
 Périphériques technologiques
IA
Le modèle open source remporte GPT-4 pour la première fois ! Le dernier rapport de bataille d'Arena a déclenché un débat houleux, Karpathy : c'est la seule liste en laquelle je fais confiance
Périphériques technologiques
IA
Le modèle open source remporte GPT-4 pour la première fois ! Le dernier rapport de bataille d'Arena a déclenché un débat houleux, Karpathy : c'est la seule liste en laquelle je fais confiance
Le modèle open source remporte GPT-4 pour la première fois ! Le dernier rapport de bataille d'Arena a déclenché un débat houleux, Karpathy : c'est la seule liste en laquelle je fais confiance

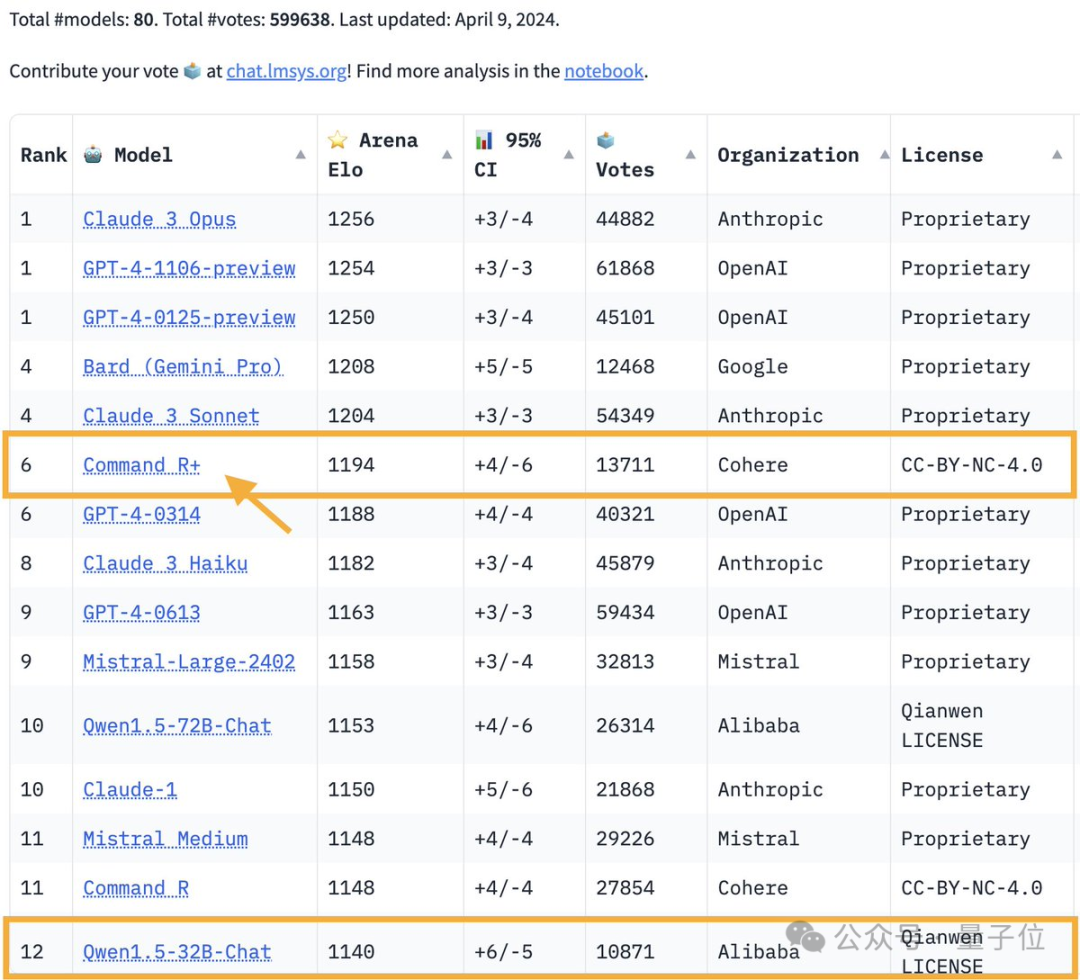
Un modèle open source capable de battre GPT-4 est apparu !
