
 Périphériques technologiques
IA
1 Mo d'IA magique détecte des millions de fichiers avec une précision de 99 % !
Périphériques technologiques
IA
1 Mo d'IA magique détecte des millions de fichiers avec une précision de 99 % !
1 Mo d'IA magique détecte des millions de fichiers avec une précision de 99 % !

Dans le développement Web, la détection du type de fichier avant de télécharger les fichiers sur le serveur est cruciale. Cette étape peut non seulement garantir la sécurité du serveur et des utilisateurs, intercepter d'éventuels fichiers malveillants, mais également garantir que les fichiers téléchargés sont complets et répondent aux attentes, améliorant ainsi la conformité des données. Dans le même temps, en fournissant des commentaires et des conseils en temps opportun aux utilisateurs, cela peut également améliorer l'expérience utilisateur et éviter toute confusion inutile.
Frère A Bao a déjà présenté "Comment JavaScript détecte-t-il le type de fichier ?" Maintenant que nous sommes entrés dans l'ère de l'IA, nous devons suivre le rythme de notre temps. Ensuite, Brother Abao présentera comment utiliser l'outil open source Magika[1] de Google pour obtenir une détection précise du type de fichier.
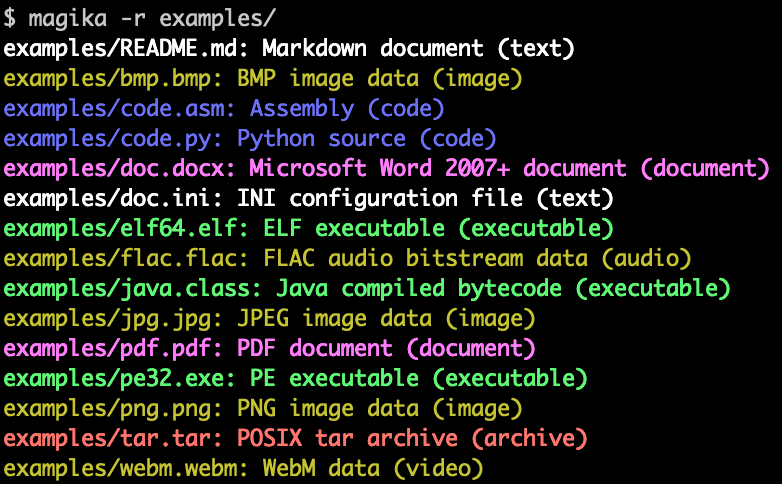 Photos
Photos
Magika Introduction
Magika+ est un nouvel outil de détection de classification de fichiers par intelligence artificielle qui s'appuie sur la dernière technologie d'apprentissage en profondeur pour fournir une détection précise. Il utilise un modèle Keras personnalisé hautement optimisé qui ne pèse qu'environ 1 Mo et permet une identification précise des fichiers en quelques millisecondes, même lorsqu'il est exécuté sur un seul processeur.
Dans les évaluations de plus d'un million de fichiers et de plus de 100 types de contenu (couvrant les formats de fichiers binaires et texte), Magika a atteint une précision et un rappel de plus de 99 %. Magika est utilisé à grande échelle pour assurer la sécurité des utilisateurs de Google en acheminant les fichiers Gmail, Drive et Safe Browsing vers les analyseurs de sécurité et de politique de contenu appropriés.
Caractéristiques de Magika
- Prend en charge la détection de plus de 100 types de fichiers.
- Prend en charge plusieurs méthodes d'utilisation telles que la ligne de commande Python, l'API Python et la version expérimentale TFJS.
- Une fois le modèle chargé (il s'agit d'une surcharge ponctuelle), le temps d'inférence est d'environ 5 ms par fichier.
- Temps d'inférence quasi constant quelle que soit la taille du fichier. Magika n'utilise qu'un sous-ensemble limité d'octets de fichier.
- Prend en charge le traitement par lots : prend en charge l'envoi simultané de plusieurs fichiers à la ligne de commande et à l'API, Magika utilisera le traitement par lots pour accélérer le temps d'inférence.
- Formé sur un ensemble de données de plus de 25 millions de fichiers sur plus de 100 types de contenu.
- Après une évaluation à grande échelle, la précision et le rappel moyens de Magika ont atteint plus de 99 %, surpassant les méthodes existantes.
