
 Périphériques technologiques
IA
Explication détaillée du codage de position de rotation RoPE couramment utilisé dans les grands modèles de langage : pourquoi est-il meilleur que le codage de position absolue ou relative ?
Périphériques technologiques
IA
Explication détaillée du codage de position de rotation RoPE couramment utilisé dans les grands modèles de langage : pourquoi est-il meilleur que le codage de position absolue ou relative ?
Explication détaillée du codage de position de rotation RoPE couramment utilisé dans les grands modèles de langage : pourquoi est-il meilleur que le codage de position absolue ou relative ?

Depuis l'article « Attention Is All You Need » publié en 2017, l'architecture Transformer est la pierre angulaire du domaine du traitement du langage naturel (NLP). Sa conception est restée pratiquement inchangée depuis des années, 2022 marquant un développement majeur dans le domaine avec l'introduction du Rotary Position Encoding (RoPE).
L'intégration de positions rotatives est la technologie d'intégration de positions PNL la plus avancée. Les modèles de langage à grande échelle les plus populaires tels que Llama, Llama2, PaLM et CodeGen l'utilisent déjà. Dans cet article, nous examinerons ce que sont les codages positionnels rotationnels et comment ils mélangent parfaitement les avantages des intégrations positionnelles absolues et relatives.
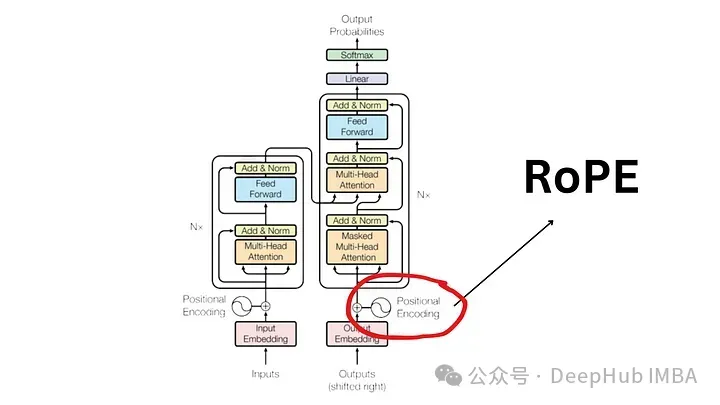
La nécessité d'un codage positionnel
Pour comprendre l'importance de RoPE, voyons d'abord pourquoi le codage positionnel est crucial. Les modèles de transformateur, de par leur conception inhérente, ne prennent pas en compte l'ordre des jetons d'entrée.
Par exemple, des expressions comme « le chien poursuit le cochon » et « le cochon poursuit les chiens », bien qu'elles aient des significations différentes, sont considérées comme indiscernables car elles sont considérées comme un ensemble de jetons non ordonnés. Afin de conserver les informations de séquenceet leur signification, une représentation est nécessaire pour intégrer les informations de position dans le modèle.
Codage de position absolue
Afin d'encoder les positions dans une phrase, un autre outil est nécessaire en utilisant des vecteurs de mêmes dimensions, où chaque vecteur représente une position dans la phrase. Par exemple, spécifiez un vecteur spécifique pour le deuxième mot d'une phrase. Par conséquent, chaque position de phrase a son vecteur unique. L'entrée de la couche Transformateur est ensuite formée en combinant les intégrations de mots avec les intégrations de leurs positions correspondantes.
Il existe deux manières principales de générer ces intégrations :
- Apprentissage à partir des données : Ici, le vecteur position est appris lors de l'entraînement, tout comme les autres paramètres du modèle. Nous apprenons un vecteur unique pour chaque position (par exemple de 1 à 512). Cela introduit une limitation : la longueur maximale de la séquence est limitée. Si le modèle apprend uniquement la position 512, il ne peut pas représenter des séquences plus longues que cette position.
