
 Périphériques technologiques
IA
CVPR 2024 | La segmentation de tous les modèles a une faible capacité de généralisation du SAM ? Stratégie d'adaptation de domaine résolue
Périphériques technologiques
IA
CVPR 2024 | La segmentation de tous les modèles a une faible capacité de généralisation du SAM ? Stratégie d'adaptation de domaine résolue
CVPR 2024 | La segmentation de tous les modèles a une faible capacité de généralisation du SAM ? Stratégie d'adaptation de domaine résolue

entre l'ensemble de données d'entraînement et l'ensemble de données de test en aval. Par conséquent, une question très importante est de savoir comment concevoir un schéma d’adaptation de domaine pour rendre SAM plus robuste face au monde réel et aux diverses tâches en aval ? La première stratégie d'adaptation de domaine pour le grand modèle "Segment Anything" est là ! Les articles connexes ont été acceptés par CVPR 2024. Le succès des grands modèles de langage (LLM) a inspiré le domaine de la vision par ordinateur à explorer les modèles de base pour la segmentation. Ces modèles de segmentation de base sont généralement utilisés pour la segmentation de zéro/quelques images via Prompt Engineer. Parmi eux, Segment Anything Model (SAM) est le modèle de base le plus avancé pour la segmentation d’images.个 Tu SAM a obtenu de mauvais résultats sur plusieurs tâches en aval. Mais des recherches récentes montrent que SAM n'est pas très puissant et généralisé dans de nombreuses tâches en aval, comme de mauvaises performances dans des domaines tels que les images médicales, les objets camouflés et les images naturelles avec des interférences supplémentaires. Cela peut être dû au grand Domain Shift
Premièrement, le paradigme traditionnel d'adaptation de domaine non supervisé nécessite un

, l'adaptation non supervisée sera très difficile.大 Figure 1 SAM est un pré-entraînement sur des ensembles de données à grande échelle, mais il existe un problème de généralisation. Nous utilisons une supervision faible pour adapter SAM sur diverses tâches en aval
- Pour réduire davantage le coût de calcul élevé lié à la mise à jour des poids complets du modèle, nous appliquons une
décomposition des poids de bas rang à l'encodeur et effectuons une rétropropagation via un chemin de raccourci de bas rang. Enfin, afin d'améliorer encore l'effet de l'adaptation passive du domaine, nous introduisons une supervision faible, telle que des annotations de points clairsemées, dans le domaine cible pour fournir en même temps des informations d'adaptation de domaine plus fortes. Ce type de supervision faible est naturellement compatible avec l'encodeur de repère dans SAM. Avec un encadrement faible comme Prompt, nous obtenons des pseudo labels auto-formés plus locaux et explicites. Le modèle optimisé montre une capacité de généralisation plus forte sur plusieurs tâches en aval.
Nous résumons les contributions de ce travail comme suit : 
Adresse de l'article : https://arxiv.org/pdf/2312.03502.pdf Adresse du projet : https://github.com/Zhang-Haojie/WeSAM -
Titre de l'article : Améliorer la généralisation de Modèle de base de segmentation sous changement de distribution via une adaptation faiblement supervisée
mise à jour du poids de faible rang
- 1. Segmenter n'importe quel modèle
- SAM consiste principalement de trois composants Composition : Image Encoder (ImageEncoder), Prompt Encoder (PromptEncoder) et Decoder (MaskDecoder)
- .
-
L'encodeur d'image est pré-entraîné à l'aide de MAE, et l'ensemble du SAM est affiné davantage sur l'ensemble d'entraînement SA-1B avec 1,1 milliard d'annotations. Une combinaison de perte focale et de perte de dés est utilisée pendant l'entraînement. Au moment de l'inférence, une image de test x est d'abord codée par un encodeur d'image, puis, à l'invite, un décodeur léger effectue trois niveaux de prédictions.
