

Mamba est l'un des modèles les plus populaires récemment et est considéré par l'industrie comme ayant le potentiel de remplacer le Transformer. L'article présenté aujourd'hui explore si le modèle Mamba est efficace dans les tâches de prévision de séries chronologiques. Cet article présente d'abord les principes de base de Mamba, puis combine cet article pour déterminer si Mamba est efficace dans les scénarios de prévision de séries chronologiques. Le modèle Mamba est un modèle basé sur l'apprentissage profond qui utilise une architecture autorégressive pour capturer les dépendances à long terme dans les données de séries chronologiques. Comparé aux modèles traditionnels, le modèle Mamba fonctionne bien dans les tâches de prévision de séries chronologiques. Grâce à des expériences et à des analyses comparatives, cet article révèle que le modèle Mamba donne de bons résultats dans les tâches de prévision de séries chronologiques. Il peut prédire avec précision les valeurs futures des séries chronologiques et mieux capturer les dépendances à long terme. Résumé

Titre de l'article : Mamba est-il efficace pour la prévision de séries chronologiques ?
Adresse de téléchargement :https://www.php.cn/link/f06d497659096949ed7c01894ba38694
Mamba est. un genre Basé sur la structure du State Space Model, mais très similaire à RNN. Par rapport à Transformer, Mamba a une complexité temporelle qui augmente linéairement avec la longueur de la séquence à la fois dans la phase de formation et dans la phase d'inférence, et l'efficacité du calcul dépend de la structure de Transformer.
Le noyau de Mamba peut être divisé en 4 parties suivantes :
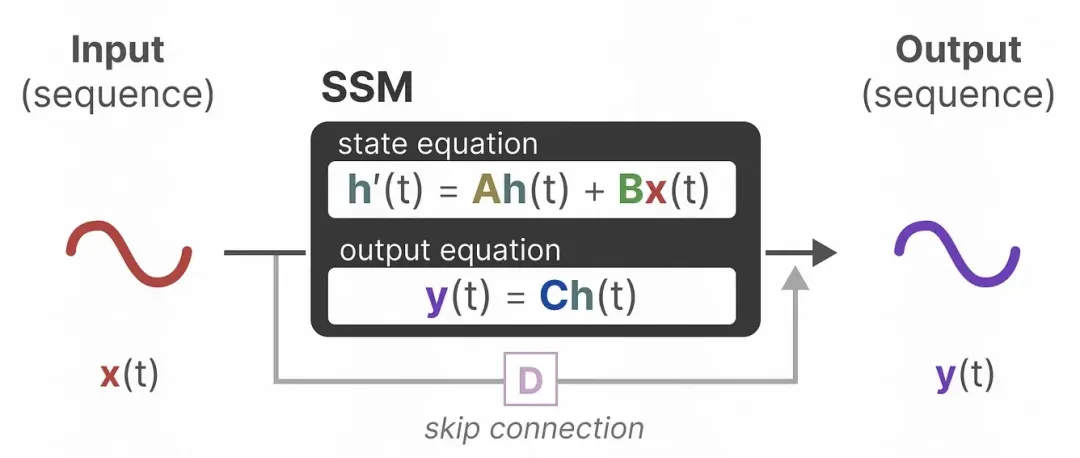
State Space Model (SSM) est un modèle mathématique utilisé pour décrire l'impact d'un état sur l'état actuel et l'impact de l'état actuel sur la sortie. Dans le modèle spatial d'états, on suppose que les entrées de l'état précédent et du moment actuel affecteront l'état suivant et l'impact de l'état actuel sur la sortie. SSM peut être exprimé sous la forme suivante, où les matrices A, B, C et D sont des hyperparamètres. La matrice A représente l'impact de l'état précédent sur l'état actuel ; La matrice B indique que l'entrée du moment actuel affectera l'état suivant ; La matrice C représente l'impact de l'état actuel sur la sortie ; La matrice D représente l’impact direct des intrants sur la production. En observant la sortie actuelle et l'entrée au moment actuel, la valeur de l'état suivant peut être déduite. Il est déterminé en fonction des résultats d’observation actuels et de l’état du moment. SSM peut être utilisé dans des domaines tels que la modélisation de systèmes dynamiques, l'estimation d'état et les applications de contrôle.
