
 Périphériques technologiques
IA
Brisez la malédiction il y a 36 ans ! Meta lance une méthode d'entraînement inversé pour éliminer la « malédiction d'inversion » des grands modèles
Périphériques technologiques
IA
Brisez la malédiction il y a 36 ans ! Meta lance une méthode d'entraînement inversé pour éliminer la « malédiction d'inversion » des grands modèles
Brisez la malédiction il y a 36 ans ! Meta lance une méthode d'entraînement inversé pour éliminer la « malédiction d'inversion » des grands modèles

La « malédiction du renversement » du grand modèle de langage a été résolue !
Cette malédiction a été découverte pour la première fois en septembre de l'année dernière, ce qui a immédiatement provoqué les exclamations de LeCun, Karpathy, Marcus et d'autres grands.

Parce que le grand modèle sans précédent et arrogant a en fait un "talon d'Achille" : un modèle de langage formé sur "A est B" ne peut pas répondre correctement "Est B A".
Par exemple, l'exemple suivant : LLM sait clairement que "la mère de Tom Cruise est Mary Lee Pfeiffer", mais ne peut pas répondre "L'enfant de Mary Lee Pfeiffer est Tom Cruise".

——C'était le GPT-4 le plus avancé à l'époque, en conséquence, même les enfants pouvaient avoir une pensée logique normale, mais LLM ne pouvait pas le faire.
Basé sur des données massives, il a mémorisé des connaissances qui surpassent presque tous les êtres humains, et pourtant il se comporte si bêtement. Il a obtenu le feu de la sagesse, mais est à jamais emprisonné dans cette malédiction.

Adresse papier : https://arxiv.org/pdf/2309.12288v1.pdf
Dès que cet incident est sorti, tout le réseau était en émoi.
D'un côté, les internautes ont dit que le grand mannequin est vraiment stupide, vraiment. Sachant seulement « A est B » mais ne sachant pas « B est A », j'ai finalement conservé ma dignité d'être humain.
D'autre part, les chercheurs ont également commencé à étudier cela et travaillent dur pour résoudre ce défi majeur.
Récemment, des chercheurs de Meta FAIR ont lancé une méthode de formation inversée pour résoudre d'un seul coup la « malédiction du renversement » du LLM.
Adresse papier : https://arxiv.org/pdf/2403.13799.pdf
Les chercheurs ont d'abord observé que les LLM sont formés de manière autorégressive de gauche à droite - c'est possible, c'est ce qui cause le renversement de la malédiction.
Donc, si vous entraînez le LLM (reverse training) dans le sens de droite à gauche, il est possible que le modèle voie les faits dans le sens inverse.
Le texte inversé peut être traité comme une seconde langue, en exploitant plusieurs sources différentes grâce au multitâche ou à une pré-formation multilingue.
Les chercheurs ont considéré 4 types d'inversion : l'inversion de jeton, l'inversion de mot, l'inversion préservant l'entité et l'inversion de segment aléatoire.
Inversion des jetons et des mots, en divisant la séquence en jetons ou en mots respectivement et en inversant leur ordre pour former une nouvelle séquence.
Entity Preserving Reverse, trouve les noms d'entités dans une séquence et préserve l'ordre des mots de gauche à droite tout en effectuant l'inversion des mots.
L'inversion de segment aléatoire divise la séquence tokenisée en blocs de longueur aléatoire, puis préserve l'ordre de gauche à droite dans chaque bloc.
