
 Périphériques technologiques
IA
Pour rendre le transformateur de pose vidéo rapide, l'Université de Pékin propose un cadre efficace d'estimation de pose humaine 3D HoT
Périphériques technologiques
IA
Pour rendre le transformateur de pose vidéo rapide, l'Université de Pékin propose un cadre efficace d'estimation de pose humaine 3D HoT
Pour rendre le transformateur de pose vidéo rapide, l'Université de Pékin propose un cadre efficace d'estimation de pose humaine 3D HoT

Actuellement, Video Pose Transformer (VPT) a atteint les performances les plus importantes dans le domaine de l'estimation de pose humaine 3D basée sur la vidéo. Ces dernières années, la charge de travail informatique de ces VPT est devenue de plus en plus importante, et ces énormes charges de travail informatique ont également limité le développement ultérieur dans ce domaine. Il est très hostile aux chercheurs disposant de ressources informatiques insuffisantes. Par exemple, la formation d'un modèle VPT de 243 images prend généralement plusieurs jours, ce qui ralentit considérablement la progression de la recherche et devient un problème majeur dans le domaine qui doit être résolu de toute urgence.
Alors, comment améliorer efficacement l'efficacité du VPT sans presque perdre en précision ?
Une équipe de l'Université de Pékin a proposé un cadre efficace d'estimation de pose humaine 3D HoT basé sur le sablier Tokenizer pour résoudre le problème des exigences informatiques élevées du Video Pose Transformer (VPT) existant. Le framework peut être plug-and-play et intégré de manière transparente dans des modèles tels que MHFormer, MixSTE et MotionBERT, réduisant ainsi les calculs du modèle de près de 40 % sans perte de précision. Le code est open source.

- Titre : Hourglass Tokenizer for Efficient Transformer-Based 3D Human Pose Estimation
- Adresse papier : https://arxiv.org/abs/2311.1202
- Adresse du code : https://github.com/NationalGAILab/HoT


Motivation de recherche
Dans le modèle VPT, chaque image de la vidéo est généralement traitée en Un jeton de pose autonome qui atteint des performances supérieures en traitant des séquences vidéo d'une longueur de centaines d'images (généralement de 243 à 351 images) et conserve une représentation de séquence complète sur toutes les couches du Transformer. Cependant, étant donné que la complexité informatique du mécanisme d'auto-attention dans VPT est proportionnelle au carré du nombre de jetons (c'est-à-dire le nombre d'images vidéo), ces modèles entraînent inévitablement d'énormes inefficacités lors du traitement des entrées vidéo avec une résolution de série temporelle plus élevée. La surcharge de calcul rend difficile leur déploiement à grande échelle dans des applications pratiques avec des ressources informatiques limitées. De plus, cette façon de traiter la séquence entière ne prend pas en compte la redondance au sein de la séquence vidéo, notamment la redondance entre des images consécutives où les changements visuels ne sont pas évidents, de sorte que la duplication de ces informations non seulement ajoute une charge de calcul inutile, mais dans une large mesure, n’apporte pas une contribution substantielle à l’amélioration des performances du modèle.
Par conséquent, afin d'obtenir un VPT efficace, cet article estime que deux facteurs doivent être pris en compte en premier :
-
Le champ de réception temporel doit être grand : bien que raccourcir directement la longueur de la séquence d'entrée puisse améliorer la l'efficacité du VPT, ce faisant, cela réduira le champ de réception temporel du modèle, limitant ainsi la capacité du modèle à capturer des informations spatio-temporelles riches, limitant ainsi l'amélioration des performances. Par conséquent, le maintien d’un champ récepteur temporel étendu est crucial pour obtenir une estimation précise lors de la poursuite de stratégies de conception efficaces.
- La redondance vidéo doit être supprimée : en raison de la similitude des actions entre les images adjacentes, les vidéos contiennent souvent une grande quantité d'informations redondantes. De plus, les recherches existantes ont souligné que dans l'architecture Transformer, à mesure que les couches s'approfondissent, les différences entre les jetons deviennent de plus en plus petites. Par conséquent, on peut en déduire que l’utilisation du jeton Pose complet dans les couches profondes de Transformer introduira des calculs redondants inutiles, et ces calculs redondants auront une contribution limitée aux résultats d’estimation finaux.