 Image
Image
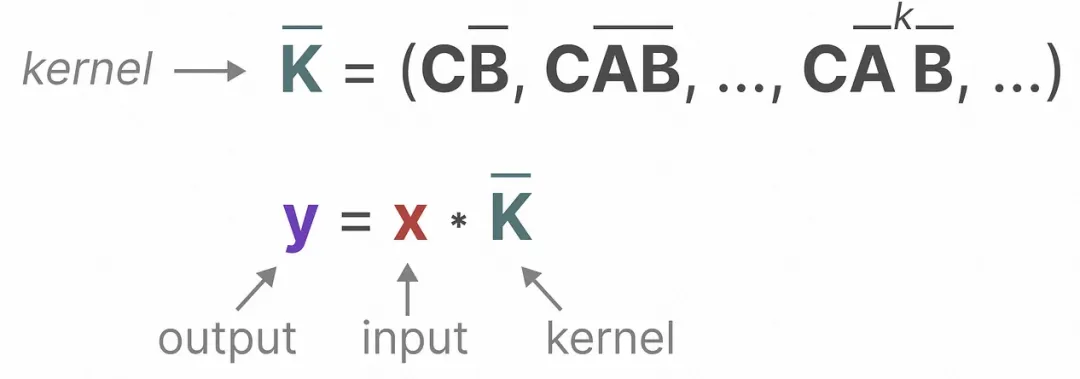
Expression de convolution : utilisez la convolution pour représenter SSM afin de réaliser un calcul simultané dans la phase de formation. En développant la formule de sortie du calcul dans SSM en fonction du temps, en concevant le noyau de convolution correspondant sous une certaine forme, vous pouvez. utilisez la convolution pour exprimer la sortie de chaque instant en fonction de la sortie des trois moments précédents :
 Images
Images
Hippo Matrix : Pour le paramètre A, Hippo Matrix est introduit pour réaliser la fusion d'atténuation des informations historiques
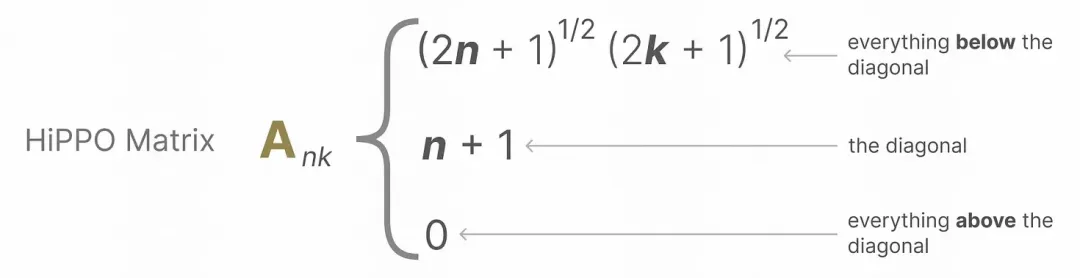 Image
Image
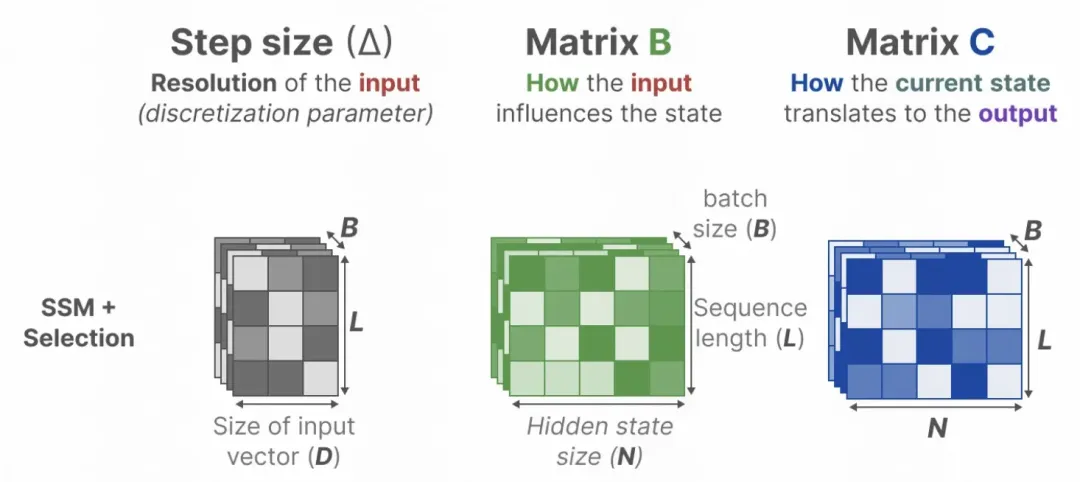
Module sélectif : Pour la matrice personnalisée du paramètre B et du paramètre C, réaliser la sélection personnalisée des informations historiques, convertir la matrice des paramètres à chaque instant en fonction sur l'entrée, et réaliser les paramètres personnalisés à chaque instant.