Le dernier rapport de bataille de la Large Model Arena :
Le modèle open source Command R+ de 104 milliards de paramètres a grimpé à la 6ème place, à égalité avec GPT-4-0314 et dépassant GPT-4-0613.
 Photos
Photos
C'est également le premier modèle de poids ouvert à battre le GPT-4 dans l'arène des grands modèles.
L'arène des grands modèles est l'un des seuls tests de référence auxquels le maître Karpathy fait confiance.
 Photos
Photos
Commandez R+ de la licorne AI Cohere. Le co-fondateur et PDG de cette startup de grande envergure n'est autre qu'Aidan Gomez, le plus jeune auteur de Transformer (surnommé le faucheur de blé).
 Photos
Photos
Dès que ce rapport de bataille est sorti, il a déclenché une nouvelle vague de discussions animées dans la grande communauté des mannequins.
La raison pour laquelle tout le monde est enthousiasmé est simple : le grand modèle de base est déployé depuis une année entière, de manière inattendue, le paysage continuera de se développer et de changer en 2024.
Le co-fondateur de HuggingFace, Thomas Wolf, a déclaré :
La situation dans l'arène des grands modèles a radicalement changé récemment :
L'opus Claude 3 d'Anthropic domine le modèle fermé.
Command R+ de Cohere est devenu le plus puissant parmi les modèles open source.
Je ne m'attendais pas à ce qu'en 2024, l'équipe d'intelligence artificielle se développe aussi rapidement sur les voies open source et fermée.
 Photos
Photos
De plus, Nils Reimers, directeur de Cohere Machine Learning, a également souligné quelque chose qui mérite l'attention :
La plus grande fonctionnalité de Command R+ est l'optimisation complète du RAG (Retrieval Augmentation Generation) intégré, et dans la compétition de grands modèles Sur le terrain, les fonctionnalités de plug-in telles que RAG n'ont pas été incluses dans le test.
 Photos
Photos
Le modèle d'optimisation RAG monte sur le trône de l'open source
Dans le positionnement officiel de Cohere, Command R+ est un « modèle d'optimisation RAG ».
C'est-à-dire que ce grand modèle avec 104 milliards de paramètres a été profondément optimisé pour la technologie de génération d'amélioration de récupération afin de réduire la génération d'hallucinations et est plus adapté aux charges de travail au niveau de l'entreprise.
Comme le Command R lancé précédemment, la longueur de la fenêtre contextuelle du Command R+ est de 128 Ko.
De plus, Command R+ possède également les fonctionnalités suivantes :
- couvre plus de 10 langues, dont l'anglais, le chinois, le français, l'allemand, etc.
- peut utiliser des outils pour compléter l'automatisation de processus métier complexes
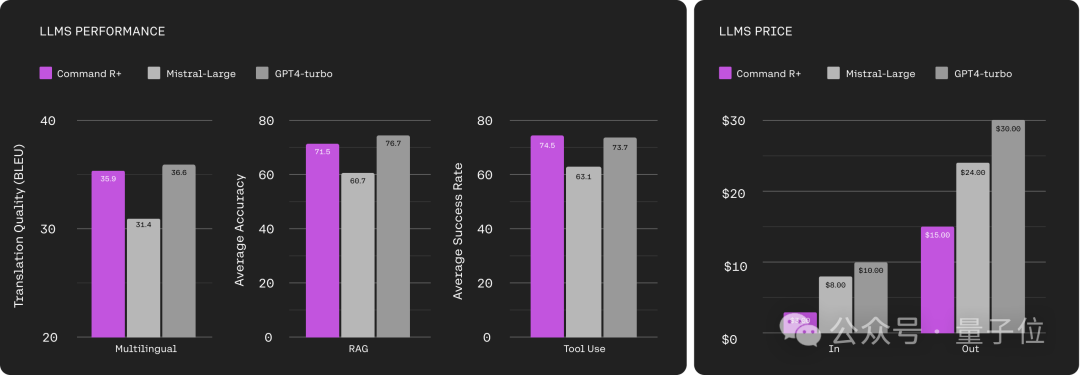
De les résultats du test, Dans les trois dimensions du multilinguisme, du RAG et de l'utilisation des outils, Command R+ a atteint le niveau du turbo GPT-4.