Sur la base de ces deux observations, l'auteur propose d'élaguer le Pose Token du deep Transformer pour réduire la redondance des images vidéo tout en améliorant l'efficacité globale du VPT. Cependant, cela soulève un nouveau défi : l'opération d'élagage entraîne une réduction du nombre de jetons. À l'heure actuelle, le modèle ne peut pas estimer directement le nombre de résultats d'estimation de pose tridimensionnelle qui correspondent à la séquence vidéo originale. En effet, dans le modèle VPT traditionnel, chaque jeton correspond généralement à une image de la vidéo, et la séquence restante après l'élagage ne sera pas suffisante pour couvrir toutes les images de la vidéo originale. Cela pose problème lors de l'estimation du volume tridimensionnel. la pose humaine de toutes les images de la vidéo devient un obstacle important. Par conséquent, afin d’obtenir un VPT efficace, un autre facteur important doit être pris en considération :
- Raisonnement Seq2seq : un véritable système d'estimation de pose humaine 3D devrait être capable d'effectuer un raisonnement rapide via seq2seq, c'est-à-dire d'estimer les poses humaines 3D de toutes les images de la vidéo d'entrée à la fois. Par conséquent, afin de parvenir à une intégration transparente avec le cadre VPT existant et d'obtenir un raisonnement rapide, il est nécessaire de garantir l'intégrité de la séquence de jetons, c'est-à-dire de récupérer un jeton complet égal au nombre d'images vidéo d'entrée.
Sur la base des trois considérations ci-dessus, l'auteur propose un cadre d'estimation de pose humaine tridimensionnelle efficace basé sur la structure du sablier, ⏳ Hourglass Tokenizer (HoT). De manière générale, cette méthode présente deux points forts majeurs :
- Simple Baseline, un framework universel et efficace basé sur Transformer
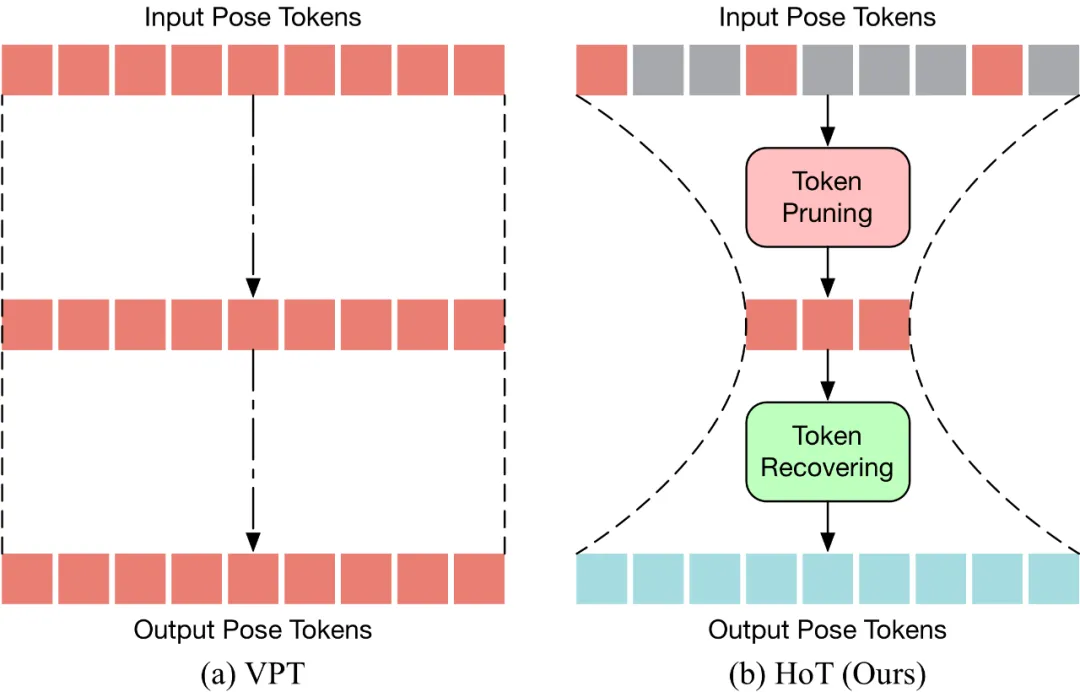
HoT est la première estimation efficace de pose humaine 3D basée sur Transformer A plug- cadre de jeu et de jeu. Comme le montre la figure ci-dessous, le VPT traditionnel adopte un paradigme « rectangulaire », c'est-à-dire qu'il conserve toute la longueur du Pose Token dans toutes les couches du modèle, ce qui entraîne des coûts de calcul élevés et une redondance des fonctionnalités. Différent du VPT traditionnel, HoT élague d'abord pour supprimer les jetons redondants, puis restaure toute la séquence de jetons (ressemblant à un "sablier"), de sorte que seule une petite quantité de jetons soit conservée dans la couche intermédiaire du transformateur, ce qui est ainsi efficace. améliorer l’efficacité du modèle. HoT fait également preuve d'une polyvalence extrêmement élevée. Non seulement il peut être intégré de manière transparente aux modèles VPT conventionnels, qu'il s'agisse de VPT basés sur seq2seq ou seq2frame, mais il peut également être adapté à diverses stratégies d'élagage et de récupération de jetons.
