
 Périphériques technologiques
IA
Une percée complète, Google a mis à jour un grand nombre de produits de grande taille hier soir
Périphériques technologiques
IA
Une percée complète, Google a mis à jour un grand nombre de produits de grande taille hier soir
Une percée complète, Google a mis à jour un grand nombre de produits de grande taille hier soir

Ce mardi, Google a publié une série de mises à jour de modèles et de produits liés à l'IA lors du Google Cloud Next 2024, notamment Gemini 1.5 Pro qui fournit pour la première fois une fonction de compréhension locale de la parole (parole), le nouveau modèle de génération de code CodeGemma, le premier Processeur Arm auto-développé Axion et ainsi de suite.

Gemini 1.5 Pro
Gemini 1.5 Pro, le modèle d'IA générative le plus puissant de Google, est désormais disponible en avant-première publique sur Vertex AI, la plateforme de développement d'IA axée sur les entreprises de Google. Il s’agit de la plateforme de développement d’IA de Google pour les entreprises. Le contexte qu'il peut gérer passe de 128 000 jetons à 1 million de jetons. Un million de jetons équivaut à environ 700 000 mots, soit environ 30 000 lignes de code. Cela représente environ quatre fois la quantité de données que le modèle phare d'Anthropic, Claude 3, peut gérer en entrée, et environ huit fois la quantité de contexte maximale du GPT-4 Turbo d'OpenAI.
Lien officiel du texte original : https://developers.googleblog.com/2024/04/gemini-15-pro-in-public-preview-with-new-features.html
Ce version Pour la première fois, des capacités de compréhension audio (parole) locale et une nouvelle API de fichier sont fournies pour faciliter le traitement des fichiers. Les modes de saisie de Gemini 1.5 Pro sont étendus pour inclure la compréhension audio (parole) dans l'API Gemini et Google AI Studio. De plus, Gemini 1.5 Pro est désormais capable d'effectuer des inférences sur les images (images) et l'audio (parole) des vidéos téléchargées dans Google AI Studio.

Vous pouvez télécharger un enregistrement d'une conférence, comme cette conférence avec plus de 117 000 jetons de Jeff Dean, et Gemini 1.5 Pro peut le convertir en un test avec des réponses. (La démo a été accélérée)
Google a également apporté des améliorations à l'API Gemini, notamment les trois contenus suivants :
Actuellement, les commandes système peuvent être utilisées dans Google AI Studio et l'API Gemini pour guider la réponse de le modèle. Définissez des rôles, des formats, des objectifs et des règles pour guider le comportement du modèle pour vos cas d'utilisation spécifiques.
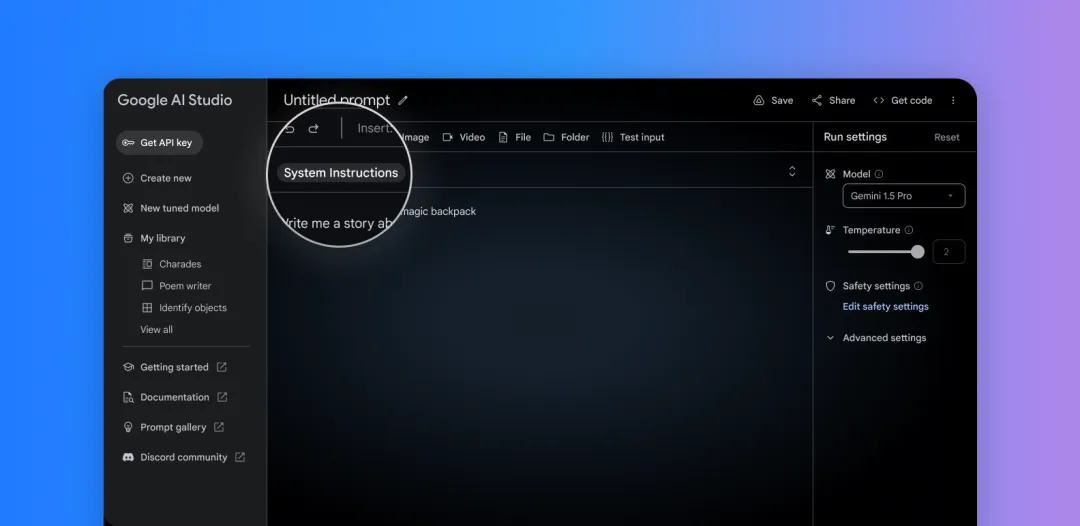
Définissez facilement les commandes système dans Google AI Studio
2 Mode JSON : demandez au modèle de générer uniquement des objets JSON. Ce modèle permet d'extraire des données structurées à partir de texte ou d'images. cURL est maintenant disponible, avec la prise en charge du SDK Python bientôt.