- Fonction sinusoïdale : Cette méthode consiste à utiliser une fonction sinusoïdale pour créer une intégration unique pour chaque position. Bien que les détails de cette construction soient complexes, elle fournit essentiellement une intégration positionnelle unique pour chaque position de la séquence. Des études empiriques montrent que l'apprentissage et l'utilisation de fonctions sinusoïdales à partir de données peuvent fournir des performances comparables dans des modèles du monde réel.
Limitations du codage positionnel absolu
Bien que largement utilisé, l'intégration positionnelle absolue n'est pas sans inconvénients :
- Longueur de séquence limitée : Comme mentionné ci-dessus, si le modèle apprend jusqu'à un certain point A vecteur de position, qui, par nature, ne peut pas représenter les positions au-delà de cette limite.
- Indépendance des intégrations d'emplacement : Chaque intégration d'emplacement est indépendante des autres intégrations d'emplacement. Cela signifie que du point de vue du modèle, la différence entre les positions 1 et 2 est la même que la différence entre les positions 2 et 500. Mais en fait, les positions 1 et 2 devraient être plus étroitement liées que la position 500, qui est nettement plus éloignée. Ce manque de positionnement relatif peut entraver la capacité du modèle à comprendre les nuances de la structure du langage.
Encodage de position relative
La position relative ne se concentre pas sur la position absolue des notes dans la phrase, mais sur la distance entre les paires de notes. Cette méthode n'ajoute pas de vecteurs de position directement aux vecteurs de mots. Au lieu de cela, le mécanisme d'attention est modifié pour incorporer des informations de position relative.
T5 (Text-to-Text Transfer Transformer) est un modèle célèbre qui utilise l'intégration de position relative. T5 introduit une manière subtile de gérer les informations de position :
- Biais pour les décalages de position : T5 utilise un biais (un nombre à virgule flottante) pour représenter chaque décalage de position possible. Par exemple, le biais B1 peut représenter la distance relative entre deux jetons séparés d’une position, quelle que soit leur position absolue dans la phrase.
- Intégration dans la couche d'auto-attention : Cette matrice de biais de position relative est ajoutée au produit de la matrice de requête et de la matrice clé dans la couche d'auto-attention. Cela garantit que les marqueurs situés à la même distance relative sont toujours représentés par le même biais, quelle que soit leur position dans la séquence.
- Évolutivité : Un avantage important de cette approche est son évolutivité. Il peut être étendu à des séquences arbitrairement longues, ce qui présente des avantages évidents par rapport à l'intégration de position absolue.
Limitations de l'encodage de position relative
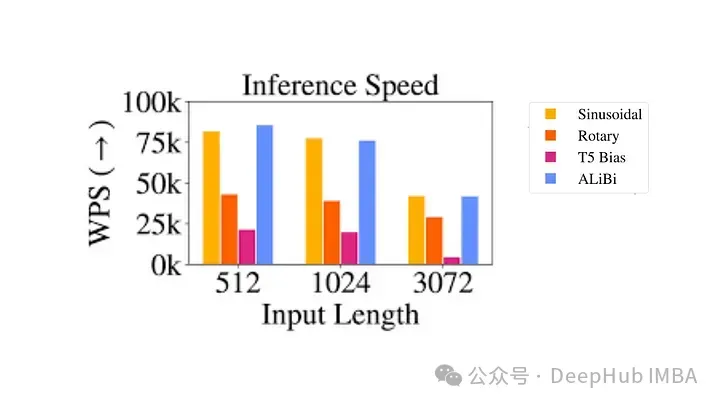
Obwohl sie theoretisch attraktiv sind, sind relative Positionskodierungen äußerst problematisch
- Rechnerisch ineffizient: Es müssen paarweise Positionskodierungsmatrizen erstellt und dann eine große Anzahl von Tensoroperationen durchgeführt werden, um die relative Positionskodierung jedes Zeitschritts zu erhalten. Vor allem bei längeren Sequenzen. Dies ist hauptsächlich auf den zusätzlichen Rechenschritt in der Selbstaufmerksamkeitsschicht zurückzuführen, wo die Positionsmatrix zur Abfrageschlüsselmatrix hinzugefügt wird.