- L'efficacité et la précision
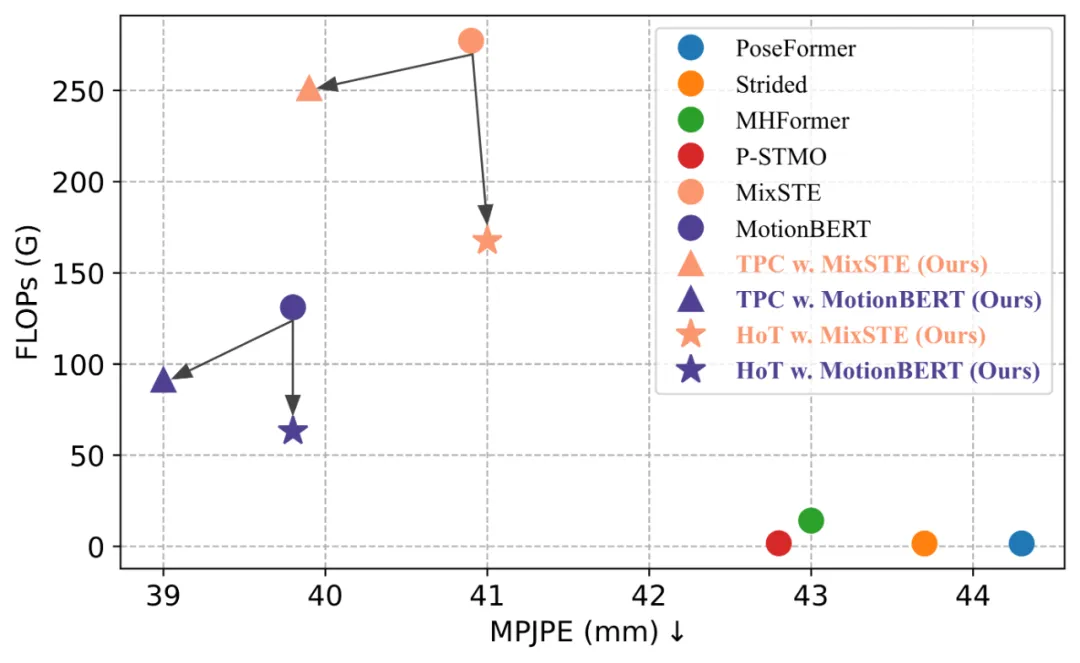
HoT a révélé que le maintien de la séquence de poses complète est redondant et que l'utilisation d'un petit nombre d'images représentatives de Pose Token peut simultanément atteindre des niveaux élevés. Efficacité et haute performance. Par rapport au modèle VPT traditionnel, HoT améliore non seulement considérablement l'efficacité du traitement, mais permet également d'obtenir des résultats très compétitifs, voire meilleurs. Par exemple, il peut réduire les FLOP de MotionBERT de près de 50 % sans sacrifier les performances, tout en réduisant les FLOP de MixSTE de près de 40 % avec seulement une légère baisse de performances de 0,2 %. Le cadre global de HoT proposé par
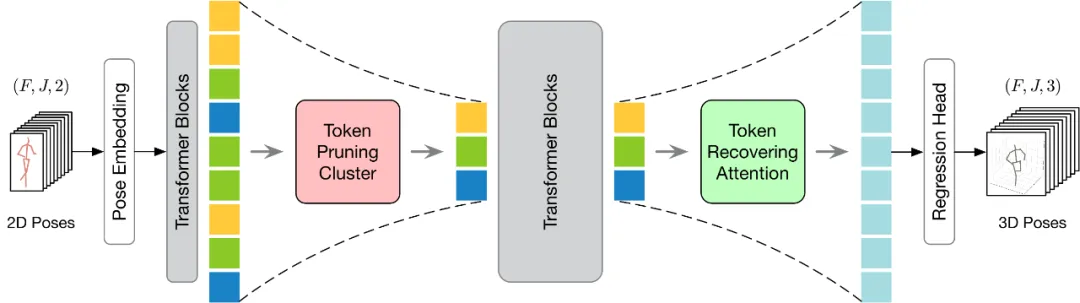
méthode modèle
est présenté dans la figure ci-dessous. Afin d'effectuer plus efficacement l'élagage et la récupération des jetons, cet article propose deux modules : Token Pruning Cluster (TPC) et Token Recovering Attention (TRA). Parmi eux, le module TPC sélectionne dynamiquement un petit nombre de jetons représentatifs avec une grande diversité sémantique tout en atténuant la redondance des images vidéo. Le module TRA récupère des informations spatio-temporelles détaillées sur la base de jetons sélectionnés, étendant ainsi la sortie du réseau à la résolution temporelle complète d'origine pour une inférence rapide.