3. Améliorations des appels de fonction : vous pouvez désormais sélectionner des modes pour limiter la sortie du modèle et améliorer la fiabilité. Sélectionnez du texte, des appels de fonction ou simplement la fonction elle-même.
De plus, Google publiera un modèle d'intégration de texte de nouvelle génération qui surpasse les modèles similaires. À partir d'aujourd'hui, les développeurs pourront accéder aux modèles d'intégration de texte de nouvelle génération via l'API Gemini. Ce nouveau modèle, text-embedding-004 (text-embedding-preview-0409 dans Vertex AI), atteint des performances de récupération plus élevées sur le benchmark MTEB et surpasse les modèles existants de dimensions comparables.
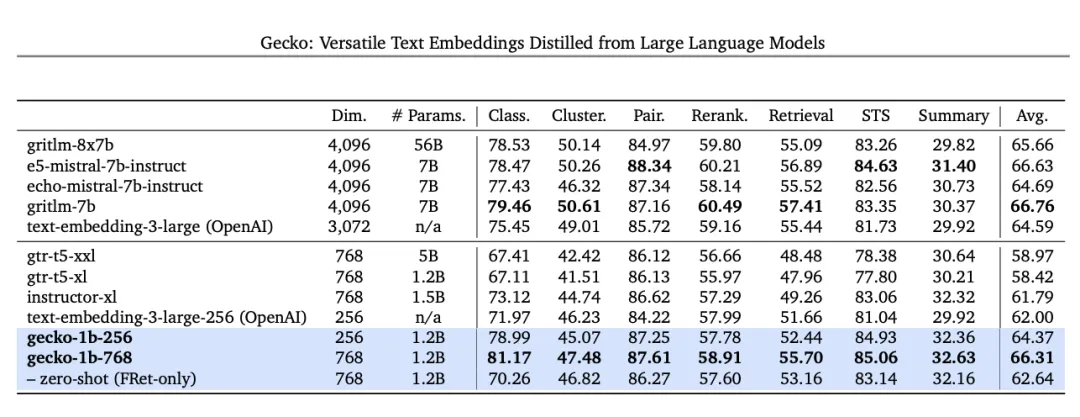
Dans le benchmark MTEB, Text-embedding-004 (alias Gecko) utilisant une sortie de 256 dims a surpassé tous les plus grands modèles de sortie de 768 dims
Cependant, il convient de noter que Gemini 1.5 Pro n'est pas disponible pour ceux qui n’ont pas accès à Vertex AI et AI Studio. Actuellement, la plupart des gens interagissent avec les modèles linguistiques Gemini via le chatbot Gemini. Gemini Ultra alimente le chatbot Gemini Advanced, et bien qu'il soit puissant et puisse comprendre de longues commandes, il n'est pas aussi rapide que Gemini 1.5 Pro.

Trois outils open source majeurs
Lors de la conférence Google Cloud Next en 2024, la société a lancé plusieurs outils open source, principalement pour prendre en charge les projets et les infrastructures d'IA générative. L'un d'eux est Max Diffusion, qui est une collection d'implémentations de référence de divers modèles de diffusion qui s'exécutent sur des appareils XLA (Accelerated Linear Algebra).
Adresse GitHub : https://github.com/google/maxdiffusion
Le second est Jetstream, un nouveau moteur pour exécuter des modèles d'IA génératifs. Actuellement, JetStream ne prend en charge que le TPU, mais pourrait être compatible avec le GPU à l'avenir. Google affirme que JetStream peut offrir jusqu'à 3 fois le rapport prix/performances de modèles comme le Gemma 7B de Google et le Llama 2 de Meta.