- Komplexität der Schlüsselwert-Cache-Nutzung: Da jedes zusätzliche Token die Einbettung jedes anderen Tokens verändert, erschwert dies die effektive Nutzung des Schlüsselwert-Cache in Transformer. Eine Voraussetzung für die Verwendung des KV-Cache ist, dass sich die Positionskodierung bereits generierter Wörter bei der Generierung neuer Wörter nicht ändert (die absolute Positionskodierung bietet), sodass die relative Positionskodierung nicht für die Inferenz geeignet ist, da sich die Einbettung jedes Tokens mit jedem neuen ändert ändert sich mit Zeitschritten.
Aufgrund dieser technischen Komplexität wurde die Positionscodierung nicht weit verbreitet, insbesondere in größeren Sprachmodellen.
Rotational Position Encoding (RoPE)?
RoPE stellt eine neue Art der Kodierung von Standortinformationen dar. Sowohl die absolute Methode als auch die relative Methode in herkömmlichen Methoden haben ihre Grenzen. Die absolute Positionskodierung weist jeder Position einen eindeutigen Vektor zu. Dies ist zwar einfach, lässt sich aber nicht gut skalieren und kann relative Positionen nicht effektiv erfassen. Die relative Positionskodierung konzentriert sich auf den Abstand zwischen Markern, verbessert das Verständnis des Modells für Markerbeziehungen, macht die Modellarchitektur jedoch komplizierter .
RoPE vereint geschickt die Vorteile beider. Kodieren Sie Standortinformationen so, dass das Modell die absolute Position der Markierungen und ihre relative Entfernung verstehen kann. Dies wird durch einen Rotationsmechanismus erreicht, bei dem jede Position in der Sequenz durch eine Drehung im Einbettungsraum dargestellt wird. Die Eleganz von RoPE liegt in seiner Einfachheit und Effizienz, die es dem Modell ermöglicht, die Nuancen der Sprachsyntax und -semantik besser zu erfassen.
Die Rotationsmatrix wird aus den trigonometrischen Eigenschaften von Sinus und Cosinus abgeleitet, die wir in der High School gelernt haben. Die Verwendung einer 2D-Matrix sollte ausreichen, um die Theorie der Rotationsmatrix wie unten gezeigt zu erhalten!
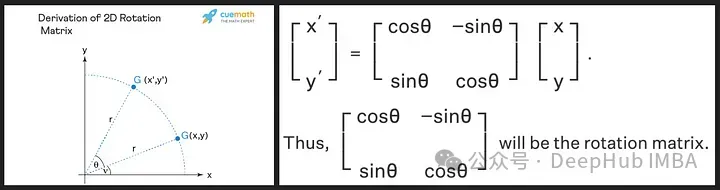
Wir sehen, dass die Rotationsmatrix die Größe (oder Länge) des ursprünglichen Vektors beibehält, wie durch „r“ im Bild oben gezeigt, das einzige, was sich ändert, ist der Winkel mit der x-Achse.
RoPE stellt ein neuartiges Konzept vor. Anstatt Positionsvektoren hinzuzufügen, werden die Wortvektoren gedreht. Der Drehwinkel (θ) ist proportional zur Position des Wortes im Satz. Der Vektor an der ersten Position wird um θ gedreht, der Vektor an der zweiten Position wird um 2θ gedreht und so weiter. Dieser Ansatz hat mehrere Vorteile:
- Stabilität von Vektoren: Das Hinzufügen von Markierungen am Ende eines Satzes hat keinen Einfluss auf den Vektor des Anfangsworts, was für ein effizientes Caching von Vorteil ist.
