
 Périphériques technologiques
IA
Le nouveau cadre de l'Université Jiao Tong de Shanghai débloque les capacités de texte long CLIP, saisit les détails de la génération multimodale et améliore considérablement les capacités de récupération d'images
Périphériques technologiques
IA
Le nouveau cadre de l'Université Jiao Tong de Shanghai débloque les capacités de texte long CLIP, saisit les détails de la génération multimodale et améliore considérablement les capacités de récupération d'images
Le nouveau cadre de l'Université Jiao Tong de Shanghai débloque les capacités de texte long CLIP, saisit les détails de la génération multimodale et améliore considérablement les capacités de récupération d'images

La capacité de texte long CLIP est déverrouillée et les performances des tâches de récupération d'images sont considérablement améliorées !
Certains détails clés peuvent également être capturés. L'Université Jiao Tong de Shanghai et le Shanghai AI Laboratory ont proposé un nouveau cadre Long-CLIP.
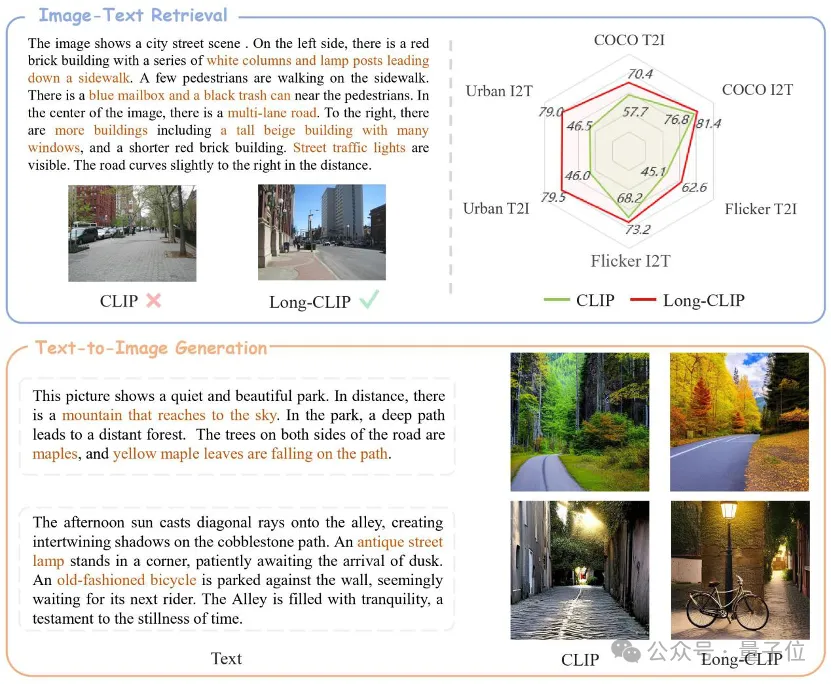
△Le texte marron est le détail clé qui distingue les deux images
Long-CLIP est basé sur le maintien de l'espace de fonctionnalités d'origine de CLIP et est plug-and-play dans les tâches en aval telles que la génération d'images pour obtenir de bons résultats. génération d'images à granularité de texte long.
La récupération de texte-image longue a augmenté de 20 %, la récupération de texte-image courte a augmenté de 6 %.
Débloquez les capacités de texte long de CLIP
CLIP aligne les modalités visuelles et textuelles et dispose de puissantes capacités de généralisation sans tir. Par conséquent, CLIP est largement utilisé dans diverses tâches multimodales, telles que la classification d'images, la récupération d'images texte, la génération d'images, etc.
Mais un inconvénient majeur de CLIP est le manque de capacités de texte long.
Tout d'abord, en raison de l'utilisation du codage de position absolue, la longueur de saisie du texte de CLIP est limitée à 677 jetons. De plus, des expériences ont prouvé que la longueur effective réelle de CLIP est même inférieure à 20 jetons, ce qui est loin d'être suffisant pour représenter des informations précises. Cependant, pour surmonter cette limitation, des chercheurs ont proposé une solution. En introduisant des balises spécifiques dans la saisie de texte, le modèle peut se concentrer sur les parties importantes. La position et le nombre de ces jetons dans l'entrée sont déterminés à l'avance et ne dépasseront pas 20 jetons. De cette manière, CLIP est capable de gérer la saisie de texte. L'absence de texte long côté texte limite également les capacités du côté visuel. Puisqu'il ne contient que du texte court, l'encodeur visuel de CLIP n'extrairea que les composants les plus importants d'une image, tout en ignorant divers détails. Ceci est très préjudiciable aux tâches plus fines telles que la
récupération multimodale. Dans le même temps, l'absence de texte long amène également CLIP à adopter une méthode de modélisation simple similaire au bag-of-feature (BOF), qui n'a pas de capacités complexes telles que le raisonnement causal.
Pour résoudre ce problème, les chercheurs ont proposé le modèle Long-CLIP.
Propose spécifiquement deux stratégies : l'étirement de l'intégration positionnelle préservant les connaissances et une stratégie de réglage fin qui ajoute l'alignement des composants de base (correspondance des composants primaires). 
Extension du codage positionnel préservant les connaissances
Une méthode simple pour étendre la longueur d'entrée et améliorer la capacité du texte long consiste d'abord à interpoler le codage positionnel à un rapport fixe λ