Adresse GitHub : https://github.com/google/JetStream
Le troisième est MaxTest, qui est un modèle d'IA de génération de texte pour les TPU et les GPU Nvidia dans la collection cloud. . MaxText inclut désormais Gemma 7B, GPT-3 d'OpenAI, Llama 2 et des modèles de la startup d'IA Mistral, qui, selon Google, peuvent tous être personnalisés et ajustés aux besoins des développeurs.
Adresse GitHub : https://github.com/google/maxtext
Le premier processeur Arm auto-développé Axion

Google Cloud a annoncé le lancement de son premier processeur auto- développé un processeur Arm Processeur Arm, appelé Axion. Il est basé sur Arm's Neoverse 2 et est conçu pour les centres de données. Google affirme que ses instances Axion fonctionnent 30 % mieux que les autres instances basées sur Arm de concurrents comme AWS et Microsoft, et qu'elles sont jusqu'à 50 % plus performantes et 60 % plus économes en énergie que les instances correspondantes basées sur X86.
Google a souligné lors de l'événement de lancement de mardi que, étant donné qu'Axion est construit sur une base ouverte, les clients de Google Cloud pourront transférer leurs charges de travail Arm existantes vers Google Cloud sans aucune modification.
Cependant, Google n'a pas encore publié d'introduction détaillée à ce sujet.
Outil de complétion et de génération de code - CodeGemma