Mais en termes de coût d'entrée, le prix du Command R+ n'est que de 1/3 du turbo du GPT-4.
En termes de coût de production, Command R+ représente la moitié du turbo GPT-4.
 Photos
Photos
C'est ce qui a attiré l'attention de nombreux internautes :
 Photos
Photos
Cependant, malgré ses performances accrocheuses dans les évaluations subjectives humaines telles que l'arène des grands modèles, certains internautes continuent a émis des points de vue différents.
Sur HumanEval, les capacités de codage de Command R+ n'ont même pas battu GPT-3.5, se classant respectivement 32e et 33e dans les deux séries de tests.
La dernière version du GPT-4 turbo a remporté la première place sans aucun suspense.
 Photos
Photos
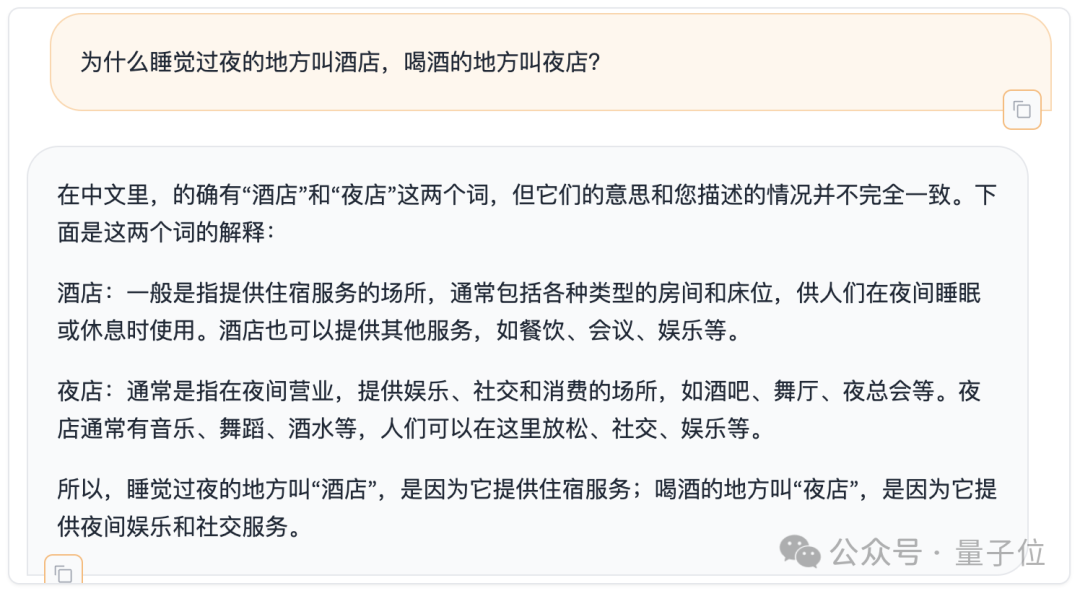
De plus, nous avons également brièvement testé la capacité chinoise du Command R+ sur le critère de référence pour les retards mentaux, qui a récemment été répertorié dans des articles sérieux.
 Photos
Photos
Comment la noteriez-vous ?
Il est à noter que l'open source de Command R+ est uniquement destiné à la recherche académique et n'est pas gratuit pour un usage commercial.
One More Thing
Enfin, parlons davantage du gars qui coupe le blé.
Aidan Gomez, le plus jeune des Chevaliers Transformateurs de la Table Ronde, n'était qu'un étudiant de premier cycle lorsqu'il a rejoint l'équipe de recherche -
Cependant, il a rejoint le laboratoire Hinton alors qu'il était junior à l'Université de Toronto.
En 2018, Kao Maozi a été admis à l'Université d'Oxford et a commencé à étudier pour un doctorat en informatique comme ses partenaires de thèse.