Module d'élagage et de regroupement de jetons
Cet article estime qu'il est difficile de sélectionner un petit nombre de jetons de pose avec des informations riches pour une estimation précise de la pose humaine en trois dimensions.
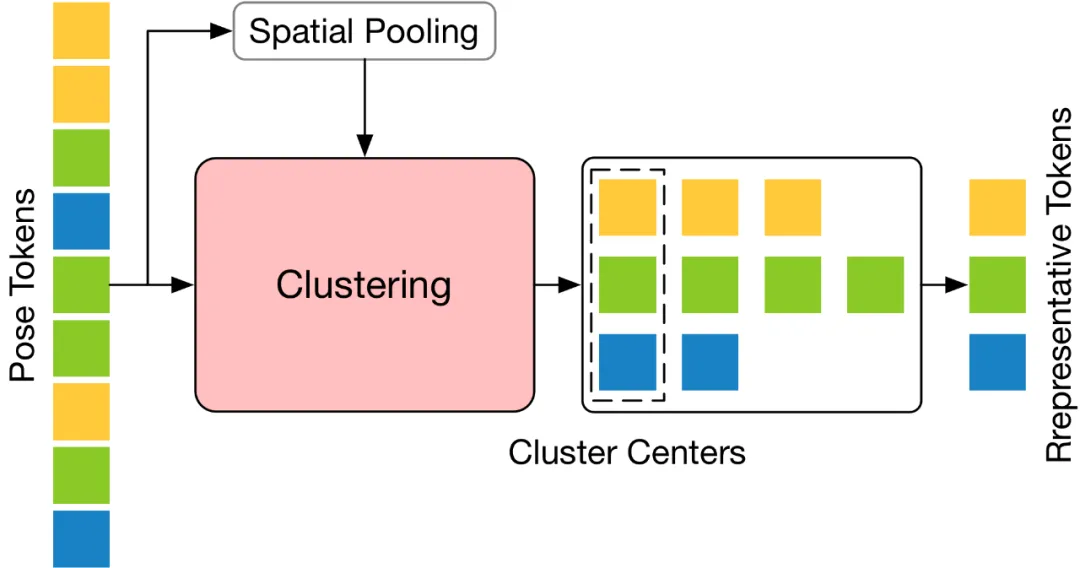
Afin de résoudre ce problème, cet article estime que la clé est de sélectionner ces jetons représentatifs avec une grande diversité sémantique, car ces jetons peuvent conserver les informations nécessaires tout en réduisant la redondance vidéo. Basé sur ce concept, cet article propose un module Token Pruning Cluster (TPC) simple et efficace qui ne nécessite aucun paramètre supplémentaire. Le cœur de ce module est d'identifier et de supprimer les jetons qui contribuent peu sémantiquement, et de se concentrer sur les jetons qui peuvent fournir des informations clés pour l'estimation finale de la pose humaine en trois dimensions. En utilisant un algorithme de clustering, TPC sélectionne dynamiquement le centre du cluster comme jeton représentatif, utilisant ainsi les caractéristiques du centre du cluster pour conserver la riche sémantique des données d'origine. La structure de
TPC est illustrée dans la figure ci-dessous. Il regroupe d'abord le jeton de pose d'entrée dans la dimension spatiale, puis utilise la similarité des caractéristiques du jeton regroupé pour regrouper le jeton d'entrée et sélectionner le centre du cluster. jeton représentatif.