CodeGemma est basé sur le modèle Gemma et apporte des fonctions de codage puissantes et légères à la communauté. Le modèle peut être divisé en une variante pré-entraînée 7B qui gère spécifiquement les tâches de complétion et de génération de code, une variante optimisée par commande 7B pour la conversation de code et le suivi de commandes, et une variante pré-entraînée 2B qui exécute une complétion rapide du code sur le site local. ordinateur.
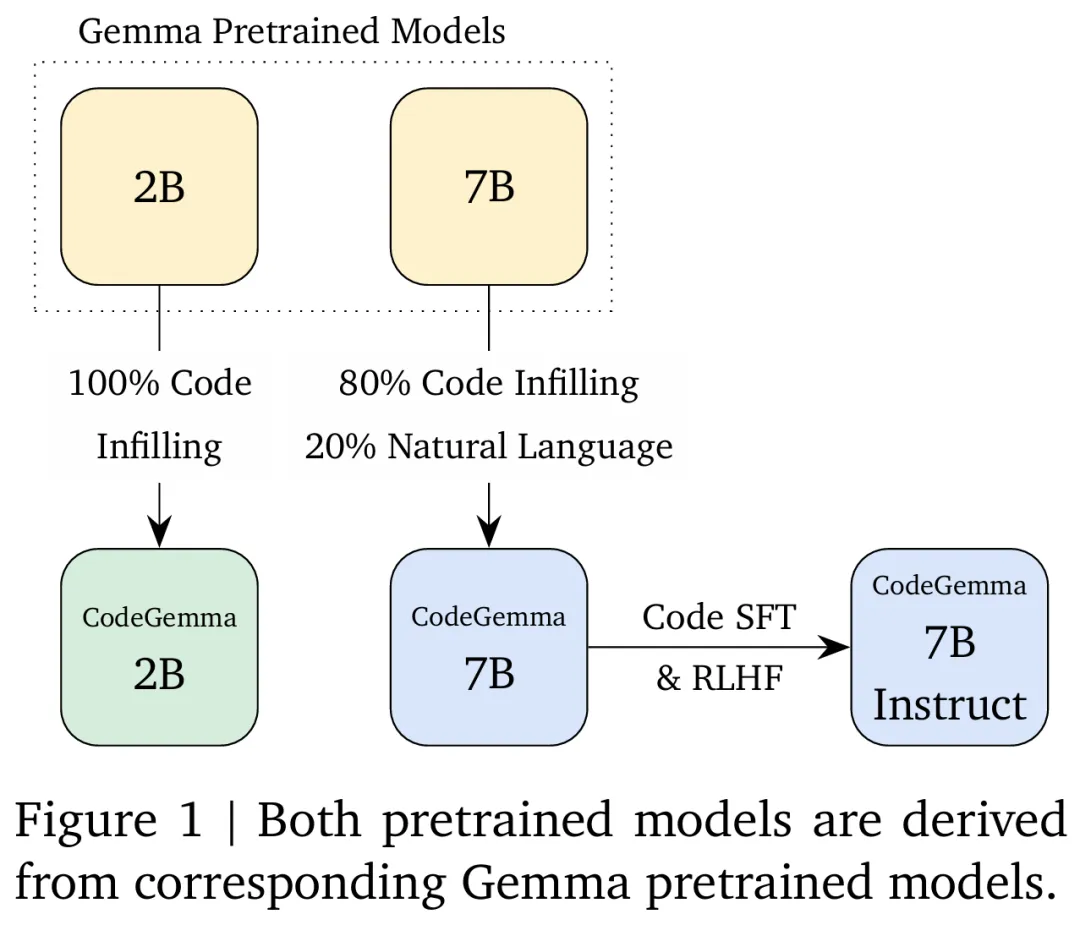
CodeGemma présente les avantages majeurs suivants :
- Complétion et génération intelligentes de code : complétez des lignes, des fonctions et générez même des blocs de code entiers, que vous travailliez localement ou dans le cloud ;
- Plus grande précision : CodeGemma utilise principalement des données en langue anglaise de 500 milliards de jetons provenant de documents en ligne, de mathématiques et de codes pour la formation. Le code généré est non seulement plus grammaticalement correct, mais également plus sémantiquement significatif, contribuant ainsi à réduire les erreurs et le temps de débogage ;.
- Capacités multilingues : prend en charge Python, JavaScript, Java et d'autres langages de programmation populaires ;
- Flux de travail simplifié : intégrez CodeGemma dans votre environnement de développement pour écrire moins de code passe-partout et travailler plus rapidement. Écrivez du code important, intéressant et différencie. Certains résultats de comparaison entre
CodeGemma et d'autres grands modèles de code grand public sont présentés dans la figure ci-dessous :
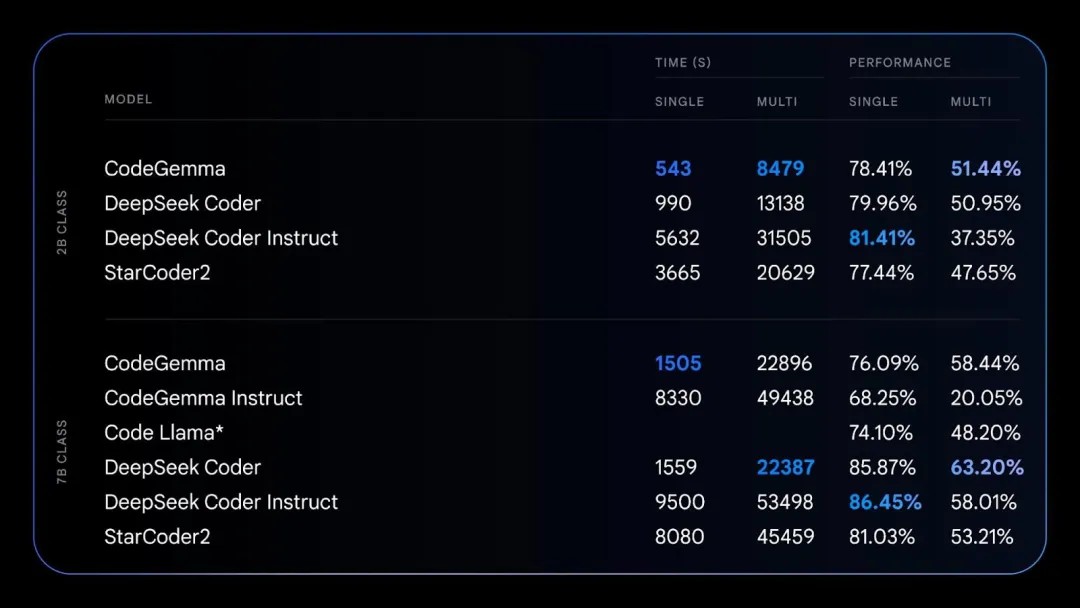
Résultats de comparaison entre le modèle CodeGemma 7B et le modèle Gemma 7B sur GSM8K, MATH et d'autres ensembles de données.