1, puis à l'affiner au fil du temps. texte. Les chercheurs ont découvert que le degré de formation des différents encodages de position du CLIP est différent. Étant donné que le texte d'apprentissage est susceptible d'être principalement un texte court, le codage de position inférieure est entraîné de manière plus complète et peut représenter avec précision la position absolue, tandis que le codage de position supérieure ne peut représenter que sa position relative approximative. Par conséquent, le coût de l’interpolation des codes à différentes positions est différent.
Sur la base des observations ci-dessus, le chercheur a retenu les 20 premiers codes de position, et pour les 57 codes de position restants, interpolés avec un rapport plus grand λ
2 La formule de calcul peut être exprimée comme suit :
Expérience Cela montre que. par rapport à l'interpolation directe, cette stratégie peut améliorer considérablement les performances de diverses tâches tout en prenant en charge une longueur totale plus longue. 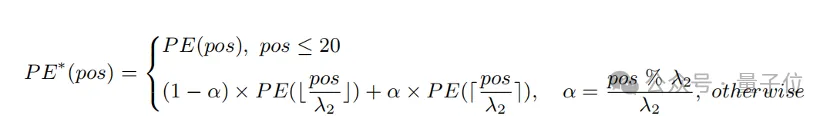
Ajouter un réglage fin de l'alignement des attributs de base
Seule l'introduction d'un réglage fin du texte long conduira le modèle à un autre malentendu, qui consiste à inclure tous les détails de la même manière. Pour résoudre ce problème, les chercheurs ont introduit la stratégie d’alignement des attributs de base lors du réglage fin.
Plus précisément, les chercheurs ont utilisé l'algorithme d'analyse en composantes principales (ACP) pour extraire les attributs de base des caractéristiques d'image à granularité fine, ont filtré les attributs restants pour reconstruire les caractéristiques d'image à granularité grossière et les ont comparés à des textes courts résumés. Cette stratégie nécessite que le modèle contienne non seulement plus de détails (alignement à granularité fine), mais qu'il identifie et modélise également la plupart des attributs essentiels (extraction des composants principaux et alignement à granularité grossière).
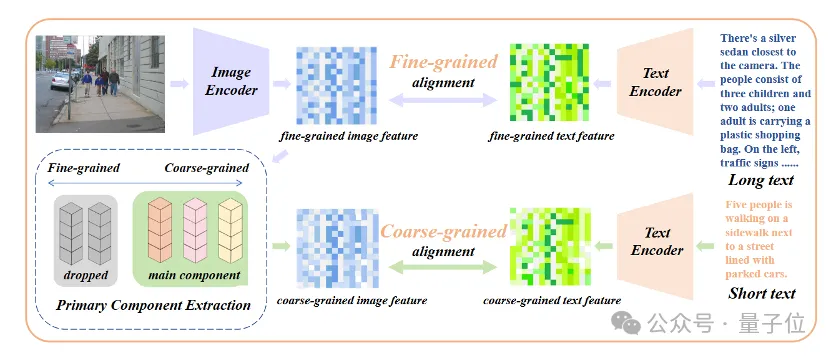 △Ajoutez le processus de réglage fin de l'alignement des attributs de base
△Ajoutez le processus de réglage fin de l'alignement des attributs de base
Plug and play dans diverses tâches multimodales
Dans les domaines de la récupération d'images et de texte, de la génération d'images et d'autres domaines, Long-CLIP peut brancher et jouer pour remplacer CLIP.
Par exemple, dans la récupération d'images et de texte, Long-CLIP peut capturer des informations plus fines en modes image et texte, améliorant ainsi la capacité de distinguer des images et du texte similaires et améliorant considérablement les performances de récupération d'images et de texte.
Qu'il s'agisse de tâches traditionnelles de récupération de texte court (COCO, Flickr30k) ou de tâches de récupération de texte long, Long-CLIP a considérablement amélioré le taux de rappel.
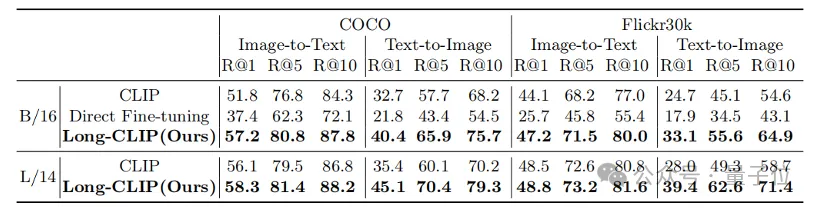
△Résultats expérimentaux de récupération de texte-image courte
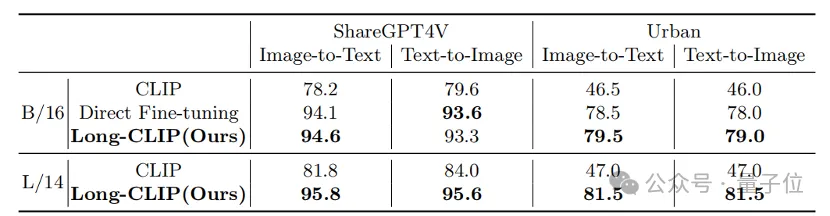
△Résultats expérimentaux de récupération de texte-image longue

△Visualisation de récupération de texte-image longue, le texte marron est le détail clé qui distingue les deux images
De plus, l'encodeur de texte de CLIP est souvent utilisé dans les modèles de génération de texte en image, tels que la série de diffusion stable, etc. Cependant, en raison du manque de fonctionnalités de texte long, les descriptions textuelles utilisées pour générer des images sont généralement très courtes et ne peuvent pas être personnalisées avec divers détails.
Long-CLIP peut dépasser la limite de 77 jetons et réaliser une génération d'images au niveau du chapitre (en bas à droite).
Vous pouvez également modéliser plus de détails dans 77 jetons pour obtenir une génération d'images plus fines (en haut à droite).

Lien papier :https://arxiv.org/abs/2403.15378
Lien code :https://github.com/beichenzbc/Long-CLIP
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