Module d'attention de restauration de jeton
Le module TPC réduit efficacement le nombre de jetons de pose. Cependant, la diminution de la résolution temporelle provoquée par l'opération d'élagage limite le VPT pour une inférence seq2seq rapide. Par conséquent, le jeton doit être restauré. Dans le même temps, compte tenu des facteurs d'efficacité, le module de récupération doit être conçu pour être léger afin de minimiser l'impact sur le coût de calcul global du modèle.
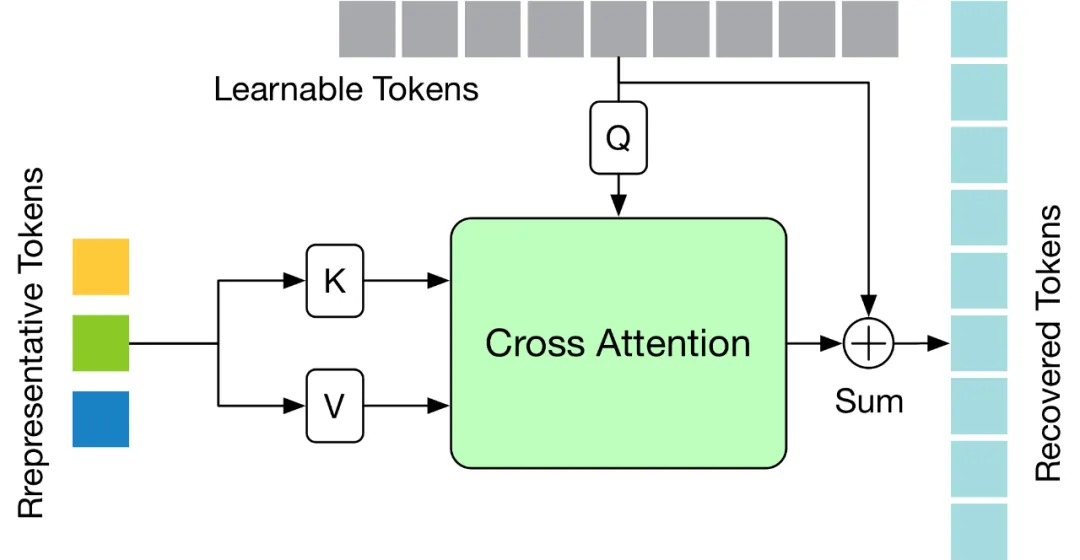
Afin de résoudre les défis ci-dessus, cet article conçoit un module léger de récupération d'attention (TRA) de jeton, qui peut récupérer des informations spatio-temporelles détaillées en fonction du jeton sélectionné. De cette manière, la faible résolution temporelle provoquée par l'opération d'élagage est efficacement étendue à la résolution temporelle de la séquence complète d'origine, permettant au réseau d'estimer la séquence de poses humaines tridimensionnelles de toutes les images à la fois, obtenant ainsi un raisonnement seq2seq rapide. La structure du module
TRA est illustrée dans la figure ci-dessous. Il utilise les jetons représentatifs de la dernière couche de Transformer et les jetons apprenables initialisés à zéro pour récupérer la séquence complète de jetons via un simple mécanisme d'attention croisée.
Appliquée au VPT existant
Avant d'expliquer comment appliquer la méthode proposée au VPT existant, cet article résume d'abord l'architecture VPT existante. Comme le montre la figure ci-dessous, l'architecture VPT se compose principalement de trois composants : un module d'intégration de pose pour coder les informations spatiales et temporelles de la séquence de pose, un transformateur multicouche pour l'apprentissage de la représentation spatio-temporelle globale et un module de tête de régression pour la régression. produire des résultats de posture humaine 3D.