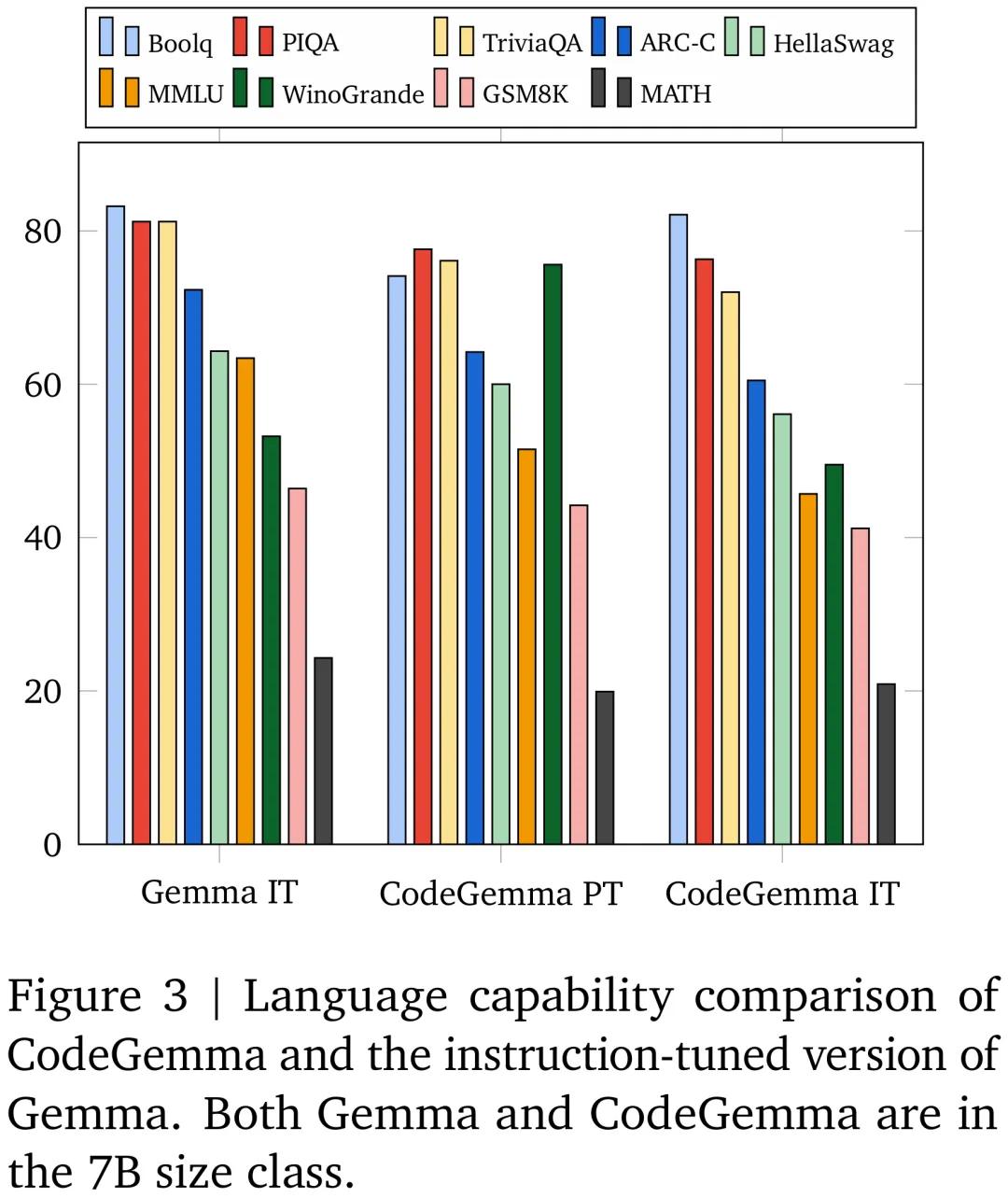
Pour plus de détails techniques et de résultats expérimentaux, veuillez vous référer à l'article publié simultanément par Google.