- Magika utilise un système de seuil pour chaque type de contenu afin de déterminer s'il faut « faire confiance » aux prédictions d'un modèle ou s'il faut renvoyer une étiquette générique telle que « Document texte générique » ou « Données binaires inconnues ».
- Prend en charge trois modes de prédiction différents pour ajuster la tolérance aux erreurs : confiance élevée, confiance moyenne et meilleure estimation.
Performances de Magika
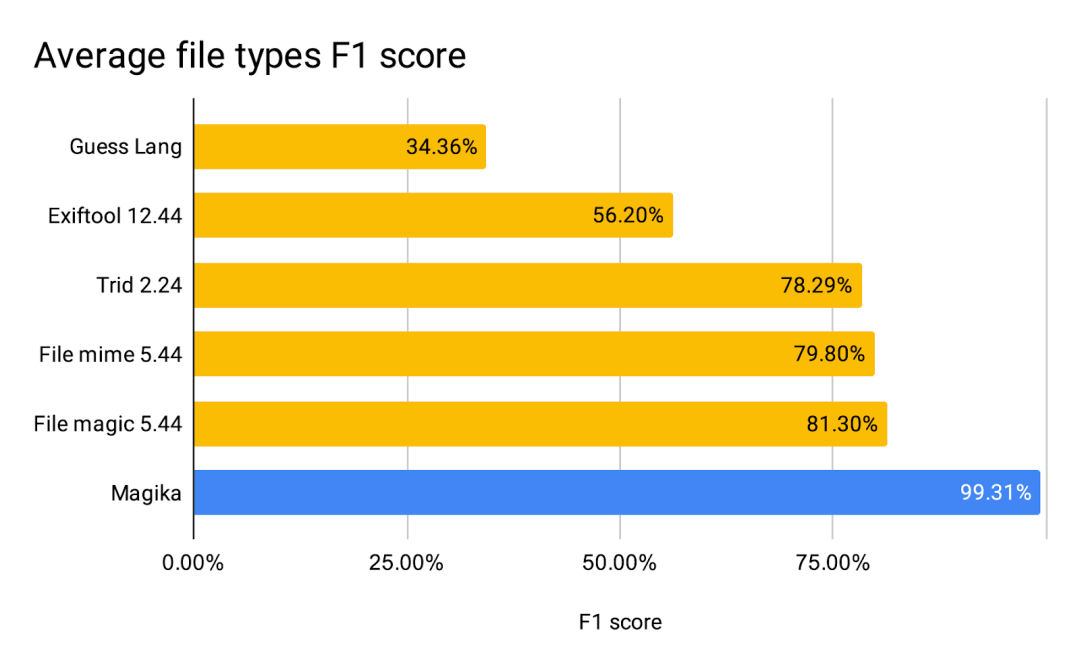 Pictures
Pictures
En termes de performances, Magika surpasse les autres applications modernes lorsqu'elles sont évaluées sur un benchmark de 1 million de fichiers avec plus de 100 types de fichiers grâce à son modèle d'IA et son vaste ensemble de données de formation. environ 20 % plus élevé. Ventilés par type de fichier, nous constatons de plus grandes améliorations de performances pour les fichiers texte, y compris les fichiers de code et les fichiers de configuration que d'autres outils peuvent avoir du mal à traiter.