 Photos
Photos
Une analyse plus détaillée du modèle sur Mamba, ainsi que les travaux ultérieurs liés à Mamba, ont également été mis à jour sur Knowledge Planet. Les étudiants intéressés peuvent en apprendre davantage sur la planète.
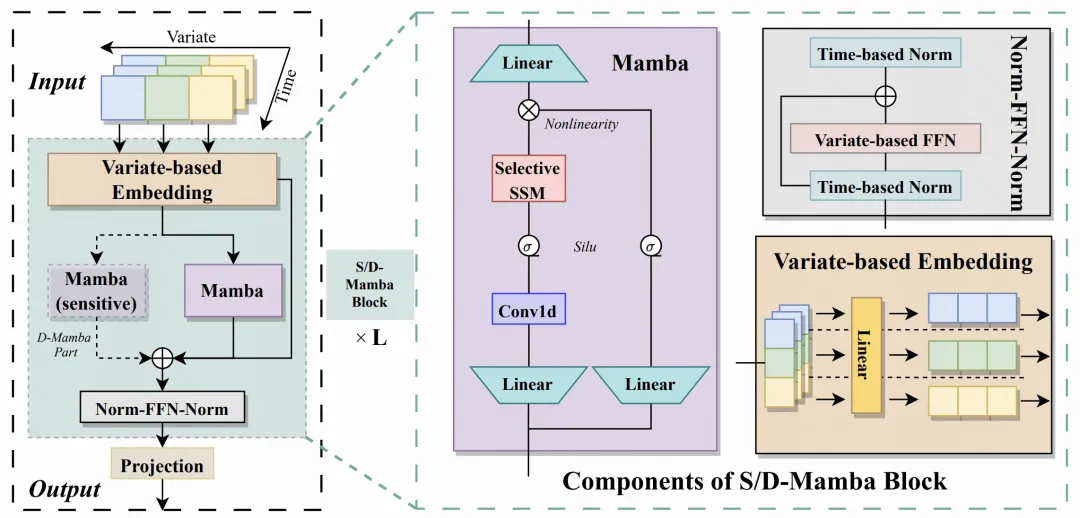
Ce qui suit présente le cadre de prédiction de séries chronologiques Mamba proposé dans cet article, qui est basé sur Mamba pour adapter les données de séries chronologiques. L'ensemble est divisé en trois parties : Embedding, couche S/D-Mamba et couche Norm-FFN-Norm.
Incorporation : similaire à la méthode de traitement iTransformer, chaque variable est mappée séparément, l'intégration de chaque variable est générée, puis l'intégration de chaque variable est entrée dans le Mamba suivant. Par conséquent, cet article peut également être considéré comme une modification de la structure du modèle d'iTransformer, en la remplaçant par la structure Mamba
Couche S/D-Mamba : la dimension d'entrée de l'intégration est [batch_size, variable_number, dim] ; entrée dans Mamba , l'article explore deux couches Mamba, S et D, qui indiquent respectivement si chaque couche utilise un mamba ou deux mambas. Les deux mamba ajouteront la sortie des deux pour obtenir le résultat de sortie de chaque couche
Norm ; -FFN-Norm Layer : dans la couche de sortie, utilisez la couche de normalisation et la couche FFN pour normaliser et cartographier la représentation de sortie de Mamba, et combinez-la avec le réseau résiduel pour améliorer la convergence et la stabilité du modèle.