Pour l'ensemble de données cible non étiqueté DT={xi} et le pré- modèle de segmentation entraîné. Nous utilisons l'architecture
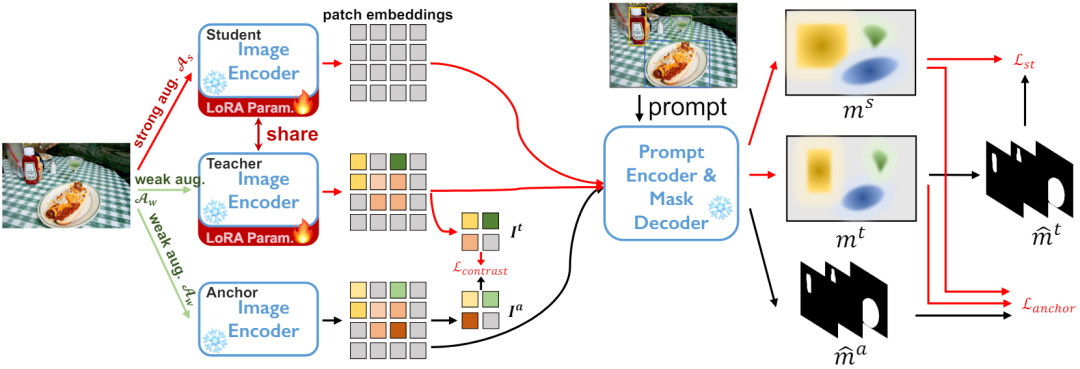 Dans le réseau de décodeur, étant donné un certain nombre Np d'invites, telles qu'une boîte, un point ou un masque grossier, un ensemble de masques de segmentation d'instance sera déduit.
Dans le réseau de décodeur, étant donné un certain nombre Np d'invites, telles qu'une boîte, un point ou un masque grossier, un ensemble de masques de segmentation d'instance sera déduit.
minimise la perte de dés
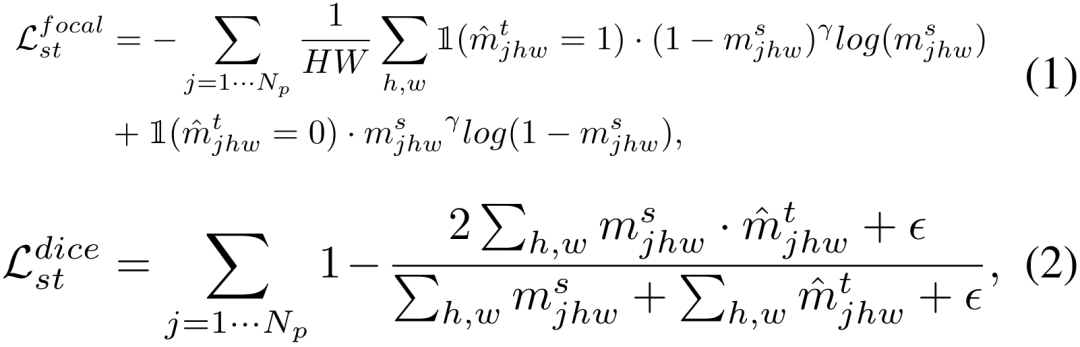 下 Comparaison perte des deux branches de la figure 3
下 Comparaison perte des deux branches de la figure 3
