référence des séries Gemini, GPT, Claude et PaLM-2
Enfin, les chercheurs ont mené LongFact sur les quatre séries de modèles (Gemini, GPT, Claude et PaLM-2) dans le tableau 1. ci-dessous. 2) Réalisation de tests de référence approfondis sur 13 grands modèles de langage.
Plus précisément, ils ont évalué chaque modèle en utilisant le même sous-ensemble aléatoire de 250 indices dans LongFact-Objects, puis ont utilisé SAFE pour obtenir les métriques d'évaluation brutes de la réponse de chaque modèle et ont utilisé la polymérisation métrique F1@K.

Il a été constaté qu'en général, les modèles linguistiques plus grands permettent d'obtenir une meilleure factualité longue durée. Comme le montrent la figure 6 et le tableau 2 ci-dessous, GPT-4-Turbo est meilleur que GPT-4, GPT-4 est meilleur que GPT-3.5-Turbo, Gemini-Ultra est meilleur que Gemini-Pro et PaLM-2-L. -IT-RLHF Mieux que PaLM-2-L-IT.
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