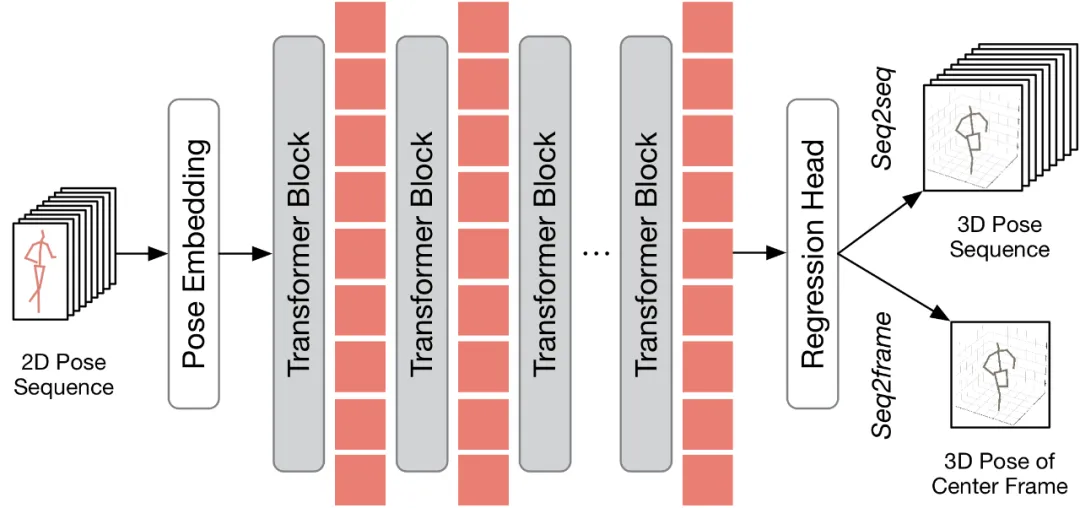
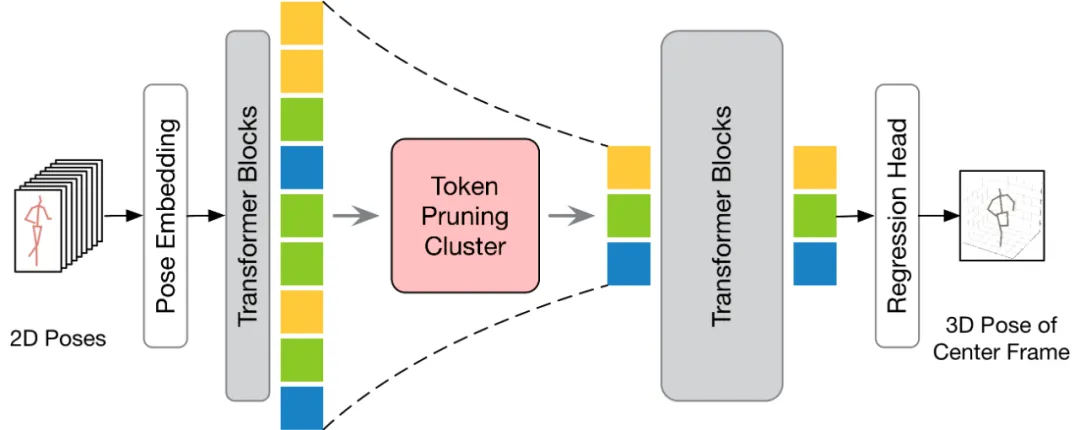
Selon le nombre de trames de sortie, le VPT existant peut être divisé en deux processus d'inférence : seq2frame et seq2seq. Dans le pipeline seq2seq, la sortie correspond à toutes les images de la vidéo d'entrée, la résolution temporelle complète d'origine doit donc être restaurée. Comme le montre le diagramme du cadre HoT, les modules TPC et TRA sont intégrés dans VPT. Dans le processus seq2frame, le résultat est la pose 3D de l'image centrale de la vidéo. Par conséquent, dans ce processus, le module TRA est inutile et seul le module TPC est intégré dans le VPT. Son cadre est présenté dans la figure ci-dessous.
Résultats expérimentaux
Expérience d'ablation
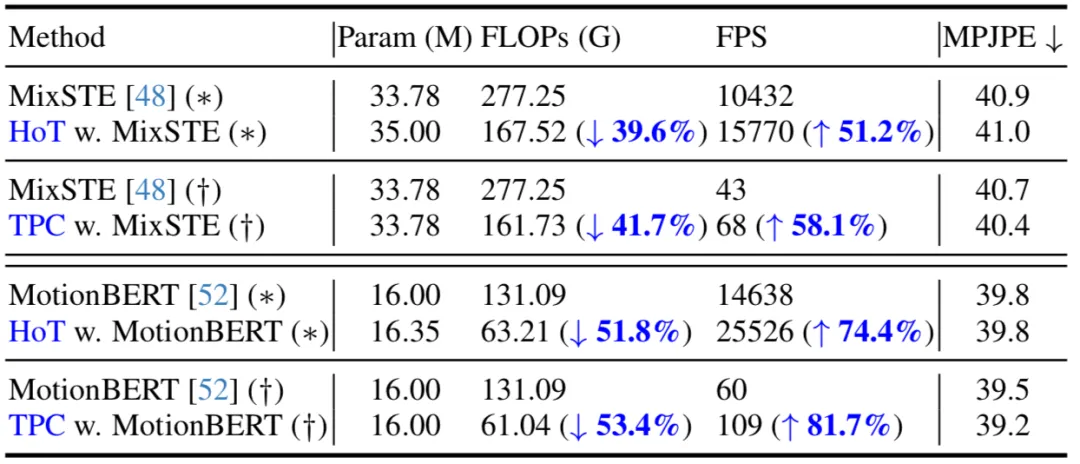
Dans le tableau ci-dessous, cet article donne une comparaison sous les processus d'inférence seq2seq (*) et seq2frame (†). Les résultats montrent qu'en appliquant la méthode proposée au VPT existant, cette méthode peut réduire considérablement les FLOP et améliorer considérablement les FPS tout en gardant le nombre de paramètres du modèle presque inchangé. De plus, par rapport au modèle original, la méthode proposée est fondamentalement la même en termes de performances ou peut obtenir de meilleures performances.