Les deux objectifs d'entraînement ci-dessus sont effectués dans l'espace de sortie du décodeur. La partie expérimentale révèle que la mise à jour du réseau d'encodeurs est le moyen le plus efficace d'adapter SAM, il est donc nécessaire d'appliquer directement la régularisation aux caractéristiques sorties du réseau d'encodeurs 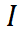
est le coefficient de température. 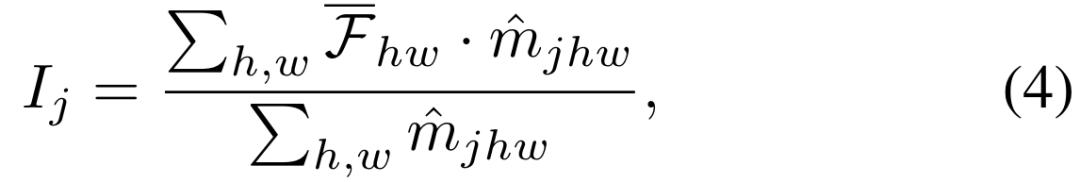
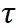
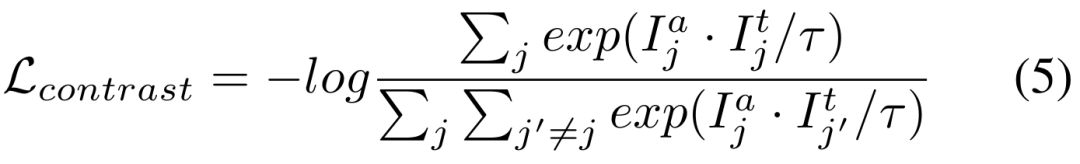

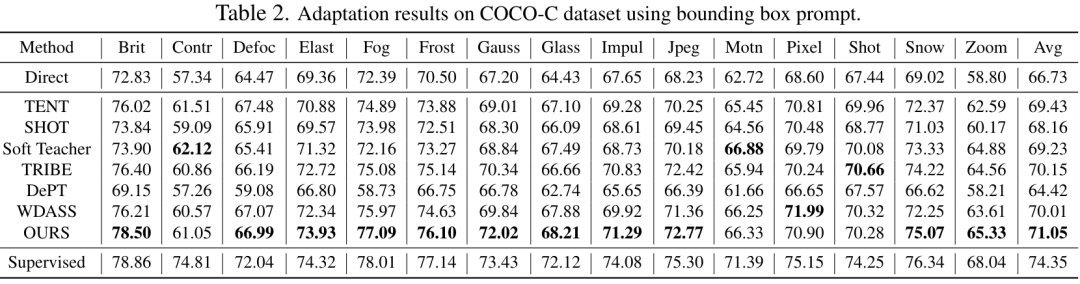
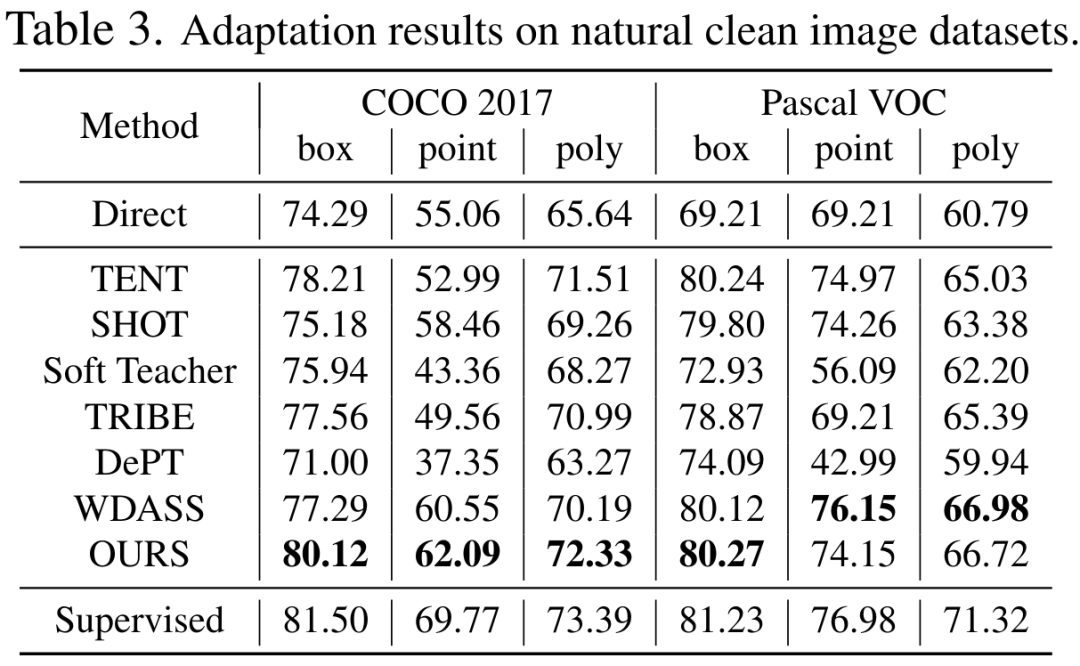
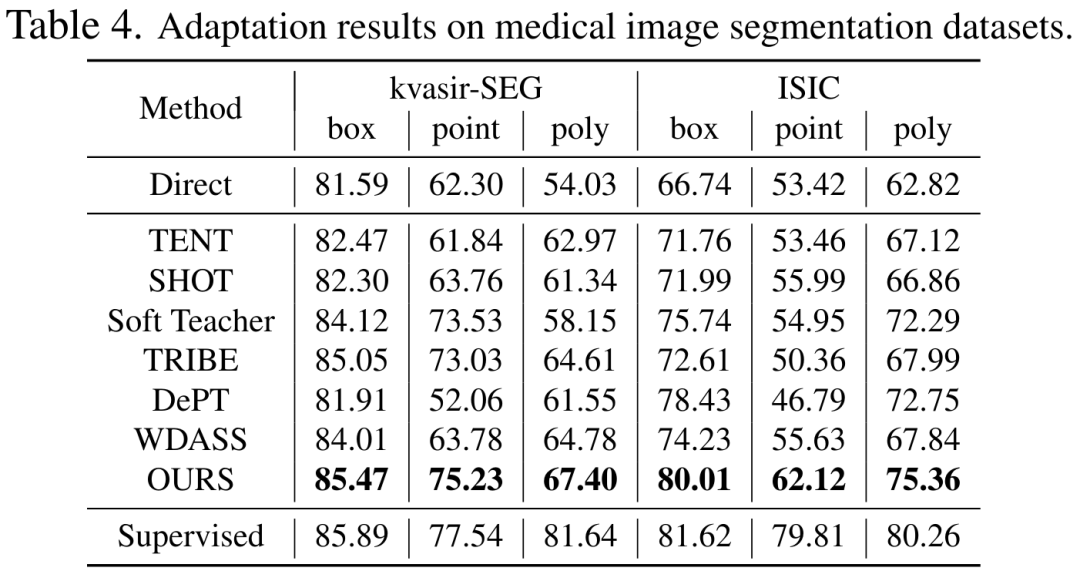
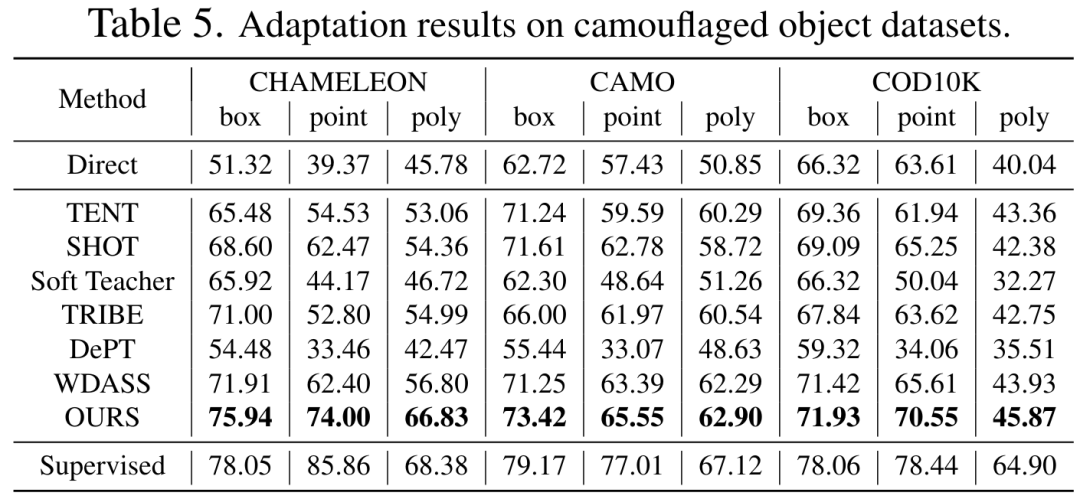


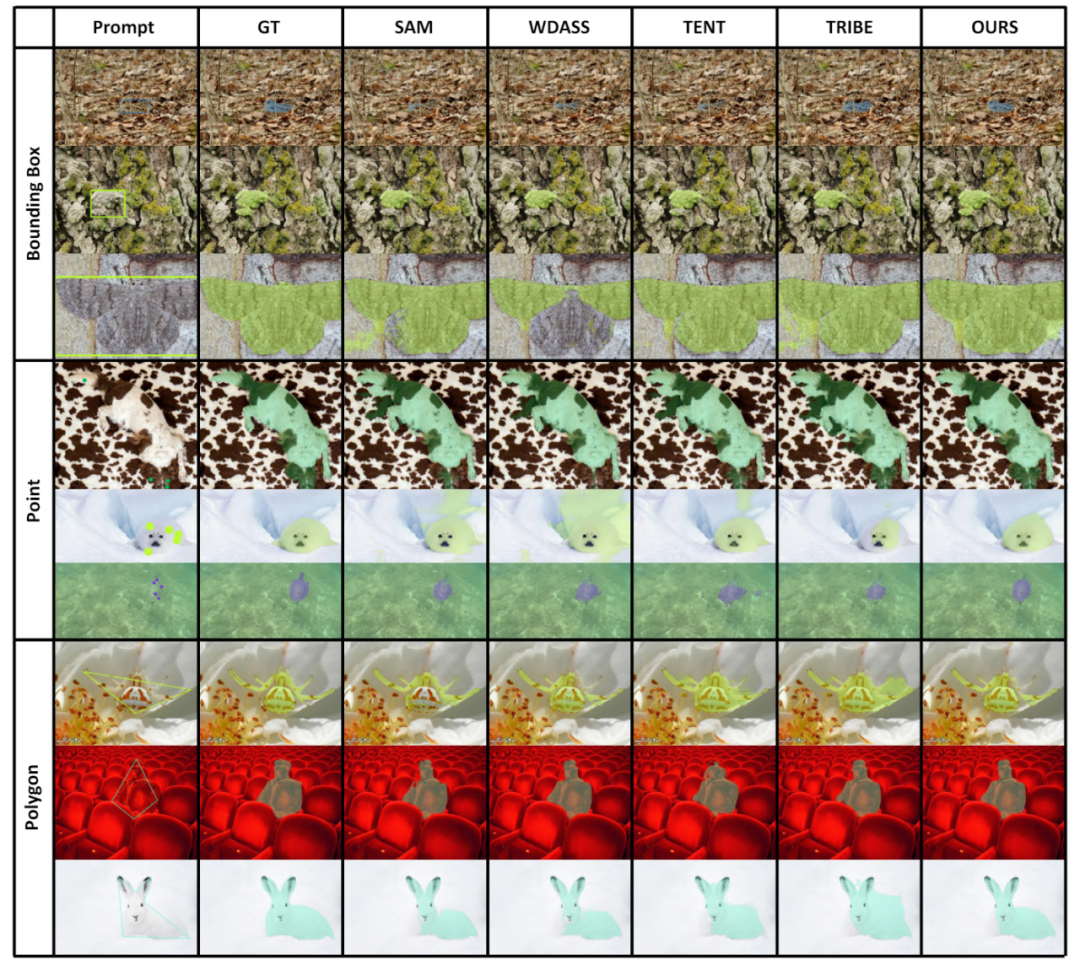
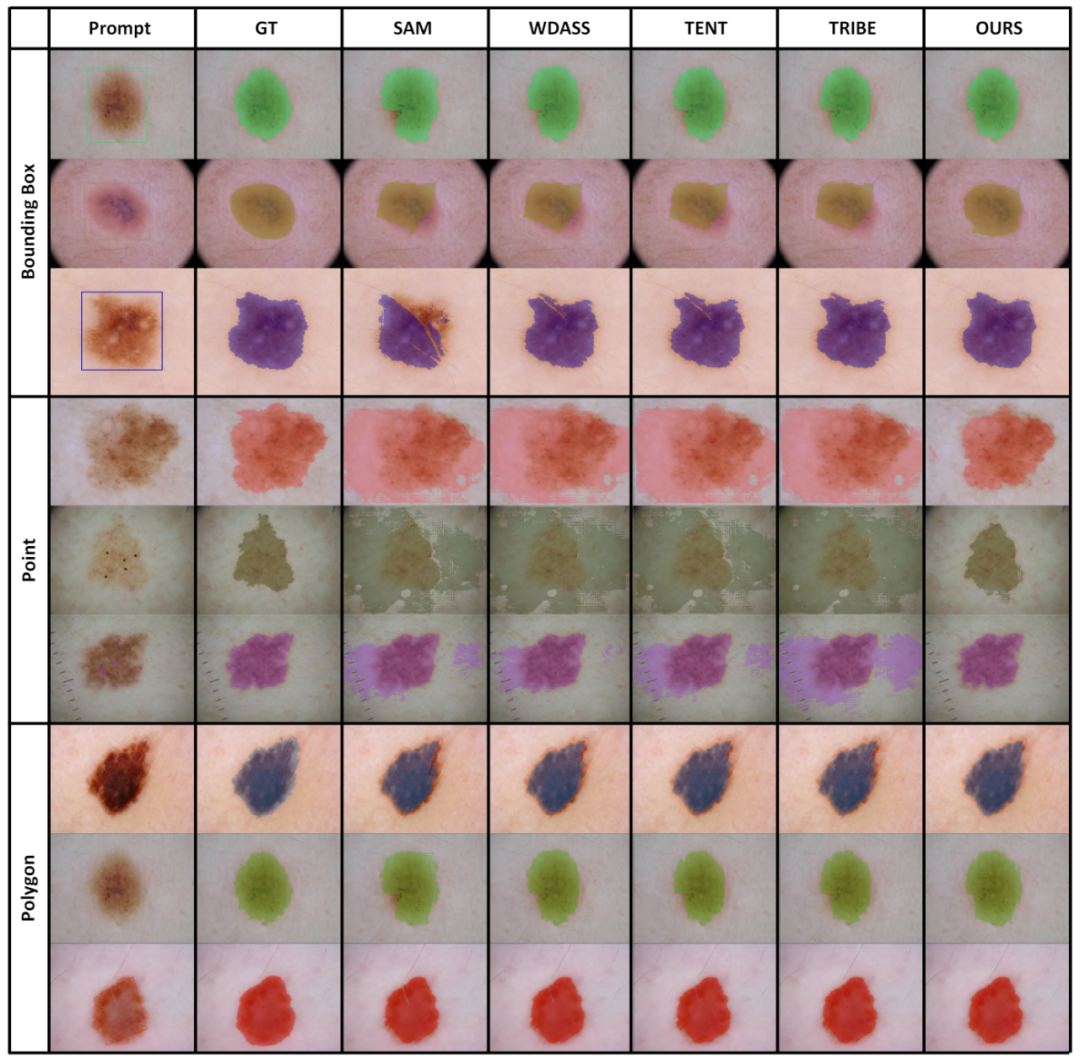
