
 Périphériques technologiques
IA
Pratique d'évaluation des performances des requêtes en contexte ultra long LLM
Périphériques technologiques
IA
Pratique d'évaluation des performances des requêtes en contexte ultra long LLM
Pratique d'évaluation des performances des requêtes en contexte ultra long LLM

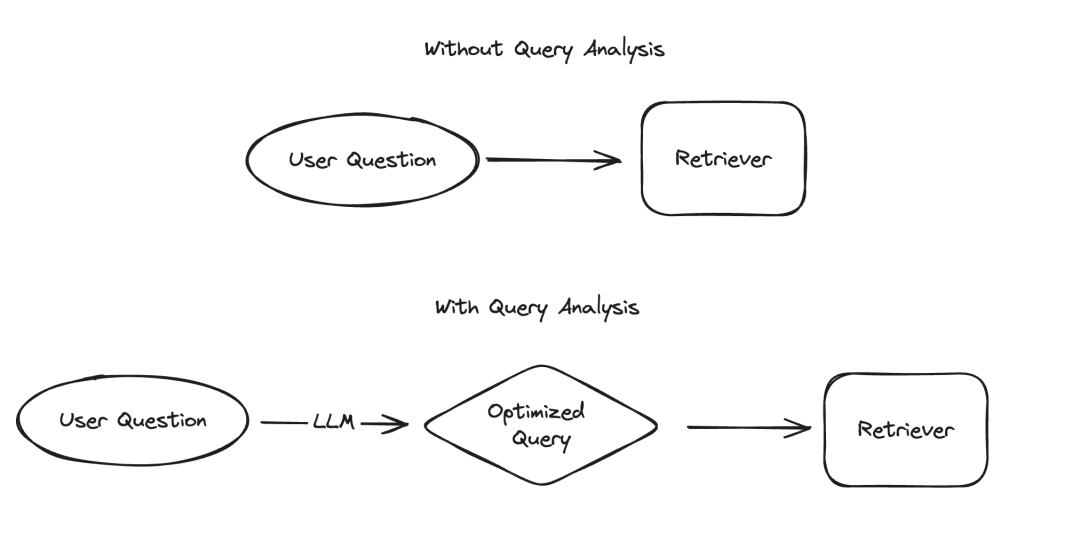
Dans l'application des grands modèles de langage (LLM), il existe plusieurs scénarios qui nécessitent que les données soient présentées de manière structurée, dont l'extraction d'informations et l'analyse de requêtes sont deux exemples typiques. Nous avons récemment souligné l'importance de l'extraction d'informations avec une documentation mise à jour et un référentiel de code dédié. Pour l'analyse des requêtes, nous avons également mis à jour la documentation associée. Dans ces scénarios, les champs de données peuvent inclure des chaînes, des valeurs booléennes, des entiers, etc. Parmi ces types, le traitement des valeurs catégorielles à cardinalité élevée (c'est-à-dire les types d'énumération) est le plus difficile.
 Images
Images
Les soi-disant « valeurs de regroupement à cardinalité élevée » font référence aux valeurs qui doivent être sélectionnées parmi des options limitées. Ces valeurs ne peuvent pas être spécifiées arbitrairement, mais doivent provenir d'un ensemble prédéfini. Dans ce type d'ensemble, il y aura parfois un très grand nombre de valeurs valides, que nous appelons « valeurs de cardinalité élevée ». La raison pour laquelle il est difficile de gérer de telles valeurs est que LLM lui-même ne sait pas quelles sont ces valeurs réalisables. Par conséquent, nous devons fournir à LLM des informations sur ces valeurs réalisables. Même en ignorant le cas où il n'y a que quelques valeurs réalisables, nous pouvons toujours résoudre ce problème en répertoriant explicitement ces valeurs possibles dans l'indice. Cependant, le problème devient compliqué car il y a tellement de valeurs possibles.