Cet article compare également différentes stratégies d'élagage de jetons, y compris l'élagage du score d'attention, l'échantillonnage uniforme et une stratégie d'élagage de mouvement qui sélectionne les k premiers jetons avec des quantités de mouvement plus importantes. On peut voir que le TPC proposé obtient pour. La meilleure performance.
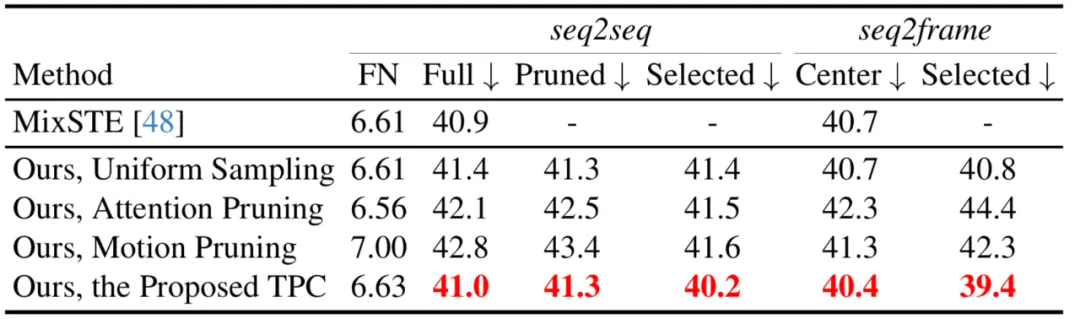
Cet article compare également différentes stratégies de récupération de jetons, y compris l'interpolation du voisin le plus proche et l'interpolation linéaire. On peut voir que le TRA proposé atteint les meilleures performances.
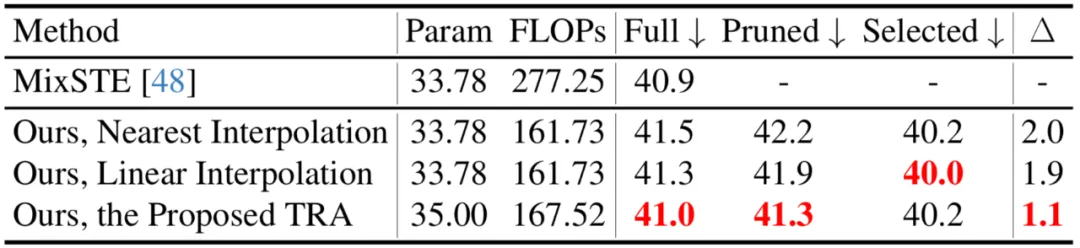
Comparaison avec les méthodes SOTA
Actuellement, sur l'ensemble de données Human3.6M, les principales méthodes d'estimation de pose humaine 3D utilisent toutes des architectures basées sur Transformer. Afin de vérifier l'efficacité de cette méthode, les auteurs l'appliquent à trois derniers modèles VPT : MHForme, MixSTE et MotionBERT, et comparent avec eux en termes de quantités de paramètres, FLOP et MPJPE.
Comme le montre le tableau ci-dessous, cette méthode réduit considérablement la quantité de calcul du modèle SOTA VPT tout en conservant la précision d'origine. Ces résultats vérifient non seulement l'efficacité et la haute efficience de cette méthode, mais révèlent également qu'il existe des redondances informatiques dans les modèles VPT existants, et que ces redondances contribuent peu aux performances d'estimation finale, et peuvent même conduire à une dégradation des performances. De plus, cette méthode peut éliminer ces calculs inutiles tout en obtenant des performances très compétitives, voire meilleures.