Bien que le modèle de vision de base puisse bien fonctionner sur les tâches de segmentation, il souffre toujours de mauvaises performances dans les tâches en aval. Nous étudions la capacité de généralisation du modèle Segment-Anything dans plusieurs tâches de segmentation d'images en aval et proposons une méthode d'auto-entraînement basée sur la régularisation des ancres et le réglage fin de bas rang. Cette méthode ne nécessite pas d'accès à l'ensemble de données source, a un faible coût en mémoire, est naturellement compatible avec une supervision faible et peut améliorer considérablement l'effet adaptatif. Après une vérification expérimentale approfondie, les résultats montrent que la méthode d'adaptation de domaine proposée peut améliorer considérablement la capacité de généralisation du SAM sous divers changements de distribution. 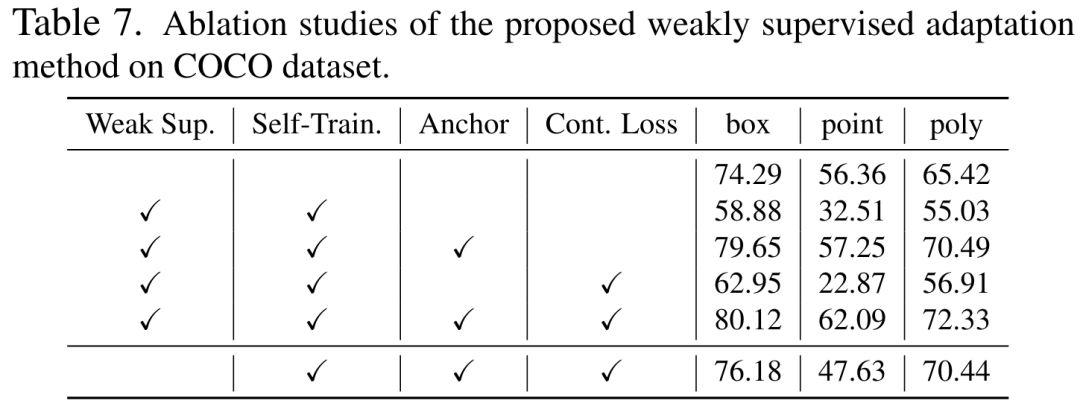