À mesure que le nombre de valeurs possibles augmente, la difficulté de sélectionner les valeurs LLM augmente également. D'une part, s'il y a trop de valeurs possibles, elles risquent de ne pas rentrer dans la fenêtre contextuelle du LLM. D'un autre côté, même si toutes les valeurs possibles peuvent s'adapter au contexte, les inclure toutes entraîne un traitement plus lent, une augmentation des coûts et une réduction des capacités de raisonnement LLM lorsqu'il s'agit de grandes quantités de contexte. `À mesure que le nombre de valeurs possibles augmente, la difficulté de sélection des valeurs par LLM augmente. D'une part, s'il y a trop de valeurs possibles, elles risquent de ne pas rentrer dans la fenêtre contextuelle du LLM. D'un autre côté, même si toutes les valeurs possibles peuvent s'adapter au contexte, les inclure toutes entraîne un traitement plus lent, une augmentation des coûts et une réduction des capacités de raisonnement LLM lorsqu'il s'agit de grandes quantités de contexte. ` (Remarque : le texte original semble être encodé en URL. J'ai corrigé l'encodage et fourni le texte réécrit.)
Récemment, nous avons mené une étude approfondie de l'analyse des requêtes, et lors de la révision de la documentation pertinente, nous avons ajouté une section spéciale sur la façon de gérer cela. Pages avec des valeurs de cardinalité élevées. Dans ce blog, nous plongerons dans plusieurs approches expérimentales et fournirons leurs résultats de référence en matière de performances.
Un aperçu des résultats peut être consulté sur LangSmith https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev. Ensuite, nous présenterons en détail :
 Images
Images
Aperçu de l'ensemble de données
L'ensemble de données détaillé peut être consulté ici https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc -d7def170be76 /d?ref=blog.langchain.dev.
Pour simuler ce problème, nous supposons un scénario : nous voulons trouver des livres sur les extraterrestres d'un certain auteur. Dans ce scénario, le champ écrivain est une variable catégorielle à cardinalité élevée : il existe de nombreuses valeurs possibles, mais il doit s'agir de noms d'écrivain spécifiques et valides. Pour tester cela, nous avons créé un ensemble de données contenant les noms d'auteurs et les alias courants. Par exemple, « Harry Chase » pourrait être un alias pour « Harrison Chase ». Nous voulons que les systèmes intelligents soient capables de gérer ce type d'alias. Dans cet ensemble de données, nous avons généré un ensemble de données contenant une liste de noms et d'alias d'écrivains. Notez que 10 000 noms aléatoires, ce n'est pas trop : pour les systèmes au niveau de l'entreprise, vous devrez peut-être gérer une cardinalité de plusieurs millions.
À l'aide de cet ensemble de données, nous posons la question : « Que sont les livres de Harry Chase sur les extraterrestres ? » Notre système d'analyse de requêtes devrait être capable d'analyser cette question dans un format structuré, contenant deux champs : sujet et auteur. Dans cet exemple, le résultat attendu serait {"topic": "aliens", "author": "Harrison Chase"}. Nous nous attendons à ce que le système reconnaisse qu'il n'y a pas d'auteur nommé Harry Chase, mais Harrison Chase est peut-être ce que l'utilisateur voulait dire.
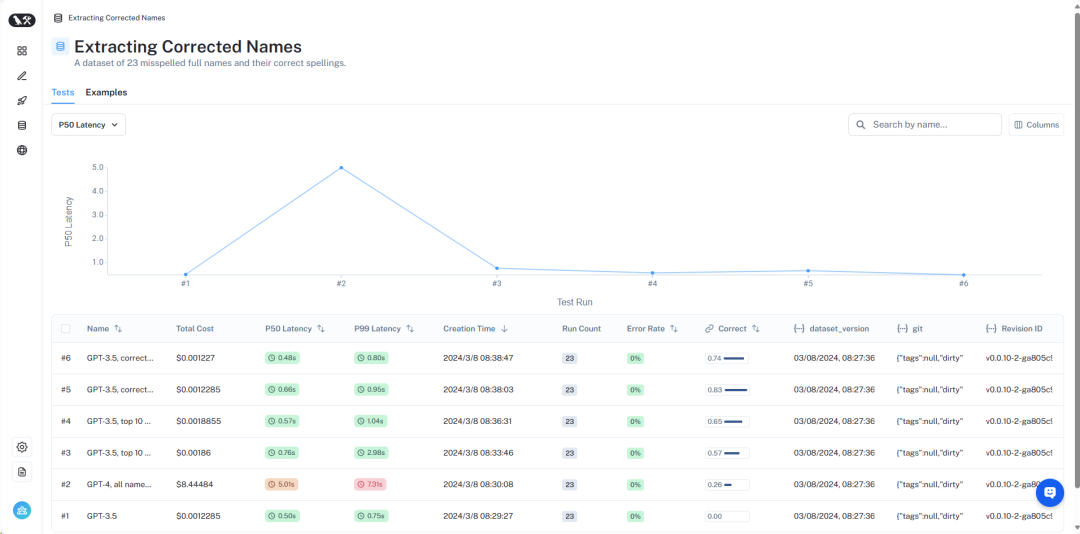
Avec cette configuration, nous pouvons tester l'ensemble de données d'alias que nous avons créé pour vérifier s'ils correspondent correctement aux vrais noms. Parallèlement, nous enregistrons également la latence et le coût de la requête. Ce type de système d'analyse des requêtes est généralement utilisé pour la recherche, nous sommes donc très préoccupés par ces deux indicateurs. Pour cette raison, nous limitons également toutes les méthodes à un seul appel LLM. Nous pourrons comparer les méthodes utilisant plusieurs appels LLM dans un prochain article.