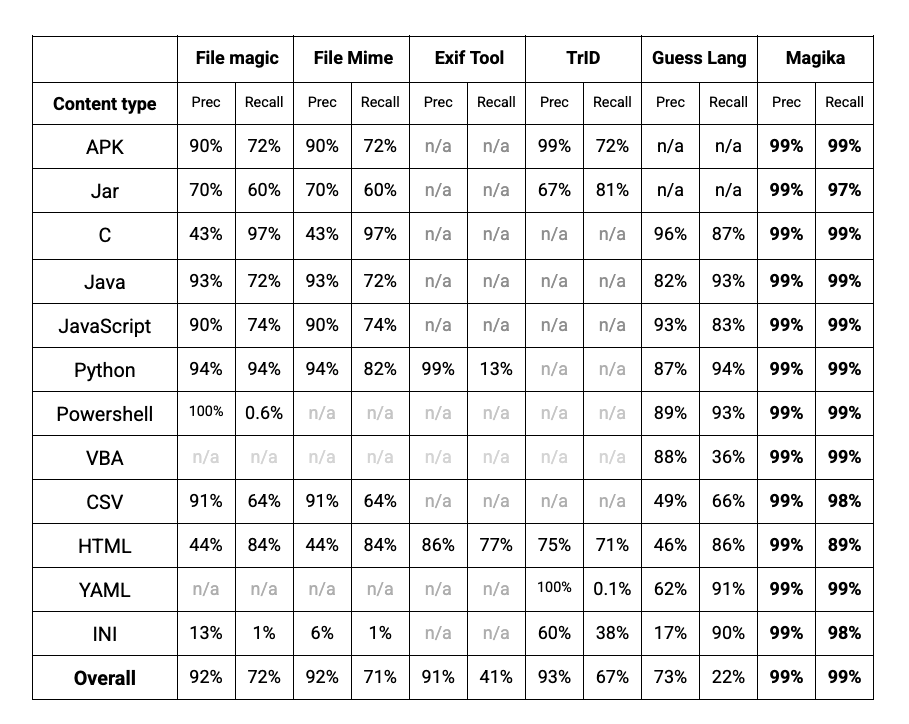 Images
Images
Exemple en ligne Magika
Magika prend en charge le navigateur et l'environnement Node.js, vous pouvez découvrir ses fonctions en visitant le site Web Web Demo[2].
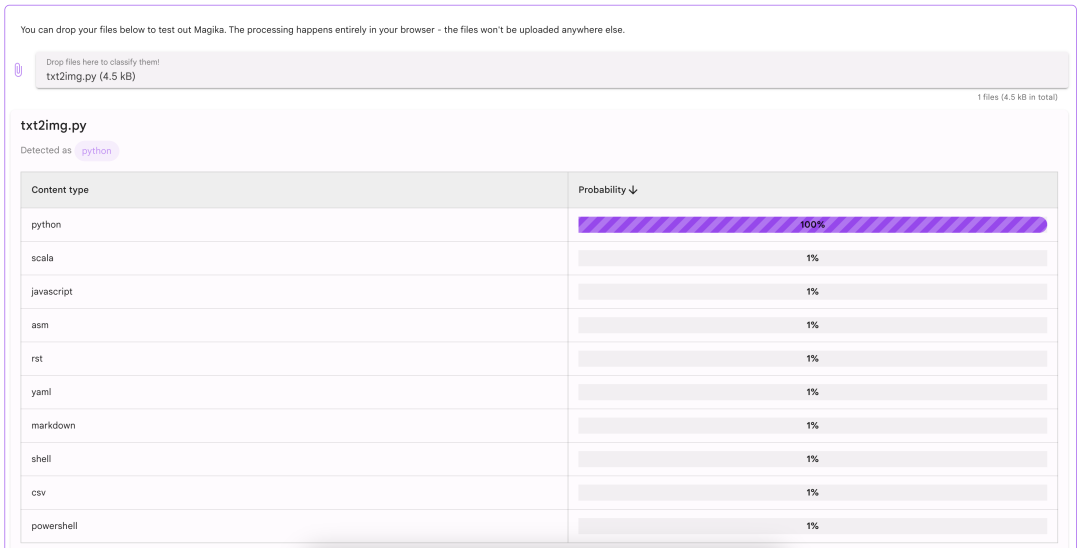 Photos
Photos
Magika Commencez vite
Installez magika
npm install magikaorpnpm add magika
Utilisez magika dans le navigateur
import { Magika } from "magika";const file = new File(["# Hello I am a markdown file"], "hello.md");const fileBytes = new Uint8Array(await file.arrayBuffer());const magika = new Magika();await magika.load();const prediction = await magika.identifyBytes(fileBytes);console.log(prediction);Utilisez magika dans Node.js
import { readFile } from "fs/promises";import { MagikaNode as Magika } from "magika";const data = await readFile("some file");const magika = new Magika();await magika.load();const prediction = await magika.identifyBytes(data);console.log(prediction);About Magika Contenu pertinent de,Si Si vous souhaitez en savoir plus sur Magika, vous pouvez continuer à lire cet article Magika : identification rapide et efficace du type de fichier grâce à l'IA[3].
Références
[1]Magika : https://github.com/google/magika
[2]Démo Web : https://google.github.io/magika/
[3]Magika : alimentée par l'IA identification rapide et efficace du type de fichier : https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