Adresse papier : https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf
Modèle de langage ouvert - RecurrentGemma
Google DeepMind a également publié une série de modèles de langage de poids ouverts - RecurrentGemma. RecurrentGemma est basé sur l'architecture Griffin, qui permet une inférence rapide lors de la génération de longues séquences en remplaçant l'attention globale par un mélange d'attention locale et de récurrences linéaires.

Rapport technique : https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf
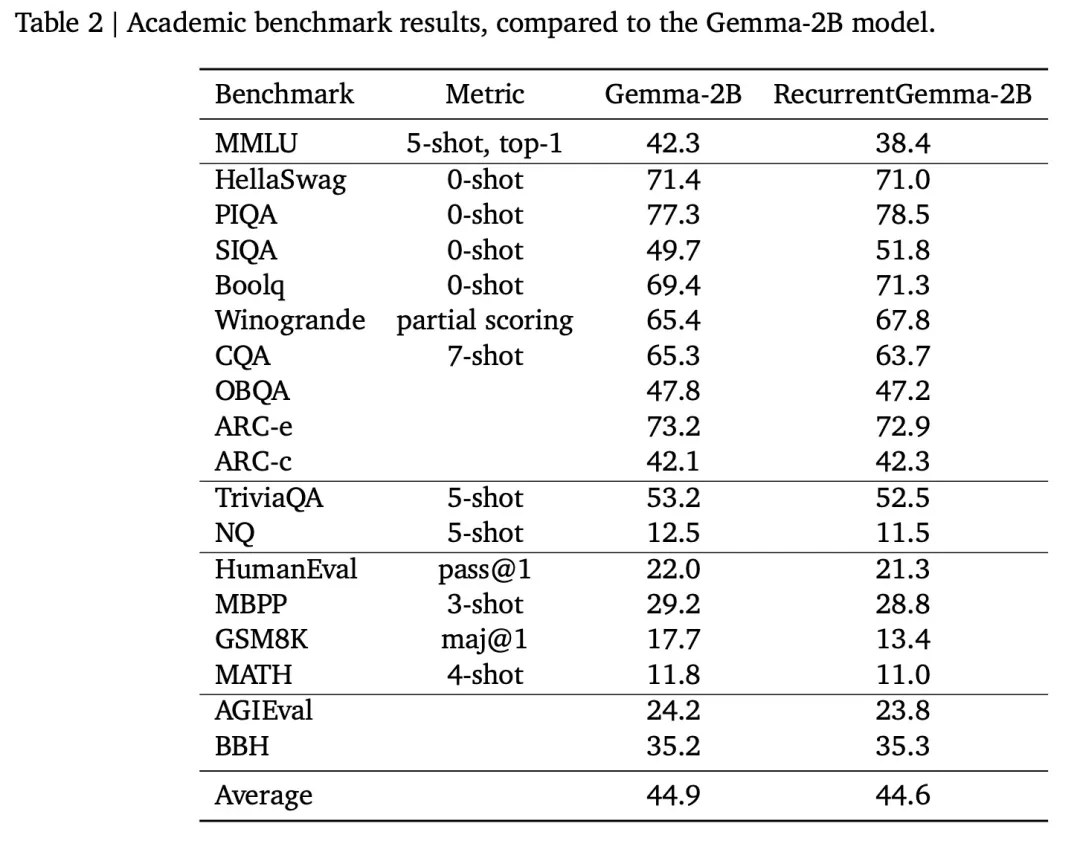
RecurrentGemma-2B atteint des performances supérieures sur les tâches en aval et peut être comparé à Gemma -2B (architecture du transformateur) est comparable.