- Bewahrung relativer Positionen: Wenn zwei Wörter in unterschiedlichen Kontexten den gleichen relativen Abstand beibehalten, werden ihre Vektoren um den gleichen Betrag gedreht. Dadurch wird sichergestellt, dass der Winkel sowie das Skalarprodukt zwischen diesen Vektoren konstant bleiben
Die Matrixformel von RoPE
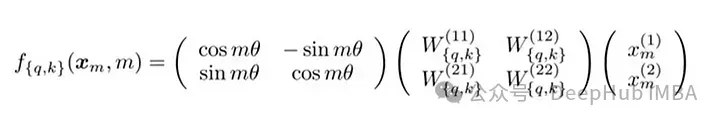
Die technische Umsetzung von RoPE beinhaltet eine Rotationsmatrix. Im 2D-Fall enthalten die Gleichungen in der Arbeit eine Rotationsmatrix, die den Vektor um Mθ Grad dreht, wobei M die absolute Position im Satz ist. Diese Rotation wird auf den Abfragevektor und den Schlüsselvektor im Selbstaufmerksamkeitsmechanismus des Transformers angewendet.
Für höhere Dimensionen werden die Vektoren in 2D-Blöcke aufgeteilt und jedes Paar wird unabhängig gedreht. Dies kann man sich als eine im Raum rotierende n-Dimension vorstellen. Es hört sich so an, als wäre die Implementierung dieser Methode kompliziert, aber das ist nicht der Fall. Sie kann in Bibliotheken wie PyTorch mit nur etwa zehn Codezeilen effizient implementiert werden.
import torch import torch.nn as nn class RotaryPositionalEmbedding(nn.Module): def __init__(self, d_model, max_seq_len): super(RotaryPositionalEmbedding, self).__init__() # Create a rotation matrix. self.rotation_matrix = torch.zeros(d_model, d_model, device=torch.device("cuda")) for i in range(d_model): for j in range(d_model): self.rotation_matrix[i, j] = torch.cos(i * j * 0.01) # Create a positional embedding matrix. self.positional_embedding = torch.zeros(max_seq_len, d_model, device=torch.device("cuda")) for i in range(max_seq_len): for j in range(d_model): self.positional_embedding[i, j] = torch.cos(i * j * 0.01) def forward(self, x): """Args:x: A tensor of shape (batch_size, seq_len, d_model). Returns:A tensor of shape (batch_size, seq_len, d_model).""" # Add the positional embedding to the input tensor. x += self.positional_embedding # Apply the rotation matrix to the input tensor. x = torch.matmul(x, self.rotation_matrix) return x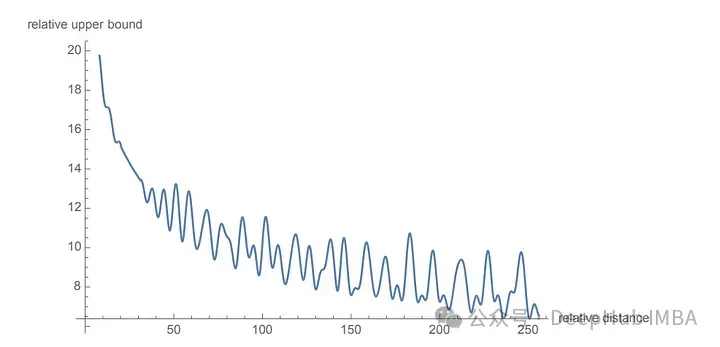
为了旋转是通过简单的向量运算而不是矩阵乘法来执行。距离较近的单词更有可能具有较高的点积,而距离较远的单词则具有较低的点积,这反映了它们在给定上下文中的相对相关性。
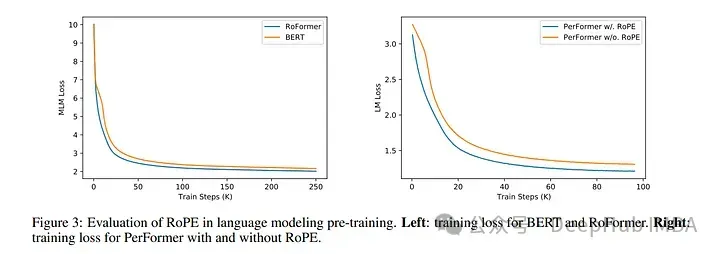
使用 RoPE 对 RoBERTa 和 Performer 等模型进行的实验表明,与正弦嵌入相比,它的训练时间更快。并且该方法在各种架构和训练设置中都很稳健。
最主要的是RoPE是可以外推的,也就是说可以直接处理任意长的问题。在最早的llamacpp项目中就有人通过线性插值RoPE扩张,在推理的时候直接通过线性插值将LLAMA的context由2k拓展到4k,并且性能没有下降,所以这也可以证明RoPE的有效性。
代码如下:
import transformers old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None): #The method is just these three linesmax_position_embeddings = 16384a = 8 #Alpha valuebase = base * a ** (dim / (dim-2)) #Base change formula old_init(self, dim, max_position_embeddings, base, device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ = ntk_scaled_init
总结
旋转位置嵌入代表了 Transformer 架构的范式转变,提供了一种更稳健、直观和可扩展的位置信息编码方式。
RoPE不仅解决了LLM context过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。这一进步不仅增强了当前的语言模型,还为 NLP 的未来创新奠定了基础。随着我们不断解开语言和人工智能的复杂性,像 RoPE 这样的方法将有助于构建更先进、更准确、更类人的语言处理系统。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Les grands modèles sont également très puissants pour la prédiction de séries chronologiques ! L'équipe chinoise active les nouvelles capacités de LLM et surpasse les modèles traditionnels pour atteindre SOTA
Apr 11, 2024 am 09:43 AM
Les grands modèles sont également très puissants pour la prédiction de séries chronologiques ! L'équipe chinoise active les nouvelles capacités de LLM et surpasse les modèles traditionnels pour atteindre SOTA
Apr 11, 2024 am 09:43 AM
Le potentiel des grands modèles de langage est stimulé : une prédiction de séries chronologiques de haute précision peut être obtenue sans formation de grands modèles de langage, surpassant ainsi tous les modèles de séries chronologiques traditionnels. L'Université Monash, Ant et IBM Research ont développé conjointement un cadre général qui a permis de promouvoir avec succès la capacité des grands modèles de langage à traiter les données de séquence selon différentes modalités. Le cadre est devenu une innovation technologique importante. La prédiction de séries chronologiques est bénéfique à la prise de décision dans des systèmes complexes typiques tels que les villes, l'énergie, les transports et la télédétection. Depuis lors, les grands modèles devraient révolutionner l’exploration de séries chronologiques et de données spatiotemporelles. L’équipe de recherche sur le cadre général de reprogrammation de grands modèles de langage a proposé un cadre général permettant d’utiliser facilement de grands modèles de langage pour la prédiction générale de séries chronologiques sans aucune formation. Deux technologies clés sont principalement proposées : la reprogrammation des entrées de synchronisation ; Temps-
 Le positionnement collant s'éloigne-t-il du flux de documents ?
Feb 20, 2024 pm 05:24 PM
Le positionnement collant s'éloigne-t-il du flux de documents ?