 Images
Images
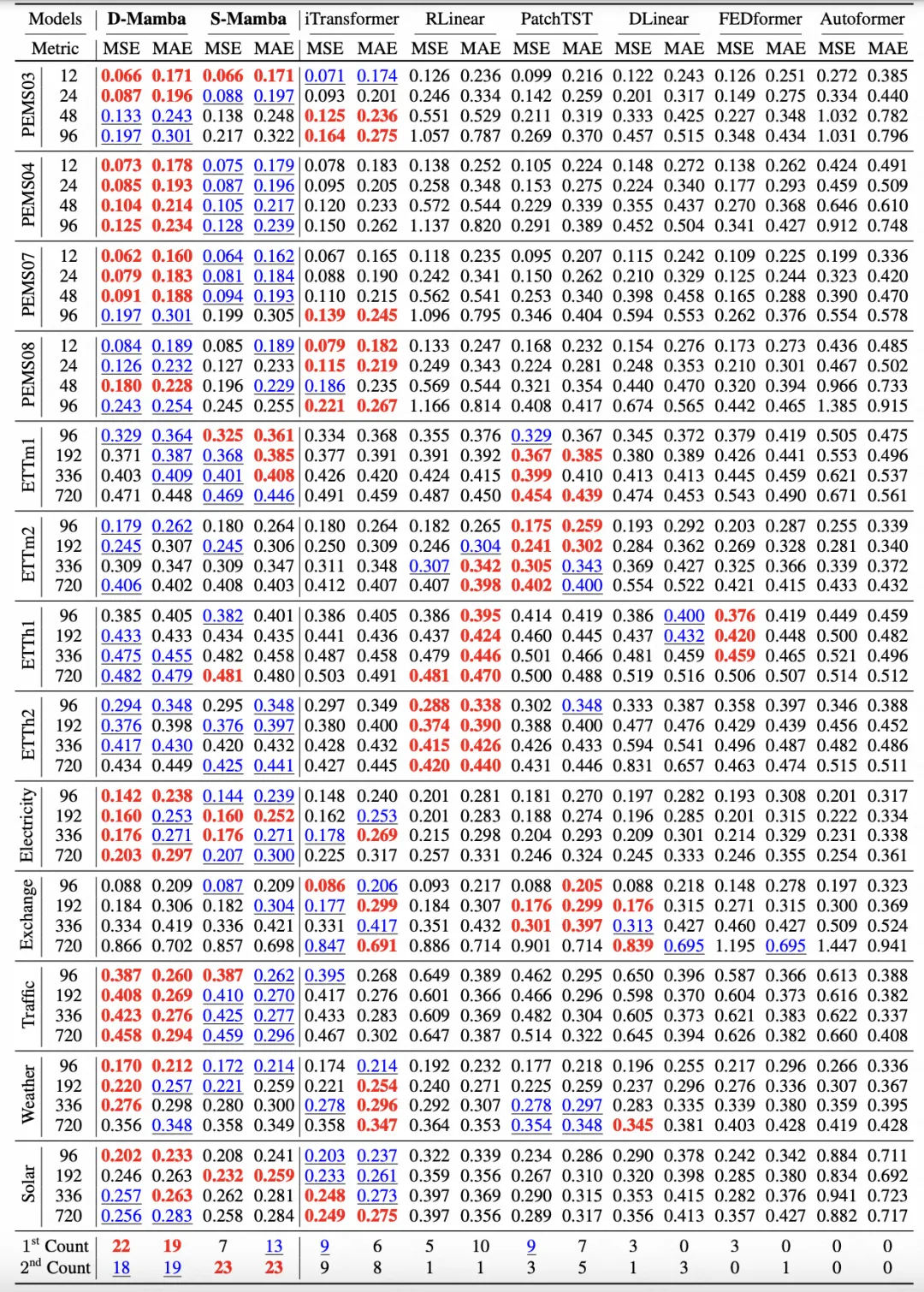
L'image suivante est le principal résultat expérimental de l'article, qui compare les effets de Mamba avec iTransformer, PatchTST et d'autres modèles de séries chronologiques grand public de l'industrie. L'article effectue également des comparaisons expérimentales sur différentes fenêtres de prédiction, propriétés de généralisation, etc. Les expériences montrent que Mamba présente non seulement des avantages en termes de ressources informatiques, mais qu'il est également comparable aux modèles liés à Transformer en termes d'effet de modèle et qu'il est également prometteur en matière de modélisation à long terme.
 photos
photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 À quelle plateforme appartient Tonglian Payment ?
À quelle plateforme appartient Tonglian Payment ?
 Quelles sont les bibliothèques couramment utilisées dans Golang ?
Quelles sont les bibliothèques couramment utilisées dans Golang ?
 Windows ne peut pas démarrer
Windows ne peut pas démarrer
 Comment déclencher un événement de pression de touche
Comment déclencher un événement de pression de touche
 Solution d'erreur HTTP 503
Solution d'erreur HTTP 503
 La différence entre les pages Web statiques et les pages Web dynamiques
La différence entre les pages Web statiques et les pages Web dynamiques
 Que signifie le réseau maillé ?
Que signifie le réseau maillé ?
 Comment créer une page Web réactive
Comment créer une page Web réactive








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