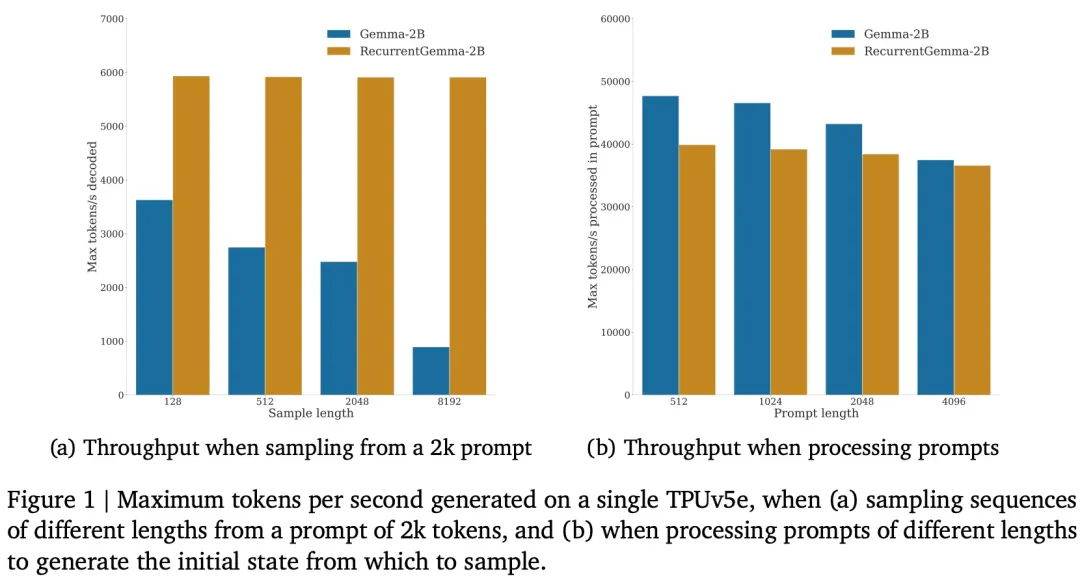
Dans le même temps, RecurrentGemma-2B atteint un débit plus élevé lors de l'inférence, en particulier sur les longues séquences.
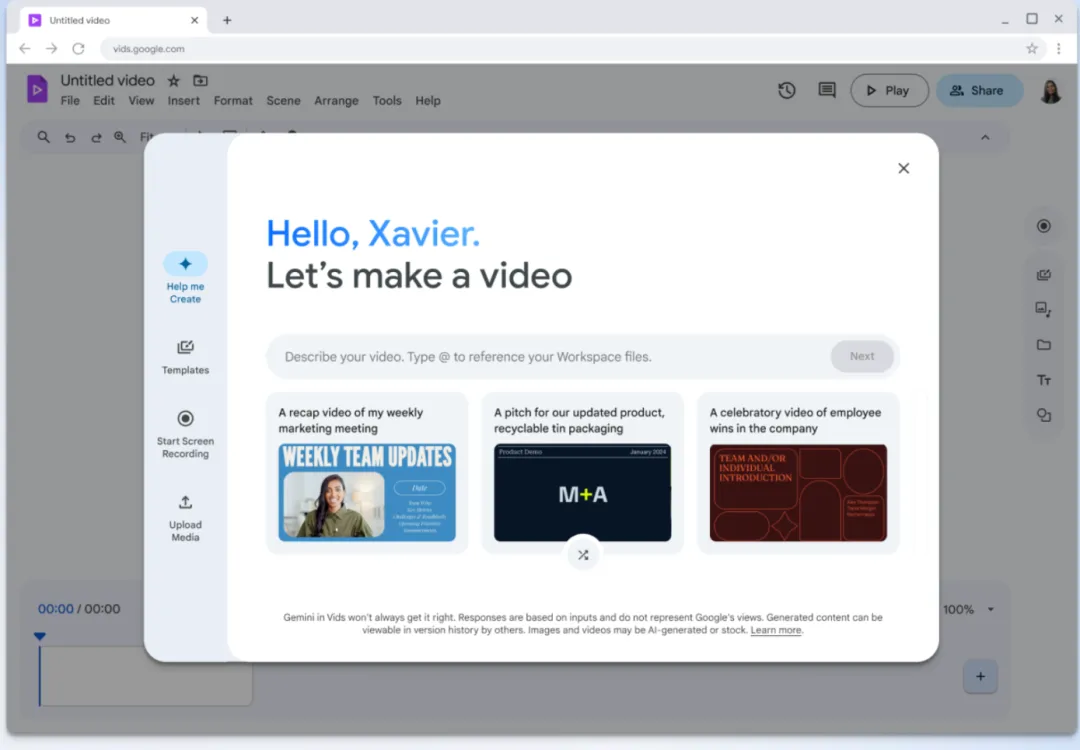
Outil de montage vidéo - Google Vids
Google Vids est un outil de création vidéo IA et une nouvelle fonctionnalité ajoutée dans Google Workspace.