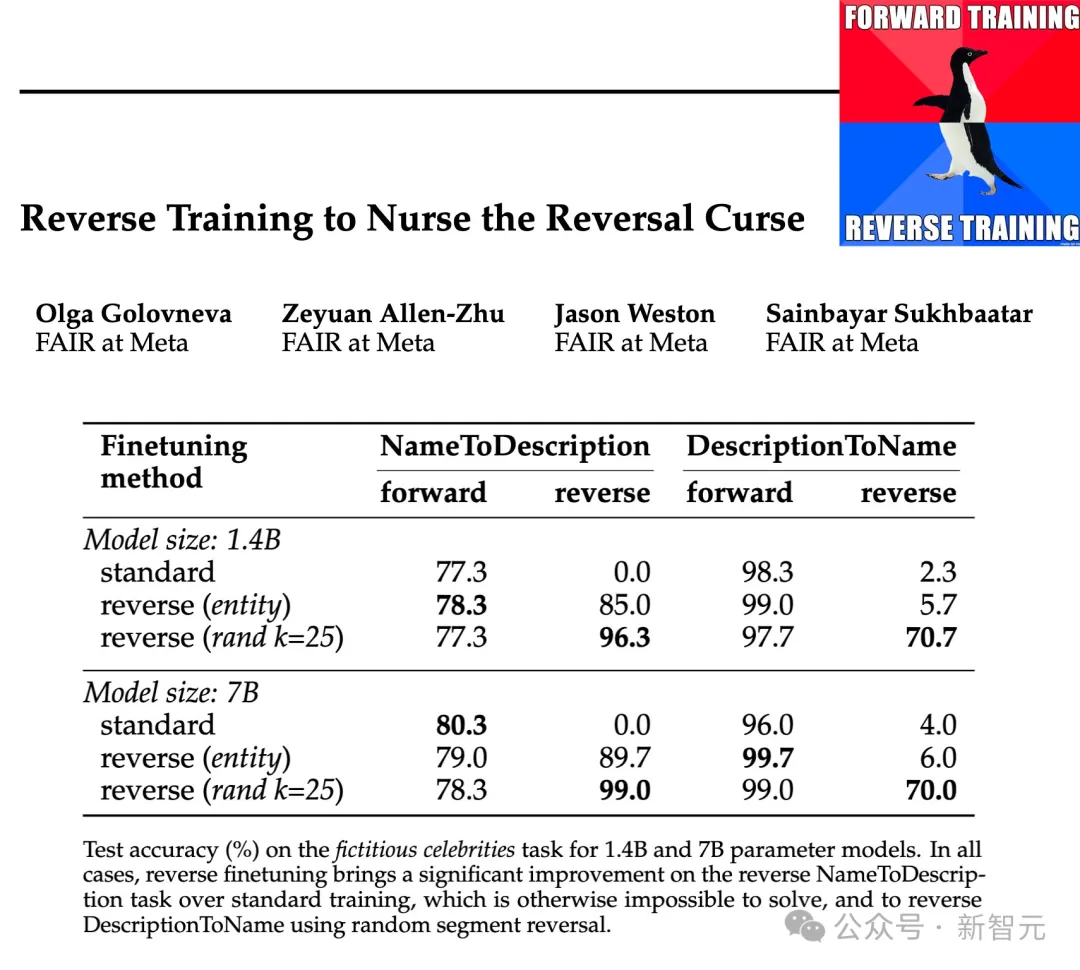
Les chercheurs ont testé l'efficacité de ces types d'inversion sur des échelles de paramètres de 1,4B et 7B, et les résultats ont montré qu'un entraînement à l'inversion par morceaux aléatoire et préservant l'entité peut atténuer la malédiction de l'inversion, voire l'éliminer complètement dans certains cas.
De plus, les chercheurs ont également découvert que l'inversion avant l'entraînement améliorait les performances du modèle par rapport à l'entraînement standard de gauche à droite - l'entraînement inversé peut donc être utilisé comme méthode d'entraînement générale.
Méthode d'entraînement inverse
L'entraînement inverse comprend l'obtention d'un ensemble de données d'entraînement avec N échantillons et la construction d'un ensemble d'échantillons inversés REVERSE (x).
La fonction REVERSE est chargée d'inverser une chaîne donnée, comme suit :
Inversion de mots : Chaque exemple est d'abord divisé en mots, puis la chaîne est inversée au niveau du mot, en utilisant des espaces reliés entre eux.
Inversion de préservation d'entité : exécutez un détecteur d'entité sur un échantillon d'entraînement donné, en divisant également les non-entités en mots. Ensuite, les mots non-entités sont inversés, tandis que les mots représentant les entités conservent leur ordre d'origine.
Inversion de segments aléatoires : au lieu d'utiliser un détecteur d'entités, nous essayons d'utiliser un échantillonnage uniforme pour diviser aléatoirement la séquence en segments de tailles comprises entre 1 et k jetons, puis inverser ces segments, mais garder chacun l'ordre des mots dans un segment, après quoi les segments sont connectés à l'aide du jeton spécial [REV].