Ensuite, nous présenterons plusieurs méthodes différentes et leurs performances.
 Photos
Photos
Les résultats complets peuvent être consultés dans LangSmith, et le code pour reproduire ces résultats peut être trouvé ici.
Test de base
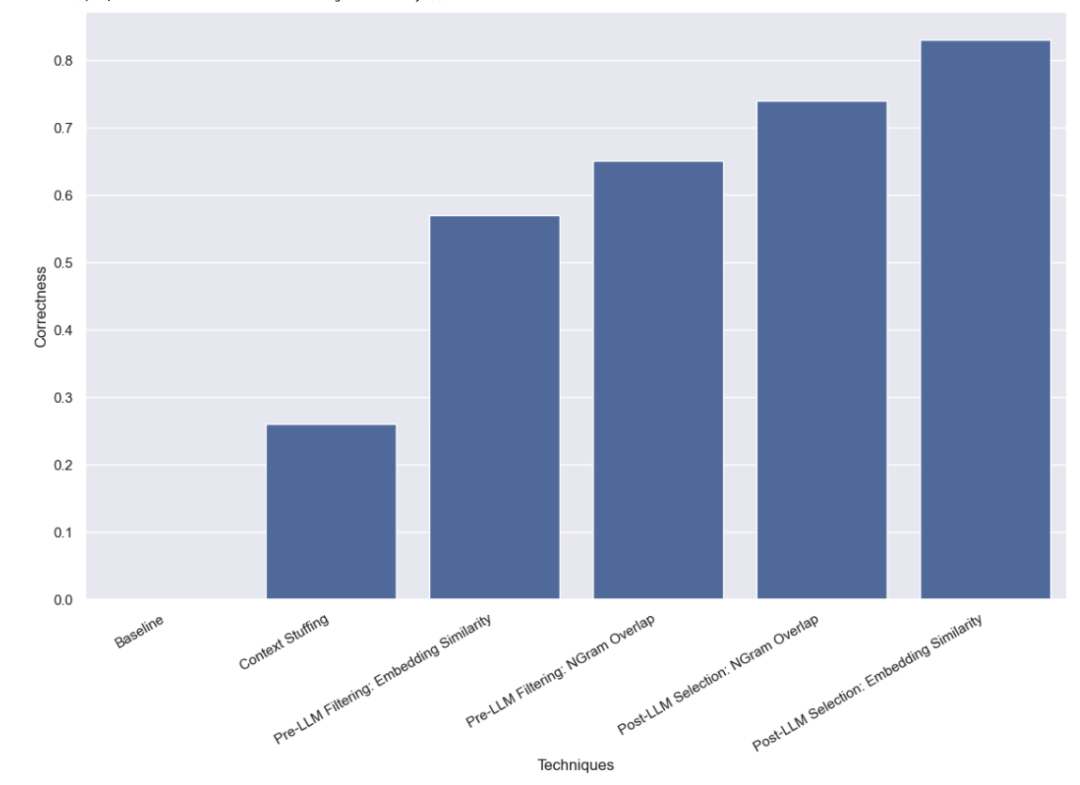
Tout d'abord, nous avons effectué un test de base sur LLM, c'est-à-dire en demandant directement à LLM d'effectuer une analyse de requête sans fournir d'informations de nom valides. Comme prévu, aucune question n’a reçu de réponse correcte. En effet, nous avons intentionnellement construit un ensemble de données qui nécessite d'interroger les auteurs par alias.