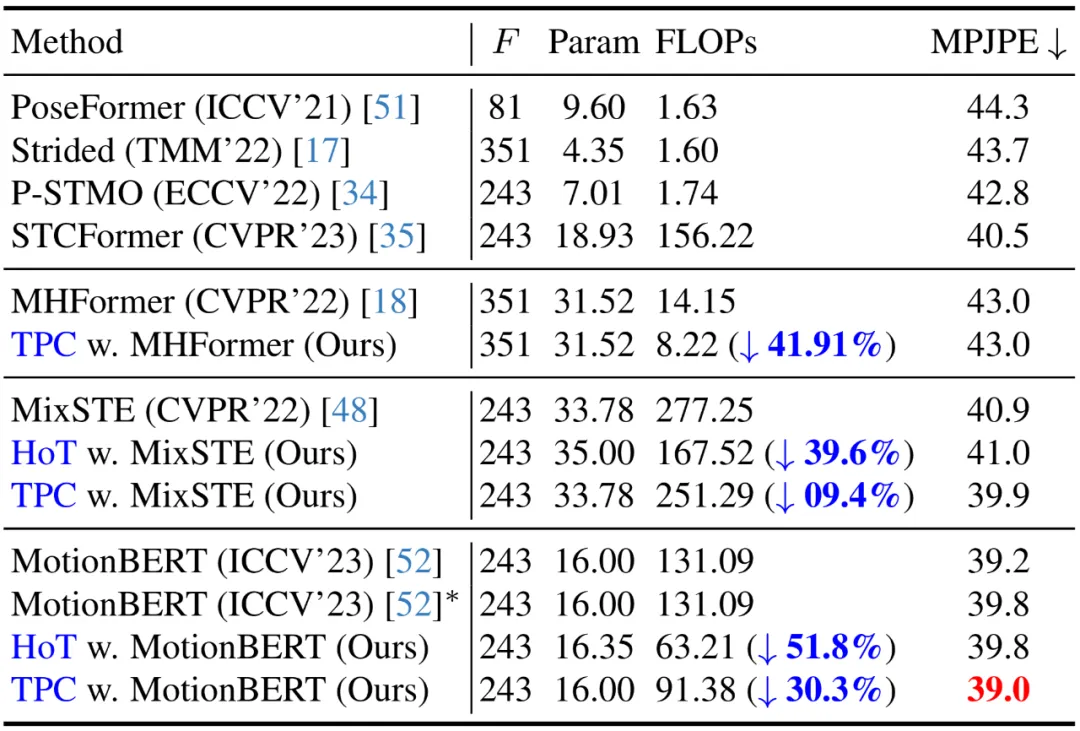
Exécution de code
L'auteur propose également une exécution de démonstration (https://github.com/NationalGAILab/HoT), qui intègre le détecteur humain YOLOv3, le détecteur d'attitude bidimensionnelle HRNet, HoT w . Optimiseur de pose MixSTE 2D à 3D. Téléchargez simplement le modèle pré-entraîné fourni par l'auteur, saisissez une courte vidéo contenant des personnes et vous pourrez directement produire une démo d'estimation de pose humaine 3D avec une seule ligne de code.
python demo/vis.py --video sample_video.mp4
Résultats obtenus en exécutant l'exemple de vidéo :

Résumé
Cet article propose le Hourglass Tokenizer (Hourglass Tokenizer) pour résoudre le problème du coût de calcul élevé de la pose vidéo existante Transforme (VPT), HoT), qui est un cadre d'élagage et de restauration de jetons plug-and-play pour une estimation efficace de la pose humaine 3D basée sur Transformer à partir de vidéos. L'étude a révélé qu'il n'est pas nécessaire de conserver des séquences de poses complètes dans VPT et que l'utilisation d'un petit nombre d'images représentatives de jetons de pose peut atteindre à la fois une précision et une efficacité élevées. Un grand nombre d’expériences ont vérifié la haute compatibilité et la large applicabilité de cette méthode. Il peut être facilement intégré à divers modèles VPT courants, qu'il s'agisse de VPT basés sur seq2seq ou seq2frame, et peut s'adapter efficacement à une variété de stratégies d'élagage et de récupération de jetons, démontrant ainsi son grand potentiel. Les auteurs s’attendent à ce que HoT stimule le développement de VPT plus puissants et plus rapides.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