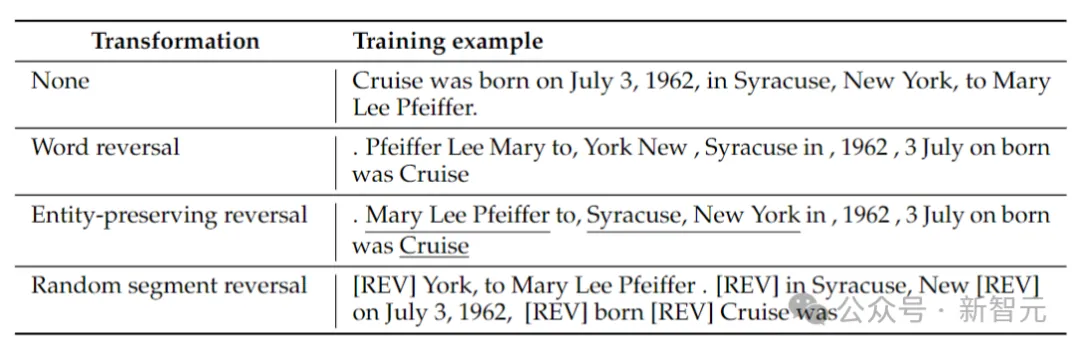
Le tableau ci-dessus donne des exemples de différents types d'inversion sur une chaîne donnée.
À l'heure actuelle, le modèle de langage est toujours entraîné de gauche à droite. Dans le cas de l'inversion de mots, cela équivaut à prédire des phrases de droite à gauche.
La formation inverse implique une formation sur des exemples standard et inversés, de sorte que le nombre de jetons de formation est doublé, tandis que les échantillons de formation avant et arrière sont mélangés.
La transformation inverse peut être considérée comme une seconde langue que le modèle doit apprendre. Notez que lors de l'inversion, la relation entre les faits reste inchangée et le modèle peut juger à partir de la grammaire s'il s'agit d'une langue directe ou inversée. modèle de prédiction.
Une autre perspective de l'entraînement inverse peut être expliquée par la théorie de l'information : le but de la modélisation du langage est d'apprendre la distribution de probabilité du langage naturel
Entraînement et tests de tâches inversées
Cartographie de paires d'entités
Commencez par créer un simple ensemble de données basé sur des symboles pour étudier la malédiction d'inversion dans un environnement contrôlé.
Associez aléatoirement les entités a et b de manière individuelle. Les données d'entraînement contiennent toutes les paires de mappages (a→b), mais seulement la moitié des mappages (b→a), et l'autre moitié sert de données de test.
Le modèle doit déduire la règle a→b ⇔ b→a à partir des données d'entraînement puis la généraliser aux paires dans les données de test.
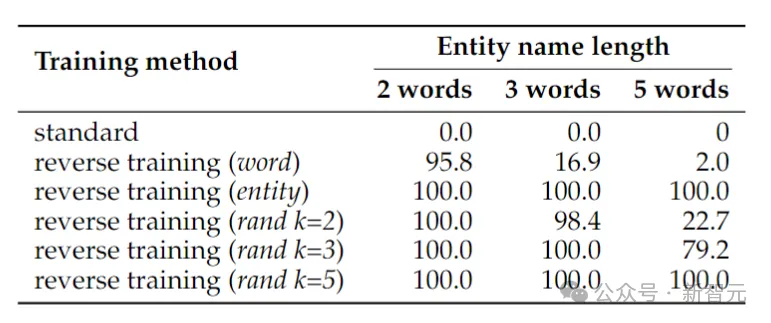
Le tableau ci-dessus montre la précision du test (%) de la tâche d'inversion de signe. Malgré la simplicité de la tâche, la formation du modèle de langage standard échoue complètement, ce qui suggère qu’il est peu probable que la mise à l’échelle à elle seule puisse la résoudre.
En revanche, la formation inversée peut presque résoudre le problème des entités à deux mots, mais ses performances diminuent rapidement à mesure que les entités s'allongent.
L'inversion de mots fonctionne bien pour les entités plus courtes, mais pour les entités contenant plus de mots, l'inversion préservant l'entité est nécessaire. L'inversion aléatoire de segment fonctionne bien lorsque la longueur maximale du segment k est au moins aussi longue que l'entité.