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Dans le cadre du cadre de beegoorm, comment spécifier la base de données associée au modèle? De nombreux projets Beego nécessitent que plusieurs bases de données soient opérées simultanément. Lorsque vous utilisez Beego ...
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Le problème de l'utilisation de Redessstream pour implémenter les files d'attente de messages dans le langage GO consiste à utiliser le langage GO et redis ...
 CS-semaine 3
Apr 04, 2025 am 06:06 AM
CS-semaine 3
Apr 04, 2025 am 06:06 AM
Les algorithmes sont l'ensemble des instructions pour résoudre les problèmes, et leur vitesse d'exécution et leur utilisation de la mémoire varient. En programmation, de nombreux algorithmes sont basés sur la recherche et le tri de données. Cet article présentera plusieurs algorithmes de récupération et de tri de données. La recherche linéaire suppose qu'il existe un tableau [20,500,10,5,100,1,50] et doit trouver le numéro 50. L'algorithme de recherche linéaire vérifie chaque élément du tableau un par un jusqu'à ce que la valeur cible soit trouvée ou que le tableau complet soit traversé. L'organigramme de l'algorithme est le suivant: Le pseudo-code pour la recherche linéaire est le suivant: Vérifiez chaque élément: Si la valeur cible est trouvée: return True return false C Implementation: # include # includeIntMain (void) {i