Méthode de remplissage contextuel
Dans cette méthode, nous mettons les 10 000 noms d'auteurs légaux dans l'invite et demandons à LLM de se rappeler qu'il s'agit de noms d'auteurs légaux lors de l'analyse des requêtes. Certains modèles (tels que GPT-3.5) ne peuvent tout simplement pas effectuer cette tâche en raison des limitations de la fenêtre contextuelle. Pour les autres modèles dotés de fenêtres contextuelles plus longues, ils ont également eu des difficultés à sélectionner avec précision le nom correct. GPT-4 n'a choisi le nom correct que dans 26 % des cas. Son erreur la plus courante consiste à extraire les noms sans les corriger. Cette méthode est non seulement lente, mais également coûteuse, prenant en moyenne 5 secondes et totalisant un coût total de 8,44 $.
Méthode de filtrage pré-LLM
La méthode que nous avons testée ensuite consiste à filtrer la liste des valeurs possibles avant de la transmettre au LLM. L'avantage est qu'il ne transmet qu'un sous-ensemble de noms possibles à LLM, ce qui signifie que LLM a beaucoup moins de noms à prendre en compte, ce qui, espérons-le, lui permettra d'effectuer une analyse des requêtes plus rapidement, à moindre coût et avec plus de précision. Mais cela ajoute également un nouveau mode de défaillance potentiel : que se passe-t-il si le filtrage initial échoue ?
Filtrage basé sur l'intégration
La méthode de filtrage que nous avons initialement utilisée était la méthode d'intégration et avons sélectionné les 10 noms les plus similaires à la requête. Notez que nous comparons l’intégralité de la requête au nom, ce qui n’est pas une comparaison idéale !
Nous avons constaté qu'en utilisant cette approche, GPT-3.5 était capable de traiter correctement 57 % des cas. Cette méthode est beaucoup plus rapide et moins chère que les méthodes précédentes, ne prenant que 0,76 seconde en moyenne, pour un coût total de seulement 0,002 $.
Méthode de filtrage basée sur la similarité NGram
La deuxième méthode de filtrage que nous utilisons consiste à TF-IDF vectoriser la séquence de caractères de 3 grammes de tous les noms valides et à utiliser les noms valides vectorisés avec la similarité cosinusoïdale vectorisée entre les entrées utilisateur est utilisé pour sélectionner les 10 noms valides les plus pertinents à ajouter aux invites du modèle. Notez également que nous comparons l’intégralité de la requête au nom, ce qui n’est pas une comparaison idéale !
Nous avons constaté qu'en utilisant cette approche, GPT-3.5 était capable de traiter correctement 65 % des cas. Cette méthode est également beaucoup plus rapide et moins chère que les méthodes précédentes, ne prenant que 0,57 seconde en moyenne et le coût total n'est que de 0,002 $.
Méthode de post-sélection LLM
La dernière méthode que nous avons testée consistait à essayer de corriger les erreurs une fois que LLM a terminé l'analyse préliminaire de la requête. Nous avons d’abord effectué une analyse des requêtes sur les entrées de l’utilisateur sans fournir aucune information sur les noms d’auteurs valides dans l’invite. Il s’agit du même test de base que nous avons effectué initialement. Nous avons ensuite effectué une étape ultérieure consistant à prendre les noms dans le champ de l'auteur et à trouver le nom valide le plus similaire.
Méthode de sélection basée sur la similarité d'intégration
Tout d'abord, nous avons effectué une vérification de similarité en utilisant la méthode d'intégration.
Nous avons constaté qu'en utilisant cette approche, GPT-3.5 était capable de traiter correctement 83 % des cas. Cette méthode est beaucoup plus rapide et moins chère que les méthodes précédentes, ne prenant que 0,66 seconde en moyenne et le coût total n'est que de 0,001 $.
Méthode de sélection basée sur la similarité NGramme
Enfin, nous essayons d'utiliser un vectoriseur de 3 grammes pour la vérification de la similarité.
Nous avons constaté qu'en utilisant cette approche, GPT-3.5 était capable de traiter correctement 74 % des cas. Cette méthode est également beaucoup plus rapide et moins chère que la méthode précédente, ne prenant que 0,48 seconde en moyenne et le coût total n'est que de 0,001 $.