Récupération des noms des personnes
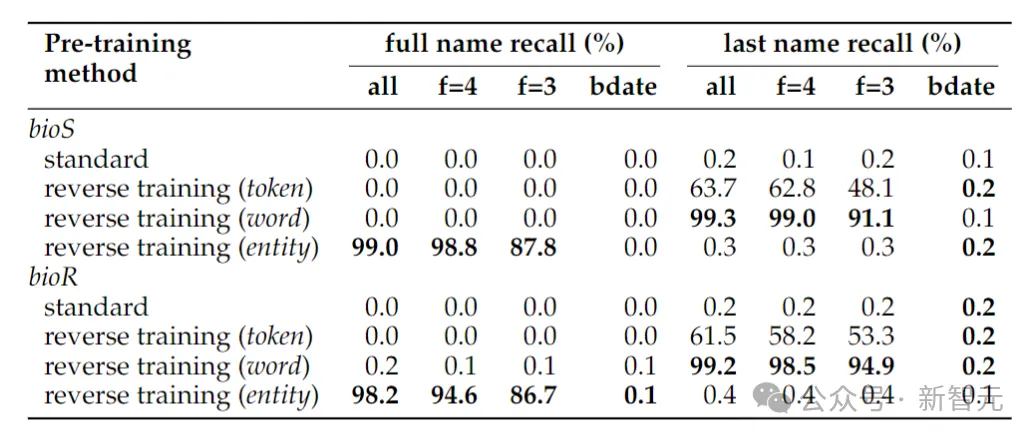
Le tableau ci-dessus montre la tâche d'inversion consistant à déterminer le nom complet d'une personne. L'exactitude de la tâche d'inversion lorsque seule la date de naissance est donnée pour déterminer le nom complet d'une personne. le nom complet est toujours proche de zéro, car dans la méthode de détection d'entité adoptée dans cet article, les dates sont traitées comme trois entités, leur ordre n'est donc pas conservé lors de l'inversion.
Si la tâche d'inversion se réduit à la simple détermination du nom de famille d'une personne, l'inversion au niveau des mots est suffisante.
Un autre phénomène qui peut surprendre est que la méthode de rétention d'entité peut déterminer le nom complet de la personne, mais pas son nom de famille.
C'est un phénomène connu : les modèles de langage peuvent être complètement incapables de récupérer des jetons tardifs de fragments de connaissances (tels que les noms de famille).
Faits du monde réel
Ici, l'auteur a formé un modèle Llama-2 de 1,4 milliard de paramètres, entraînant un modèle de base de 2 000 milliards de jetons dans la direction de gauche à droite.
En revanche, l'entraînement inverse n'utilise que 1 000 milliards de jetons, mais utilise le même sous-ensemble de données pour s'entraîner dans deux directions, de gauche à droite et de droite à gauche - les deux directions combinées représentent 2 000 milliards de jetons, garantissant l'équité et la justice en termes de ressources informatiques.
Pour tester l'inversion des faits du monde réel, les chercheurs ont utilisé une tâche de célébrité, qui comprenait des questions telles que « Qui est la mère d'une célébrité ? » ainsi que des questions d'inversion plus difficiles, par exemple « Qui sont les enfants d'un certain ». les parents d'une célébrité ?"
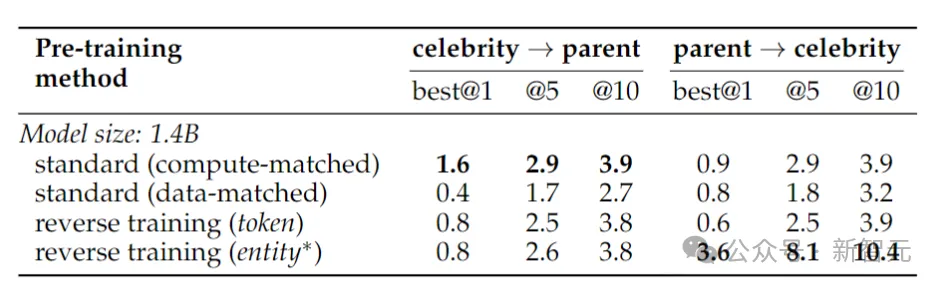
Les résultats sont présentés dans le tableau ci-dessus. Les chercheurs ont échantillonné les modèles plusieurs fois pour chaque question et considéraient que c'était un succès si l'un d'entre eux contenait la bonne réponse.
En général, la précision est généralement relativement faible car le modèle est petit en termes de nombre de paramètres, a un pré-entraînement limité et manque de réglage fin. Cependant, l’entraînement inversé a donné de meilleurs résultats.
Prophétie il y a 36 ans
En 1988, Fodor et Pylyshyn ont publié un article sur la nature systématique de la pensée dans la revue "Cognition".

Si vous comprenez vraiment ce monde, alors vous devriez être capable de comprendre la relation entre a et b, et la relation entre b et a.
Même les créatures cognitives non verbales devraient être capables de le faire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