Feb 20, 2024 pm 05:24 PM
Le positionnement collant s'éloigne-t-il du flux de documents ? Des exemples de code spécifiques sont nécessaires dans le développement Web, la mise en page est un sujet très important. Parmi elles, le positionnement est l’une des techniques de mise en page les plus couramment utilisées. En CSS, il existe trois méthodes de positionnement courantes : le positionnement statique, le positionnement relatif et le positionnement absolu. En plus de ces trois méthodes de positionnement, il existe également une méthode de positionnement plus particulière, à savoir le positionnement collant. Alors, le positionnement collant s'éloigne-t-il du flux de documents ? Discutons-en en détail ci-dessous et fournissons quelques exemples de code pour vous aider à comprendre. Tout d’abord, nous devons comprendre ce qu’est le flux de documents
 Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Cet article ouvrira en source les résultats du « Déploiement local de grands modèles de langage dans OpenHarmony » démontrés lors de la 2e conférence technologique OpenHarmony. Adresse : https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Les idées et les étapes de mise en œuvre consistent à transplanter le cadre d'inférence de modèle LLM léger InferLLM vers le système standard OpenHarmony et à compiler un produit binaire pouvant s'exécuter sur OpenHarmony. InferLLM est un L simple et efficace
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Cet après-midi, Hongmeng Zhixing a officiellement accueilli de nouvelles marques et de nouvelles voitures. Le 6 août, Huawei a organisé la conférence de lancement de nouveaux produits Hongmeng Smart Xingxing S9 et Huawei, réunissant la berline phare intelligente panoramique Xiangjie S9, le nouveau M7Pro et Huawei novaFlip, MatePad Pro 12,2 pouces, le nouveau MatePad Air, Huawei Bisheng With de nombreux nouveaux produits intelligents tous scénarios, notamment la série d'imprimantes laser X1, FreeBuds6i, WATCHFIT3 et l'écran intelligent S5Pro, des voyages intelligents, du bureau intelligent aux vêtements intelligents, Huawei continue de construire un écosystème intelligent complet pour offrir aux consommateurs une expérience intelligente du Internet de tout. Hongmeng Zhixing : Autonomisation approfondie pour promouvoir la modernisation de l'industrie automobile intelligente Huawei s'associe à ses partenaires de l'industrie automobile chinoise pour fournir
 Traitement du langage naturel : permettre aux ordinateurs de comprendre et de traiter le langage humain
Sep 21, 2023 pm 03:53 PM
Traitement du langage naturel : permettre aux ordinateurs de comprendre et de traiter le langage humain
Sep 21, 2023 pm 03:53 PM
Le traitement du langage naturel (NLP) est une technologie importante et passionnante dans le domaine de l'intelligence artificielle. Son objectif est de permettre aux ordinateurs de comprendre, d'analyser et de générer le langage humain. Le développement de la PNL a fait d’énormes progrès, permettant aux ordinateurs de mieux interagir avec les humains et d’atteindre une plus large gamme d’applications. Cet article explorera les concepts, les technologies, les applications et les perspectives d'avenir du traitement du langage naturel. Le concept de traitement du langage naturel est une discipline qui étudie comment permettre aux ordinateurs de comprendre et de traiter le langage humain. La complexité et l’ambiguïté du langage humain confrontent les ordinateurs à d’énormes défis en matière de compréhension et de traitement. L'objectif de la PNL est de développer des algorithmes et des modèles permettant aux ordinateurs d'extraire des informations à partir d'un texte.
 Comment l'utilisation des fonctions Java dans le traitement du langage naturel peut-elle faciliter les interactions conversationnelles ?
Apr 30, 2024 am 08:03 AM
Comment l'utilisation des fonctions Java dans le traitement du langage naturel peut-elle faciliter les interactions conversationnelles ?
Apr 30, 2024 am 08:03 AM
Les fonctions Java sont largement utilisées en PNL pour créer des solutions personnalisées qui améliorent l'expérience des interactions conversationnelles. Ces fonctions peuvent être utilisées pour le prétraitement de texte, l'analyse des sentiments, la reconnaissance d'intention et l'extraction d'entités. Par exemple, en utilisant les fonctions Java pour l'analyse des sentiments, les applications peuvent comprendre le ton de l'utilisateur et réagir de manière appropriée, améliorant ainsi l'expérience conversationnelle.