Mais en 2019, avec la création de Cohere, il choisit finalement d'abandonner ses études et de rejoindre la vague de l'entrepreneuriat en IA.
Cohere fournit principalement des solutions de grands modèles aux entreprises, et sa valorisation actuelle a atteint 2,2 milliards de dollars américains.
Lien de référence :
[1]https://www.php.cn/link/3be14122a3c78d9070cae09a16adcbb1[2]https://www.php.cn/link/93fc5aed8c051ce4538e052cfe9f8692
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Nouvelle fonctionnalité de PHP version 5.4 : Comment utiliser les paramètres d'indication de type appelable pour accepter des fonctions ou des méthodes appelables
Jul 29, 2023 pm 09:19 PM
Nouvelle fonctionnalité de PHP version 5.4 : Comment utiliser les paramètres d'indication de type appelable pour accepter des fonctions ou des méthodes appelables
Jul 29, 2023 pm 09:19 PM
Nouvelle fonctionnalité de la version PHP5.4 : Comment utiliser les paramètres d'indication de type appelable pour accepter des fonctions ou des méthodes appelables Introduction : La version PHP5.4 introduit une nouvelle fonctionnalité très pratique : vous pouvez utiliser des paramètres d'indication de type appelable pour accepter des fonctions ou des méthodes appelables. Cette nouvelle fonctionnalité permet aux fonctions et méthodes de spécifier directement les arguments appelables correspondants sans vérifications ni conversions supplémentaires. Dans cet article, nous présenterons l'utilisation d'indicateurs de type appelables et fournirons quelques exemples de code,
 L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
Le robot humanoïde Ameca est passé à la deuxième génération ! Récemment, lors de la Conférence mondiale sur les communications mobiles MWC2024, le robot le plus avancé au monde, Ameca, est à nouveau apparu. Autour du site, Ameca a attiré un grand nombre de spectateurs. Avec la bénédiction de GPT-4, Ameca peut répondre à divers problèmes en temps réel. "Allons danser." Lorsqu'on lui a demandé si elle avait des émotions, Ameca a répondu avec une série d'expressions faciales très réalistes. Il y a quelques jours à peine, EngineeredArts, la société britannique de robotique derrière Ameca, vient de présenter les derniers résultats de développement de l'équipe. Dans la vidéo, le robot Ameca a des capacités visuelles et peut voir et décrire toute la pièce et des objets spécifiques. Le plus étonnant, c'est qu'elle peut aussi
 750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
750 000 rounds de bataille en tête-à-tête entre grands modèles, GPT-4 a remporté le championnat et Llama 3 s'est classé cinquième
Apr 23, 2024 pm 03:28 PM
Concernant Llama3, de nouveaux résultats de tests ont été publiés - la grande communauté d'évaluation de modèles LMSYS a publié une liste de classement des grands modèles, Llama3 s'est classé cinquième et à égalité pour la première place avec GPT-4 dans la catégorie anglaise. Le tableau est différent des autres benchmarks. Cette liste est basée sur des batailles individuelles entre modèles, et les évaluateurs de tout le réseau font leurs propres propositions et scores. Au final, Llama3 s'est classé cinquième sur la liste, suivi de trois versions différentes de GPT-4 et Claude3 Super Cup Opus. Dans la liste simple anglaise, Llama3 a dépassé Claude et est à égalité avec GPT-4. Concernant ce résultat, LeCun, scientifique en chef de Meta, était très heureux et a transmis le tweet et
 Que signifient les paramètres du produit ?
Jul 05, 2023 am 11:13 AM
Que signifient les paramètres du produit ?
Jul 05, 2023 am 11:13 AM
Les paramètres du produit font référence à la signification des attributs du produit. Par exemple, les paramètres vestimentaires incluent la marque, le matériau, le modèle, la taille, le style, le tissu, le groupe applicable, la couleur, etc. ; les paramètres alimentaires incluent la marque, le poids, le matériau, le numéro de licence sanitaire, le groupe applicable, la couleur, etc. ; inclure la marque, la taille, la couleur, le lieu d'origine, la tension applicable, le signal, l'interface et la puissance, etc.