Conclusion
Nous avons effectué plusieurs benchmarks sur les méthodes d'analyse de requêtes pour gérer les valeurs catégorielles à cardinalité élevée. Nous nous sommes limités à effectuer un seul appel LLM afin de simuler les contraintes de latence réelles. Nous avons constaté que l'intégration de méthodes de sélection basées sur la similarité fonctionnait mieux après l'utilisation de LLM.
Il existe d'autres méthodes qui méritent d'être testées davantage. En particulier, il existe de nombreuses façons différentes de trouver la valeur catégorielle la plus similaire avant ou après l'appel LLM. De plus, la base de catégories de cet ensemble de données n’est pas aussi élevée que celle de nombreux systèmes d’entreprise. Cet ensemble de données contient environ 10 000 valeurs, alors que de nombreux systèmes du monde réel peuvent avoir besoin de gérer des millions de cardinalités. Par conséquent, une analyse comparative sur des données de cardinalité plus élevée serait très utile.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
LeanCopilot, cet outil mathématique formel vanté par de nombreux mathématiciens comme Terence Tao, a encore évolué ? Tout à l'heure, Anima Anandkumar, professeur à Caltech, a annoncé que l'équipe avait publié une version étendue de l'article LeanCopilot et mis à jour la base de code. Adresse de l'article image : https://arxiv.org/pdf/2404.12534.pdf Les dernières expériences montrent que cet outil Copilot peut automatiser plus de 80 % des étapes de preuve mathématique ! Ce record est 2,3 fois meilleur que le précédent record d’Esope. Et, comme auparavant, il est open source sous licence MIT. Sur la photo, il s'agit de Song Peiyang, un garçon chinois.
 Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud, la société derrière le Plaud Note AI Voice Recorder (disponible sur Amazon pour 159 $), a annoncé un nouveau produit. Surnommé NotePin, l’appareil est décrit comme une capsule mémoire AI, et comme le Humane AI Pin, il est portable. Le NotePin est
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
La génération améliorée de récupération de graphiques (GraphRAG) devient progressivement populaire et est devenue un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article. structure
 Google AI annonce Gemini 1.5 Pro et Gemma 2 pour les développeurs
Jul 01, 2024 am 07:22 AM
Google AI annonce Gemini 1.5 Pro et Gemma 2 pour les développeurs
Jul 01, 2024 am 07:22 AM
Google AI a commencé à fournir aux développeurs un accès à des fenêtres contextuelles étendues et à des fonctionnalités économiques, à commencer par le modèle de langage large (LLM) Gemini 1.5 Pro. Auparavant disponible via une liste d'attente, la fenêtre contextuelle complète de 2 millions de jetons
 Comprendre GraphRAG (1) : les défis de RAG
Apr 30, 2024 pm 07:10 PM
Comprendre GraphRAG (1) : les défis de RAG
Apr 30, 2024 pm 07:10 PM
RAG (RiskAssessmentGrid) est une méthode qui améliore les grands modèles linguistiques (LLM) existants avec des sources de connaissances externes pour fournir des réponses plus pertinentes sur le plan contextuel. Dans RAG, le composant de récupération obtient des informations supplémentaires, la réponse est basée sur une source spécifique, puis introduit ces informations dans l'invite LLM afin que la réponse du LLM soit basée sur ces informations (phase d'amélioration). Le RAG est plus économique que d’autres techniques telles que le parage. Il présente également l'avantage de réduire les hallucinations en fournissant un contexte supplémentaire basé sur ces informations (étape d'augmentation) - votre RAG devient la méthode de workflow pour les tâches LLM d'aujourd'hui (telles que la recommandation, l'extraction de texte, l'analyse des sentiments, etc.). Si nous décomposons cette idée davantage, en fonction de l'intention de l'utilisateur, nous examinons généralement
 Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java : Traitement des requêtes API REST : Vert.x est le meilleur, avec un taux de requêtes de 2 fois SpringBoot et 3 fois Dropwizard. Requête de base de données : HibernateORM de SpringBoot est meilleur que l'ORM de Vert.x et Dropwizard. Opérations de mise en cache : le client Hazelcast de Vert.x est supérieur aux mécanismes de mise en cache de SpringBoot et Dropwizard. Cadre approprié : choisissez en fonction des exigences de l'application. Vert.x convient aux services Web hautes performances, SpringBoot convient aux applications gourmandes en données et Dropwizard convient à l'architecture de microservices.