Google affirme qu'avec Google Vids, les utilisateurs peuvent créer des vidéos aux côtés d'autres outils Workspace comme Docs et Sheets, et collaborer avec des collègues en temps réel.
Assistant de code spécifique à l'entreprise - Gemini Code Assist
Gemini Code Assist est un outil de complétion et d'assistance de code IA pour les entreprises, comparé à GitHub Copilot Enterprise. Code Assist sera disponible sous forme de plug-in pour les éditeurs populaires tels que VS Code et JetBrains.
Source de l'image : https://techcrunch.com/2024/04/09/google-launches-code-assist-its-latest-challenger-to-githubs-copilot/
Code Assist Propulsé par Gemini 1.5 Pro. Gemini 1.5 Pro dispose d'une fenêtre contextuelle d'un million de jetons, permettant aux outils de Google d'introduire plus de contexte que ceux de leurs concurrents. Google affirme que cela signifie que Code Assist peut fournir des suggestions de code plus précises et la possibilité de raisonner et de modifier de gros morceaux de code.
Google a déclaré : "Code Assist permet aux clients d'apporter des modifications à grande échelle à l'ensemble de leur base de code, permettant ainsi des transformations de code assistées par l'IA qui étaient auparavant impossibles." L'intelligence est une direction de développement de l'industrie brûlante cette année. Google a annoncé un nouvel outil pour aider les entreprises à créer des agents IA : Vertex AI Agent Builder.
Thomas Kurian, PDG de Google Cloud, a déclaré : « Vertex AI Agent Builder rend extrêmement simple et rapide la création et le déploiement d'agents conversationnels génératifs, prêts pour la production et pilotés par l'IA, qui peuvent guider les humains dans un processus. moyen d'améliorer la qualité et la précision des résultats générés par le modèle. "
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment enregistrer l'écran macOS
Apr 12, 2025 pm 05:33 PM
Comment enregistrer l'écran macOS
Apr 12, 2025 pm 05:33 PM
MacOS possède une application "Enregistrement d'écran" intégrée qui peut être utilisée pour enregistrer des vidéos d'écran. Étapes: 1. Démarrez l'application; 2. Sélectionnez la plage d'enregistrement (tout l'écran ou une application spécifique); 3. Activer / désactiver le microphone; 4. Cliquez sur le bouton "Enregistrer"; 5. Cliquez sur le bouton "Arrête" pour terminer. Enregistrez le fichier d'enregistrement au format .mov dans le dossier "Films".
 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
 Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Cet article décrit comment surveiller efficacement les performances SSL des serveurs Nginx sur les systèmes Debian. Nous utiliserons NginxExporter pour exporter des données d'état NGINX à Prometheus, puis l'afficher visuellement via Grafana. Étape 1: Configuration de Nginx Tout d'abord, nous devons activer le module Stub_Status dans le fichier de configuration NGINX pour obtenir les informations d'état de Nginx. Ajoutez l'extrait suivant dans votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou son fichier incluant): emplacement / nginx_status {Stub_status
 Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Comment configurer les règles de pare-feu pour Debian Syslog
Apr 13, 2025 am 06:51 AM
Cet article décrit comment configurer les règles de pare-feu à l'aide d'iptables ou UFW dans Debian Systems et d'utiliser Syslog pour enregistrer les activités de pare-feu. Méthode 1: Utiliser iptableIpTable est un puissant outil de pare-feu de ligne de commande dans Debian System. Afficher les règles existantes: utilisez la commande suivante pour afficher les règles iptables actuelles: Sudoiptables-L-N-V permet un accès IP spécifique: Par exemple, permettez l'adresse IP 192.168.1.100 pour accéder au port 80: Sudoiptables-Ainput-PTCP - DPORT80-S192.16