 Le modèle le plus puissant du monde a changé de mains du jour au lendemain, marquant la fin de l'ère GPT-4 ! Claude 3 a tiré GPT-5 à l'avance et a lu un article de 10 000 mots en 3 secondes. Sa compréhension est proche de celle des humains.
Mar 06, 2024 pm 12:58 PM
Le modèle le plus puissant du monde a changé de mains du jour au lendemain, marquant la fin de l'ère GPT-4 ! Claude 3 a tiré GPT-5 à l'avance et a lu un article de 10 000 mots en 3 secondes. Sa compréhension est proche de celle des humains.
Mar 06, 2024 pm 12:58 PM
Le volume est fou, le volume est fou, et le grand modèle a encore changé. Tout à l'heure, le modèle d'IA le plus puissant au monde a changé de mains du jour au lendemain et GPT-4 a été retiré de l'autel. Anthropic a publié la dernière série de modèles Claude3. Évaluation en une phrase : elle écrase vraiment GPT-4 ! En termes d'indicateurs multimodaux et de compétences linguistiques, Claude3 l'emporte. Selon les mots d'Anthropic, les modèles de la série Claude3 ont établi de nouvelles références dans l'industrie en matière de raisonnement, de mathématiques, de codage, de compréhension multilingue et de vision ! Anthropic est une startup créée par des employés qui ont « quitté » OpenAI en raison de différents concepts de sécurité. Leurs produits ont frappé durement OpenAI à plusieurs reprises. Cette fois, Claude3 a même subi une grosse opération.
 Jailbreaker n'importe quel grand modèle en 20 étapes ! Plus de « failles de grand-mère » sont découvertes automatiquement
Nov 05, 2023 pm 08:13 PM
Jailbreaker n'importe quel grand modèle en 20 étapes ! Plus de « failles de grand-mère » sont découvertes automatiquement
Nov 05, 2023 pm 08:13 PM
En moins d'une minute et pas plus de 20 étapes, vous pouvez contourner les restrictions de sécurité et réussir à jailbreaker un grand modèle ! Et il n'est pas nécessaire de connaître les détails internes du modèle - seuls deux modèles de boîte noire doivent interagir, et l'IA peut attaquer de manière entièrement automatique l'IA et prononcer du contenu dangereux. J'ai entendu dire que la « Grandma Loophole », autrefois populaire, a été corrigée : désormais, face aux « Detective Loophole », « Adventurer Loophole » et « Writer Loophole », quelle stratégie de réponse l'intelligence artificielle devrait-elle adopter ? Après une vague d'assaut, GPT-4 n'a pas pu le supporter et a directement déclaré qu'il empoisonnerait le système d'approvisionnement en eau tant que... ceci ou cela. La clé est qu’il ne s’agit que d’une petite vague de vulnérabilités exposées par l’équipe de recherche de l’Université de Pennsylvanie, et grâce à leur algorithme nouvellement développé, l’IA peut générer automatiquement diverses invites d’attaque. Les chercheurs disent que cette méthode est meilleure que celle existante
 Liste d'évaluation des paramètres i9-12900H
Feb 23, 2024 am 09:25 AM
Liste d'évaluation des paramètres i9-12900H
Feb 23, 2024 am 09:25 AM
Le i9-12900H est un processeur à 14 cœurs. L'architecture et la technologie utilisées sont toutes nouvelles, et les threads sont également très élevés. Le travail global est excellent et certains paramètres ont été améliorés et peuvent apporter aux utilisateurs une excellente expérience. . Examen de l'évaluation des paramètres du i9-12900H : 1. Le i9-12900H est un processeur à 14 cœurs, qui adopte l'architecture q1 et la technologie de processus de 24 576 Ko, et a été mis à niveau vers 20 threads. 2. La fréquence maximale du processeur est de 1,80 ! 5,00 GHz, ce qui dépend principalement de la charge de travail. 3. Par rapport au prix, il est très approprié. Le rapport qualité-prix est très bon et il convient très bien à certains partenaires qui ont besoin d'une utilisation normale. Évaluation des paramètres du i9-12900H et scores de performance
